
cuda
通讯模式:多个线程合作解决一个问题,常见的合作模式称为Communication Patterns
- 映射:map
- 聚合:gather
- 分散:scatter
- 模板:stencil
- 转换:transpose
- 压缩:reduce
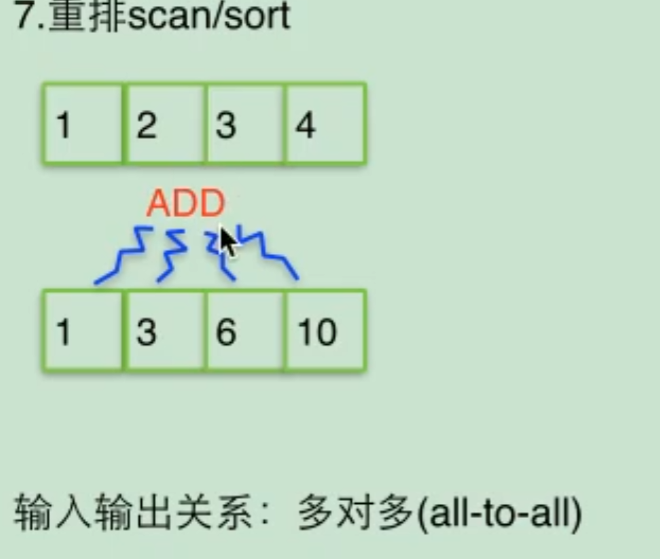
- 重排:scan/sort
cuda编程的特点:
对线程块在何处、何时运行不做保证
- 对于哪个块在哪个SM上运行无法做出任何假设,
- 无法获取块之间的明确通讯
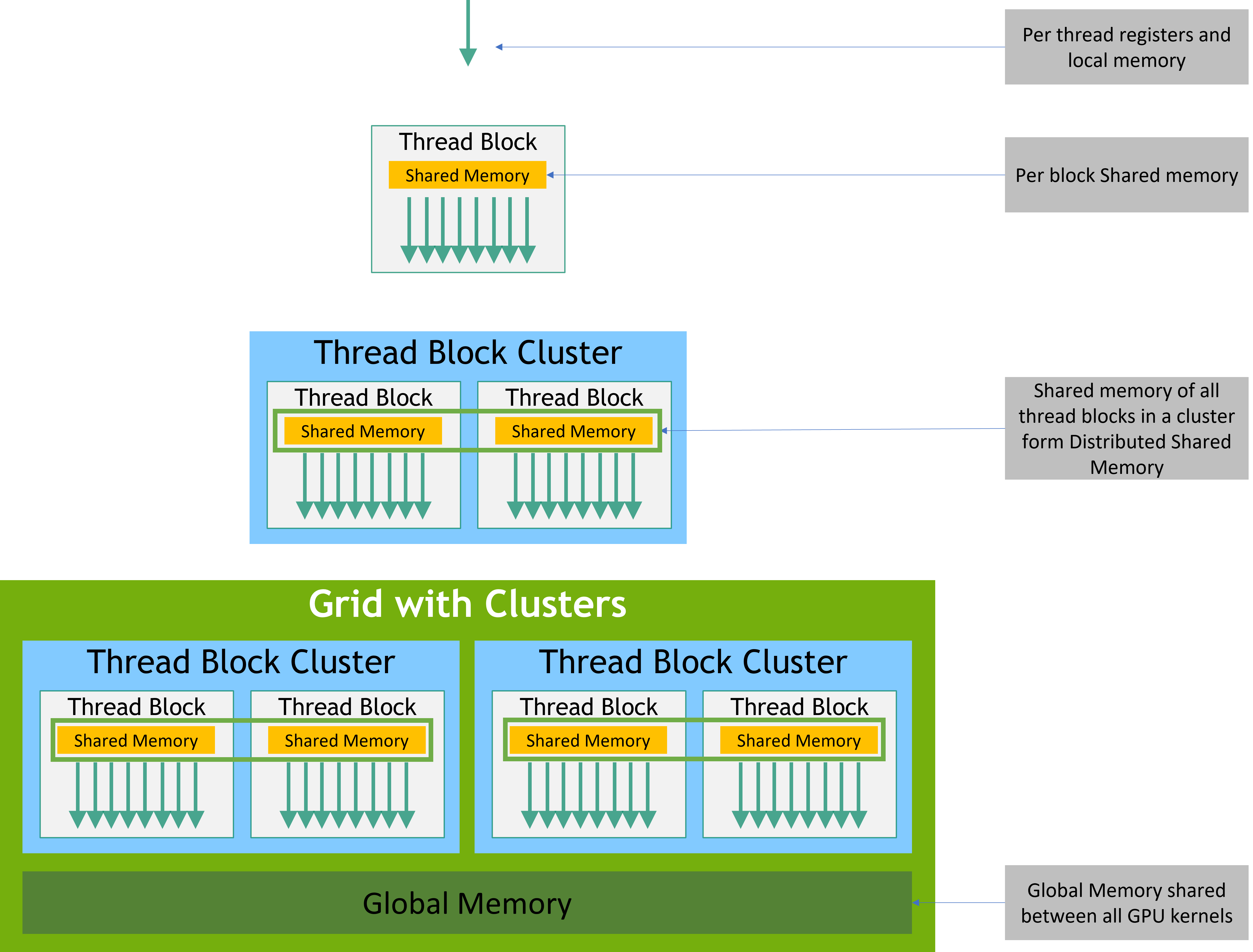
共享内存是在SM(Streaming Multiprocessor)内部的,一个线程块(block)在启动时,申请的共享内存不能超过 SM 上剩余的共享内存。通常CUDA编译器默认给一个block最多分配48KB,超过就launch失败!如果想要大共享内存,通常要指定 extern shared 的方式动态申请,并且调整launch参数。
获取每个SM和线程块最大共享内存大小
#include <stdio.h>
int main(int argc, char** argv) {
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, 0);
printf("Shared memory per block: %d bytes\n", prop.sharedMemPerBlock);
printf("Shared memory per SM: %d bytes\n", prop.sharedMemPerMultiprocessor);
}
Shared memory per block: 49152 bytes
Shared memory per SM: 102400 bytes
每个block申请多少共享内存 | 一个SM最多能并行多少block?
48KB | 大概2个block(因为48KB×2=96KB,还剩一点点)
24KB | 大概4个block
8KB | 大概12个block
知识是我们已知的
也是我们未知的
基于已有的知识之上
我们去发现未知的
由此,知识得到扩充
我们获得的知识越多
未知的知识就会更多
因而,知识扩充永无止境

 浙公网安备 33010602011771号
浙公网安备 33010602011771号