

二、YARN
一、YARN 介绍
yarn 是下一代 MapReduce,即 MRv2,是在第一代 MapReduce 基础上演变而来的,主要是为了解决原始 Hadoop 扩展性较差,不支持多计算框架而提出的,通俗讲是跑任。
其核心思想:将 MR1 中 JobTracker 资源管理和作业调用两个功能分开,分别由 ResourceManager 和 ApplicationMaster 进程来实现。
- ResourceManager:负责整个集群的资源管理和调度;
- ApplicationMaster:每个应用程序特有,负责单个应用程序的管理,负责应用程序相关事务,比如任务调度、任务监控和容错等。
1.1 MRv1 VS MRv2
MRv1:
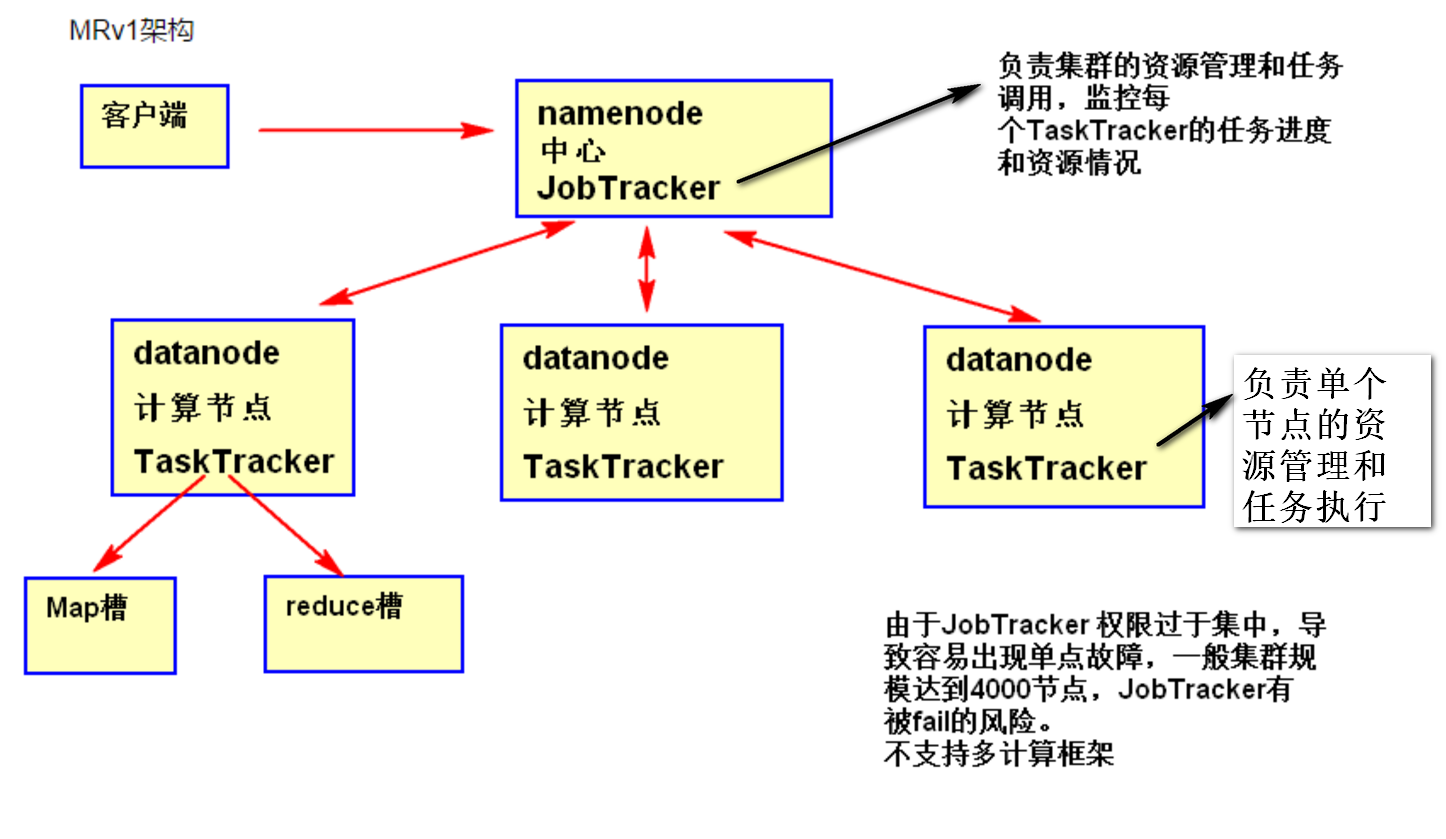
- 扩展性差。在 MRv1 中,JobTracker 同时兼备了资源管理和作业控制两个功能,这成为系统的一个最大瓶颈,严重制约了Hadoop集群扩展性。
- 可靠性差。MRv1 采用了master/slave结构,其中,master 存在单点故障问题,一旦它出现故障将导致整个集群不可用。
- 资源利用率低。MRv1 采用了基于槽位的资源分配模型,槽位是一种粗粒度的资源划分单位,通常一个任务不会用完槽位对应的资源,且其他任务也无法使用这些空闲资源。此外,Hadoop 将槽位分为 Map Slot 和 Reduce Slot 两种,且不允许它们之间共享,常常会导致一种槽位资源紧张而另外一种闲置(比如一个作业刚刚提交时,只会运行 Map Task,此时 Reduce Slot闲置)。
- 无法支持多种计算框架。随着互联网高速发展,MapReduce 这种基于磁盘的离线计算框架已经不能满足应用要求,从而出现了一些新的计算框架,包括内存计算框架、流式计算框架和迭代式计算框架等,而 MRv1 不能支持多种计算框架并存。
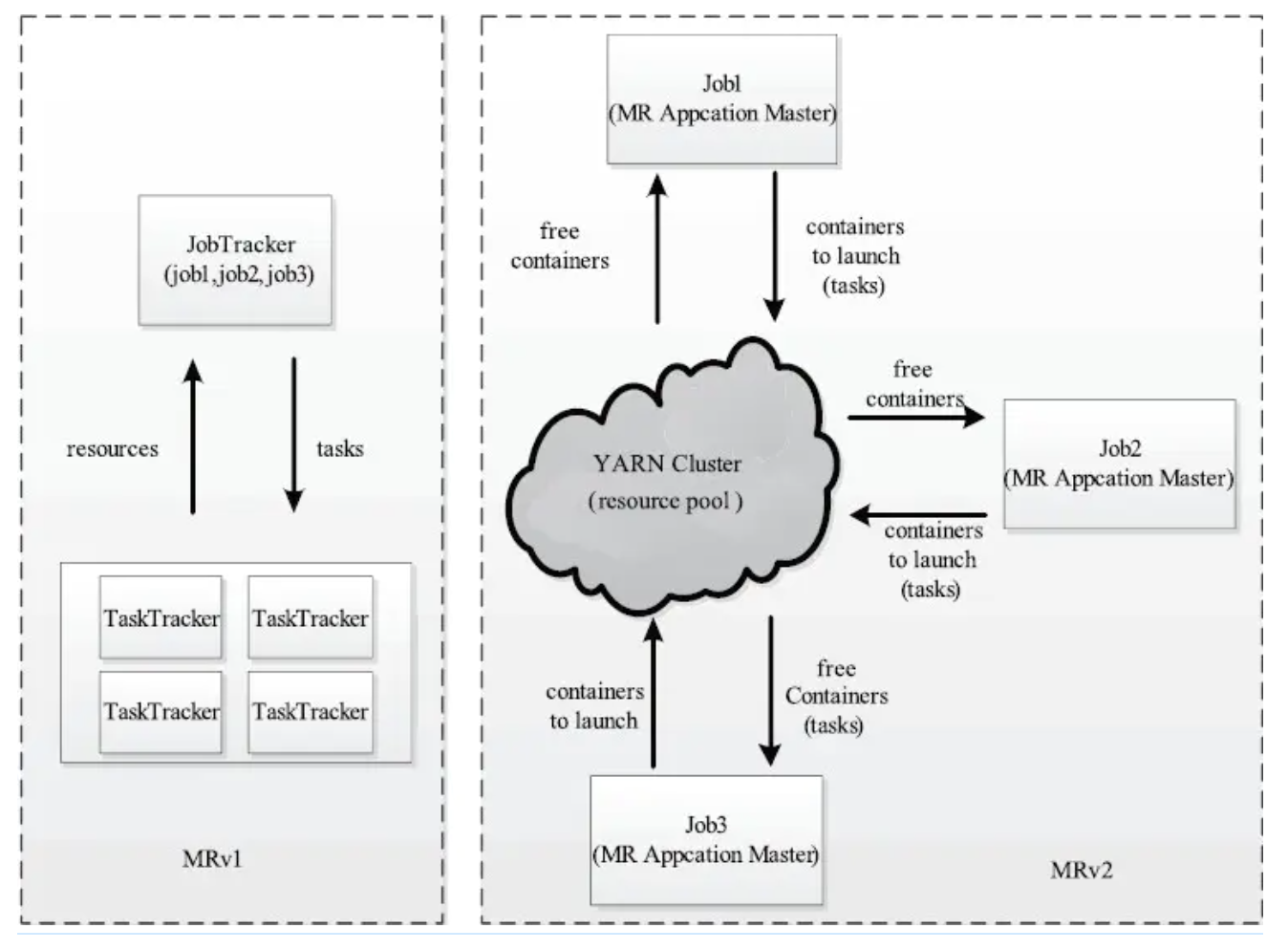
MRv2:
与 MapReduce v1 相比,YARN 采用了一种分层的集群框架,它解决了旧 MapReduce 一系列的缺陷,具有以下几种优势。
- YARN 通过将资源管理和应用程序管理两部分分剥离开,分别由 ResouceManager 和 ApplicationMaster 负责,其中,ResouceManager 专管集群资源管理和调度,而 ApplicationMaster 则负责与具体应用程序相关的任务切分、任务调度和容错等,每个应用程序对应一个 ApplicationMaster。
- ARN 具有向后兼容性,用户在 MRv1 上运行的作业,无需任何修改即可运行在 YARN 之上。
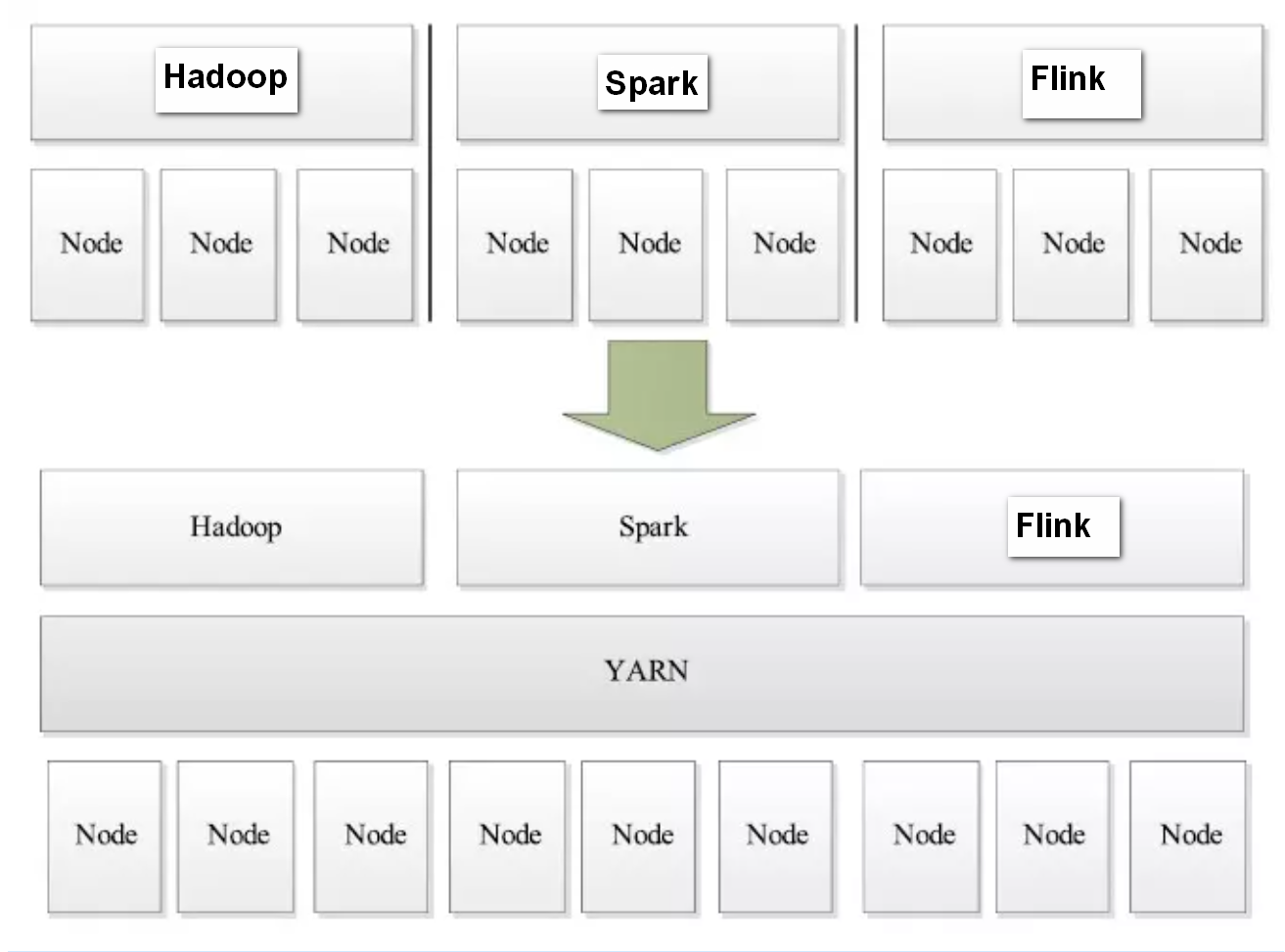
- 支持多个框架, YARN 不再是一个单纯的计算框架,而是一个框架管理器,用户可以将各种各样的计算框架移植到 YARN 之上,由 YARN 进行统一管理和资源分配,提高集群资源的利用率。
- 框架升级更容易, 在 YARN 中,各种计算框架不再是作为一个服务部署到集群的各个节点上,而是被封装成一个用户程序库(lib)存放在客户端,当需要对计算框架进行升级时,只需升级用户程序库即可。
- 运维成本低、数据共享。
1.2 YARN 的架构
yarn 主要由 ResourceManager、NodeManager、ApplicationMaster、Container、Scheduler 等几个组件构成。
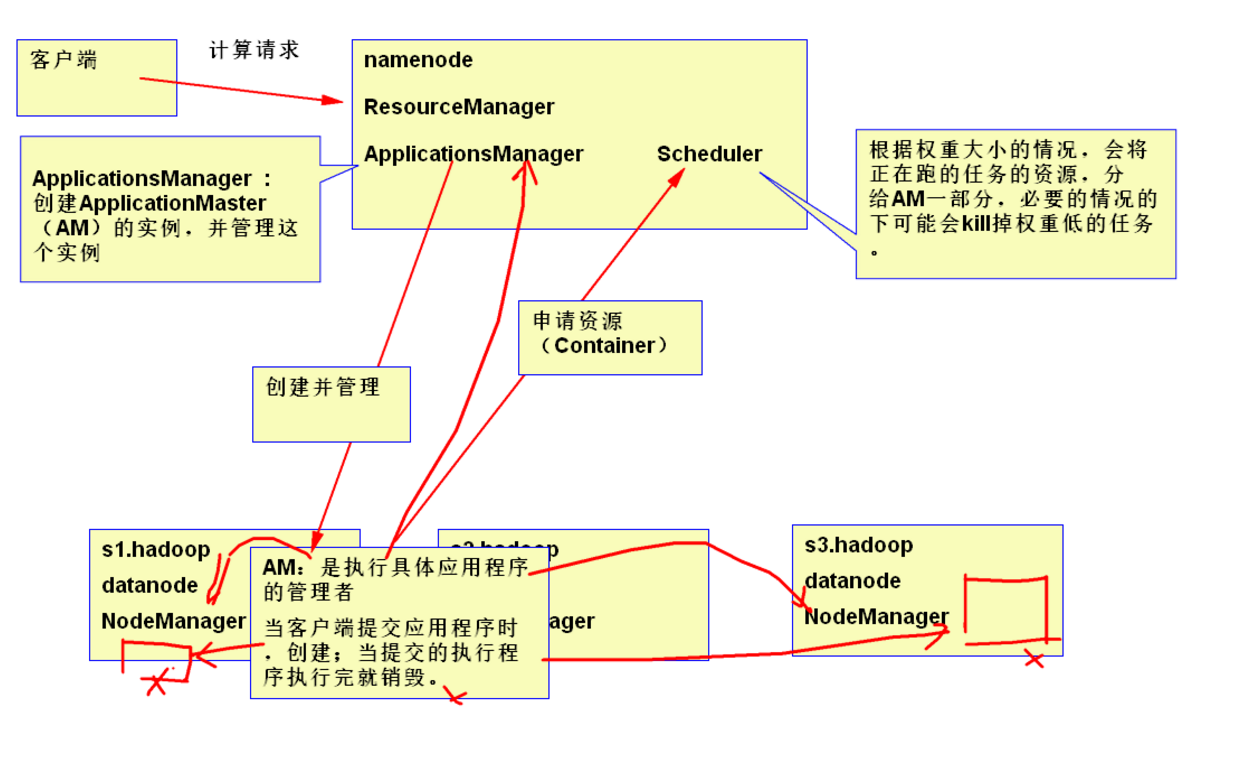
- ResourceManager(RM)
- RM 是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(ApplicationsManager,ASM),通俗讲是用于管理 NodeManager 节点的资源,包括cup、内存等。
- Scheduler(调度器)
- 调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序;在资源紧张的情况下,可以kill掉优先级低的,来运行优先级高的任务。
- 需要注意的是,该调度器是一个“纯调度器”,它不再从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的 ApplicationMaster 完成。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(Resource Container,简称Container)。
- 该调度器是一个可插拔的组件,用户可根据自己的需要设计新的调度器,YARN提供了多种直接可用的调度器,比如Fair Scheduler和Capacity Scheduler等。
- ApplicationsManager(应用程序管理器)
- 负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动 ApplicationMaster、监控 ApplicationMaster 运行状态并在失败时重新启动它等。
- ApplicationMaster(AM)
- ApplicationMaster 管理在 YARN 内运行的每个应用程序实例。每个应用程序对应一个 ApplicationMaster。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配),通俗讲是管理发起的任务,随着任务创建而创建,任务的完成而结束。
- NodeManager(NM)
- NM 是每个节点上的资源和任务管理器,一方面,它会定时地向 RM 汇报本节点上的资源使用情况和各个 Container 的运行状态;另一方面,它接收并处理来自 AM 的 Container 启动/停止等各种请求。
- Container
- Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当 AM 向 RM 申请资源时, RM 为 AM 返回的资源便是用Container 表示的。YARN 会为每个任务分配一个 Container,且该任务只能使用该 Container 中描述的资源。
1.3 YARN 的工作流程
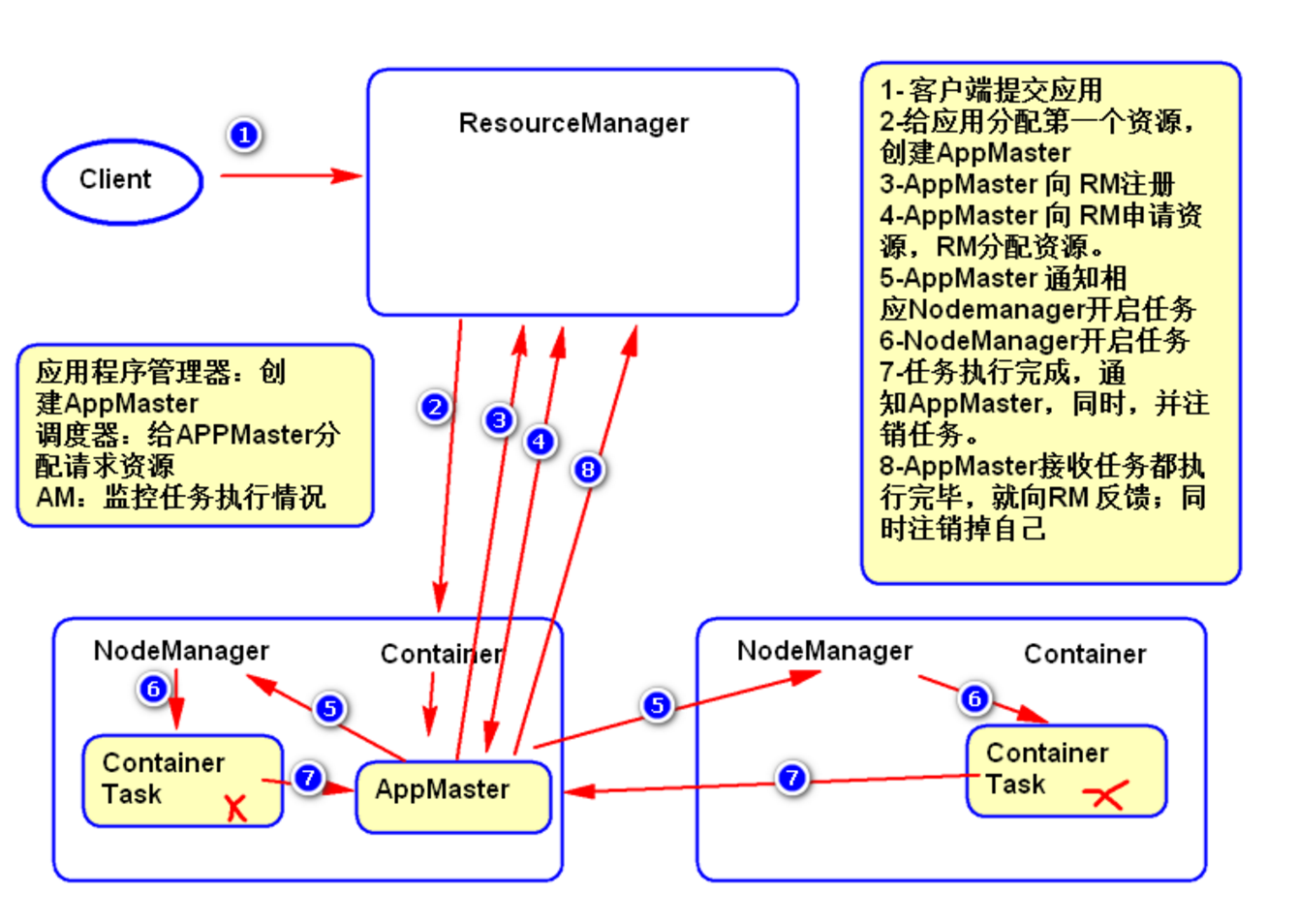
- 用户向YARN中提交应用程序.
- ResourceManager 为该应用程序分配第一个 Container,并与对应的NodeManager通信,要求它在这个 Container 中启动应用程序的 ApplicationMaster。
- ApplicationMaster 首先向 ResourceManager 注册,目的是让用户可以直接通过 ResourceManager 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束。即重复步骤 4-7。
- ApplicationMaster 向 ResourceManager 的 scheduler 申请和领取资源。
- ApplicationMaster 申请到资源后,便与对应的 NodeManager 通信,要求它启动任务。
- NodeManager启动任务。
- 各个任务向 ApplicationMaster 汇报自己的状态和进度,以便让 ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 应用程序运行完成后,ApplicationMaster 向 ResourceManager 注销并关闭自己。
二、YARN 的主要配置
2.1 yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- 重要开始 start -->
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
<description>单个任务可申请的最小虚拟CPU个数</description>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>3</value>
<description>单个任务可申请的最大虚拟CPU个数,此参数对应yarn.nodemanager.resource.cpu-vcores,建议最大为一个物理CPU的数量</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
<description>该节点上可分配的物理内存总量</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>3</value>
<description>该节点上YARN可使用的虚拟CPU个数,一个物理CPU对应3个虚拟CPU</description>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>43008</value>
<description>单个任务可申请的最多物理内存量</description>
</property>
<!-- 重要开始 end -->
<!-- yarn ha start -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>是否开启yarn ha</description>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
<description>ha状态切换为自动切换</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
<description>RMs的逻辑id列表</description>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>nn1.hadoop:2181,nn2.hadoop:2181,s1:2181</value>
<description>ha状态的存储地址</description>
</property>
<!-- yarn ha end -->
<!-- RM1 configs start -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>nn1.hadoop:8032</value>
<description>ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>nn1.hadoop:8030</value>
<description>ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>nn1.hadoop:8089</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>nn1.hadoop:8088</value>
<description>ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>nn1.hadoop:8031</value>
<description>ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等。</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>nn1.hadoop:8033</value>
<description>ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等</description>
</property>
<!-- RM1 configs end -->
<!-- RM2 configs start -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>nn2.hadoop:8032</value>
<description>ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>nn2.hadoop:8030</value>
<description>ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资>源等。</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>nn2.hadoop:8089</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>nn2.hadoop:8088</value>
<description>ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>nn2.hadoop:8031</value>
<description>ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等。</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>nn2.hadoop:8033</value>
<description>ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等</description>
</property>
<!-- RM2 configs end -->
<!-- scheduler begin -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>调度器实现类</description>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>fair-scheduler.xml</value>
<description>自定义XML配置文件所在位置,该文件主要用于描述各个队列的属性,比如资源量、权重等</description>
</property>
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
<description>当应用程序未指定队列名时,是否指定用户名作为应用程序所在的队列名。如果设置为false或者未设置,所有未知队列的应用程序将被提交到default队列中,默认值为true</description>
</property>
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
<description>是否支持抢占</description>
</property>
<property>
<name>yarn.scheduler.fair.sizebasedweight</name>
<value>false</value>
<description>在一个队列内部分配资源时,默认情况下,采用公平轮询的方法将资源分配各各个应用程序,而该参数则提供了外一种资源分配方式:按照应用程序资源需求数目分配资源,即需求资源数量越多,分配的资源越多。默认情况下,该参数值为false</description>
</property>
<property>
<name>yarn.scheduler.increment-allocation-mb</name>
<value>256</value>
<description>内存规整化单位,默认是1024,这意味着,如果一个Container请求资源是700mB,则将被调度器规整化为 (700mB / 256mb) * 256mb=768mb</description>
</property>
<property>
<name>yarn.scheduler.assignmultiple</name>
<value>true</value>
<description>是否启动批量分配功能。当一个节点出现大量资源时,可以一次分配完成,也可以多次分配完成。默认情况下,参数值为false</description>
</property>
<property>
<name>yarn.scheduler.fair.max.assign</name>
<value>10</value>
<description>如果开启批量分配功能,可指定一次分配的container数目。默认情况下,该参数值为-1,表示不限制</description>
</property>
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
<description>如果提交的队列名不存在,Scheduler会自动创建一个该队列,默认开启</description>
</property>
<!-- scheduler end -->
<!--目录相关 start -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/yarn/local</value>
<description>中间结果存放位置,存放执行Container所需的数据如可执行程序或jar包,配置文件等和运行过程中产生的临时数据</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/yarn/logs</value>
<description>Container运行日志存放地址(可配置多个目录)</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>是否启用日志聚集功能</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/app-logs</value>
<description>当应用程序运行结束后,日志被转移到的HDFS目录(启用日志聚集功能时有效)</description>
</property>
<!--目录相关 end -->
<!-- 其它 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>1209600</value>
<description>nodemanager上所有Container的运行日志在HDFS中的保存时间,保留半个月</description>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:9103</value>
</property>
<property>
<name>yarn.nodemanager.health-checker.script.path</name>
<value>/usr/local/hadoop/conf/health-check.sh</value>
<description>健康状况检测脚本,脚本输出以“ERROR”开头的字符串,则认为节点处于不健康状态态</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序</description>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>pseudo-yarn-rm-cluster</value>
<description>集群的Id</description>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
<description>默认值为false,也就是说resourcemanager挂了相应的正在运行的任务在rm恢复后不能重新启动</description>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
<description>配置RM状态信息存储方式3有两种,一种是FileSystemRMStateStore,另一种是MemoryRMStateStore,还有一种目前较为主流的是zkstore</description>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>nn1.hadoop:2181,nn2.hadoop:2181,s1:2181</value>
<description>当使用ZK存储时,指定在ZK上的存储地址。</description>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:8042</value>
</property>
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:8040</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>nn1.hadoop:8041</value>
</property>
<!-- 关闭内存检测 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>虚拟内存检测,默认是True</description>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
<description>物理内存检测,默认是True</description>
</property>
</configuration>
2.2 yarn-env.sh
#RESOURCEMANAGER内存
export YARN_RESOURCEMANAGER_HEAPSIZE=512
#NODEMANAGER内存
export YARN_NODEMANAGER_HEAPSIZE=256
三、YARM 的调度器
3.1 yarn 的三种调度策略
1. FIFO策略
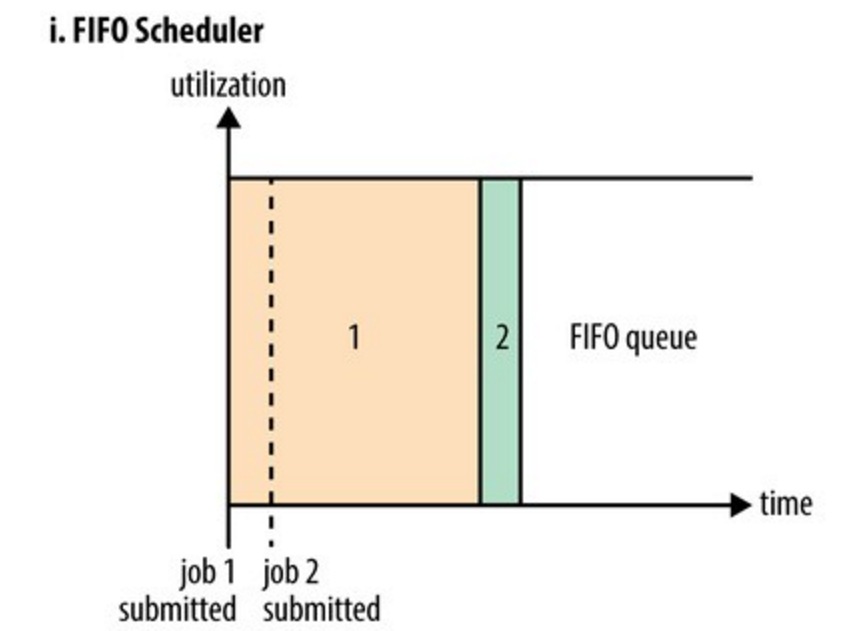
- 有两个任务,第一个是任务需要大量资源;第二个需要少量资源,但是紧急重要任务,此时第二个需要等待第一个执行完,才能执行第二个。
- 弊端:由于顺序执行任务,如果第一个是大量资源,后续任务需要等待。没有做到资源共享。
2. 容量调度策略

- 将集群资源,给队列分配部分资源,每个队列互不干涉
- 弊端:某个队列突然来个大的任务,那这个大的任务不会占用其他队列资源,执行时间长,效率低。
- 配置弹性队列:允许队列超过自己配置的容量,但仅在其他队列没有占用资源的情况下。
- 容量调度,加上弹性队列后,可以实现资源共享。
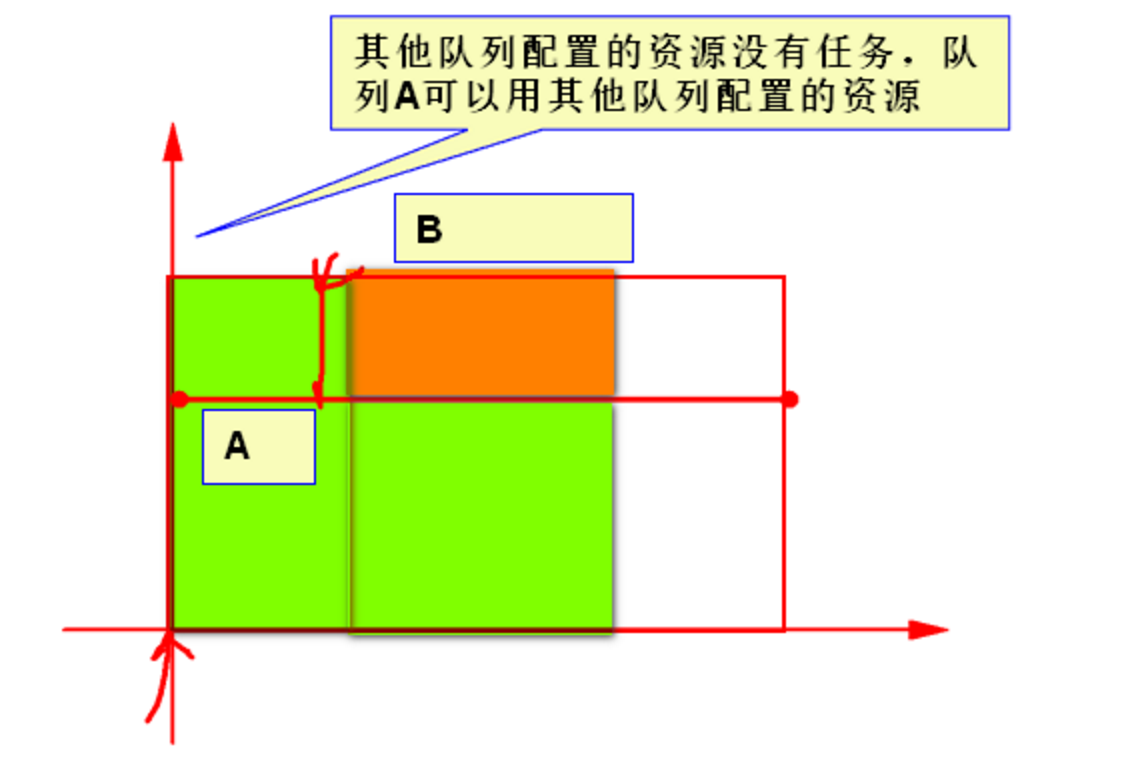
3. 公平调度策略
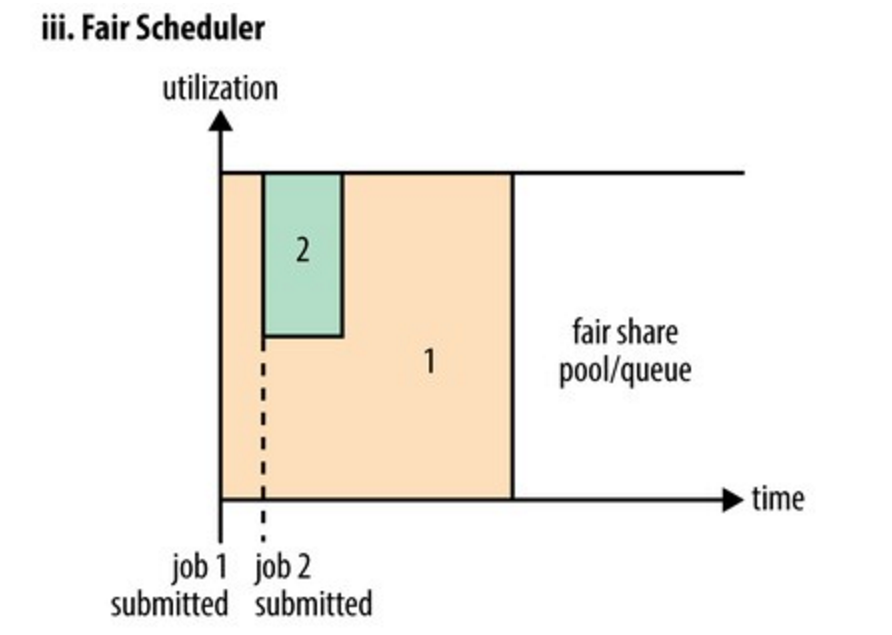
- 队列间可以互相共享资源,如果权重高的任务来了,权重低的任务会分给权重高的任务部分资源,必要时,可kill掉权重低的任务。
- Steady Fair Share(稳定的公平份额):
- 是 Yarn 根据每个队列的 minShare、maxShare 和 weight 的配置计算得到的理论上应该分配给这个队列的最大资源,它与这个队列当前是否有app正在运行无关,只和我们在fair-scheduler.xml中的配置有关。
- Instantaneous Fair Share(瞬时的公平份额)
- 指的是实时动态分配的资源,它的值是随着集群资源的变动而实时变动的。
- 如果集群中有队列从 active 变为 inactive,那么剩余这些队列瓜分到的 instaneous fair shared 都会随之变大,反之,如果有一个队列从 inactive 变为active,则剩余每个队列的 instaneous fair share 会随之变小,即 instaneous fair share 会变小。
配置公平调度策略:
启用公平调度策略,配置属性yarn.resourcemanager.scheduler.class
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>公平调度器</description>
</property>
队列配置,需要配置属性yarn.scheduler.fair.allocation.file
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>fair-scheduler.xml</value>
<description>自定义XML配置文件所在位置,该文件主要用于描述各个队列的属性,比如资源量、权重等</description>
</property>
并在fair-scheduler.xml 文件中配置队列、用户、以及匹配规则等。
抢占:
- 公平调度器支持抢占功能。
- 所谓抢占,就是允许调度器终止那些占用资源超过了其公平份额的队列的容器,这些容器资源释放后可以分配给资源数量低于应得份额的队列。
- 注意,抢占会降低整个集群的效率,因为被终止的containers 需要重新执行。
启用抢占,配置yarn-site.xml 的 yarn.scheduler.fair.preemption 属性
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
<description>是否支持抢占</description>
</property>
两个相关抢占超时设置
在fair-scheduler.xml 文件中配置,为所有队列设置默认的超时时间
<!-- 一个队列在该时间内获得的资源仍然低于其共享份额的一半,那么调度器会抢占其他容器,以秒计算 -->
<fairSharePreemptionTimeout>60</fairSharePreemptionTimeout>
<!-- 一个队列在该时间内未获得被承诺的最小共享资源,那么调度器会抢占其他容器,以秒计算 -->
<defaultMinSharePreemptionTimeout>60</defaultMinSharePreemptionTimeout>

