


论文地址:https://arxiv.org/abs/1908.10084
论文中文翻译:https://www.cnblogs.com/gczr/p/12874409.html
源码下载:https://github.com/UKPLab/sentence-transformers
相关网站:https://www.sbert.net/
“论文中文翻译”已相当清楚,故本篇不再翻译,只简单介绍SBERT的原理,以及训练和使用中文相似度模型的方法和效果。
原理
挛生网络Siamese network(后简称SBERT),其中Siamese意为“连体人”,即两人共用部分器官。SBERT模型的子网络都使用BERT模型,且两个BERT模型共享参数。当对比A,B两个句子相似度时,它们分别输入BERT网络,输出是两组表征句子的向量,然后计算二者的相似度;利用该原理还可以使用向量聚类,实现无监督学习任务。
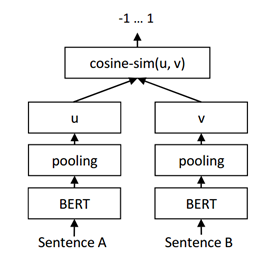
挛生网络有很多应用,比如使用图片搜索时,输入照片将其转换成一组向量,和库中的其它图片对比,找到相似度最高(距离最近)的图片;在问答场景中,找到与用户输入文字最相近的标准问题,然后给出相应解答;对各种文本标准化等等。
衡量语义相似度是自然语言处理中的一个重要应用,BERT源码中并未给出相应例程(run_glue.py只是在其示例框架内的简单示例),真实场景使用时需要做大量修改;而SBERT提供了现成的方法解决了相似度问题,并在速度上更有优势,直接使用更方便。
SBERT对Pytorch进行了封装,简单使用该工具时,不仅不需要了解太多BERT API的细节, Pytorch相关方法也不多,下面来看看其具体用法。
配置环境
需要注意的是机器需要能正常配置BERT运行环境,如GPU+CUDA+Pytorch+Transformer匹配版本。
$ pip install sentence_transformers
下载源码
$ git clone https://github.com/UKPLab/sentence-transformers.git
模型预测
在未进行调优(fine-tune)前,使用预训练的通用中文BERT模型也可以达到一定效果,下例是从几个选项中找到与目标最相近的字符串。
from sentence_transformers import SentenceTransformer
import scipy.spatial
embedder = SentenceTransformer('bert-base-chinese')
corpus = ['这是一支铅笔',
'关节置换术',
'我爱北京天安门',
]
corpus_embeddings = embedder.encode(corpus)
# 待查询的句子
queries = ['心脏手术','中国首都在哪里']
query_embeddings = embedder.encode(queries)
# 对于每个句子,使用余弦相似度查询最接近的n个句子
closest_n = 2
for query, query_embedding in zip(queries, query_embeddings):
distances = scipy.spatial.distance.cdist([query_embedding], corpus_embeddings, "cosine")[0]
# 按照距离逆序
results = zip(range(len(distances)), distances)
results = sorted(results, key=lambda x: x[1])
print("======================")
print("Query:", query)
print("Result:Top 5 most similar sentences in corpus:")
for idx, distance in results[0:closest_n]:
print(corpus[idx].strip(), "(Score: %.4f)" % (1-distance))
训练中文模型
模型训练方法
训练原理:https://www.sbert.net/docs/training/overview.html
训练示例说明:https://www.sbert.net/examples/training/sts/README.html
训练示例代码:examples/training/sts/training_stsbenchmark.py
训练中文模型
把示例中的bert-base-cased换成bert-base-chinese,即可下载和使用中文模型。需要注意的是:中文和英文词库不同,不能将中文模型用于英文数据训练。
下载中文训练数据
下载信贷相关数据,csv数据7M多,约10W条训练数据,可在下例中使用
$ git clone https://github.com/lixuanhng/NLP_related_projects.git
$ ls NLP_related_projects/BERT/Bert_sim/data
代码
from torch.utils.data import DataLoader
import math
from sentence_transformers import SentenceTransformer, LoggingHandler, losses, models, util
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
from sentence_transformers.readers import InputExample
import logging
from datetime import datetime
import sys
import os
import pandas as pd
model_name = 'bert-base-chinese'
train_batch_size = 16
num_epochs = 4
model_save_path = 'test_output'
logging.basicConfig(format='%(asctime)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
level=logging.INFO,
handlers=[LoggingHandler()])
# Use Huggingface/transformers model (like BERT, RoBERTa, XLNet, XLM-R) for mapping tokens to embeddings
word_embedding_model = models.Transformer(model_name)
# Apply mean pooling to get one fixed sized sentence vector
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True,
pooling_mode_cls_token=False,
pooling_mode_max_tokens=False)
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
train_samples = []
dev_samples = []
test_samples = []
def load(path):
df = pd.read_csv(path)
samples = []
for idx,item in df.iterrows():
samples.append(InputExample(texts=[item['sentence1'], item['sentence2']], label=float(item['label'])))
return samples
train_samples = load('/workspace/exports/git/NLP_related_projects/BERT/Bert_sim/data/train.csv')
test_samples = load('/workspace/exports/git/NLP_related_projects/BERT/Bert_sim/data/test.csv')
dev_samples = load('/workspace/exports/git/NLP_related_projects/BERT/Bert_sim/data/dev.csv')
train_dataloader = DataLoader(train_samples, shuffle=True, batch_size=train_batch_size)
train_loss = losses.CosineSimilarityLoss(model=model)
evaluator = EmbeddingSimilarityEvaluator.from_input_examples(dev_samples, name='sts-dev')
warmup_steps = math.ceil(len(train_dataloader) * num_epochs * 0.1) #10% of train data for warm-up
# Train the model
model.fit(train_objectives=[(train_dataloader, train_loss)],
evaluator=evaluator,
epochs=num_epochs,
evaluation_steps=1000,
warmup_steps=warmup_steps,
output_path=model_save_path)
model = SentenceTransformer(model_save_path)
test_evaluator = EmbeddingSimilarityEvaluator.from_input_examples(test_samples, name='sts-test')
test_evaluator(model, output_path=model_save_path)
测试结果
- 直接使用预训练的英文模型,测试集正确率21%
- 直接使用预训练的中文模型,测试集正确率30%
- 使用1000个用例的训练集,4次迭代,测试集正确率51%
- 使用10000个用例的训练集,4次迭代,测试集正确率68%
- 使用100000个用例的训练集,4次迭代,测试集正确率71%
一些技巧
除了设置超参数以外,也可通过构造训练数据来优化SBERT网络,比如:构造正例时,把知识“喂”给模型,如将英文缩写与对应中文作为正例对训练模型;构造反例时用容易混淆的句子对训练模型(文字相似但含义不同的句子;之前预测出错的实例,分析其原因,从而构造反例;使用知识构造容易出错的句子对),以替代之前的随机抽取反例。
参考
- BERT中文实战(文本相似度) https://blog.csdn.net/weixin_37947156/article/details/84877254
- Bert 文本相似度实战(使用详解) https://zhuanlan.zhihu.com/p/367726571
- Sentence-BERT: 一种能快速计算句子相似度的孪生网络 https://www.cnblogs.com/gczr/p/12874409.html
- Sentence-Bert论文笔记 https://zhuanlan.zhihu.com/p/113133510?from_voters_page=true


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具