Redis 的那些事儿
一、官方定义 Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value) 非关系型 存储数据库,并提供多种语言的 API。
Redis 通常被称为数据结构服务器,因为值(value)可以是字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets)等类型。
二、Redis数据类型应用场景:
1、String 最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存。
2、hash value存放的是结构化的对象,比较方便的就是操作其中的某个字段。
3、list 使用List的数据结构,可以做简单的消息队列的功能;可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。
4、set 因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。
5、sorted set 多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。可以用来做延时任务、做范围查找。
三、Redis过期策略的几种选择:
1)定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略
2)定期删除,redis默认每隔100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每隔100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。
因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
3)定期+惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。这时就需要用到内存淘汰机制来处理过期的key。
内存淘汰机制选择:
redis.conf 配置信息
# maxmemory-policy volatile-lru 内存淘汰机制
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。不做移除操作。
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。不推荐
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐
ps:如果没有设置过期 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
四、Redis常见问题:
(一)缓存和数据库双写一致性问题
一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。
如果对数据有强一致性要求,不能放缓存;我们所做的一切,只能保证最终一致性。我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。
解决方法:首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
(二)缓存雪崩问题
指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
处理办法:
1)缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
2)一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。
3)给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
(三)缓存穿透
缓存穿透是指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍,然后返回空。
如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至击垮数据库系统。
处理办法:
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短一点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力。
(四)缓存击穿问题
是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库
处理办法:
1)、使用互斥锁(mutex key)
这种思路比较简单,就是让一个线程回写缓存,其他线程等待回写缓存线程执行完,重新读缓存即可。
同一时间只有一个线程读数据库然后回写缓存,其他线程都处于阻塞状态。如果是高并发场景,大量线程阻塞势必会降低吞吐量。
如果是分布式应用就需要使用分布式锁。
2)热点数据永不过期
永不过期实际包含两层意思:
物理不过期,针对热点key不设置过期时间逻辑过期,把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建;
不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,对于不追求严格强一致性的系统是可以接受的。
(五)缓存的并发竞争问题
不同客户端 同时并发请求更新同一个KEY,那么本来应该先到数据库的数据结果后来到了,只要顺序错了,数据库数据就错了。
处理方法:
第一种方案:分布式锁+时间戳
1).整体技术方案
这种情况,主要是准备一个分布式锁,大家去抢锁,抢到锁就做set操作。
加锁的目的实际上就是把并行读写改成串行读写的方式,从而来避免资源竞争。
2).Redis分布式锁的实现
主要用到的redis函数是setnx()
用SETNX实现分布式锁
利用SETNX非常简单地实现分布式锁。例如:某客户端要获得一个名字youzhi的锁,客户端使用下面的命令进行获取:
SETNX lock.youzhi<current Unix time + lock timeout + 1>
如返回1,则该客户端获得锁,把lock.youzhi的键值设置为时间值表示该键已被锁定,该客户端最后可以通过DEL lock.foo来释放该锁。
如返回0,表明该锁已被其他客户端取得,这时我们可以先返回或进行重试等对方完成或等待锁超时。
3).时间戳
由于上面举的例子,要求key的操作需要顺序执行,所以需要保存一个时间戳判断set顺序。
系统A key 1 {ValueA 7:00}
系统B key 1 { ValueB 7:05}
假设系统B先抢到锁,将key1设置为{ValueB 7:05}。接下来系统A抢到锁,发现自己的key1的时间戳早于缓存中的时间戳(7:00<7:05),那就不做set操作了。
第二种方案:利用消息队列
在并发量过大的情况下,可以通过消息中间件进行处理,把并行读写进行串行化。
把Redis.set操作放在队列中使其串行化,必须的一个一个执行。
这种方式在一些高并发的场景中算是一种通用的解决方案。
五、其他问题
缓存预热:
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统,这样就可以避免在用户请求的时候,先查询数据库,然后再将数据回写到缓存。
如果不进行预热, 那么 Redis 初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
处理方法:
- 数据量不大的时候,工程启动的时候进行加载缓存动作;
- 数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
- 数据量太大的时候,优先保证热点数据进行提前加载到缓存。
缓存降级:
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。
在项目实战中通常会将部分热点数据缓存到服务的内存中,这样一旦缓存出现异常,可以直接使用服务的内存数据,从而避免数据库遭受巨大降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。
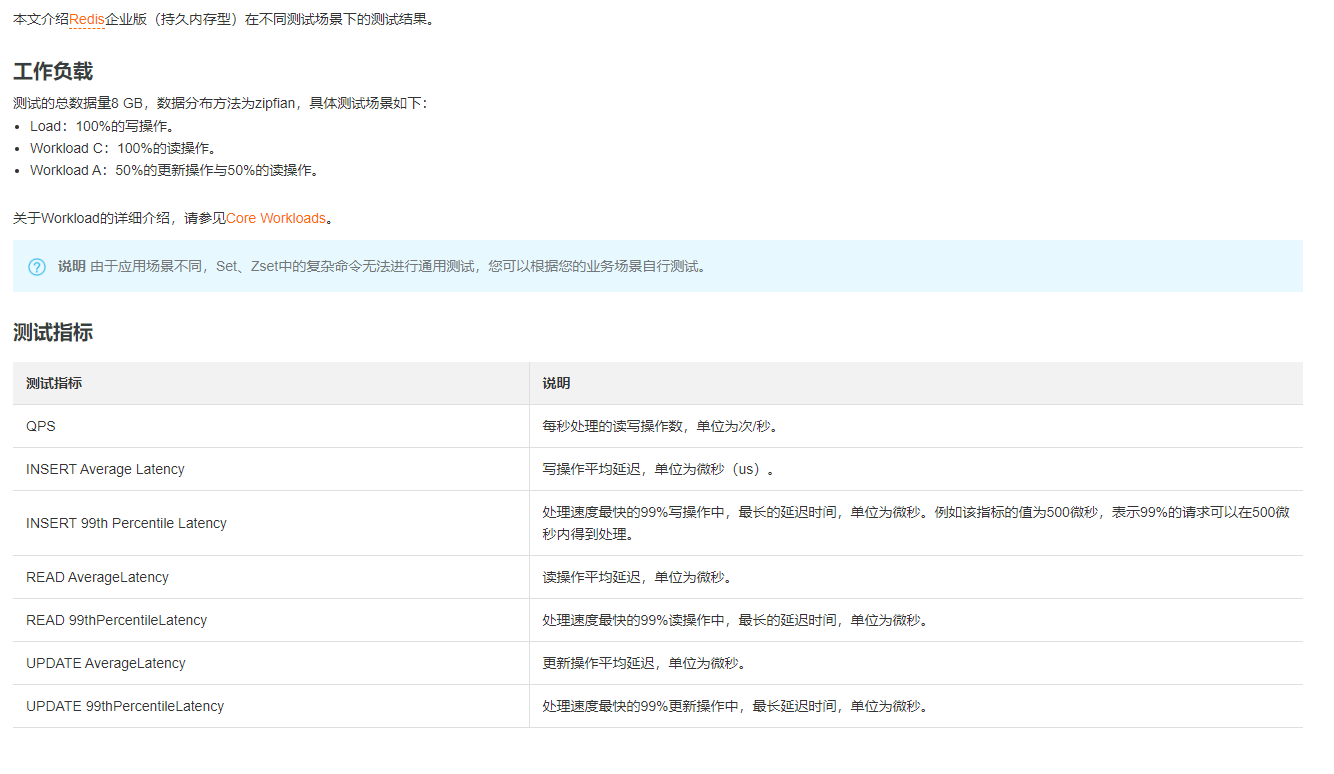
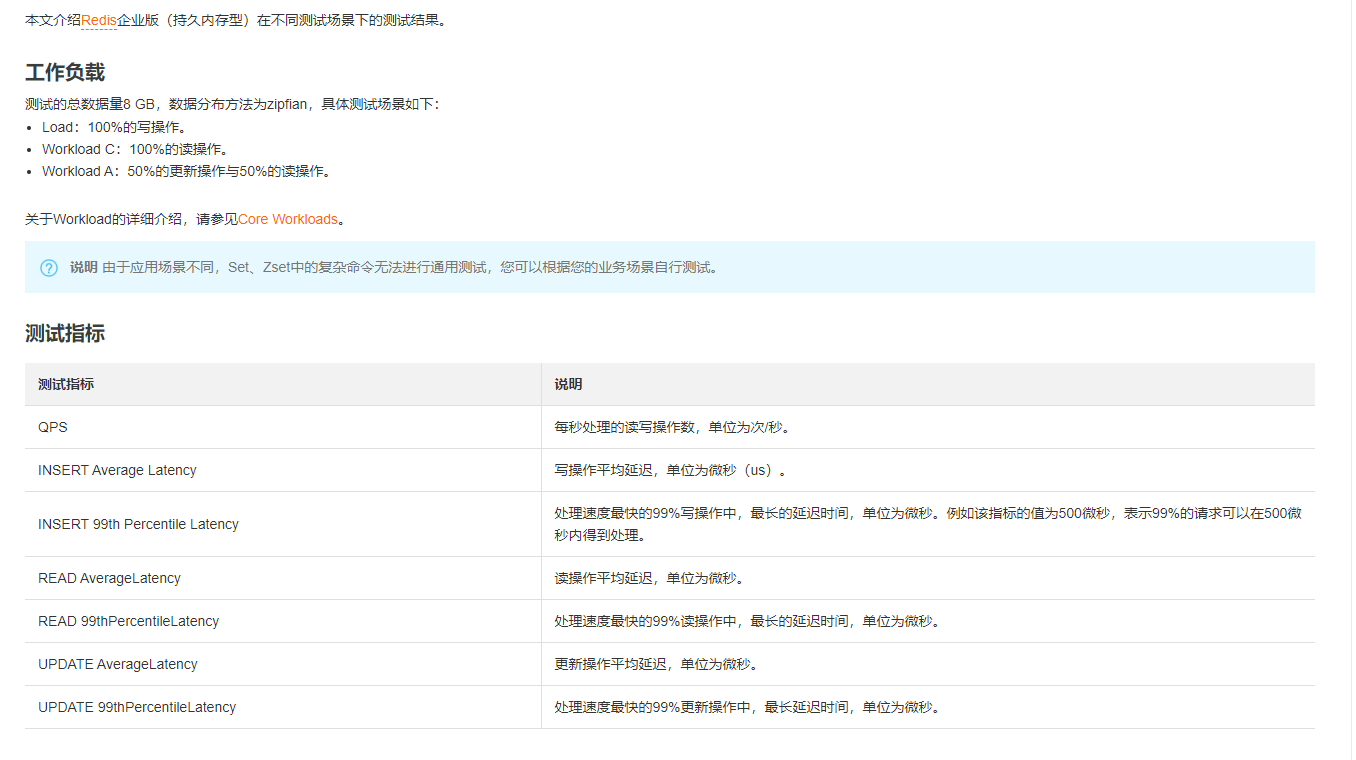
Redis性能测试工具:memtier_benchmark是Redis Labs推出的命令行工具,可用于在键值存储数据库中生成数据负载并进行压力测试。
前提条件
您的Linux系统已安装以下库或工具。
- Git
- libevent 2.0.10或更高版本
- libpcre 8.x
- autoconf
- automake
- GNU make
- GCC C++ compiler
如果缺少以上组件,您可以按照以下步骤进行安装:
说明:本文中的安装环境为阿里云ECS实例中的CentOS 7.2系统,其它系统的安装方法此处不做详细介绍。
- 执行如下命令,安装Git。
yum install git
- 安装编译所需的工具。
yum install -y autoconf automake make gcc-c++ git
- 安装部分需要的库。
yum install -y pcre-devel zlib-devel libmemcached-devel openssl-devel libevent-devel
- 如您系统中的libevent库不符合要求,下载并安装libevent-2.0.21。
wget https://github.com/downloads/libevent/libevent/libevent-2.0.21-stable.tar.gz
tar xfz libevent-2.0.21-stable.tar.gz
pushd libevent-2.0.21-stable
./configure
make
sudo make install
popd - 设置PKG_CONFIG_PATH使configure能够发现前置步骤安装的库。
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:${PKG_CONFIG_PATH}
下载和安装
- 使用Git将memtier-benchmark的源文件克隆到本地目录。
git clone https://github.com/RedisLabs/memtier_benchmark.git
- 执行以下命令,进入指定目录。
cd memtier_benchmark
- 编译和安装memtier-benchmark。
autoreconf -ivf
./configure
make
make install
测试方法
测试命令示例及常用选项说明如下
./memtier_benchmark -s r-XXXX.redis.rds.aliyuncs.com -p 6379 -a XXX -c 20 -d 32 --threads=10 --ratio=1:1 --test-time=1800 --select-db=10
-s --server:代表服务器地址,默认localhost
-p --port:代表端口,默认为redis的6379端口
-x --run-number:代表完整测试的重复次数
--client-stats=file:生成每个客户端的统计文件
--out-file=file:生成最后的统计结果
-n --request:每个客户端发出的请求数,默认是10000
-c --clients:每个线程驱动的客户端数量,默认是50
-t --thread:模拟的线程数量,默认是4
--test-time:测试的时间,这里时间最好不要太短,否则有可能捕捉不到bad case
--ratio=Ratio:set和get请求的比例,默认是1:10
--data-size:对象数据大小,默认是32
-R、--random-data:使用随机化的测试数据
--data-size-range:数据对象大小范围,可以写成32-512,代表32字节到512字节
--data-size-list:这个参数比较关键,它可以帮助你去对key值的大小进行配比,按照一定的比例去模拟key值,关于这个参数,手册上没有很清楚的讲述,也是查看了日本一位作者的测试报告才看到的,举例如下:
--data-size-list=4000:50,16000:50
上面的样例代表4k大小的key值占比50%,16k大小的key值占比50%,当然,你可以增加到3个key,只要权重的和是100%即可
--data-size-pattern=R|S 这个参数的取值只能是R或者S,R代表random,S代表sequence,试想,如果你的数据对象大小是在32-512字节之间,如何分配所有的字节大小呢?该参数就是帮你解决这个问题,配置成R,则会随机的在这个定义好的范围内去取值,配置成S则会顺序均匀生成32-512大小的key
有了上面的参数说明,我们现在可以看一个完整的命令怎么写了:
memtier_benchmark -s 127.0.0.1 -p 6379
--threads=4 --clients=100
--data-size-list=4000:50,512000:50
--test-time=1800
--ratio=1:10
--client-stats=/dir/client --out-file=/dir/result.txt
上面的命令代表:
测试本地6379端口,模拟并发线程4个,每个线程驱动100个客户端,其中4k大小的key占比50%,512k大小的key占比50%,总共测试1800s,读写比例10:1,将每个客户端的日志保存在/dir/client.txt中,将总的结果保存在/dir/result.txt中。
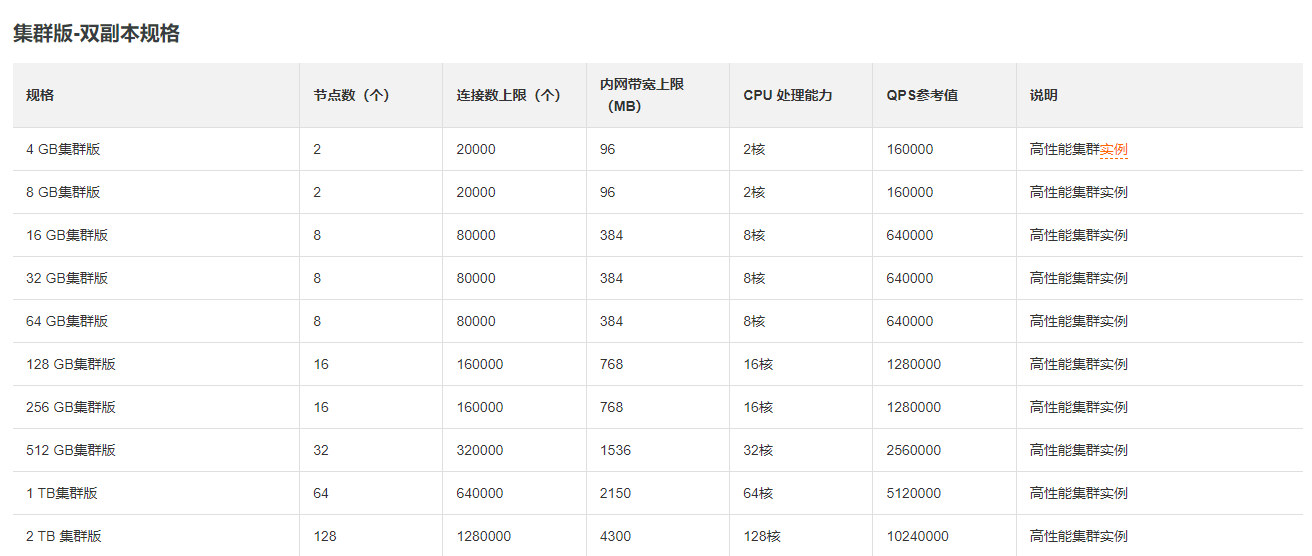
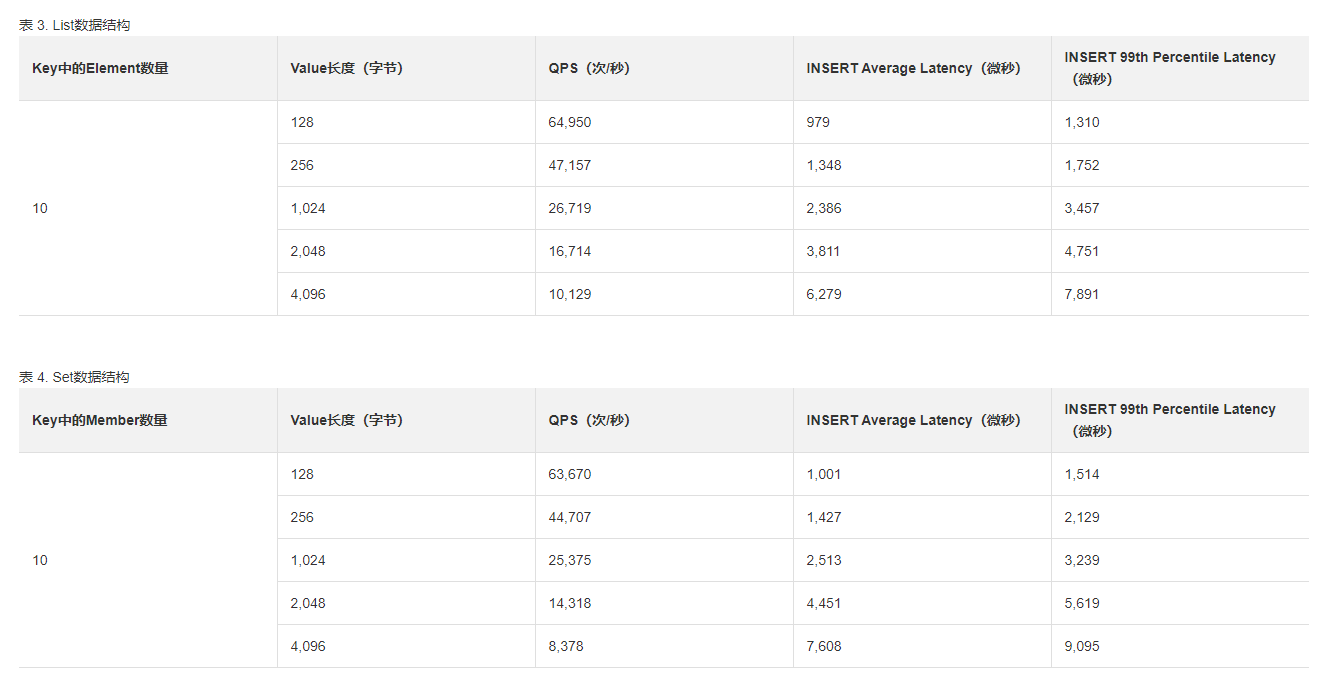
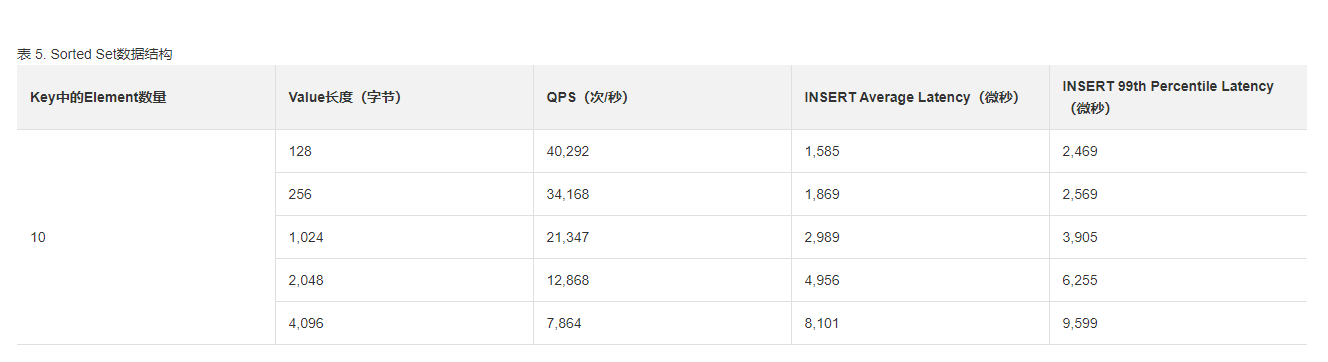
阿里云Redis 集群版 双副本的 性能参数:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号