


1、Hive介绍
一、Hive介绍与原理分析
- Hive是一个基于Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。
- 它是Facebook 2008年8月开源的一个数据仓库框架,提供了类似于SQL语法的HQL(hiveSQL)语句作为数据访问接口。
- Hive数据存储在HDFS上,因此可以存大量数据。
- Hive执行查询的时候生成的是mapreduce任务。所以可以处理大量数据,但是速度比较慢。
1.1、hive的优缺点
优点:
- Hive 使用类SQL 查询语法, 最大限度的实现了和SQL标准的兼容,大大降低了传统数据分析人员处理大数据的难度
- 使用JDBC/ODBC接口,开发人员更易开发应用;
- 以MR 作为计算引擎、HDFS 作为存储系统,为超大数据集设计的计算/ 扩展能力;
- 统一的元数据管理(Derby、MySql等),并可与Pig 、spark等共享;
缺点:
- Hive 的HQL 表达的能力有限,比如不支持UPDATE(更新)、非等值连接、DELETE、INSERT单条等;
- 由于Hive自动生成MapReduce 作业, HQL 调优困难;
- 粒度较粗,可控性差,是因为数据是读的时候进行类型的转换,mysql关系型数据是在写入的时候就检查了数据的类型。
- mysql 插入数据时,会校验数据和表结构字段的一致性;
- hive 插入数据时不校验,查询的时候校验。
- hive生成MapReduce作业,高延迟,不适合实时查询。
1.2、与关系数据库的区别
- hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
- hive使用mapreduce做运算,与传统数据库相比运算数据规模要大得多;
- 关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据挖掘设计的,实时性很差;实时性差导致hive的应用场景和关系数据库有很大的区别;
- Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比Hive差很多。
| HIVE | RDBMS | |
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or Local FS |
| 执行 | MapReduce | 数据库引擎 |
| 数据存储校验 | 存储不校验 | 存储校验 |
| 可扩展性 | 强 | 有限 |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
1.3、hive的组成
服务端组件和客户端组件:
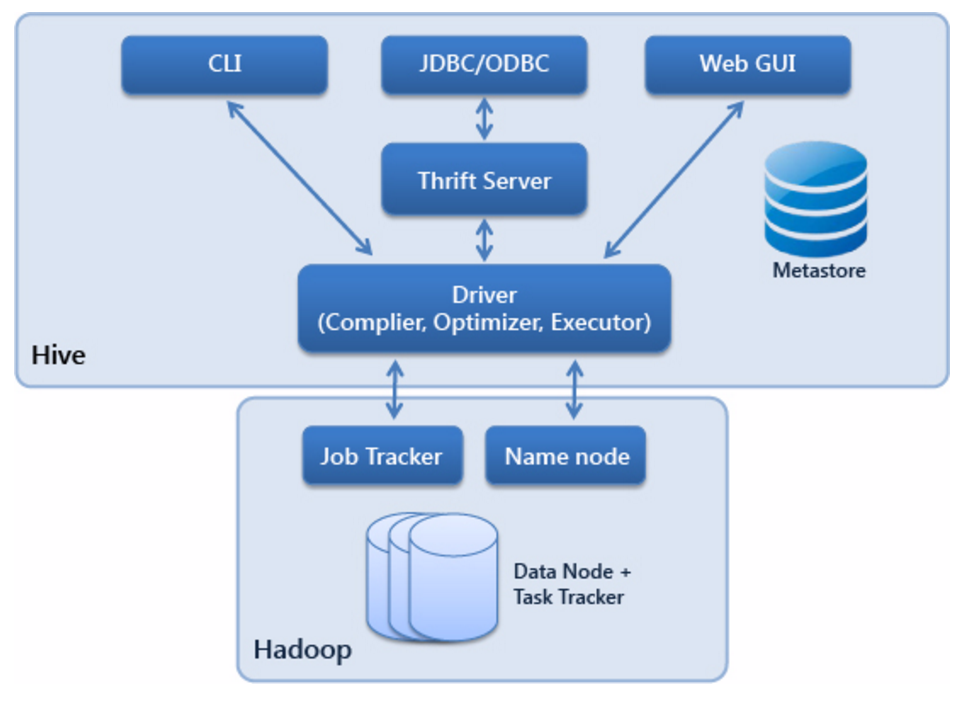
- 服务端组件:
- Driver组件:该组件包括Complier、Optimizer和Executor,它的作用是将HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的MapReduce计算框架。
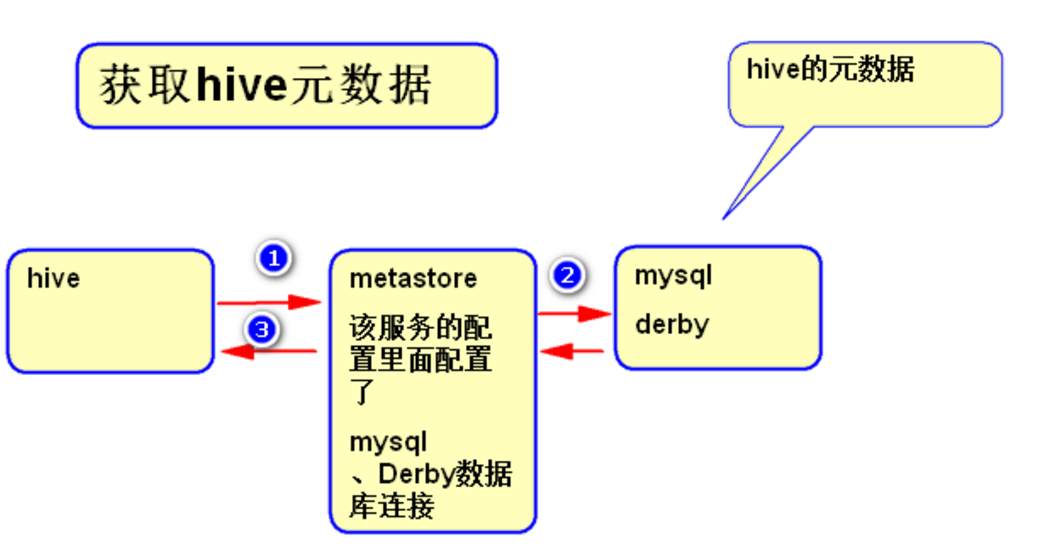
- Metastore组件:元数据服务组件,这个组件存取Hive的元数据,Hive的元数据存储在关系数据库里,Hive支持的关系数据库有Derby和Mysql。
- 作用是:客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。
- Thrift服务:Thrift是Facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,Hive集成了该服务,能让不同的编程语言调用Hive的接口。
- 客户端组件:
- CLI:Command Line Interface,命令行接口。
- JDBC/ODBC:Hive架构的JDBC和ODBC接口是建立在Thrift客户端之上。
- WEBGUI:Hive客户端提供了一种通过网页的方式访问Hive所提供的服务。这个接口对应Hive的HWI组件(Hive Web Interface),使用前要启动HWI服务。
1.4、Hive sql的执行过程
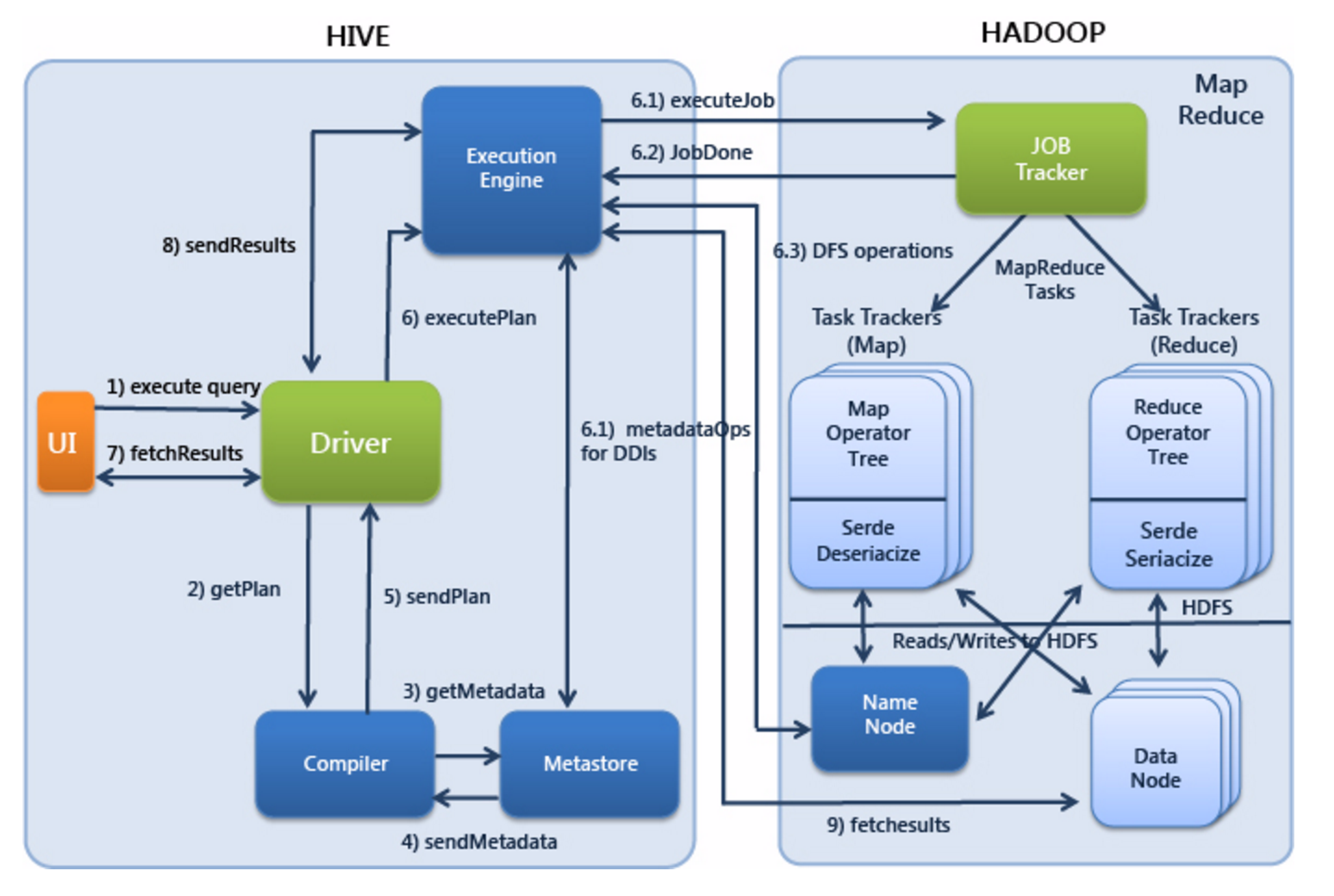
- Execute Query:hive界面如命令行或Web UI将查询发送到Driver(任何数据库驱动程序如JDBC、ODBC,等等)来执行。
- Get Plan:Driver根据查询编译器解析query语句,验证query语句的语法,查询计划或者查询条件。
- Get Metadata:编译器将元数据请求发送给Metastore(数据库)。
- Send Metadata:Metastore将元数据作为响应发送给编译器。
- Send Plan:编译器检查要求和重新发送Driver的计划。到这里,查询的解析和编译完成。
- Execute Plan:Driver将执行计划发送到执行引擎。
- Execute Job:hadoop内部执行的是mapreduce工作过程,任务执行引擎发送一个任务到资源管理节点(resourcemanager),资源管理器分配该任务到任务节点,由任务节点上开始执行mapreduce任务。
- Metadata Ops:在执行引擎发送任务的同时,对hive的元数据进行相应操作。
- Fetch Result:执行引擎接收数据节点(data node)的结果。
- Send Results:执行引擎发送这些合成值到Driver。
- Send Results:Driver将结果发送到hive接口。
二、hive的三种模式
2.1、使用内置的derby数据库做元数据的存储
- 使用内置的derby数据库做元数据的存储,操作derby数据库做元数据的管理,使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。
- 这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,目录不同时元数据也无法共享。
- 不适合生产环境只适合练习。
2.2、本地模式
- 使用mysql做元数据的存储,操作mysql数据库做元数据的管理,可以多个hive client一起使用,并且可以共享元数据。
- 但mysql的连接信息明文存储在客户端配置,不便于数据库连接信息保密和以后对元数据库进行更改。
- 如果客户端太多也会对mysql造成较大的压力,因为每个客户端都自己发起连接。
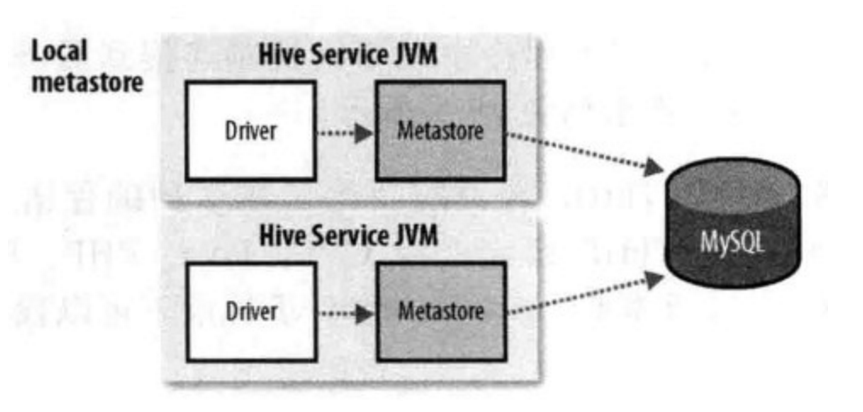
- driver 和 metastore在同一台机器上, driver能访问到mysql的数据库连接信息,不安全。
- 多个hive连一个mysql,这样mysql压力就会增加
2.3、远程模式
- 使用mysql做元数据的存储,使用metastore服务做元数据的管理,优点便于元数据库信息的保密,因为只需要在运行metastore的机器上配置元数据库连接信息,客户端只需要配置metastore连接信息即可。
- 缺点会引发单点问题,例如metastore服务挂了,其它hive终端就获取不到元数据信息了。
- 企业环境推荐使用第此种模式。
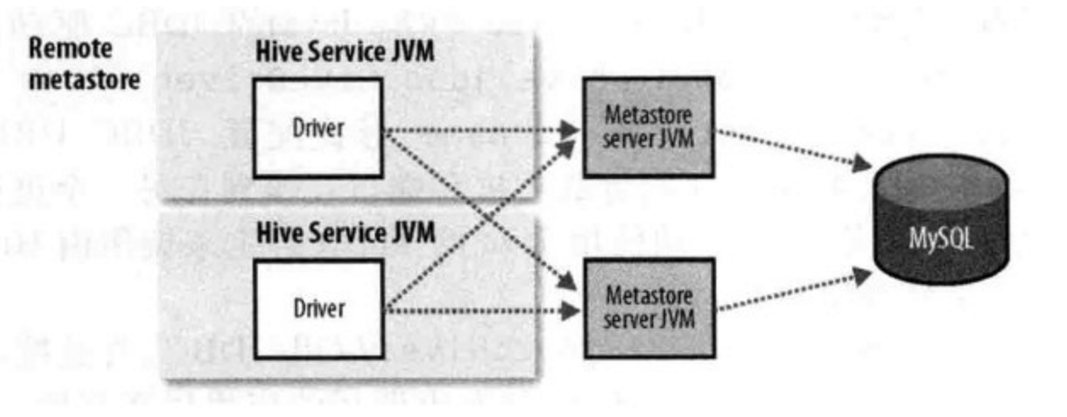
- driver 和 metastore不在同一台机器上, driver通过metastore访问到mysql的数据库连接信息,安全性高
- 通过高可用方案,设置多个metastore,来避免metastore的单点问题。
本地模式和远程模式的区别是:
- 本地模式不需要单独起metastore服务,用的是跟hive在同一个进程里的metastore服务。
- 远程模式需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。
- 远程模式的metastore服务和hive运行在不同的进程里。
三、hive的数据组织
基本概念和关系型数据库类似,如:库,表,列,分区。按照数据组织粒度由大到小说明:
- 数据库Databases:Database起到命名空间的功能,避免表,视图等定义的混乱,同时也为权限的定义及分配提供良好的隔离。
- 在hdfs中表现为${hive.metastore.warehouse.dir}(/hive/warehouse)目录下一个文件夹。 ( 如:/hive/warehouse/xxd.db),xxd----数据库
- 表Tables: 每个表包含一个主题信息,有多个属性字段组成的二维数据集合,一个数据库可以包含多张表。
- 在hdfs中表现为db目录下的一个文件夹。(如:/hive/warehouse/xxd.db/user_info)user_info--表
- 分区 Partitions: 每个表可以有一个或多个分区键值,是数据的存储单元,可以按分区key划分查询数据范围,有效提高查询效率。比如可以按月和按天设计表分区,查询是指定查某天则不需要扫描整月数据。
- 在hdfs中表现为table目录下的子目录 。
- 桶 Buckets: 表分区下的数据还可以按照某几列hash进行划分,是更细粒度的数据范围。桶表就是对应不同的文件。为了抽样,不用扫描全表,桶是对文件更细粒度的划分,和分区无关
