


做模型时常常是特征越多模型准确率越高(至少在训练集上)。但过多的特征又增加了数据收集、处理、存储的工作量,以及模型的复杂度。
在保证模型质量的前提下,我们希望尽量少地使用特征,这样也间接地加强了模型的可解释性。一般来说,为避免过拟合,特征尽量控制在实例个数的1/20以下,比如有3000个实例,则特征最好控制在150以下。
除了特征的具体个数,特征工程中也经常遇到某些特征严重缺失,特征相关性强,一些特征不但无法给模型带来贡献,反而带来噪声等问题。
本篇介绍特征筛选工具feature-selector,在github上有1.8K星,它使用少量的代码解决了特征筛选中的常见问题,用法简单,便于扩展;同时也提供了作图方法,以更好地呈现特征效果。
下载地址
https://github.com/WillKoehrsen/feature-selector
核心代码
其核心代码文件只有feature_selector/feature_selector.py(600多行代码),所有方法都定义在FeatureSelector类中,因此,不用安装,只需要将该文件复制你的项目中即可使用。
功能点
- 寻找缺失严重的特征
- 寻找仅有单值的特征
- 寻找相关性强的特征(皮尔森相关系数,默认只考虑数值型)
- 寻找特征重要性为0的特征(根据gbm模型)
- 寻找特征重要性低的特征(根据gbm模型)
示例代码
示例及效果见:Feature Selector Usage.ipynb
代码中使用Kaggle比赛中信用风险预测的数据,为分类问题。
其中包含10000条数据,122个特征;将其TARGET字段作为标签,其它字段作为预测特征。
首先用训练数据建立类的实例:
fs = FeatureSelector(data = train, labels = train_labels)
后面逐一列出了各个函数的用法,此处不再一一列举。
图示
工具提供plot_xxx等方法具象地展示了数据情况:
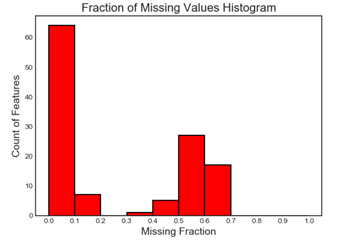
- 数据缺失图
该图横坐标为缺失比例,纵坐标为特征个数,例如第一列为缺失比例在0-0.1之间的特征约60多个。
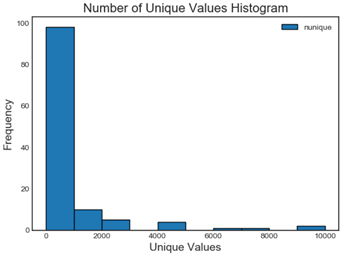
- 特征取值图
该图横坐标为特征取值个数,纵轴为特征个数,例如第一个柱表示将近100个特征取值的个数在1-1000之间,最后一柱表示有几个特征有上万种取值。
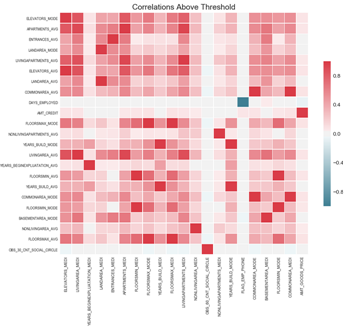
- 特征相关性
下图中列出了相关系数大于0.98的特征(未列出所有特征),同时还提供fs.record_collinear()方法列出各个特征对及其相关系数。
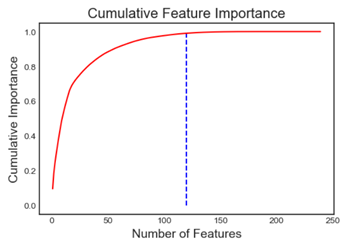
- 特征重要性
工具默认使用lightgbm模型计算特征重要性,在调用方法时需要指定损失函数,以及使用分类方法还是回归方法,迭代次数等等。工具可显示其前N个重要特征。另外,还可以参考下图,查看模型特征个数与模型效果的关系,下图显示:将模型参数简化为122个后,模型准确率几乎不变。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具