

论文题目:Making Sense of Word Embeddings
相关源码:https://github.com/uhh-lt/sensegram
论文地址:https://arxiv.org/abs/1708.03390
简介
论文是2016年发表于ACL(Association for Computational Linguistics,自然语言处理顶会,一年召开一次,CCF等级/JCR分区:A类)的会议论文。
背景知识
论文介绍了一种简单有效的方法用于学习语义嵌入。文中方法既可以直接从语料库和字典学习,也可以根据已有的词向量数据通过自我网络聚类的方法归纳学习。它提升了下游应用的效果,与当时最好的模型效果类似。
词向量
- 预处理时将词映射成稠密向量代入模型,降低稀疏性
- 对比不同词的语义相似度,实现近义词的迁移
- 表征不同语义单位:词向量->词组向量->短语向量
- 通过词嵌入实现运算,比如:男-女=国王-王后,国王-男+女->王后,实现类比相关的逻辑推理功能,以及性质变换。
语义向量
无论是稠密的还是稀疏的表示,大部分的词嵌入方法都面临一词多义的问题。后来有人提出了意义向量(sense vector)的概念来解决这个问题,从而提升一些应用的效果,如成份标注、语义关系识别。
论文中提出了一种意义向量学习方法,它使用自我中心网络聚类,将已存在的词嵌入转换成意义嵌入。最终实现了利用上下文实现语义消歧机制(WSD)。
自我中心网络
自我中心网络 ego network,它的节点是由唯一的中心节点(ego),以及这个节点的邻居(alters)组成的,它的边只包括了ego和alter之间,以及alter与alter之间的边。

image.png
词嵌入方法
请参考我之前的文档:几种词嵌入方法
Chinese_whisper算法
话从第一个人传给第二个人,第二个人再传给第三个人,一直传下去,越传越走样。
Chinese_whisper 是一种图聚类算法:
- 原则:构建无向图,将每个词做为无向图中的一个节点,词之间的相似度,作为节点之间的边,如果词之间的相似度小于设定的阈值那么,这两个词对应的节点之间就没有边。
- 步骤一:迭代开始前,将每个词作为一个节点,每个词都被赋予一个id作为该词的类别。
- 步骤二:遍历所有节点,把每个节点移动到邻居所属最多的类(在连接相等的情况下,从中随机选择一个)。
- 步骤三:重复步骤二,直到达到预定的迭代次数或收敛。
前人的方法
一词多义
- 聚类方法不断迭代,将簇心作为语义嵌入(词聚类/上下文聚类)
- 稠密向量常使用神经网络方法
- 基于知识的方法,如将知识库中的任何实体表实为稠密向量,以及利用WordNet和词嵌入来构建语义嵌入。
词义消歧
有监督学习,常常为每一个目标词建立一个模型,使用有监督方法训练,这需要大量标注。另外,还有基于知识的方法,比如从WordNet中导出意义的表示。
无监督学习,从数据中自动归纳语义清单,具体的方法有两种:分别是上下文聚类,和词(自我中心网络)聚类;是否为歧义由其上下文的重叠度来确定;计算上下文词与中心词的距离。
语义嵌入算法
算法具体包含四步

image
- 学习词嵌入
- 基于向量的相似度建立最近邻图
- 使用ego-network聚类归纳语义向量(分组)
- 用词向量计算语义向量
上述主要流程也是可以被替换的,比如:已经存在词嵌入,则可省略第一步;如果使用已经构建的词相似度图,可替代第二步;如果使用众包的方式构建语义列表,则可替代第二三步。
学习词嵌入
论文使用了Word2Vec的CBOW模型训练100维(或300维)的词向量,具体的上下文大小是3,词出现的最小频率是5。并在后面的评测阶段将其作为baseline模型。使用Wikipedia和ukWaC作为训练数据。
计算相似图
建立基于近义词的图,比如桌子和椅子近似度为0.78,对每个词取其200个最近邻(对于绝大多数词来说是足够的)。这个图既可以基于上一步的词向量,也可以使用JoBimText(JBT)架构提供的语义相似度。
- 词向量相关性
使用cosine距离来计算词向量相似度最高的最近邻,具体使用矩阵乘法实现。
- JBT 相关性
这是一种无监督的方法,每个词被表征为基于依赖关系的稀疏特征词袋,使用MALT解析器提取。特征使用LM1方法归一化。其剪枝方法是:对每个词保留1000个特征,每个特征与1000个词关联。两个词的相似度通过它们共有特征的个数计算。
JBT有两个优点:
(1) 基于依赖特征准确地估计词的相似度。
(2) 高效地计算语料库中所有词的最近邻域。
此外,即使次要意义在训练语料库中有显著的支持,单词嵌入的近邻往往也倾向于属于主要意义。
语义归纳(分组)
首先,对词 t 建立一个ego-network G,然后使用网络聚类,用聚类去解释词t的各个语义(sense)。同样的语义一般会紧密相连,反之则认为语义不同。
具体算法如下:

每一次迭代从相关图T中取一个词t,首先,取与t语义最相近的N个词作为结点V构建ego-network G(图中不含t);然后,对于G中的每个结点v在T中寻找与之最相近的n个词V',并建立v到v'的边;最后,使用Chinese Whispers算法(不需要超参数)对ego-network聚类。输出是多个簇,每个聚St包含它的N个最近邻。
算法中有三个超参数:N是ego-network的大小;n是v近邻的最大连接数,k是簇中元素的最小个数。参数n决定了描述的细化程度(n越大关系越密)。经验值是N=200, n为50,100或200,k为5或15(k越小越细分)。
每个词在义群里都有权重,其权重是该词与歧义词t的距离。
综上,该方法是计算每个词t可能有几种意思,并对每种意思抽像成一个sense vector(由其它词组成的list)表示。
用词向量计算语义向量
为每一种词义归纳出一组语义向量。假设一个词义可能由多个词表示。
设W是训练语料中所有词的集合,Si={w1,...wn} ⊆W,Si是从前一步计算得到的语义簇,设一个函数vecw,用于将词映射到向量;函数γi 计算其在簇中的权重,分别使用两种方法计算语义向量。
不加权方法:
加权方法:
加权结果如表1所示:
“桌子”一词既与家具相关,又与数据相关,而词义向量的邻域拆分后不同时与家具和数据相关(通过语义向理计算而非词向量)。
词义消歧
此部分介绍语义向量的具体用法:利用上下文进行语义消歧。
设目标词为w,其上下文为C = {c1,...,ck}, 首先,将w映射成一系列的语义簇S ={s1,...,sn},用两种方法来确定其在上下文中最确切的语义。
- 方法一:计算基于上下文的语义概率
右侧的公式实际上是一个sigmoid函数——将具体值转换成概率:
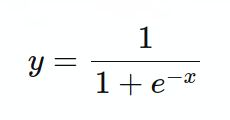
sigmoid函数图像:
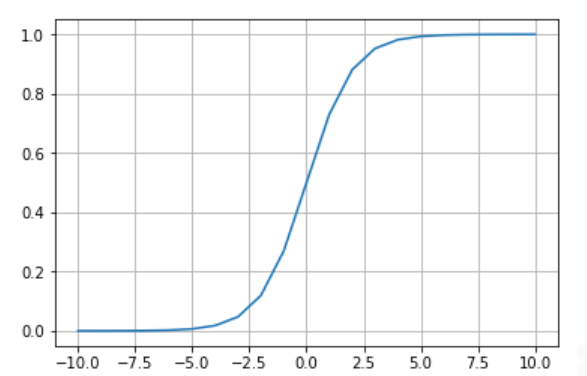
公式中的c是上下文嵌入的均值,使用上下文均值来计算中心词的词义本身就类似于CBOW的基础方法。使用这种方法对随机词有较低的标量积,对上下文中出现的词有较高的标量积。
- 方法二:基于计算中心词与上下文的相似度
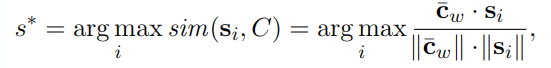
公式中的c是上下文词嵌入的均值,与方法一不同的是它不需要使用上下文嵌入,而只需要每个词的词嵌入(Word2Vec工具默认不保存上下文嵌入)。
为进一步提升效果,论文还使用了上下文过滤方法,比如上下文中一些词“chairs”"kitchen"可能对“table”的词义起到更重要的作用,具体算法如下:

其中f是上述公式中的计算方法,i为具体的语义簇,j是上下文中词的位置,对每一个词cj,计算它与各个词义的距离(如果cj有辨识度,上式的值就比较大),从而找到最具消歧能力的词。
实验
分别在两个数据集上对模型进行评价,一个是用众包方式收集的带上下文的语义标注;一个是公用的SemEval数据集。
TWSI评测
主要评测不同参数对模型的影响。
TWSI是一个众包系统,其中包含1012个高频名词,每个词平均2.26个语义,提供145140个标注的句子。另外,它还提供一个清单,其中列出了所有可以替代该单词语义的词表。
数据分布是有偏的,其中79%指向最常用的语义,因此除了TWSI数据全集以外,还构造了无偏子集(balanced subset),每个语义除它本身以外,有五个上下文词。
评价方法
创建一个映射表用于对比预测值和标注值。语义被表征为一袋词向量,可用余弦相似度进行比较。每个归纳的语义对应一个最相似TWSI语义作为预测值,对比预测值和TWSI标注值,即可使用准确率、召回率等指标给模型打分。
指标
为了方便比较,还定义了一些指标:
- 归纳上界
当该含义的映射存在时,定义归纳上界为理论上能达到的最佳值。 - TWSI最高频
TWSI数据集中某个词对应最高频的词义。 - 归纳最高频
某个词归纳后,最大的聚簇。 - 随机语义
从某个词语义中随机取一个作为baseline。
结果
表3展示了基于不同底层模型,在不同粒度下模型的表现:
认为其能达到的最好情况是众包标注结果(TWSI);可以看到粒度越细,表现越好;同时也可以看到语义个数(Sense)与识别性能成反比。
表4展示了有偏数据与校正数据,以及过滤的效果,结果是使用上下文中的两个词p=2过滤时效果最好。

最终图3展示了实验结果:
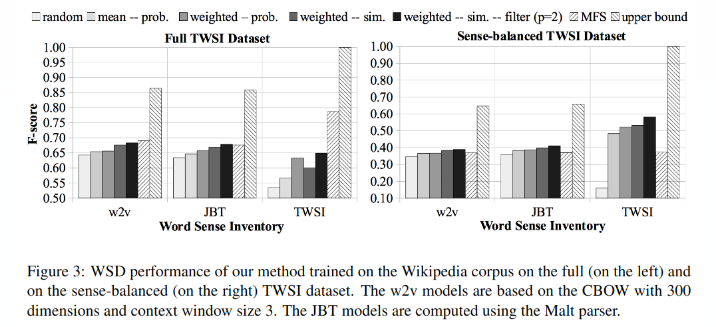
实验对比了随机算法、基于概率的均值、加权重,基于相似度的加权值,加p=2过滤,最高频语义,以及理论最佳效果(upper bound)。
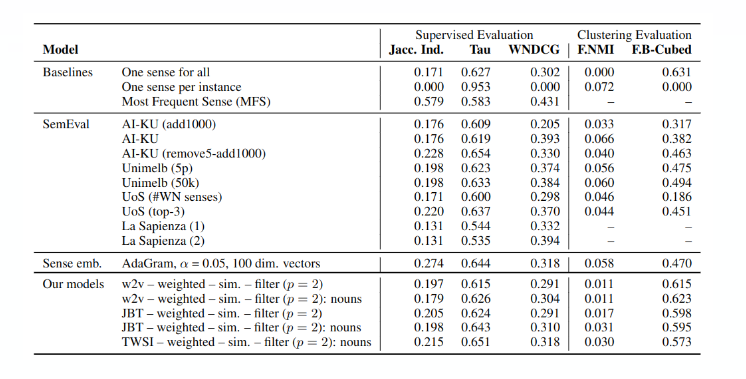
SemEval 评测
国际语义评测SemEval 是国际权威的词义消歧评测,文中使用了其中的任务13,用于与其它模型对比效果。
提供20个名词、20个动词和10个形容词。包含20-100个上下文单词,总共4664个上下文。
对比结果如下:
参考
超全word embedding论文总结
秒懂词向量Word2vec的本质
知识图谱之WordNet
ego-network概念
A Survey of Word Embeddings Evaluation
A Survey on Language Models
Chinese Whisper 人脸聚类算法实现
0人点赞

