


2、Hive的排序,窗口函数
一、Hive的排序
- order by:会对输入做全局排序,因此只有一个 reducer。
- order by 在 hive.mapred.mode = strict 模式下 必须指定 limit 否则执行会报错。
- sort by:不是全局排序,其在数据进入 reducer 前完成排序。
- 因此,如果用 sort by 进行排序,并且设置 mapred.reduce.tasks>1(如果为1就和 order by 效果一致), 则 sort by 只保证每个 reducer 的输出有序,不保证全局有序。
- distribute by:(类似于分桶),就是把相同的 key 分到一个 reducer 中,根据 distribute by 指定的字段对数据进行划分到不同的输出 reduce 文件中。
- CLUSTER BY (cluster):
- cluster by column = distribute by column + sort by column (注意,都是针对 column 列,且采用默认 ASC (升序),不能指定排序规则为 asc 或者 desc)
二、窗口函数
- 聚合函数:(如sum()、avg()、max()等等)是针对定义的行集(组)执行聚集,每组只返回一个值。
- 窗口函数:是针对定义的行集(组)执行聚集,可为每组返回多个值。如既要显示聚集前的数据,又要显示聚集后的数据。
2.1、over( )
over (order by col1) --按照 col1 排序 over (partition by col1) --按照 col1 分区 over (partition by col1 order by col2) -- 按照 col1 分区,按照 col2 排序 --带有窗口范围 over (partition by col1 order by col2 ROWS 窗口范围) -- 在窗口范围内,按照 col1 分区,按照 col2 排序
over_table id name age 1 a1 10 2 a2 10 3 a3 10 4 a4 20 5 a5 20 6 a6 20 7 a7 20 8 a8 30 --建表 CREATE TABLE over_table( id int, name string, age int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; -- 窗口范围是整个表 -- 按照age排序,每阶段的age数据进行统计求和 select id, name, age, count() over (order by age) as n from over_table; -- 结果如下 1 a1 10 3 2 a2 10 3 3 a3 10 3 4 a4 20 7 5 a5 20 7 6 a6 20 7 7 a7 20 7 8 a8 30 8 ------------------------------------ -- 窗口范围是表下按照age进行分区 -- 在分区里面,再按照age进行排序 select id, name, age, count() over (partition by age order by age) as n from wt1; -- 结果如下 1 a1 10 3 2 a2 10 3 3 a3 10 3 4 a4 20 4 5 a5 20 4 6 a6 20 4 7 a7 20 4 8 a8 30 1 ---------------------------------- -- 窗口范围是表下按照age进行分区 -- 在分区里面,再按照id进行排序 select id, name, age, count() over (partition by age order by id) as n from wt1; 1 a1 10 1 2 a2 10 2 3 a3 10 3 4 a4 20 1 5 a5 20 2 6 a6 20 3 7 a7 20 4 8 a8 30 1 --------------------------------------
2.2、序列函数
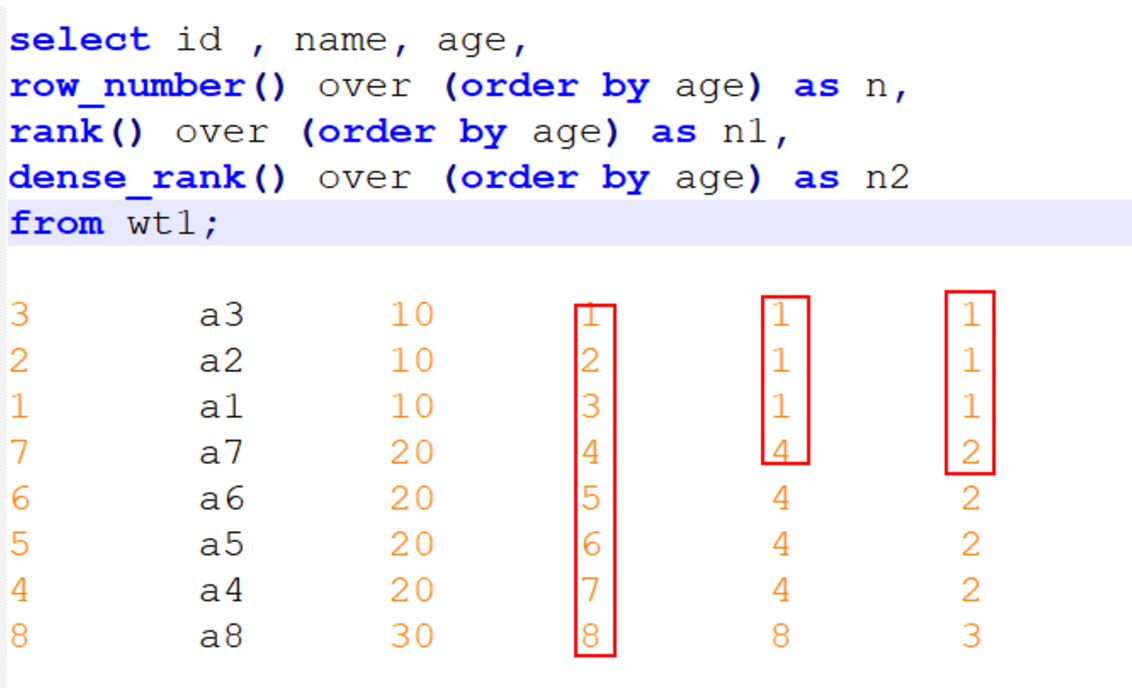
- row_number:会对所有数值,输出不同的序号,序号唯一且连续,如:1、2、3、4、5。
- rank:会对相同数值,输出相同的序号,而且下一个序号间断,如:1、1、3、3、5。
- dense_rank:会对相同数值,输出相同的序号,但下一个序号不间断,如:1、1、2、2、3。
over 中 partition by 和 distribute by 区别
- partition by [key..] order by [key..] 只能在窗口函数中使用,
- distribute by [key...] sort by [key...] 在窗口函数和 select 中都可以使用。
- 窗口函数中两者是没有区别的
- where 后面不能用 partition by
2.3、Window 函数
- ROWS 窗口函数中的行选择器 rows between [n|unbounded preceding]|[n|unbounded following]|[current row] and [n|unbounded preceding]|[n|unbounded following]|[current row]
- 参数解释:
- n 行数
- unbounded 不限行数
- preceding 在前N行
- following 在后N行
- current row 当前行

