

oop:面向对象思想 (mvc模式) 自定义一套框架(mvc + mysql())
mysql(高级理论) mysql优化
设计数据库(表的结构设计开始)
一:数据库三大范式
mysql优化
1NF----2NF-----3NF 三大范式
(1):第一范式(1NF 列不可在分 (表里面的数据增加,不要影响原有的数据结构) )
id 部门主管 员工 员工1 员工2 员工3 员工4
1 A a b c u j
2 B 1 2
3 C q w e r
4 D t
id 部门主管 员工
1 A a
2 A b
3 A c
4 A u
5 A j
6 B 1
(2):第二范式(2NF 行不可再分 (降低数据冗余,数据冗余和查询效率成正比)) 数据冗余永远降不到0
外键:主表
主表里面有个字段是附表里面的id字段那么主表里面的这个字段叫外键
id 姓名 年龄 联系电话 地区邮编
1 张三 22 127.。。 1
2 张四 22 127.。。 1
3 可爱 18 135.。。 2
4 王五 23 134。。。 1
5 李四 34 124.。。。 3
//附表
//地区表
id 地区 邮编
1 西安 7140000
2 四川 1100000
3 北京 1221343
(3) :第三范式(3NF 表不可再分 (不必要的数据就不要在数据库里面在去存储 ))
id 单价 库存 销量 销量总额
1 10 2 4 40
2 20 4 5 100
3 6 8 7 42
4 8 6 8 64
id 单价 库存 销量
1 10 2 4
2 20 4 5
3 6 8 7
4 8 6 8
//这张表有问题
id 姓名 性别 民族 身份证号码
1 可爱 1 1 1234567890
2 乖巧 2 1 1231243545
3 张三 2 2 1232432432
4 李四 1 1 1232432432
//名族表
id 民族 住址
1 汉族 四川
2 布依族 西安
//性别表
id 性别
1 男
2 女
id 姓名 成绩 科目 学期
1 张三 80 1 1
2 张三1 80 2 2
3 张三2 80 1 1
4 张三3 80 1 1
//科目表
id 科目
1 物理
2 化学
//学期表
id 学期
1 第一学期
2 第二学期
二 :设计表的结构要注意 (节约空间)
(1):99.9%的情况下,全部为NOT NULL类型 id is null(不为空)
(2) :预计不会存储非负数的字段,例如各项id、发帖数等,必须设置为UNSIGNED类型
(3) :enum() 枚举类型 (通常枚举类型用在性别) ☆
tinyint(数据类型一般用在年龄字段)
UNSIGNED :有符号(或者无符号)
(4) : 日期使用int类型保存时间戳,通常用unsigned(或者用字符串类型 ) 整形最节约成本
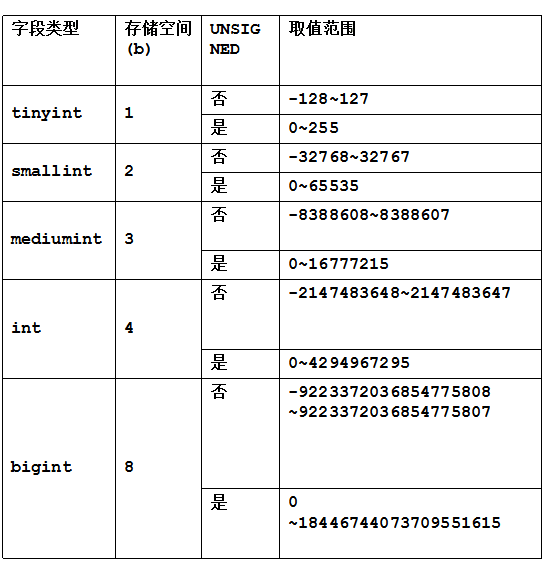
三:设计表的数据类型
(1):整形类型
字段类型 存储空间(b) UNSIGNED 取值范围
tinyint 1 否 / 是 -128~127 / 0~255
smallint 2 否 / 是 -32768~32767 / 0~65535
mediumint 3 否 / 是 -8388608~8388607 / 0~16777215
int 4 否 / 是 -2147483648~2147483647 / 0~4294967295
bigint 8 否 / 是 -9223372036854775808~9223372036854775807 / 0~18446744073709551615
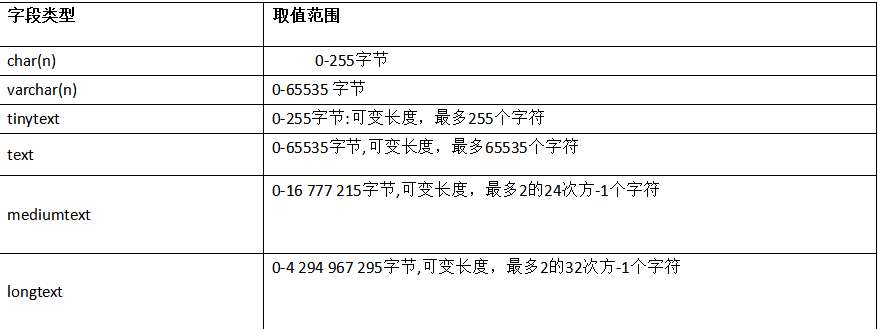
(2):字符串类型
注意:一个汉字占多少长度与编码有关
UTF-8:一个汉字=3个字节
GBK :一个汉字=2个字节
字段类型 取值范围
char(n) ☆ 0-255字节
varchar(n) ☆ 0-65535 字节
tinytext 0-255字节,最多255个字符
text 0-65535字节,最多65535个字符
mediumtext 0-16 777 215字节,最多2的24次方-1个字符
longtext 0-4 294 967 295字节,最多2的32次方-1个字符
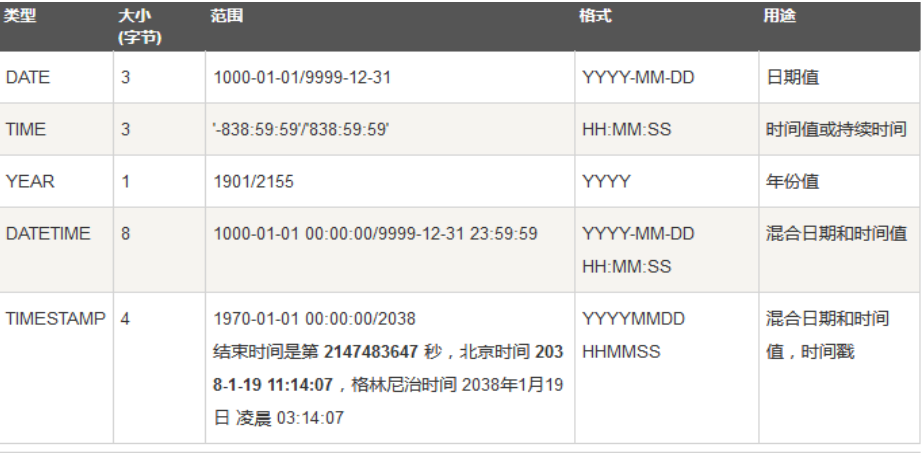
(3):日期类型
字段类型 取值范围
TIME ☆ 3 HH:MM:SS 时间值或持续时间
四 :
(1):变长表 (一张表里面数据类型有char varchar text,同时有char varchar只要有varchar就是变长表)
id(int) name(varchar[10]) sex(枚举)
1 jack 男
2 rose 女
3 lolita 女
name(varchar[10])
[jack]
[rose]
[lolita]
(2):定长表 (一张表里面出现 char int 这张表称为定长表)
id(int) name(char[10]) sex(枚举)
1 tim 男
2 lucy 女
3 lily 女
name(char[10])
[tim ]
[lucy ]
[lily ]
1.存储方式:定长表char[10] 内容不够你定义的长度会自动给你添满整个长度 定长表自动添加,但查询效率高,适合频繁查询的
变长表varchar[10]内容不够你定义的长度,他不会去给你填充长度
变长表varchar[10]比定长表char[10]节约空间. 变长表不自动填充,节约空间,安全且查询不那么频繁的
2.读取方式:定长表char[10]比变长表varchar[10]查询效率高
3.一般频繁查询的表设计为定长表char[10],
一般安全高且查询不是那么频繁用变长表varchar[10]
五:设计表的数据引擎
1.MyISAM ☆:(数据库默认引擎)非事务表,支持全文搜索fulltext,搜索速度快,记录表行数,但写入速度慢,不支持外键。多用于频繁查询,数据量要求不高的数据表中.
事务:(回滚)
2.nnoDB ☆:事务表,支持外键等高级数据库功能,CPU利用率最高,不支持全文搜索,搜索速度相对较慢,不记录行数。多用于安全性要求高,数据量高的数据表中.
3.Memory:内存表,数据记录在内存中,写入及查询速度最快。但由于使用内存,根本无法长期保存数据,而且可以保存的数据量也不能太高。通常用于临时记录数据,可以即用即弃的数据表中,如密钥验证记录密钥等
六.视图(作用:提高查询效率,提高数据安全)

(1):创建一个视图 VIEW:视图
视图创建:
CREATE ALGORITHM=视图类型 VIEW 视图名 as 查询sql语句(要什么样的视图写什么语句)
CREATE VIEW 视图名 as 查询sql语句(要什么样的视图写什么语句)
CREATE VIEW 视图名 as 曾 删 改 查
(2):视图创建特点(注意的内容)
视图涉及到相关字段名,不能有重复
视图名字不能与任何表名重复
视图不能重复取一个名字创建多个视图
创建视图的sql查询语句,语法与普通查询一样
视图查询与普通sql查询一致,如视图名为news_view,查询语句: select * from news_view
(3):视图的作用
安全性:隐藏真实的数据表,防止数据表泄漏。
开发速度提升:例如多表查询,以往要写复杂的语句,现在多个表关联到一个视图,只查询一个视图,语 句变得简单
查询速度提升:以往多表查询,需从硬盘中获取多次,而视图只获取一次
七:存储过程(提高查询效率)
(1):创建一个存储过程
CREATE PROCEDURE 过程名 ([过程参数[,...]]) BEGIN 过程体 END
CREATE PROCEDURE 过程名(iid INT)
BEGIN
删除语句 delete from news where id=iid
end
//创建一个存储过程
CREATE PROCEDURE news_cc (iid INT)
BEGIN
DELETE from news where id=iid;
end
2.执行存储过程:
CALL 过程名 ([过程参数[,...]])
CALL 过程名(2);
CALL news_cc (19);
3.删除存储过程:
drop PROCEDURE 过程名
八:触发器(trigger)(提高查询效率,弊端:数据维护很难)
有回滚性

九:索引:索引的作用相当于一本书的目录,索引能大大加快查询速度。索引优化和查询优化是相辅相成的。
(1):PRIMARY(pk):主键,在所有类型的索引速度最快。每个数据表最多有一个,涉及到主键的字段(组合)值必须唯一。建议每个数据表都建立一个主键,该主键就是id。
(2):UNIQUE:唯一索引,速度仅次于主键,涉及到的字段(组合)值必须唯一。但一个数据表中可以存在多个。
(3):INDEX(了解):普通索引,速度在三者中最慢,但是几乎没有任何限制
(4) : fulltext:全文索引,主要用于模糊搜索。表类型必须是myisam,涉及字段类型必须是字符型
(5): spaital(了解):地理信息索引,主要用于地理信息搜索。涉及字段类型必须是地理信息型
十:
group by :分组(统计分组数据 )
order by :排序 (asc(默认的升序) desc:降序)
select sex,count(*) from stus group by sex
//一般用在多表查询时使用 多表查询联系关键字
left join(左链接)
right join(右链接)
inner join(内连接) (用的比较多) ☆
select * from news inner join category on category.id=news.category_id
news表 (文章信息表)
id title content time category_id
1 哈哈哈 嘻嘻 11-5 3
1 哈哈哈1 嘻嘻1 11-5 4
1 哈哈哈2 嘻嘻2 11-5 5
1 哈哈哈3 嘻嘻3 11-5 3
1 哈哈哈4 嘻嘻4 11-5 3
1 哈哈哈5 嘻嘻5 11-5 3
category :(分类表)
id name pid
1 娱乐 0
2 体育 0
3 ktv 1
4 足球 2
5 西甲 4
十一: explain :分析查询语句的效率
explain 查询语句
explain select * from news where id=1
SIMPLE:最简单的sql语句,最常见。大部分有效率的语句,类型都是SIMPLE
PRIMARY:查询的数据表是一个动态表,数据表是有一条sql语句生成的结果集构建出的临时表,该表无法 使用索引,如下
select * from (select * from news)n,通过n得到结果集来查询,那n就是动态表
UNION:使用union关键字,用于合并两个或多个 SELECT 语句的结果集(一般少用)
十二:用命令操作mysql数据库
cmd:打开命名控制面板
cd D:\phpstydy\phpStudy\MySQL\bin 进入到这个文件
d: 进入到d盘文件
mysql -u root -p 链接数据库
登录MySQL
mysql -u root -p
切换选择数据库
use dbname;
显示所有数据库
show databases;
显示数据库中所有数据表
show tables;
查看数据表结构
describe table;
显示表创建信息
show create table table_name;
查看运行环境信息
status;

