《Non-local Neural Networks 》——笔记
Non-local Neural Networks
卷积(convolutional)运算和循环(recurrent)运算都是对局部区域的处理。受计算机视觉中的非局部均值方法的启发,论文中提出一种非局部操作去捕捉远程依赖,用来建立较远位置的数据之间的关系。
比如在卷积网络中,我们虽然可以通过叠加多个卷积层来捕捉远程依赖,但是这样有三个问题:
1、计算效率低
2、优化更加困难
3、当信息需要在远距离位置来回传递时,多跳模型难以实现(不太理解)
定义神经网络中的非局部运算的一般形式是:
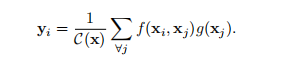
i:输出位置的索引 (在空间、时间、时空中的位置)
j:枚举所有位置的索引
x:输入信号 (图像、序列、视频;通常是他们的特征)
y:size和x相同的输出信号
f:计算两个位置之间的相关性
g:输入的映射表达
c:归一化参数
论文中给出f和g的几种形式,为了简化,只考虑g是线性的情况,即:
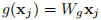
\(W_{g}\)是一个学习的权重矩阵,执行的时候是通过1x1的空间上的卷积或者1x1x1的时空上的卷积。
Gaussian
遵循非局部平均和双边滤波器,f的一个选择是高斯函数。
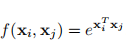
\(x_{i}^{T}x_{j}\)是点积相似性,也可以使用欧氏距离,但是在深度学习平台中前者更容易实现。
归一化参数:
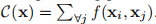
Embedded Gaussian
高斯函数的一个简单扩展是计算嵌入空间中的相似性。
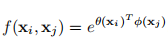
\(θ(x_{i}) = W_{θ}x_{i}\) 和 \(φ(x_{j}) = W_{φ}x_{j}\)是两个嵌入,\(W_{θ}\)和\(W_{φ}\)也是通过1 x 1或者1 x 1 x 1的卷积实现的。
归一化参数:
self-attention模块其实就是non-local的embedded Gaussian版本的一种特殊情况。修改:
\(y = softmax(x^{T} W^{T}_{θ} W_{φ}x)g(x)\),得到结构图如下:
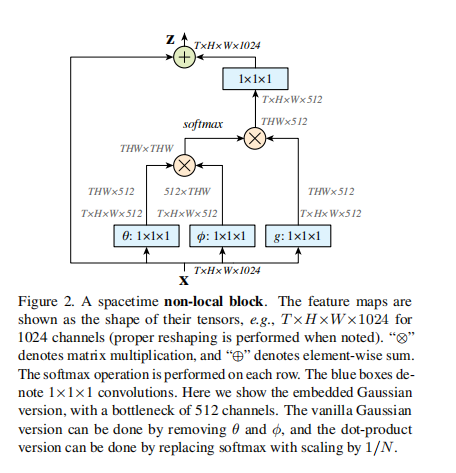
图中给出的是时空维度上的一个 non-local block,我们在处理图像的时候只需要将1x1x1的时空卷积改成1x1的空间卷积即可。
普通的高斯版本可以将图中θ、φ模块去掉来得到,点积版本(Dot product)可以通过将softmax改为1/N缩放来得到。
Dot product
f可以定义为点积相似性:
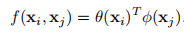
在这种情况下,归一化因子设置为\(C(X)=N\),其中N是x中的位置数,而不是f的和,因为它简化了梯度计算。 Dot product版本和Embedded Gaussian版本的主要区别是Softmax的存在,Softmax起着激活函数的作用。
Concatenation
这里就是将两个输入进行concat起来之后进行映射和激活操作。
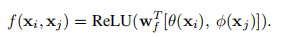
[.,.]表示的是concat,\(w_{f}\)是能够将concat的向量转换成一个标量的权重向量。这里设置\(C(x)=N\)。
简单实现了一个Embedded Gaussian版本,使用的二维卷积,用于图像问题当中:
import torch
import torch.nn as nn
import torch.nn.functional as F
class EmbeddedGaussian(nn.Module):
def __init__(self,in_channels):
super(EmbeddedGaussian,self).__init__()
self.in_channels = in_channels
self.hide_channels = self.in_channels//2 if self.in_channels >= 2 else 1 #一般设置theta、phi、g这三个部分的卷积核个数为输入通道的一半。
self.theta = nn.Conv2d(in_channels=self.in_channels, out_channels=self.hide_channels,
kernel_size=1, stride=1, padding=0)
self.phi = nn.Conv2d(in_channels=self.in_channels, out_channels=self.hide_channels,
kernel_size=1, stride=1, padding=0)
self.g = nn.Conv2d(in_channels=self.in_channels, out_channels=self.hide_channels,
kernel_size=1, stride=1, padding=0)
self.reshape_conv = nn.Conv2d(in_channels=self.hide_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0) #用来恢复通道数目,方便后面的shortcut。
def forward(self,x):
'''
x : (b,c,h,w)
theta_out : (b,hw,c)
phi_out : (b,c,hw)
g_out : (b,hw,c)
theta_pui_out : (b,hw,hw)
'''
b,h,w = x.shape[0],x.shape[2],x.shape[3]
theta_out = self.theta(x).reshape(b,self.hide_channels,h*w)
theta_out = theta_out.permute(0,2,1) #调换维度,使theta_out维度由(b,c,hw) 变为 (b,hw,c) 后面代码同理
phi_out = self.phi(x).reshape(b,self.hide_channels,h*w)
g_out = self.g(x).reshape(b,self.hide_channels,h*w)
g_out = g_out.permute(0,2,1)
theta_pui_out = torch.matmul(theta_out,phi_out)
theta_pui_out = F.softmax(theta_pui_out,dim=-1)
out = torch.matmul(theta_pui_out,g_out).permute(0,2,1)
out = out.reshape(b,self.hide_channels,h,w)
out = self.reshape_conv(out)
out = x + out
return out
各个版本的完整代码可以从https://github.com/AlexHex7/Non-local_pytorch查看

