爬虫学习第三天
BeautifulSoup
使用BeautifulSoup来解析html页面
import requests
url = "https://python123.io/ws/demo.html"
# 1. 使用requests库
r = requests.get(url)
demo = r.text
#2. 使用BeautifulSoup库
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo, "html.parser")
print(soup.prettify())
BeautifulSoup库的基本元素


import requests
from bs4 import BeautifulSoup
url = "https://python123.io/ws/demo.html"
r = requests.get(url)
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
# 打印title
print(soup.title)
# 打印<a>标签的内容
print(soup.a)
# 打印<a>标签的属性
print(soup.a.attrs)
# 获取<a>标签class属性值
print(soup.a.attrs['class']) # ['py1']
# 获取<a>标签中间的内容
print(soup.a.string)
# 获取<p>标签中间的内容
print(soup.p.string)
# 获取注释内容
newsoup = BeautifulSoup("<b><!--This is a comment--></b><p>This is not a comment</p></b>", "html.parser")
print(newsoup.b.string)
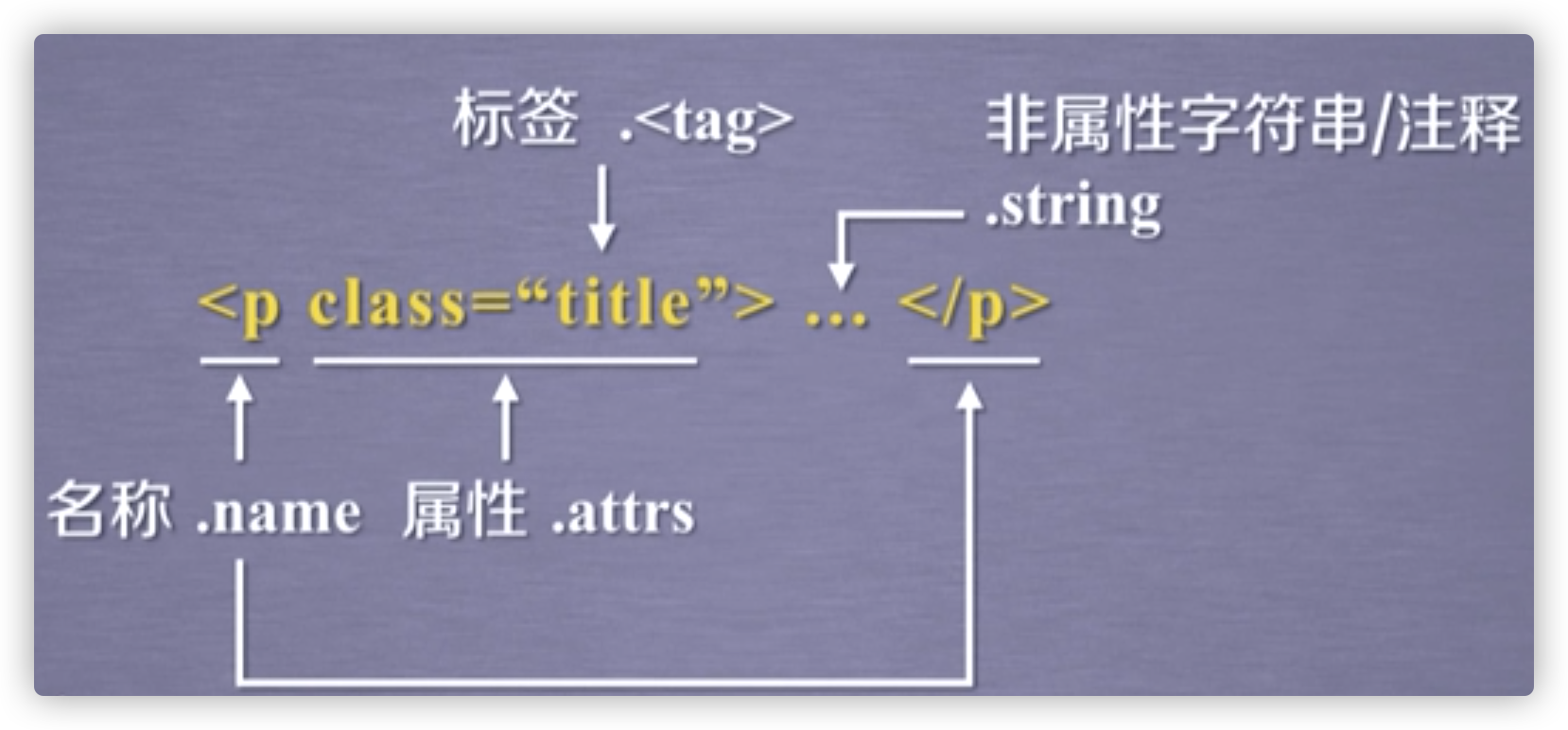
使用bs4遍历HTML内容
HTML的结构,一个树形结构的文本信息,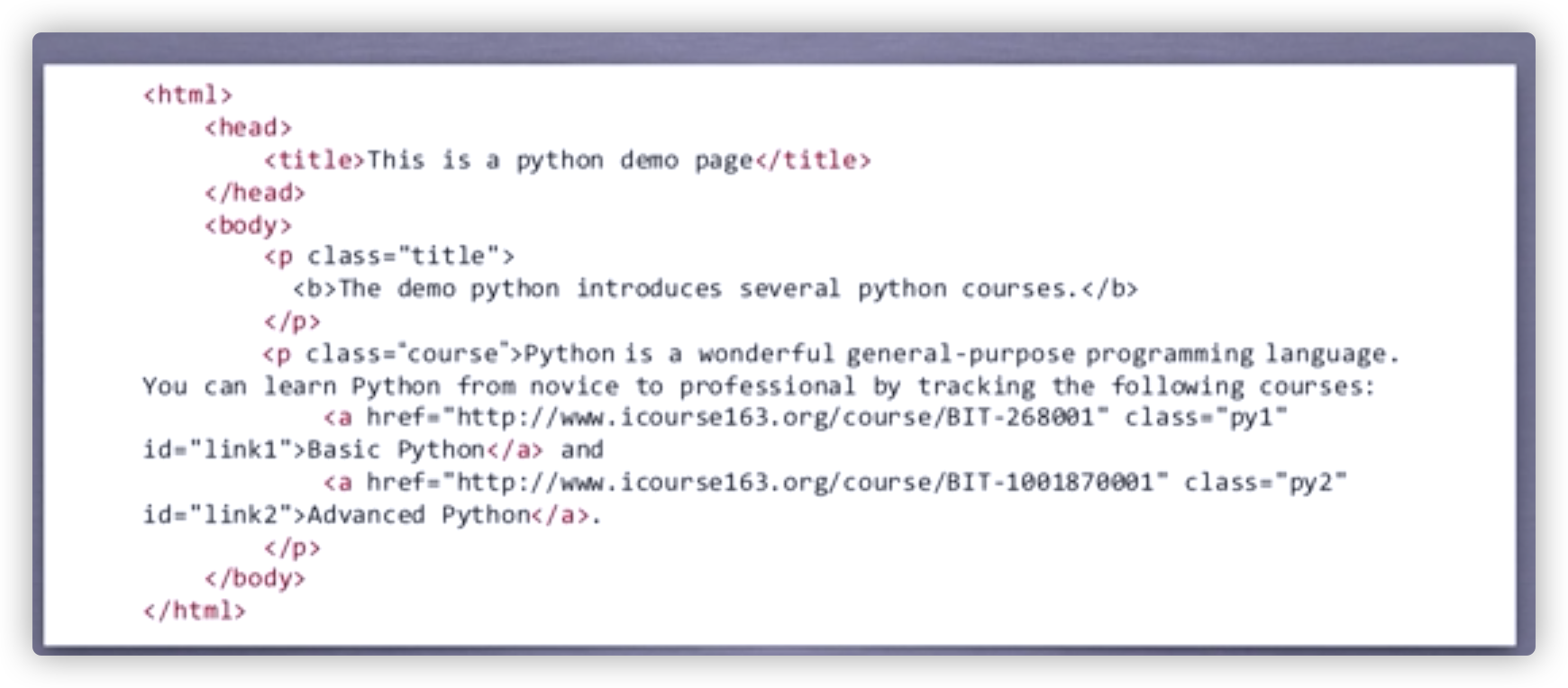 ,或者
,或者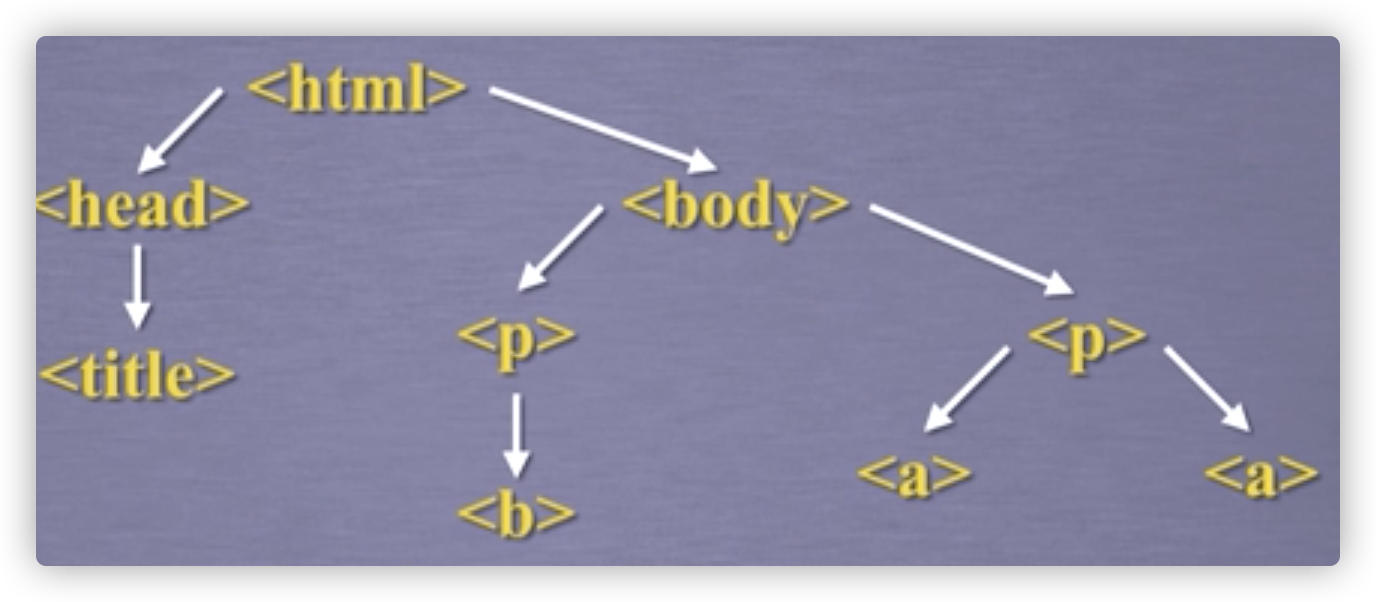
文本也算结点,可能出现在遍历中。
-
下行遍历


-
上行遍历


-
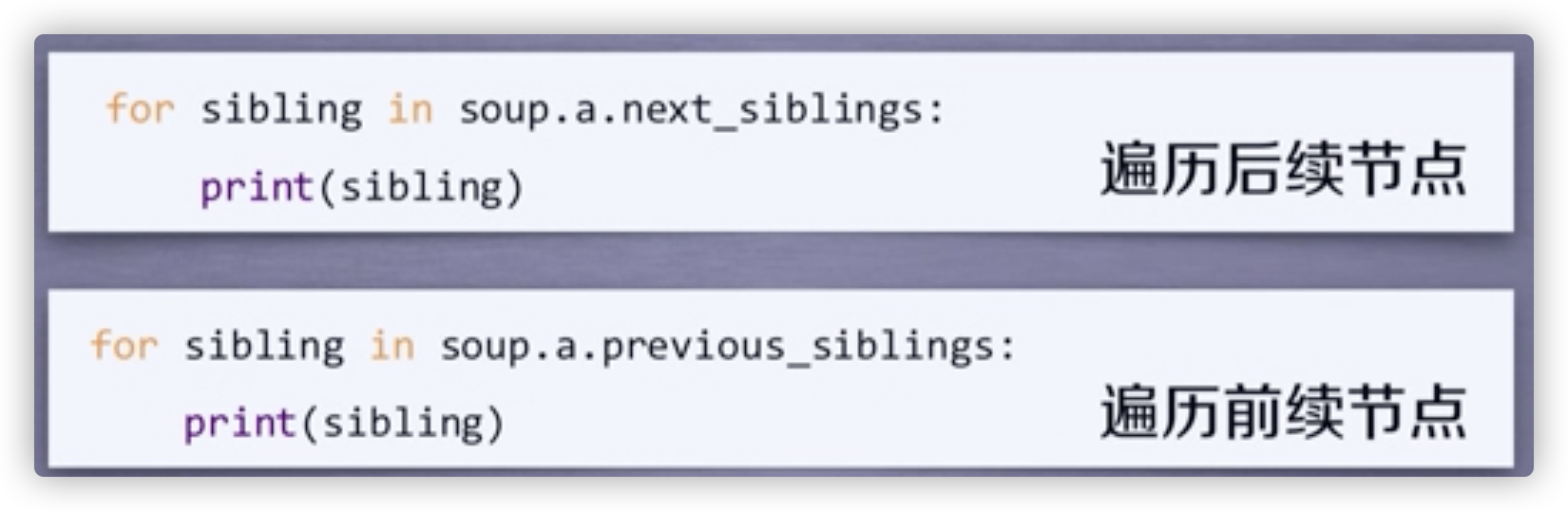
平行遍历
平行遍历必须发生在同一个父亲结点下。

基于bs4的HTML格式化输出
使用prettify()方法。
import requests
from bs4 import BeautifulSoup
url = "https://python123.io/ws/demo.html"
r = requests.get(url)
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
# 格式化输出HTML文件
print(soup.prettify())
