爬虫学习第一天
Requests库入门
使用pip install requests安装包,然后使用import requests来导入包。
Ex.
import requests
r = requests.get("http://www.baidu.com")
print(r.status_code) # 200
r.encoding = "utf-8"
print(r.text) # 网页代码

get方法
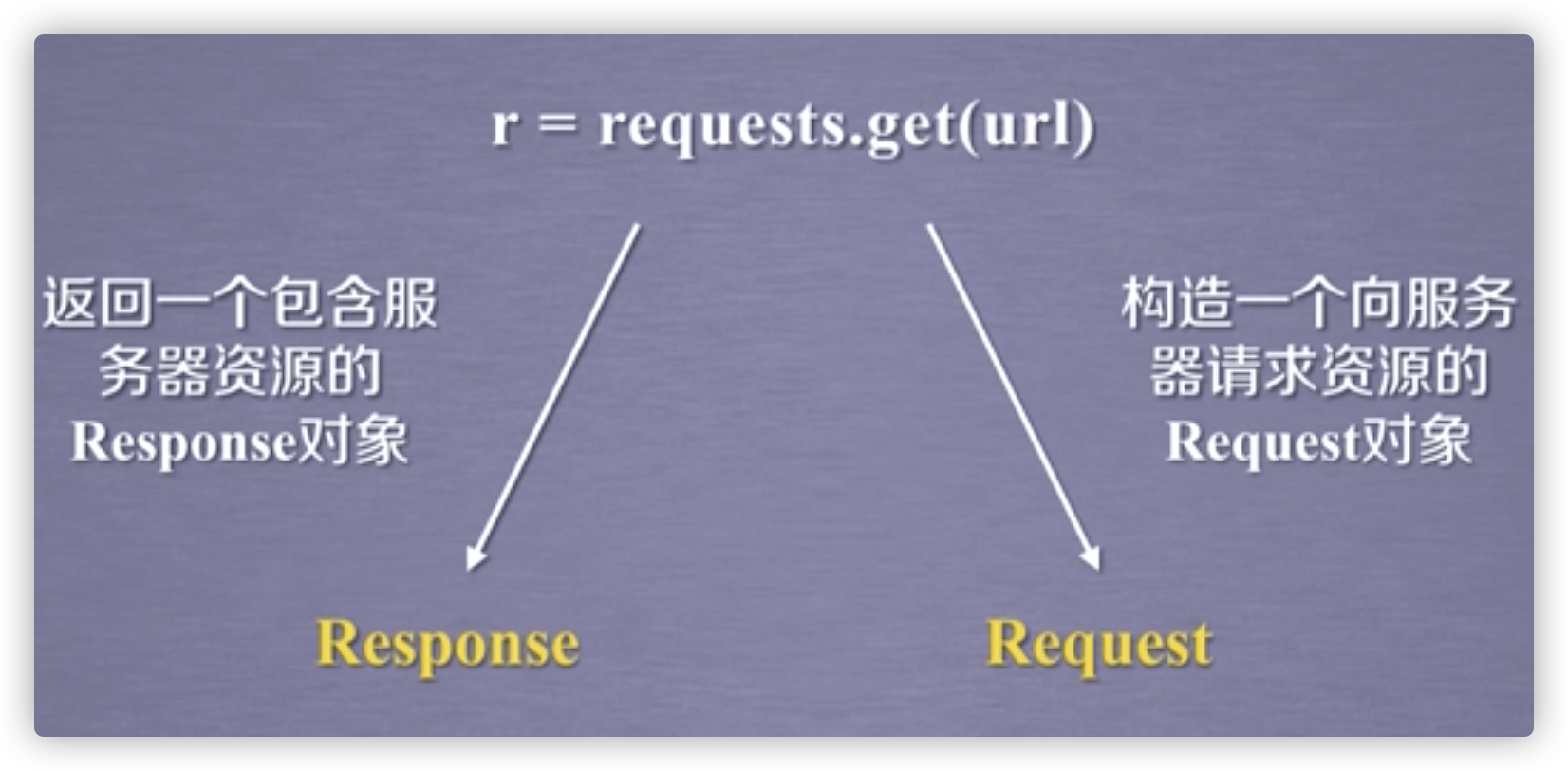


Ex.
爬取百度新闻的内容(https://news.baidu.com/)
import requests
r = requests.get("https://news.baidu.com/")
print(r.status_code) # 200
print(r.encoding, r.apparent_encoding) # utf-8 utf-8
r.encoding = "utf-8"
print(r.text)
网页异常处理
在爬取时出现异常怎么办?


爬虫代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() # 如果状态码不是200,排除HTTPError
r.encoding = r.apparent_encoding
return r.text
except:
return '产生异常'
if __name__ == '__main__':
url = "http://www.baidu.com"
print(getHTMLText(url))
HTTP协议及Requests主要方法




