

论文地址:https://arxiv.org/pdf/1606.07792.pdf
相关代码:https://github.com/jrzaurin/pytorch-widedeep
《Wide & Deep Learning for Recommender Systems》是2016年Google发表的一篇使用深线层网络相结合构建推荐系统的论文。
个人认为结合浅度学习和深度学习,是为一种处理表格数据,以及综合数据的好方法。这篇论文涉及:两种网络各自的优势;稀疏特征的组合;以及融合两种网络的具体方法。
使用非线性特征组合(具体方法见后)构造的线性网络(浅层网络)常被用于解决输入是稀疏特征的分类和回归问题,它的优点是高效且具有可解释性,缺点是需要大量特征工程。相对来说深层网络不需要太多特征工程,使用Embedding方法可将稀疏特征降维成稠密特征,它能构造在训练集中没见过的特征组合,而其问题在于过于泛化,当数据过于稀疏和高秩(具体见下文)时,它会推荐出一些无关的选项。文中方法结合了浅层网络的记忆力和深度网络的泛化力,使用TensorFlow实现,并将其应用在Google Play的应用推荐系统中,取得了明显的提升。该方法也可应用于其它场景。
介绍
推荐系统的输入一般是用户相关数据及其上下文信息,系统在数据库中找到与之最匹配的商品项,排序后输出。这里涉及到记忆力和泛化力。记忆力可以看作寻找训练集中频繁出现的项目或特征组合,在历史数据中挖掘相关性;而泛化性则基于传递性,探索新的特征组合。
在浅层网络中常使用特征组合的方法,如将类别特征经过Onehot转换成二值特征,再将其进行组合,例如:AND(user_installed_app=netflix,impression_app=pandora),即用户安装过netflix为其推荐的应用是pandora,当二者都为真时结果为真,其余情况下结果为假,从而确定了一些同时出现的组合对最终结果的影响。浅层网络通常会用到一些手动的特征工程,且无法找到在训练集中没出现过的组合。
深度网络可以找到一些训练集中未出现过的组合,且不需要手动做特征工程。当数据过于稀疏和高秩时,比如用户的特殊偏好或者比较小众的产品,并不在组合中大量出现,而稠密的嵌入层将会产出大量的非零组合,从而导致了无关的推荐。而浅层网络的“例外规则”用少量参数即可解决该问题。(深度网络更加宏观,浅度网络保存更多细节,不只是浅度线性模型,其它机器学习模型也类似)。

(下方是输入,上方是输出)
推荐系统
推荐系统工作流程如下图所示:

Query表示用户在访问应用商店时产生的相关上下文信息,推荐系统返回App列表Ranked items(也称impressions)。而用户的信息及与系统的交互过程都被记录到Logs中,以备训练模型使用Learner。
数据库(Database)中存储着数百万应用程序,用户查询又需要即时返回,因此第一步是检索(Retrieval),系统通过机器学习模型和人工定义的规则检索出少量可选项(比如100项)。最终通过模型输出排序(Ranking),排序根据概率P(y|X),即:给定X的情况下(X包含用户信息和应用程序信息),用户动作为y(如安装app)的概率。
算法原理
Wide组件
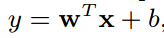
使用了简单的线性模型,其中w和b为模型参数,x由两部分组成,一部分为模型的输入x,另一部分为组合参数:
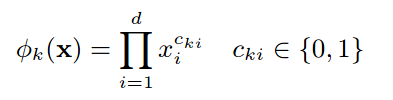
其中Cki为布尔类型,定义了第i维参数是否被使用在第k种组合中时,使用时值为1,否则为0。简单地说,就是使用某些方法(算法或者手动特征工程)新建了k个组合参数,每个参数涉及一个以上的x特征。
Deep组件
深度组件一般是一个包含嵌入层的深度神经网络。如网络结构图所示,特征传入网络后被转换成低维高密度的实值(real-value)特征,即嵌入向量(Embedding),维度一般为10-100维,之后再逐层传入隐藏层,隐藏层计算方法如下:

其中l为层号,f为激活函数,W,b为网络参数,a为各层的入和输出(和一般神经网络无差别)。
结合两种组件
文中以宽度组件和深度组件输出对数概率的加权和再传入公共的logstic函数联合训练模型。
需要注意的是,结合组件有两种方式联合训练(joint train)和集成训练(ensemble)。集成训练是在训练过程中两组件相互无关,只在预测时将二者结合;而联合训练在训练时,优化误差函数,反向传播同时优化两个组件的参数。两种方法的模型大小也有区别,集成训练时,为了保证单个组件的精度,每个模型都比较大,而联合训练时宽度模型只需要弥补深度模型的弱点,构件少量的组合特征即可。
文中使用FTRL(Follow the regularized leader)算法和L1正则化优化宽度模型,使用AdaGrad优化深度模型。最终组合的算法是:
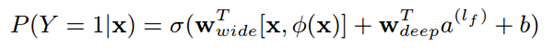
其中Y是二分类的标签,σ为sigmoid函数,φ(x)用于产生组合特征,w和b为网络参数。
系统实现
具体实现分成:数据产生、模型训练、模型服务三部分。
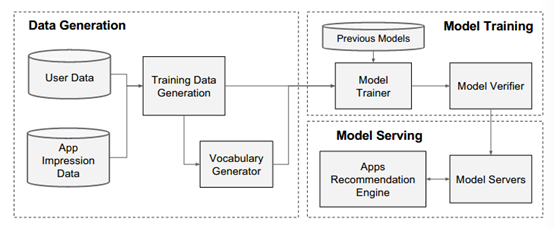
数据包含用户数据和推荐数据,而标签为二值型,如用户是否安装了app。在数据产生阶段生成了词表,当字符特征出现次数足够多后,将词表可将字串映射成到整数ID。
模型结构如下图所示:
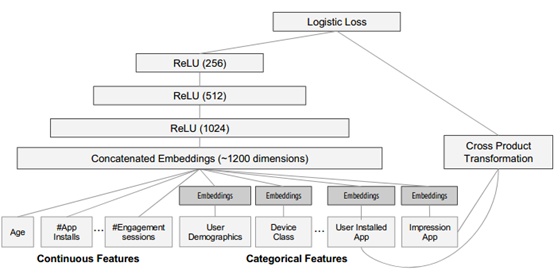
数据输入包含数据和词表产生的稀疏和稠密的特征以及标签。深度网络包含用户安装和推荐的app组合出的特征;深度模型将每一个类别型数据转换成32维的嵌入特征。然后将这些稠密特征连接在一起,最终组合出1200维特征。模型使用500 billion样本训练,更新模型时为缩减训练使用的时间,使用之前的模型参数初始化模型参数。最终提供的服务对每个请求能在10ms以内做出应答。
实验结果
线上和离线的评测结果如下:

相关代码:
相关代码:https://github.com/jrzaurin/pytorch-widedeep
这是在github中找到的一个相对高星的项目,其实现方法也基于本篇介绍的论文。它可使用widedeep处理表格、文本数据、图像数据,基于pytorch框架实现。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号