
一文弄懂字符编码的演变史
ASCII码
起初美国有关标准组织制定了一套编码叫ASCII码,用了一个字节低7位,最高位二进制位0,编码范围是00000000-0xxxxxxx,总共有128状态,表示了大小写字母,数字,标点符号以及特殊的控制字符.
0~31以及127(共33个)是控制字符,例如:LF(换行),CR(回车).
32~156(共95个)是字符,48~57为0到9共十个阿拉伯数字,65~122是大小的英文字母,其余的是字符,运算符等.
0-127 标准ascii码,127-255扩展ascii码,扩展主要存储西欧国家的一些字符
ISO8859-1
Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。属于单字节编码,最多能表示的字符范围是0-255,应用于英文系列。比如,字母a的编码为0x61=97。
GB2312
它是双字节编码,总的编码范围是 A1-F7,其中从 A1-A9 是符号区,总共包含 682 个符号,从 B0-F7 是汉字区,包含 6763 个汉字,1980年发布。
规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
GBK
它的编码范围是 8140~FEFE(去掉 XX7F)总共有 23940 个码位,它能表示 21003 个汉字,它的编码是和 GB2312 兼容的,也就是说用 GB2312 编码的汉字可以用 GBK 来解码,并且不会有乱码。gb2312的低字节有>127位的限制,为了扩展更多字符,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
GB18030
它可能是单字节、双字节或者四字节编码,它的编码与 GB2312 编码兼容,这个虽然是国家标准,但是实际应用系统中使用的并不广泛。主要少数民族也要用电脑了,于是我们再扩展,共收录了27484个汉字,又加了几千个新的少数民族的字,包括蒙文,藏文,维吾尔文,在GBK的基础上 扩成了GB18030。从此之后,中华民族的文化就可以在计算机时代中传承了。
历史问题
ASCII 码的问题在于尽管所有人都在 0 - 127 号字符上达成了一致,但对于 128 - 255 号字符上却有很多种不同的解释。与此同时,亚洲语言有更多的字符需要被存储,一个字节已经不够用了。于是,人们开始使用两个字节来存储字符,这种以双字节的字符集称为“DBCS”(Double Byte Charecter Set),所引申出来的编码 如台湾big5,日本shift_js,韩国euc-kr等,这些编码都是根据操作系统相关,此类编码称之为ansi编码,简体中文操作系统的ansi其实就是gbk.
最大的特点是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,因此他们写的程序为了支持中文处 理,必须要注意字串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。
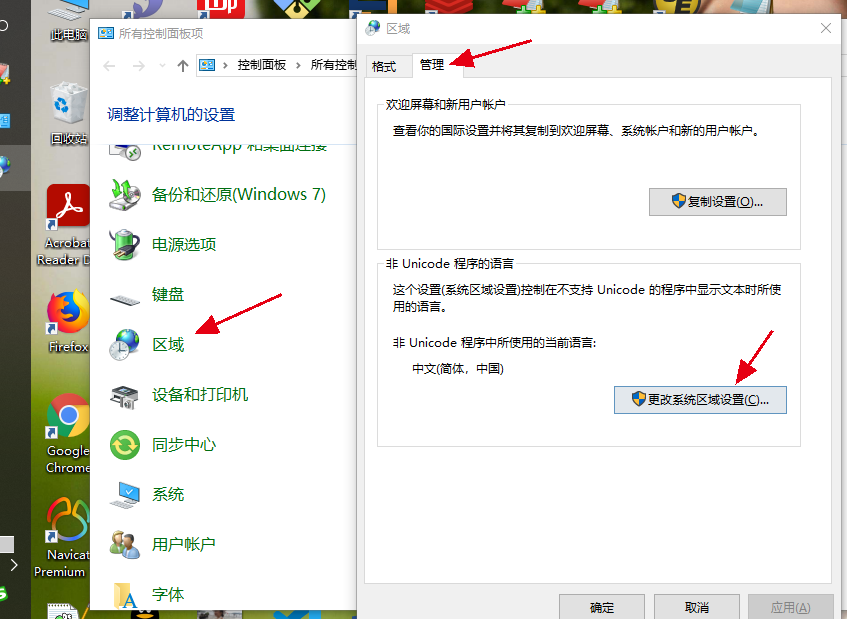
Windows下code page是根据当前系统区域(locale)来设置的,要想修改系统默认的“ANSI编码”,我们可以通过修改系统区域来实现(“控制面板” =>“时钟、语言和区域”=>“区域和语言”=>“管理”=>“更改系统区域设置...”):
Unicode
最终,美国人意识到他们应该提出一种标准方案来展示世界上所有语言中的所有字符,出于这个目的,Unicode诞生了,或叫UCS,分为UCS-2和UCS-4.分别代表用2或4个字节存储。
Unicode 给所有的字符指定了一个数字用来表示该字符。
现目前 Unicode 支持 3种编码方式,UTF-8,UTF-16,UTF-32。
| 编码方式 | 字节数 |
|---|---|
| UTF-8 | 1 - 4 |
| UTF-16 | 2 or 4 |
| UTF-32 | 4 |
UTF-8
目前互联网上使用最广泛的一种 Unicode 编码方式,它的最大特点就是可变长。它可以使用 1 - 4 个字节表示一个字符,根据字符的不同变换长度。编码规则如下:
对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。
对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。
编码规则如下:
Unicode 十六进制码点范围 UTF-8 二进制
0x00- 0x7F 0xxxxxxx
0x80-0x7FF 110xxxxx 10xxxxxx
0x800-0xFFFF 1110xxxx 10xxxxxx 10xxxxxx
0x10000 - 0x10FFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
根据上面编码规则对照表,进行 UTF-8 编码和解码就简单多了。下面以汉字“汉”为利,具体说明如何进行 UTF-8 编码和解码。
“汉”的 Unicode 码点是 0x6c49(110 1100 0100 1001),通过上面的对照表可以发现,0x0000 6c49 位于第三行的范围,那么得出其格式为 1110xxxx 10xxxxxx 10xxxxxx。接着,从“汉”的二进制数最后一位开始,从后向前依次填充对应格式中的 x,多出的 x 用 0 补上。这样,就得到了“汉”的 UTF-8 编码为 11100110 10110001 10001001,转换成十六进制就是 0xE6 0xB7 0x89。
解码的过程也十分简单:如果一个字节的第一位是 0 ,则说明这个字节对应一个字符;如果一个字节的第一位1,那么连续有多少个 1,就表示该字符占用多少个字节。
字节序
Little endian和Big endian
以汉字"严"为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。
这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
因此,第一个字节在前,就是"大头方式"(Big endian),第二个字节在前就是"小头方式"(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
|
Unicode编码
|
UTF-16LE
|
UTF-16BE
|
UTF32-LE
|
UTF32-BE
|
|
0x006C49
|
49 6C
|
6C 49
|
49 6C 00 00
|
00 00 6C 49
|
|
0x020C30
|
30 DC 43 D8
|
D8 43 DC 30
|
30 0C 02 00
|
00 02 0C 30
|
|
UTF编码
|
Byte Order Mark (BOM)
|
| UTF-8 without BOM | 无 |
|
UTF-8 with BOM
|
EF BB BF
|
|
UTF-16LE
|
FF FE
|
|
UTF-16BE
|
FE FF
|
|
UTF-32LE
|
FF FE 00 00
|
|
UTF-32BE
|
00 00 FE FF
|
UTF-16
UTF-16 具体定义了 Unicode 字符在计算机中存取方法。UTF-16 用两个字节来表示 Unicode 转化格式,这个是定长的表示方法,不论什么字符都可以用两个字节表示,两个字节是 16 个 bit,所以叫 UTF-16。UTF-16 表示字符非常方便,每两个字节表示一个字符,这个在字符串操作时就大大简化了操作,这也是 Java 以 UTF-16 作为内存的字符存储格式的一个很重要的原因。
UCS-4根据最高位为0的最高字节分成27=128个组(group)。每个group再根据次高字节分为256个平面(plane)。每个平面根据第3个字节分为256行 (row),每行有256个码位(cell)。group 0的平面0被称作BMP(Basic Multilingual Plane)。如果UCS-4的前两个字节为全零,那么将UCS-4的BMP去掉前面的两个零字节就得到了UCS-2。每个平面有216=65536个码位。Unicode计划使用了17个平面,一共有17×65536=1114112个码位。
最前面的 65536 个字符位,称为基本平面(简称 BMP ),它的码点范围是从 0 到 2^16-1,写成 16 进制就是从 U+0000 到 U+FFFF。所有最常见的字符都放在这个平面,这是 Unicode 最先定义和公布的一个平面。剩下的字符都放在辅助平面(简称 SMP ),或叫增补平面,码点范围从 U+010000 到 U+10FFFF。
它的编码规则很简单:基本平面的字符占用 2 个字节,增补平面的字符占用 4 个字节。也就是说,编码长度要么是 2 个字节(U+0000 到 U+FFFF),或 4 个字节(U+010000 到 U+10FFFF)。那么问题来了,当我们遇到两个字节时,到底是把这两个字节当作一个字符还是与后面的两个字节一起当作一个字符呢?
这里有一个很巧妙的地方,在基本平面内,从 U+D800 到 U+DFFF 是一个空段,即这些码点不对应任何字符。因此,这个空段可以用来映射或是代理增补平面的字符。

基本平面中这些用作“代理”的码点区域就被称之为“代理区(Surrogate Zone)”,其码点编号范围为0xD800~0xDFFF(十进制55296~57343),共2048个码点。
辅助平面的字符位共有 2^20 个,因此表示这些字符至少需要 20 个二进制位。UTF-16 将这 20 个二进制位分成两半,前 10 位映射在 U+D800 到 U+DBFF,称为高位(H),后 10 位映射在 U+DC00 到 U+DFFF,称为低位(L)。这意味着,一个辅助平面的字符,被拆成两个基本平面的字符表示。
因此,当我们遇到两个字节,发现它的码点在 U+D800 到 U+DBFF 之间,就可以断定,紧跟在后面的两个字节的码点,应该在 U+DC00 到 U+DFFF 之间,这四个字节必须放在一起解读。
增补平面一共有16个平面(即第2平面~第17平面),码点编号范围为0x10000~0x10FFFF(十进制为65536~1114111,码点总数为1048576个)。用两个代理码元表示,第一个码元的取值范围为0xD800~0xDBFF(二进制为1101 1000 0000 0000 ~ 1101 1011 1111 1111,十进制为55296 ~ 56319),第二个码元的取值范围为0xDC00~0xDFFF(二进制为1101 1100 0000 0000 ~ 1101 1111 1111 1111,十进制为56320 ~ 57343)。
辅助平面的字符转化成两个基本平面中的代理对的具体算法如下:
1) 增补平面中的码点值(0x10000~0x10FFFF,二进制为0001 0000 0000 0000 0000~1 0000 1111 1111 1111 1111,对应的字符名称为U+10000~U+10FFFF)减去0x10000(二进制为0001 0000 0000 0000 0000),可得到20位长的比特组(值的范围为0x00000~0xFFFFF,二进制为0000 0000 0000 0000 0000 ~ 1111 1111 1111 1111 1111);
2)将得到的20位长的比特组分拆为两部分:高位10比特和低位10比特;
3)20位长的比特组中的高位10比特(值的范围为0x000~0x3FF,二进制为00 0000 0000~11 1111 1111)加上0xD800(二进制为1101 1000 0000 0000),得到第一个代理码元即引导代理(值的范围是0xD800~0xDBFF,二进制为1101 1000 0000 0000 ~ 1101 1011 1111 1111);
4)20位长的比特组中的低位10比特(值范围也是0x000~0x3FF,二进制为00 0000 0000~11 1111 1111)加上0xDC00(二进制为1101 1100 0000 0000),得到第二个代理码元即尾随代理(值的范围是0xDC00~0xDFFF,二进制为1101 1100 0000 0000 ~ 1101 1111 1111 1111);
5)将引导代理与尾随代理按前后顺序组合在一起成为“代理对”,就得到了增补平面字符的码元序列。
举例:
增补平面中码点值为10437(字符名称为U+10437)的字符(𐐷):


注意:
editplus,记事本可以存储unicode辅助平面的字符,nodepad++存储会失效。
使用ultraedit查看的时候,nodepad++存储的辅助字符会缺少两个字节,再次读取时会将两字节转化为普通的字符
总结
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
以上内容均参考各类技术文章,百度百科等,如有误,欢迎指出!!!!
如果,您认为阅读这篇博客让您有些收获, 如果,您希望更容易地发现我的新博客,不妨关注一下。因为,我的写作热情也离不开您的肯定支持。
感谢您的阅读,如果您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客。
因为有小孩,兼职卖书,路过的朋友有需要低价购买图书、点读笔、纸尿裤等资源的,可扫最上方二维码,质量有保证,价格很美丽,欢迎咨询! 欢迎关注微信公众号:18般武艺
