
Hibernate(二) - 主键生成策略--一级缓存--事务管理
Hibernate 持久化类的编写规则
1、什么是持久化类:
Hibernate 是持久层 ORM 映射框架,专注于数据的持久化操作。所谓的持久化,就是将内存中的数据永远存储到关系型数据库中。那么知道了什么是持久化?什么又是持久化类呢?其实所谓的持久化类指的是一个 Java 类与数据库表建立了映射关系,那么这个类称为是持久化类。其实可以简单的理解为持久化类就是一个 Java 类有了 一个映射文件与数据库的表建立了关系。那么在编写持久化类的时候有哪些要求呢?
持久化:将内存中的一个对象持久化到数据库中 的过程。Hibernate 框架就是用来进行持久化的框架。
持久化类:一个 Java 对象与数据库的表建立了映射关系,那么这个类在 Hibernate 中称为持久化类。
持久化类 = Java 类 + 映射文件
2、持久化类的编写规则
对持久化类提供一个 无参的构造方法 :Hibernate 底层需要使用反射生成示例
属性需要私有,对私有属性提供 public 的 get 和 set :Hibernate 中获取,设置对象的值
对持久化类提供一个唯一标识OID与数据库逐渐对应 :Java 中通过对象的地址区分是否是同一个对象,数据库中通过逐渐区分是否是同一记录。在 Hibernate 中通过持久化类的 OID 的属性区分是否是同一对象。
持久化类中的属性尽量使用包装类型 :因为基本数据类型默认是0,会有很多歧义。包装类型默认值是 null。
持久化类不要使用 final 进行修饰 :延迟加载(load 方法)本身是 hibernate 一个优化的手段,返回的是一个代理对象(javassist 可以对没有几口实现的类产生代理——使用了非常底层的字节码增强技术,继承这个类进行代理)。如果不能被继承,不能产生代理对象,延迟加载也就失效。load 方法和 get 方法效果一致。
主键生成策略
1、主键的分类
① 自然主键:主键的本身就是表中的一个字段(实体中的一个具体的属性)。
创建一个人员表,人员都会有一个身份证号(唯一的不可重复的),使用了身份证号作为主键,这种主键称为是自然主键(如果录入信息时输错,不易于修改)。
② 代理主键:主键的本身不是表中必须的一个字段(不是实体中的某个具体的属性)。
创建一个人员表,没有使用人员的身份证号,用了一个与这个表不相关的字段 ID(PNO),这种主键称为是代理主键。
在实际开发中,尽量使用代理主键。
一旦自然主键参与到业务逻辑中,后期有可能要修改源代码(主键不可以修改)。
好的程序设计满足 OCP 原则,对程序的扩展是 open 的,对源代码的修改是 close 的。
2、Hibernate 的主键生成策略
在实际开发中一般不允许用户手动设置主键,一般将主键交给数据库,手动编写程序进行设置。在 Hibernate 中为了减少程序编写,提供了多种主键的生成策略。
increment:Hibernate 中提供的自动增长机制,适用 sort、int、long 类型的主键,在单线程使用 。
首先发送一条语句, select max(id) from 表;然后让id + 1,作为 下一条记录(线程不安全)。使用 hibernate 生成主键,须将配置改为自动建表,建表后,数据库中的主键不显示自动增长。
indentity:适用 sort、int、long 类型的主键,使用的是数据库底层的增长机制。适用于有自动增长机制的数据库(MySQL、MSSQL),但 Oracle 没有自动增长机制。
sequence:适用 sort、int、long类型的主键,采用的是序列的方式(通过序列实现增长,Orcle支持序列 ),MySQL不能使用sequence。
uuid :适用于字符串型主键。使用 hibernate 中的随机方式生成字符串主键(类似于 Java 中的 uuid)。
native :本地策略,可以在 identity 和 sequence 之间进行切换。如果底层使用的 MySQL,它的底层相当于 identity;如果底层使用 Orcle,相当于 sequence。
自动切换,不用去管使用的使 Orcle 还是 MySQL。
assigned :hibernate 放弃主键的管理,需要通过手动编写程序或者用户自己设置。主键在插入数据的时候必须手动设置进去,否则的话 hibernate 会报错。
Java 对象属性与数据可主键相互对应,设置 Java 对象中特定属性的值即可。
foreign :外部的,在一对一的一种关联映射的情况下使用。
一对一这种关系,实际开发过程中非常少。但是有一种一对一叫作主键对应,一张表的主键作为另一张表的主键,建立了一种关系,可以使用 foreign。否则,用不上 foreign。
持久化类的三种状态
Hibernate 是持久化框架,通过持久化类完成 ORM操作。Hibernate 为了更好的管理持久化类,将持久化了分成三种状态。
1、瞬时态(transient)
瞬时态也称为临时态或者自由态,瞬时态的实例是由 new 命令创建、开辟存储空间的对象,不存在持久化标识 OID(相当于主键值 ),尚未与 Hibernate Session 关联,在数据库中也没有记录,失去引用后将被 JVM 回收。瞬时状态的对象在内存中是孤立存在的,与数据库的数据无任何关联,仅是一个信息携带的载体。
2、持久态(persistent)
持久态的对象存在持久化标识 OID,,加入到了 Session 缓存中,并且相关的 Session 没有关闭,在数据库中有相应的记录,每条记录只对应唯一的持久化对象,需要注意的是,持久化对象在事务还未提交前变成持久态的。
3、托管态(detached)
托管态也称离线态或者游离态,当某个持久化状态的实例与 Session 的关联被关闭时就变成了托管态,托管态对象存在持久化表示OID,并且仍然与数据库中的数据存在关联,只是失去了与当前 Session 的关联,托管状态对象发生改变时 Hibernate 不能检测到。
customer 对象由 new 关键字创建,此时还位于 Session 进行关联,它的状态称为瞬时态;在执行了 session.save(customer) 操作后,customer 对象纳入了 Session 的管理范围,这时的 customer 对象变成了持久态镀锡,此时的 Session 的事务还没有被提交;程序执行完 commit() 操作并关闭了 Session 后,customer 对象与 Session 的关联被关闭,此时 customer 对象就变成了托管态。
4、区分三种状态对象
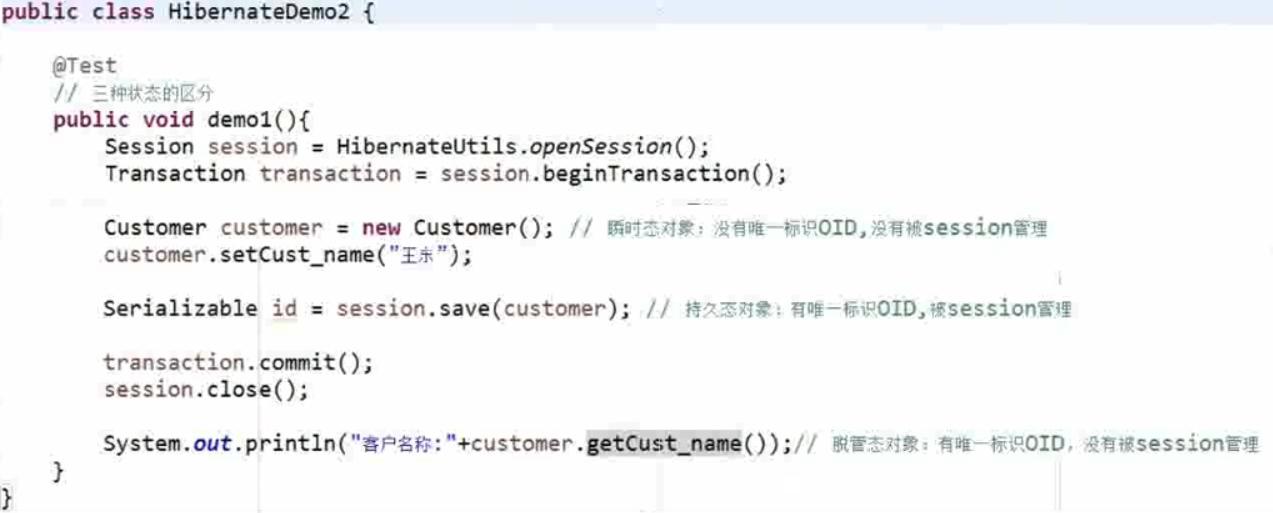
重点研究的是持久化类的持久态的对象,有一个特殊的能力可以自动更新数据库。
几种状态的对象都可以 相互转换。
三种状态的转换
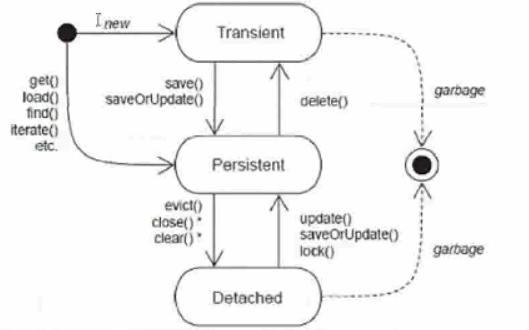
1、瞬时态对象
获得
Customer customer = new Customer();
状态转换
瞬时态→持久态
save(Object obj)、saveOrUpdate(Object obj)
瞬时态→托管态
customer.setCust_id(1l);
2、持久态对象
获得
get()、load()、find()、iterate()
Customer customer = session.get(customer.class,1l);
状态转换
持久态→瞬时态
delete()
持久态→托管态
close()、clear()、evict(Object obj);
3、托管态对象
获得
Customer customer = new Customer();
customer.setCust_id(1l);
状态转换
脱管态→持久态
update()、saveOrUpdate();
脱管态→瞬时态
customer.setCust_(null);
注意:saveOrUpdate(保存或更新),如果一个对象是瞬时态对象,它就会执行保存;如果一个对象是脱管态,它就会执行更新。
持久化对象特性
持久化类持久太对象自动更新数据库。

当设置的值与数据可中的值不相同是,会更新数据库中的值;当设置的值与数据库中的值相同是,只发送查询语句,不发送更新语句。
底层原理,依赖了 Hibernate 里面的一级缓存。
Hibernate 的一级缓存
1、什么是缓存
缓存,是一种优化的方式,将数据放到内存中,使用的时候直接从缓存中获取,不用通过存储源。
2、Hibernate 的缓存
Hibernate 框架中提供了优化手段:缓存、抓取策略。Hibernate 中提供了两种缓存机制:一级缓存、二级缓存。
Hibernate 的一级缓存,称为是 Session 级别的缓存,一级缓存生命周期与 Session 一致(一级缓存是由 Session 中的一系列 Java 集合构成)。一级缓存为 Hibernate 的内置缓存,不能被卸载。(Hibernate 的二级缓存是 SessionFactory 级别的缓存,需要配置的缓存)。
二级缓存默认是不开启的,想要使用二级缓存需要自己去配置。二级缓存在企业开发中基本不用,Redis 基本可以替代二级缓存。
3、什么是 Hibernate 的一级缓存

4、证明一级缓存的存在

Hibernate 的一级缓存的结构
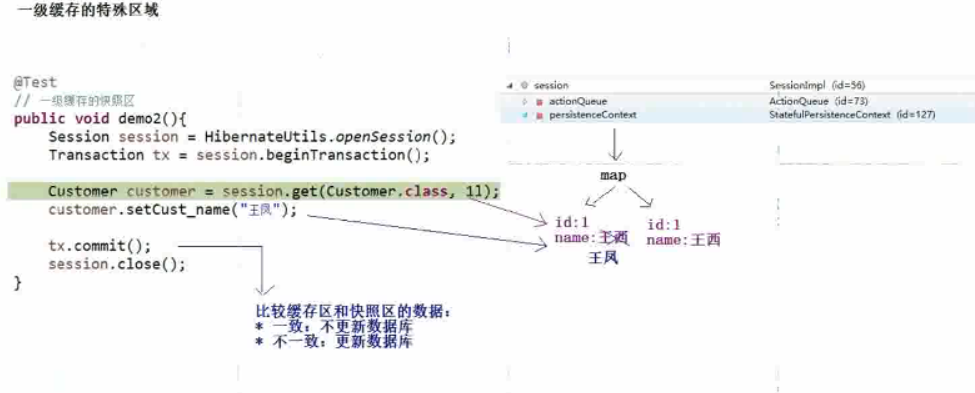
只有了解了它内部的结构,那么就可以明白,为什么持久态对象能够自动更新数据库。其实,依赖的是一级缓存中的一个特殊的区域——快照区。
1、一级缓存中的特殊区域:快照区
快照区会将你放入到一级缓存中的数据进行快照,备份一份,当数据发送变化时,当事务提交的时候,会将一级缓存中的数据跟快照区的数据进行比较。如果数据不一致,它就会自动更新数据库;如果一致,就不会更新数据库了。
session 的一级缓存是由一系列的 Java 集合构成的,主要由
Hibernate3 使用的是一个 map,使用 key 作为一级缓存区,使用 value 作为快照区。
clear()和evict()都可以清空一级缓存,惊喜管理工作。
session.clear(); // 清空所有 session.evict(customer1); // 清除单个对象
Hibernate 事务管理。
(一)、事务的回顾
1、什么是事务
事务:事务指的是逻辑上的一组操作,组成这组操作的各个逻辑单元要么全都成功,要么全都失败。
2、事务特性
原子性:代表事务不可分割。
一致性:代表事务执行的前后,数据的完整性保持一致。
隔离性:代表一个事物执行的过程中,不应该受到其它事物的干扰。
持久性:代表事务执行完成后,数据持久到数据可中(事务执行完毕指的是,事务提交或回滚)。
3、如果不考虑隔离性,引发安全性问题
读问题
脏读:一个事务读到另一个事务未提交的数据。
不可重复读:一个事务读到另一个事务已经提交的 update 数据,导致在前一个事务多次查询结果不一致。
虚读(幻读):一个事务读到另一个事务已经提交的 insert 数据,,导致在前一个事务多次查询结果不一致。
写问题(了解)
引发两类丢失更新
4、读问题的解决
设置事务的隔离级别
Read uncommitted:以上问题都会发生。
Read commited:解决脏读,但是不可重复度和虚读有可能发生(Orcle 默认)。
Repeatable read:解决脏读和不可重复读,但是虚读有可能发生(MySQL 默认)。
Serializable:解决所有读问题(安全性最高,但效率最低)。
(二)、Hibernate 中设置事务隔离级别
Hibernate 中设置事务隔离级别

(三)、Service 层事务
由于事务通常加载在 Service 层,所以事务通常也被称为 Service 层事务。
为什么要把事务加载 Service 层:
持久层通常也叫做 DAO(数据访问对象),DAO 中封装的对数据源的单个的操作(查询是一个,修改是一个,保存是一个,都是单独的方法),所以通常在 DAO 的一个写法是这样的:假设 DAO 中有一个方法 xxx(),在这个方法中需要链接数据库,做一些相关的操作。把事务加载这里面是最方便的,因为 JDBC 的时候,需要在这里获得连接,事务管理通过 connection 这个对象来管理,把事务加在这里很简单。但是这是不行的,因为它(DAO)里面封装的都是单个的操作,而 Service 层(业务层)做得才是一个业务逻辑。Service 层中才会封装业务逻辑的操作,一个业务可能调用多个 DAO,它要保证 DAO的多个 单个操作 一起成功。
什么叫做一个业务呢?比如转账,转账整个叫做一个业务,这一个业务 可能调用多个 DAO,有可能在 Service 层的一个转账方法当中,有可能会调用 DAO1 里面的一个操作,又去调用 DAO2 里面的操作,才能完成一个业务。因为需要保证两个 DAO 的单个操作是一起成功,一起失败,所以说事务应该加在业务层。
但是出现一个问题,DAO1 里面需要获得一个 connection,DAO2 里面也需要获得一个 connectionn。当然,现在用的是 HIbernate 了 ,所以都需要获得一个 session。那么,怎么保证 DAO1 里面和 DAO2 里面用的 session 是同一个?在 Service 层中的方法里开启事务了,开启事务需要用到连接,那么怎么保证外边用到的连接和 DAO1 里面,还有 DAO2 里面用到的连接是同一个。必须保证连接是同一个,如果开启事务用到一个连接,DAO 中用到另外一个连接,那它(DAO)会被 事务管理吗?(不可能)
必须保证连接对象是同一个,在 JDBC 那里需要保证 connection 是同一个,在 HIbernate 这里需要保证 session是同一个。JDBC 有两种解决办法,一是向下传递,就是在外边获得了一个连接,把它传到 DAO1/DAO2 中,直接使用这个连接,是最简单的方法,也是 DBUtils 在进行事务管理时所采用的一种方法;二是使用 ThreadLocal 对象,它是一个绑定线程的对象,在当前方法中需要获得连接(aaa 方法),将这个连接绑定到线程中,就是绑定到ThreadLocal 对象。外边是一个请求过来的,那也就是说它在同一个线程里面,在 DAO 的方法中,通过当前的线程获得到连接对象,这样就能保证它们是同一个连接 。
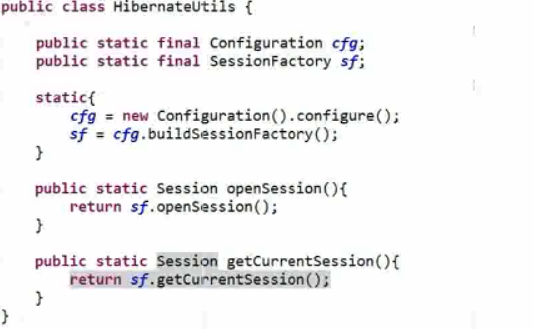
JDBC 那里由事务管理,在业务层加事务就必须要绑定 ThreadLocal 对象;但是在 Hibernate 中,它作为一个框架,内部已经绑定好了 ThreadLocal 对象。在 SessionFactory 中提供了 getCurrentSession() 方法;获取当前线程中的 session,但这个方法默认不能用(之前使用的openSeesion 不需要配置),需要通过一个配置来完成。只要把它配好了,调用这个方法,它会创建一个 session 对象,并绑定到 ThreadLocal 对象上(不再需要手动绑定了,HIbernate 底层已经绑定好了,直接使用即可)。
但是要使用需要配置,并且调用 getCurrentSession() 方法
1、改写工具类
第一步需要改写工具类,因为工具类里面,并没有 getCurrentSession() 这个方法。找到工具类,再提供一个静态方法,返回 Seddion。但是现在调用会出错,因为默认没有开启这个方法。这就与线程绑定了,只要一获得,它就帮你绑定到当前线程中。也可以自己手动绑定,但是比较麻烦。
2、配置完成
第二步需要配置完成,因为默认这个方法不能用 ,需要区配置,再核心配置文件中去配置。

HIbernate 里面提供了 这几个值:
thread:就是与当前线程绑定了
jta:就是与 JTA 的事务绑定(跨数据库的事务,往 Orcle 中做了一个操作,往 MySQL 中做了一个操作,需要保证它们两个在一个事务里面)
在 hibernate.cfg.xml 中进行如下配置 :
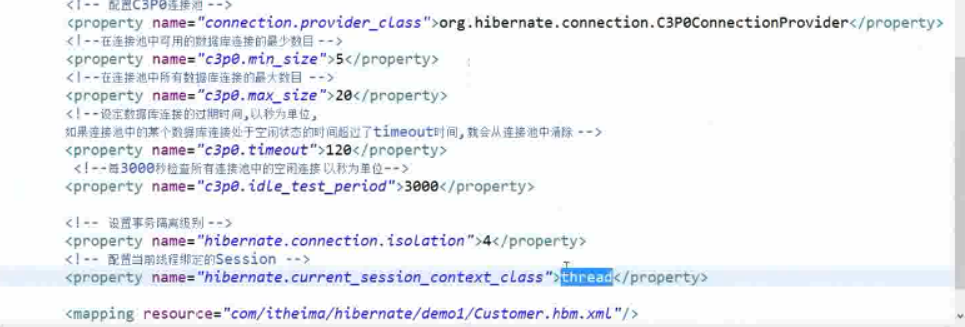
配置完成后,在以后去使用 getCurrentSession(),就可以直接使用了。而且 getCurrentSession() 方法,可以不需要 session.close(),线程结束,会自动关闭 session,自动就释放掉了。一旦关闭就会报错,当线程结束的时候已经关闭了,再次关闭就会报错。
开始的时候,一创建它就绑定到当前线程;当当前线程执行完以后,就会把这个 Session 销毁。
HIbernate 的其他的 API
前两个可以做一些查询、条件查询的操作 。
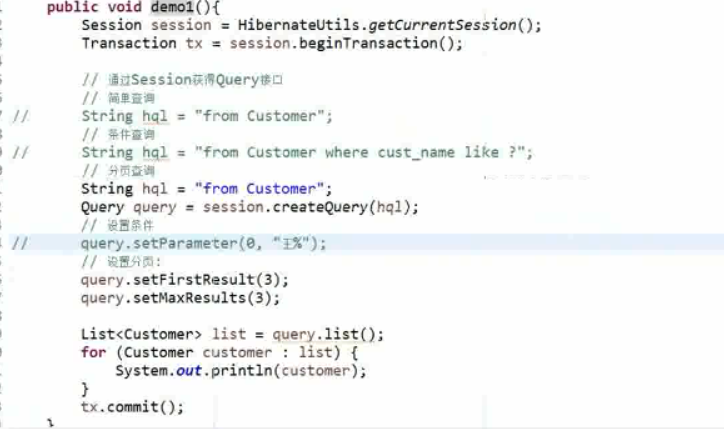
1、Query

Query 接口用于接收HQL,查询多个对象。HQL 是 ,这种语言与 SQL语法非常类似,是面向对象的查询语言。
通过 Session 获得 query 接口,Query query = session.creatQuery();通过这个方法才能获得一个 query 对象,方法里面接收的是一个 HQL语句。
变量参数是一个字符串类型,可以使用query.setString(),还可以使用 query.setParameter(arg0, arg1),这就不需要在意类型了,什么类型都可以。之前是从1开始的,HIbernate 里面是从0开始的。可以是query.setParameter(0, "王%"),, 也
SQL 语句不用自己写,自己写了带有 limit 的语句,想要换成 Orcle 的数据库,就不能用了。所以说 HIbernate 的分页 查询,只需要调用方法即可。query.setFirstResult(arg0) 就代表 limit 的第一个参数,query.setMaxResults(),每页显示多少条记录。默认从0开始,那么limit 语句中0可以省略,limit就只要一个参数。
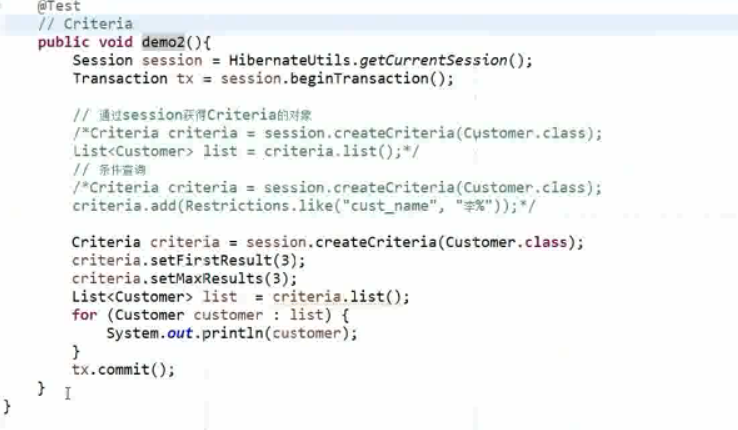
2、Criteria(条件查询)
Criteria:QBC(Query By Criteria),criteria 就是条件的意思。更加面向对象的一种查询方式,看不到类似 HQL语句的写法。
通过 session 获得 Criteria 的对象,用 Criteria criteria = session.creatCriteria();,里面只需要写 Customer.class 就可以返回一个 Criteria 的接口。
设置条件,可以用 ciriteria.add();,里面就可以加条件了,比如查询姓“王”的,写 ciriteria.add(Restrictions.like(propertyName, value));,like() 第一个参数可以写属性名。当二个参数没有标明匹配模式时还可以写第三个参数,选择匹配模式。
3、SQLQuery(了解 )
接收一个 SQL 语句(就是 SQL 查询),特别复杂的情况下需要使用 SQL。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号