

一、kafka 介绍 && kafka-client
一、kafka 介绍
1.1、kafka 介绍
Kafka 是一个分布式消息引擎与流处理平台,经常用做企业的消息总线、实时数据管道,有的还把它当做存储系统来使用。
早期 Kafka 的定位是一个高吞吐的分布式消息系统,目前则演变成了一个成熟的分布式消息引擎,以及流处理平台。
Kafka 主要起到削峰填谷(缓冲)、系统解构以及冗余的作用,主要特点有:
- 高吞吐、低延时:这是 Kafka 显著的特点,Kafka 能够达到百万级的消息吞吐量,延迟可达毫秒级;
- 持久化存储:Kafka 的消息最终持久化保存在磁盘之上,提供了顺序读写以保证性能,并且通过 Kafka 的副本机制提高了数据可靠性。
- 分布式可扩展:Kafka 的数据是分布式存储在不同 broker 节点的,以 topic 组织数据并且按 partition 进行分布式存储,整体的扩展性都非常好。
- 高容错性:集群中任意一个 broker 节点宕机,Kafka 仍能对外提供服务。
使用消息队列的好处:
解耦、冗余(每个分区都有副本)、提高扩展性、灵活性 & 峰值处理能力、可恢复性(有副本)、顺序保证、缓冲、异步通信
1.2、kafka术语
-
生产者(Producer):
- 向 broker 发布消息的应用程序。
- 生产者也负责选择发布到Topic上的哪一个分区。最简单的方式从分区列表中轮流选择。也可以根据某种算法依照权重选择分区。
-
消费者(Consumer):
-
从消息队列中获取消息的客户端应用程序。
-
一个 topic 可以让若干个消费者进行消费,若干个消费者组成一个 Consumer Group 即消费组,一条消息只能被消费组中一个 Consumer 消费。
-
假如所有的消费者都在一个组中,那么这就变成了 queue 模型。 假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。
-
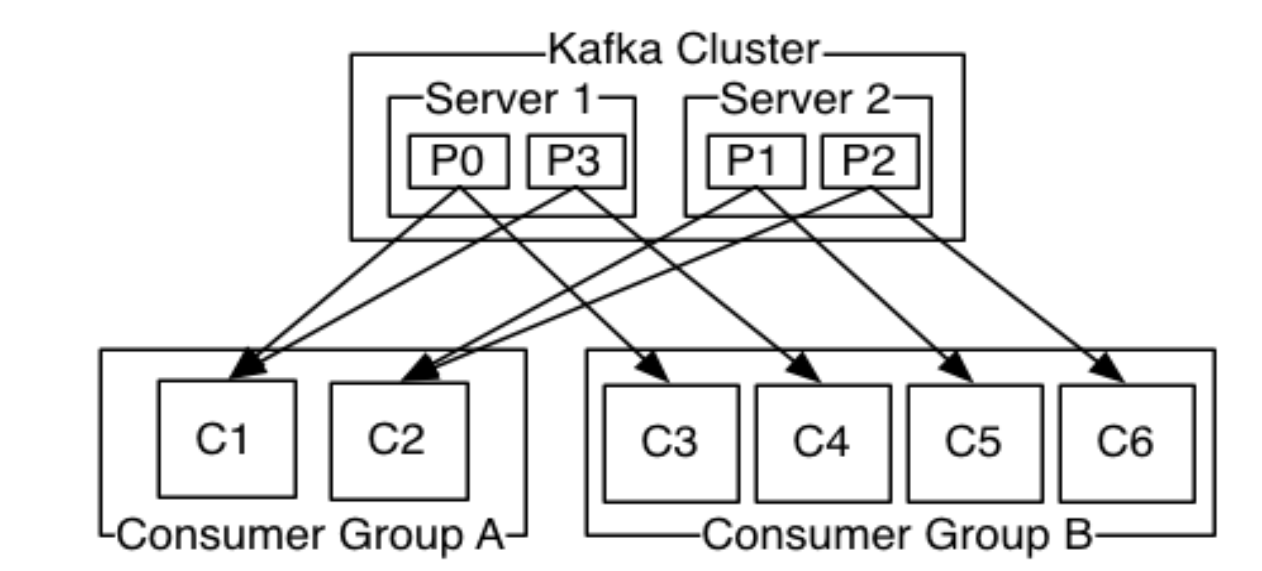
更通用的,我们可以创建一些消费者组作为逻辑上的订阅者。每个组包含数目不等的消费者,一个组内多个消费者可以用来扩展性能和容错。如下图所示:
-
![消费者]()
-
2个 kafka 集群托管4个分区(P0-P3),2个消费者组,消费组 A 有2个消费者实例,消费组 B 有4个。
-
kafka 中消费者组有两个概念:队列:消费者组(consumer group)允许消费者组成员瓜分处理。发布订阅:允许你广播消息给多个消费者组(不同名)。
-
传统的消息有两种模式:队列和发布订阅。
-
在队列模式中,消费者池从服务器读取消息(每个消息只被其中一个读取),优点是允许多个消费者瓜分处理数据,这样可以扩展处理。;
-
发布订阅模式:消息广播给所有的消费者。允许你广播数据到多个消费者,由于每个订阅者都订阅了消息,所以没办法缩放处理。
-
-
broker:
- Kafka 实例,多个 broker 组成一个 Kafka 集群,Kafka 以集群方式运行,集群中每个服务器称为 broker。
- 通常一台机器部署一个 Kafka 实例,一个实例挂了不影响其他实例
-
主题(Topic):
- 一组消息的归纳(代表不同的业务,如超市办会员,付款)。
- 服务端消息的逻辑存储单元。一个 topic 通常包含若干个 Partition 分区。
-
分区(Partition):
- 一个 Topic 中的消息数据按照多个分区组织,分区是 Kafka 消息队列组织的最小单位,一个分区可以看作是一个队列。
- 分布式存储在各个 broker 中, 实现发布与订阅的负载均衡。
- 若干个分区可以被若干个 Consumer 同时消费,达到消费者高吞吐量。
- 单个 partition 有序,整体无序,整体有序就将数据都放到一个 partition 中,但是效率极低。
- 每个分区有一个 leader,零或多个 follower。Leader 处理此分区的所有的读写请求,而follower被动的复制数据。如果leader宕机,其它的一个follower会被推举为新的leader。
- 一台服务器可能同时是一个分区的 leader,另一个分区的 follower。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
-
message:
- 消息,或称日志消息,是 Kafka 服务端实际存储的数据,每一条消息都由一个 key、一个 value 以及消息时间戳 timestamp 组成。
-
offset:
- 偏移量,分区中的消息位置,由 Kafka 自身维护,Consumer 消费时也要保存一份 offset 以维护消费过的消息位置。
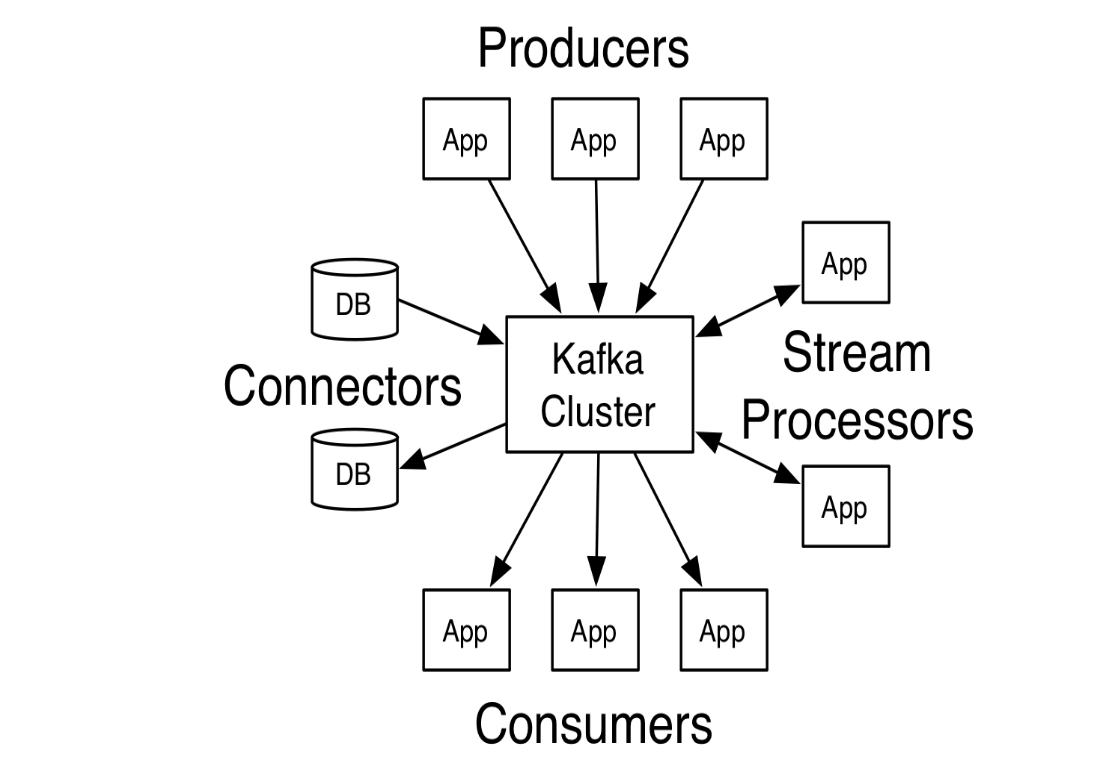
1.3、四个核心 API
- Producer API 发布消息到1个或多个 topic(主题)中。
- Consumer API 来订阅一个或多个topic,并处理产生的消息。
- Streams API 充当一个流处理器,从1个或多个 topic 消费输入流,并生产一个输出流到1个或多个输出 topic,有效地将输入流转换到输出流。
- Connector API 可构建或运行可重用的生产者或消费者,将 topic 连接到现有的应用程序或数据系统。例如,连接到关系数据库的连接器可以捕获表的每个变更。
二、kafka 客户端
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
2.1、 KafkaProduce
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* @author xiandongxie 2020-06-04
*/
public class KafkaProducerTest {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092");
// 判别请求是否为完整的条件(判断是不是成功发送了)。指定了“all”将会阻塞消息,这种设置性能最低,但是是最可靠的
props.put("acks", "all");
// 如果请求失败,生产者会自动重试,我们指定是0次,如果启用重试,则会有重复消息的可能性
props.put("retries", 0);
// 生产者缓存每个分区未发送的消息。缓存的大小是通过 batch.size 配置指定的。值较大的话将会产生更大的批。并需要更多的内存(每个“活跃”的分区都有1个缓冲区)
props.put("batch.size", 16384);
// 默认缓冲可立即发送,即便缓冲空间还没有满,但是,如果想减少请求的数量,可以设置 linger.ms 大于0。
// 这将指示生产者发送请求之前等待一段时间,希望更多的消息填补到未满的批中。这类似于TCP的算法,例如,可能100条消息在一个请求发送,因为我们设置了linger(逗留)时间为1毫秒,然后,如果我们没有填满缓冲区,这个设置将增加1毫秒的延迟请求以等待更多的消息。需要注意的是,在高负载下,相近的时间一般也会组成批,即使是 linger.ms=0。在不处于高负载的情况下,如果设置比0大,以少量的延迟代价换取更少的,更有效的请求。
props.put("linger.ms", 1);
// 控制生产者可用的缓存总量,如果消息发送速度比其传输到服务器的快,将会耗尽这个缓存空间。当缓存空间耗尽,其他发送调用将被阻塞,阻塞时间的阈值通过 max.block.ms 设定,之后它将抛出一个TimeoutException。
props.put("buffer.memory", 33554432);
// key.serializer 和 value.serializer,将用户提供的 key 和 value 对象 ProducerRecord 转换成字节,可以使用附带的ByteArraySerializaer或StringSerializer处理简单的string或byte类型。
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 100; i < 500; i++)
// send()方法是异步的,添加消息到缓冲区等待发送,并立即返回。生产者将单个的消息批量在一起发送来提高效率
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
}
}
2.2、KafkaConsumer
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
/**
* 【自动提交偏移量】的简单的kafka消费者API
*
* @author xiandongxie
*/
public class KafkaConsumerTest {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092");
// 消费者组名称
props.put("group.id", "test");
// 设置 enable.auto.commit,偏移量由 auto.commit.interval.ms 控制自动提交的频率。
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 指定订阅 topic 名称
consumer.subscribe(Arrays.asList("my-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号