爬虫学习第二天

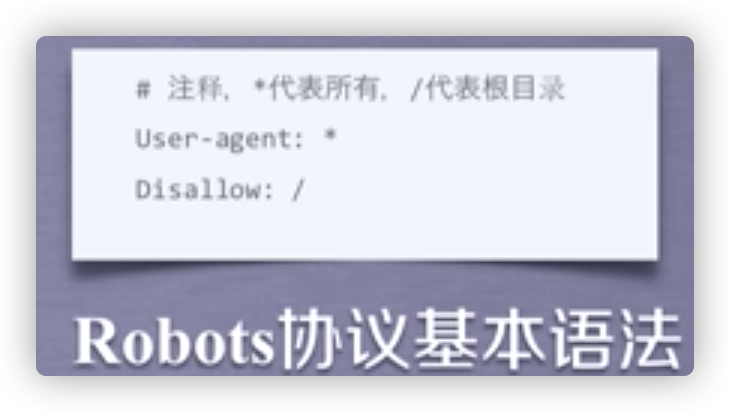
Robots协议
全称网络爬虫排除标准。
作用:告知网络爬虫哪些页面可以爬取,哪些不可以。
形式:在网络根目录下的robots.txt文件。
Ex.查看京东网站的robots.txt文件
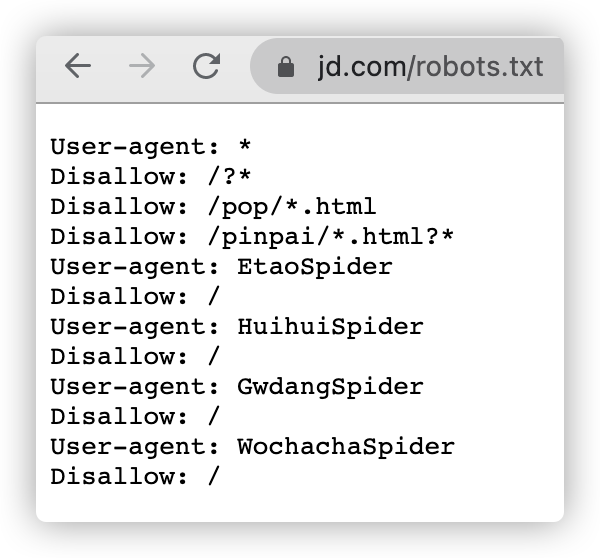
Robots协议的使用
爬虫应该自动识别robots.txt文件,再进行内容爬取。
实战
实战1 --京东商品
显示这个商品的信息(https://item.jd.com/100014205312.html)
import requests
url = 'https://item.jd.com/100014205312.html'
try:
r = requests.get(url)
r.raise_for_status()
print(r.text[:1000])
except:
print('爬取失败')
很遗憾,只能爬取到登录信息。。。
<script>window.location.href='https://passport.jd.com/new/login.aspx?ReturnUrl=http%3A%2F%2Fitem.jd.com%2F100014205312.html'</script>
实战2 --爬取亚马逊商品
url(https://www.amazon.cn/dp/B008IMI036/ref=lp_2142196051_1_1)
import requests
url = 'https://www.amazon.cn/dp/B008IMI036/ref=lp_2142196051_1_1'
try:
r = requests.get(url)
r.raise_for_status()
print(r.text[:1000])
except:
print('爬取失败')
无情,直接爬取失败
查看一下status_code,显示503
再查看一下User-Agent,
{'User-Agent': 'python-requests/2.25.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}可以看到,直接就是python-requests,那么网站完全可以拒绝掉。
那么能不能模拟成浏览器去访问呢?
在使用get函数时,可以替换掉headers。
import requests
url = 'https://www.amazon.cn/dp/B008IMI036/ref=lp_2142196051_1_1'
try:
kv = {'user-agent': 'Mozilla/5.0'}
r = requests.get(url, headers=kv)
r.raise_for_status()
print(r.text[:1000])
except:
print('爬取失败')
这次运行就成功了,输出
<!DOCTYPE html>
<!--[if lt IE 7]> <html lang="zh-CN" class="a-no-js a-lt-ie9 a-lt-ie8 a-lt-ie7"> <![endif]-->
<!--[if IE 7]> <html lang="zh-CN" class="a-no-js a-lt-ie9 a-lt-ie8"> <![endif]-->
<!--[if IE 8]> <html lang="zh-CN" class="a-no-js a-lt-ie9"> <![endif]-->
<!--[if gt IE 8]><!-->
<html class="a-no-js" lang="zh-CN"><!--<![endif]--><head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8">
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<title dir="ltr">Amazon.cn</title>
<meta name="viewport" content="width=device-width">
<link rel="stylesheet" href="https://images-na.ssl-images-amazon.com/images/G/01/AUIClients/AmazonUI-3c913031596ca78a3768f4e934b1cc02ce238101.secure.min._V1_.css">
<script>
if (true === true) {
var ue_t0 = (+ new Date()),
ue_csm = window,
ue = { t0: ue_t0, d: function() { return (+new Date() - ue_t0); } },
ue_furl = "fls-cn.amazon.cn",
ue_mid = "AAHKV2X7AFYLW",
实战3 --百度/360关键字提交
百度的关键字接口是https://www.baidu.com/s?wd=[keyword]
360的关键字接口是https://www.so.com/s?&q=[keyword]
import requests
keyword = 'Python'
try:
kv = {'wd': keyword}
r = requests.get('http://www.baidu.com/s', params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print('爬取失败')
####
http://www.baidu.com/s?wd=Python
691734
实战4 -- 网络图片的爬取和存储
地理网(http://www.natgeo.com.cn/)
import requests
path = "./a.jpg"
url = "http://www.natgeo.com.cn/upload/images/2020/11/d3c334dde2292fe7.jpg"
r = requests.get(url)
with open(path, 'wb+') as f:
f.write(r.content)

