


基本信息
- 论文题目:《Time Series Shapelets: A New Primitive for Data Mining》
- 论文地址:https://readpaper.com/paper/2029438113
- 相关源码:https://github.com/johannfaouzi/pyts
原理
2009年,Ye和Keogh在KDD上发表论文,首次提出了时序数据中的 Shapelet 的概念。Shapelet是最近邻算法的扩展,它提取最典型的特征子集作为判断依据。
例如:马鞭草和荨麻的叶片很相似,如果将它们的叶片边缘形状整体作为序列建模,则难以区分。
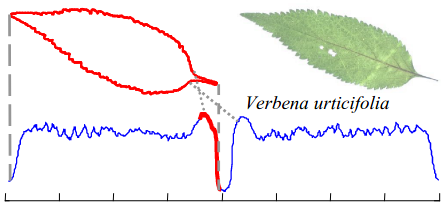
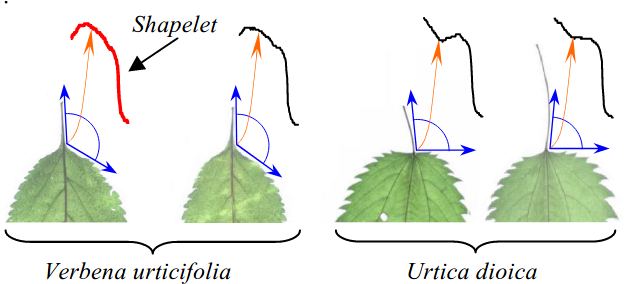
它们的重要差别是叶柄与叶片之间的角度,一个是直角,一个是钝角。因此,如果使用序列中的小片断(子序列)作为序列的表征,就很容易将二者区分开来。
优缺点
优点
- 具有可解释性
- 鲁棒性强
- 相对于最近邻算法速度快
缺点
- 算法相对简单,花费时间较长
- 一般用于二分类和聚类,不支持多分类
用途
- 训练分类模型
- 解释分类原因
- 用于选择时间区间和维度
方法
算法的核心是如何找到最有代表子序列(文章第三部分)。首先使用滑动时间窗口获取所有可能子序列,然后,使用使信息增益高的作为切分策略。
暴力找
其最简单的实现方法包含如下两步:
- 利用穷举方法找到所有可选子序列作为备选项。
-
找到其中信息增益(该子序列能否能更好区分不同类别)最大的片断。
后面的方法都基于这个算法。
其中D是训练使用的数据集,取滑动窗口的长度最小为MINLEN,最长为MAXLEN的所有子序列作为候选集Candidates,函数CheckCandidate()用于计算信息增益,具体方法是计算每个时间序列到候选对象的距离。将其放在实数线上,并标注上类别。

可以看到,如果其中某个候选者,所有正例离它都近,所有反例离它都远,也就是说它可以很好地区分二者,则它的信息增益较大。
其中一个序列T与了一个子序列S的距离被定义为:
SubsequenceDist(T, S) = min(Dist(S, S'))其中S'是序列T的子序列,在序列T中查找与子序列S最近似的子序列S‘,并计算S到S'间的距离。因此,不需要把叶子方向摆正,只要两片叶子里包含相似的子序列就能找到。
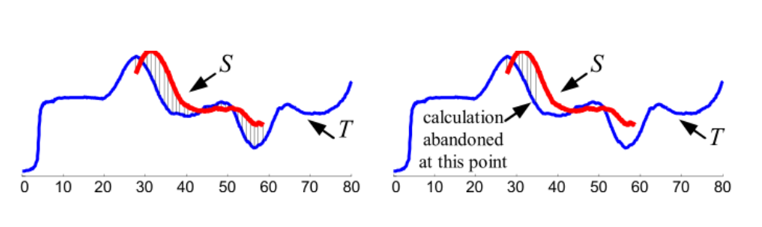
子序列早弃
为减少计算量,在计算过程中发现距离比已知最大的距离还大时,则不再继续计算。
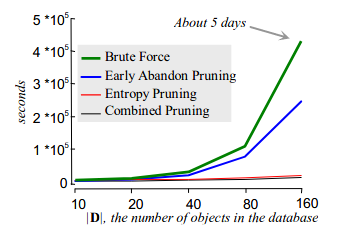
熵剪枝
为减少计算量,在计算过程中如果信息增益比当前值还小,则不再继续计算。
在几种方法中,熵剪枝速度最快
用法
- 安装
代码集成在pyts包中(1.1K Star),pyts是处理时间序列的类似scikit-learn的函数库。
$ pip install pyts
启发
- 可以将时序看作决策树,子序列看作特征。
- 找到最典型的特征,类似于人的思考方式。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具