

spark系列-3、缓存、共享变量
一、persist 和 unpersist
1.1、persist() :
用来设置RDD的存储级别
| 存储级别 | 意义 |
| MEMORY_ONLY | 将RDD作为反序列化的的对象存储JVM中。如果RDD不能被内存装下,一些分区将不会被缓存,并且在需要的时候被重新计算。这是是默认的级别 |
| MEMORY_AND_DISK | 将RDD作为反序列化的的对象存储在JVM中。如果RDD不能被与内存装下,超出的分区将被保存在硬盘上,并且在需要时被读取 |
| MEMORY_ONLY_SER | 将RDD作为序列化的的对象进行存储(每一分区占用一个字节数组)。通常来说,这比将对象反序列化的空间利用率更高,尤其当使用fast serializer,但在读取时会比较占用CPU |
| MEMORY_AND_DISK_SER | 与MEMORY_ONLY_SER相似,但是把超出内存的分区将存储在硬盘上而不是在每次需要的时候重新计算 |
| DISK_ONLY | 仅仅使用磁盘存储RDD的数据 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2 | 与上述的存储级别一样,但是将每一个分区都复制到集群两个结点上 |

import org.apache.spark.storage.StorageLevel val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8), 8) val rdd2 = rdd1.persist(StorageLevel.DISK_ONLY) // 缓存到磁盘上 rdd2.count()

1.2、unpersist():
1.3、修改executor的storage memory内存比例配置:
spark-shell --master spark://nn1.hadoop:7077 --executor-cores 3 --executor-memory 5G --conf spark.memory.useLegacyMode=true --conf spark.storage.memoryFraction=0.1
观察spark-UI界面:
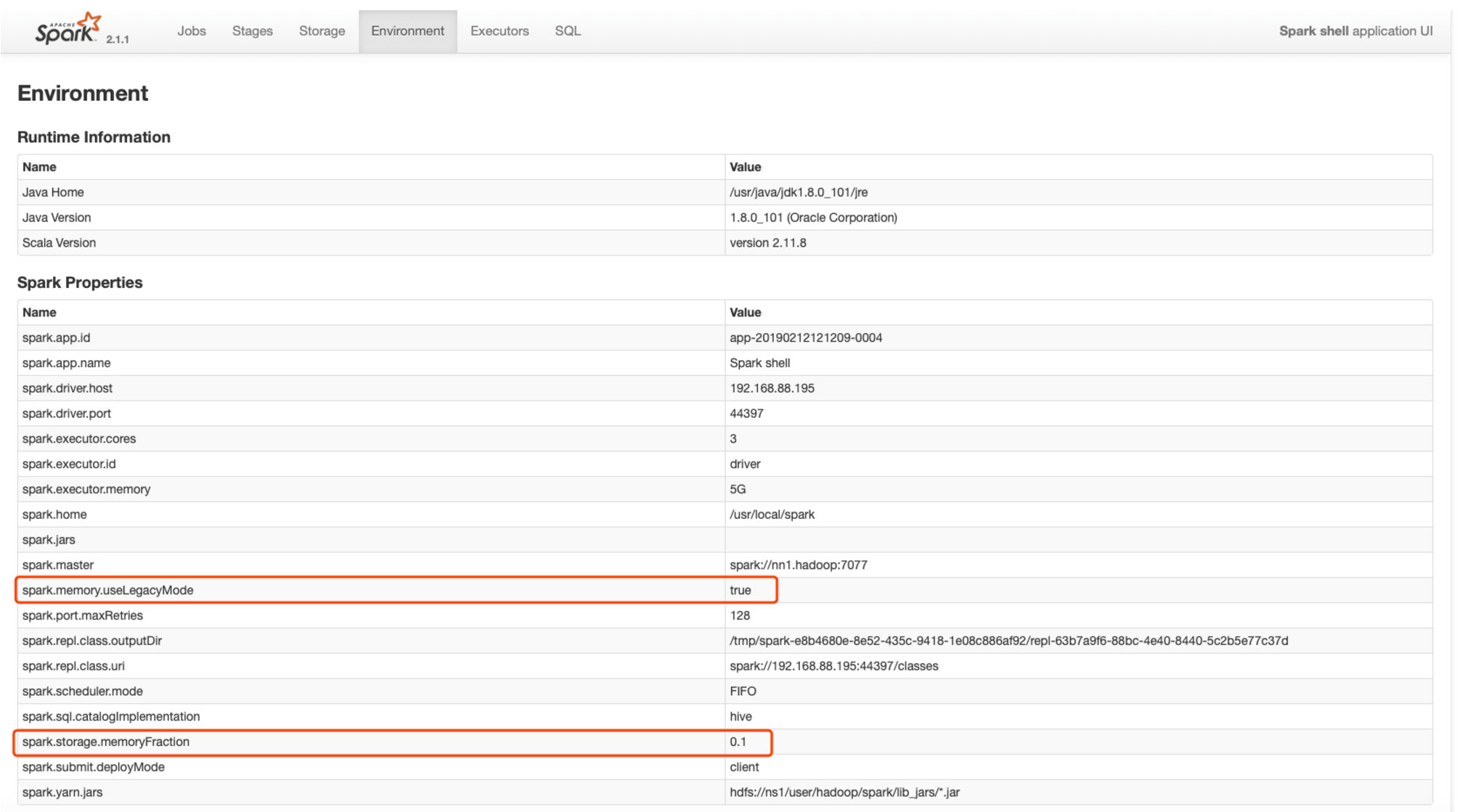
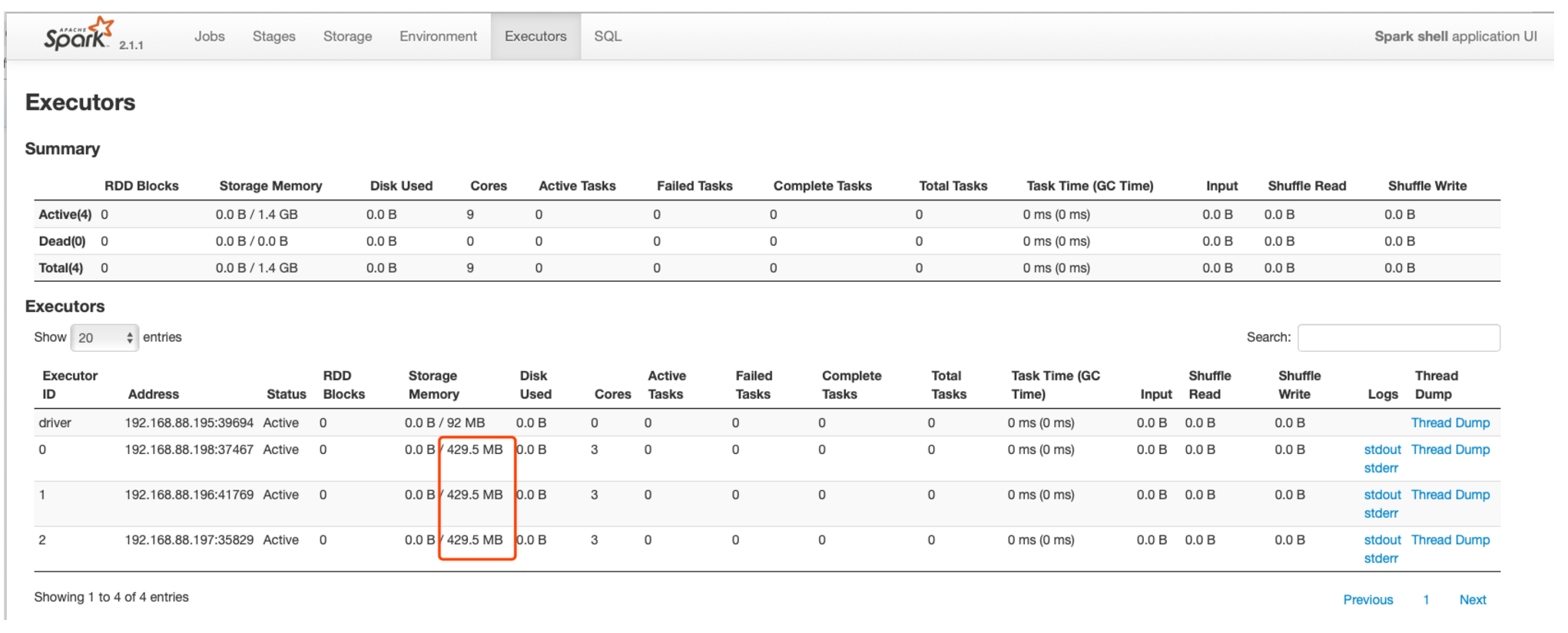
1.4、BlockManager & BlockManagerMaster
BlockManager是spark自己的存储系统,RDD-Cache、 Shuffle-output、broadcast 等的实现都是基于BlockManager来实现的,BlockManager也是分布式结构,在driver和所有executor上都会有blockmanager节点,每个节点上存储的block信息都会汇报给driver端的blockManagerMaster作统一管理,BlockManager对外提供get和set数据接口,可将数据存储在memory, disk, off-heap。
- BlockManagerMaster负责整个应用程序运行期间的数据块的元数据管理和维护。
- BlockManager(Slave)负责将本地数据块的状态信息上报给BlockManagerMaster,同时接受从BlockManagerMaster传过来的执行命令,如获取数据块状态,删除数据块等命令。
- 每个BlockManager中都存在数据传输通道,根据需要进行远程数据的读取和写入。
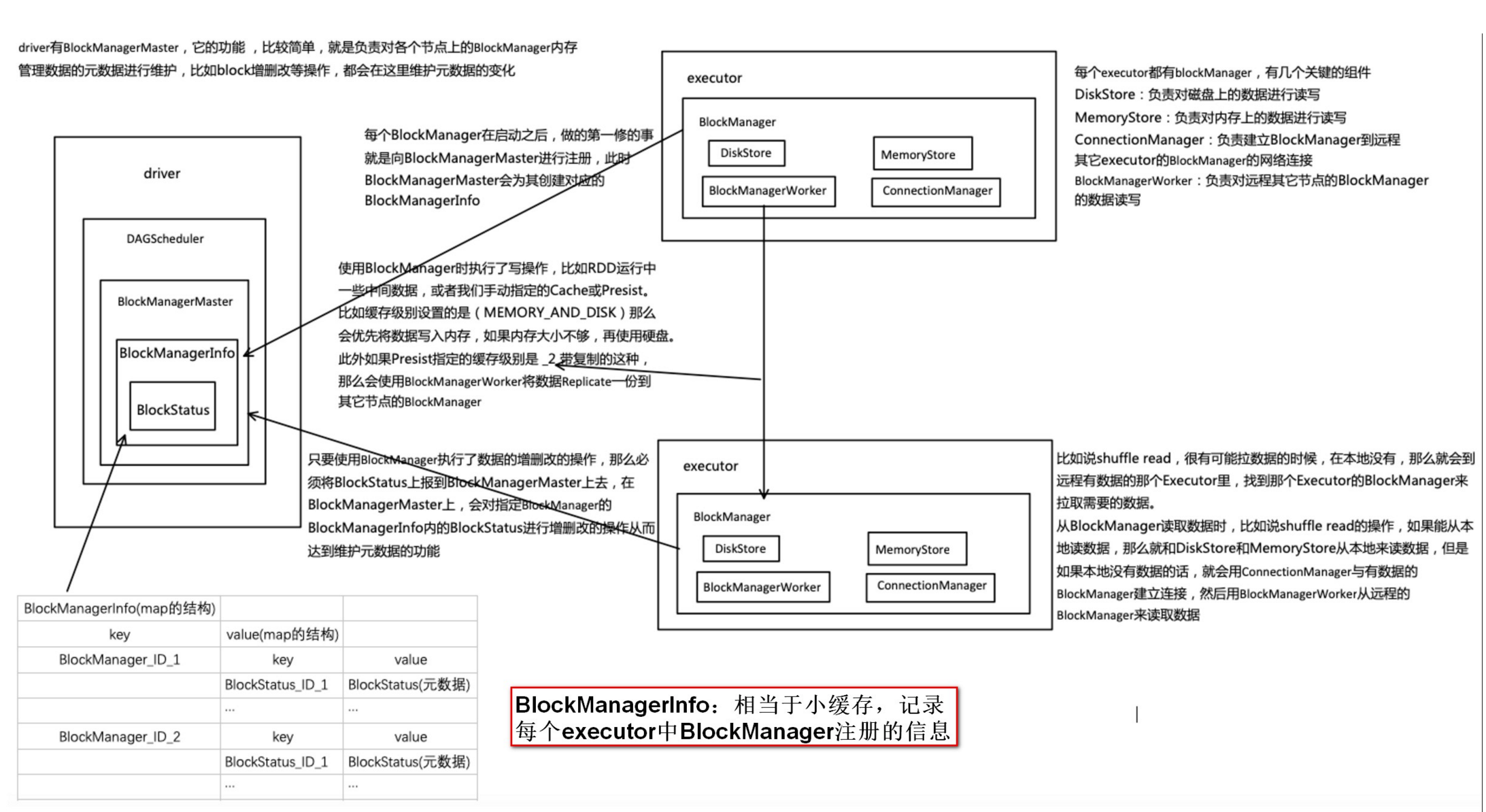
1.5、如何选择存储级别
- 默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大,可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。
- 如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常。
- 如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为既然到了这一步,就说明RDD的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
- 通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
- 总结来看就是:MEMORY_ONLY > MEMORY_ONLY_SER > MEMORY_AND_DISK_SER
二、共享变量
我们传递给Spark的函数,如map(),或者filter()的判断条件函数,能够利用定义在函数之外的变量,但是集群中的每一个task都会得到变量的一个副本,大大增加了内存和网络资源,并且task在对变量进行的更新不会被返回给driver。
2.1、累加器
- 累加器:val acc: Accumulator[Int] = sc.accumulator(0)
- 累加器可以很简便地对各个 worker 返回给 driver 的值进行聚合。累加器最常见的用途之一就是对一个 job 执行期间发生的事件进行计数。
- 累加器则可以让多个task共同操作一份变量,主要可以进行累加操作。task 只能对累加器进行累加操作,不能读取它的值。只有 Driver 程序可以读取累加器的值。
- Spark 内置的累加器有如下几种。
- LongAccumulator:长整型累加器,用于求和、计数、求均值的 64 位整数。
- DoubleAccumulator:双精度型累加器,用于求和、计数、求均值的双精度浮点数。
- CollectionAccumulator[T]:集合型累加器,可以用来收集所需信息的集合。
- 所有这些累加器都是继承自 AccumulatorV2,如果这些累加器还是不能满足用户的需求,Spark 允许自定义累加器。如果需要某两列进行汇总,无疑自定义累加器比直接编写逻辑要方便很多。
自定义累加器:统计 A 列与 B 列的汇总值
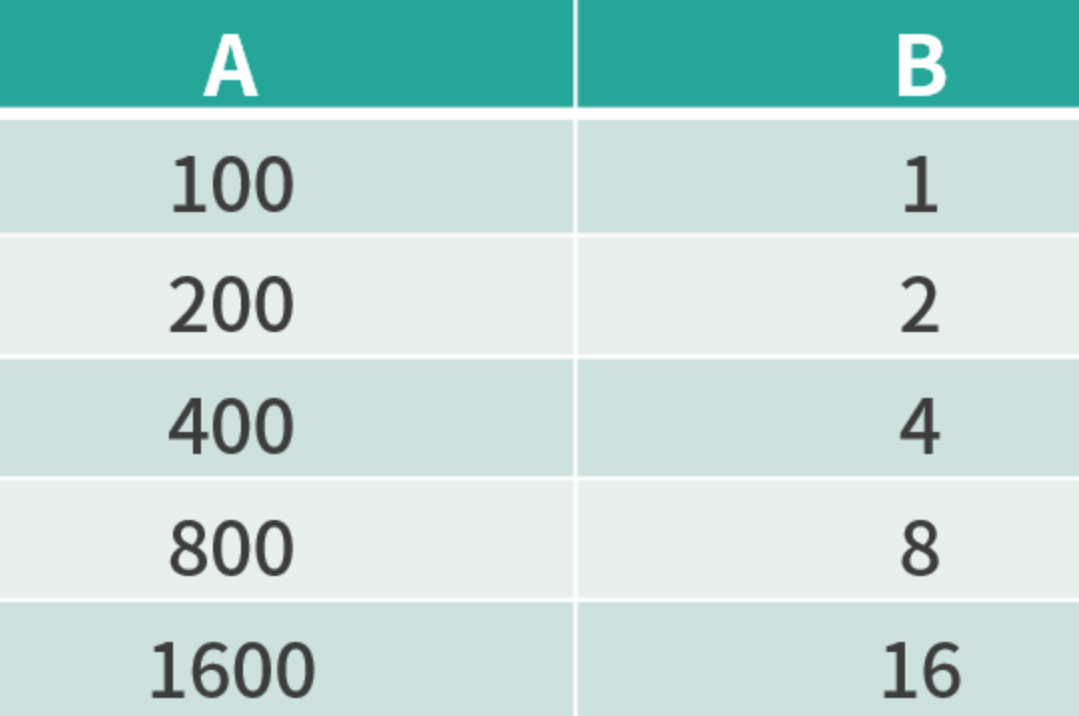
import org.apache.spark.util.AccumulatorV2 import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkConf // 构造一个保存累加结果的类 case class SumAandB(A: Long, B: Long) class FieldAccumulator extends AccumulatorV2[SumAandB,SumAandB] { private var A:Long = 0L private var B:Long = 0L // 如果A和B同时为0,则累加器值为0 override def isZero: Boolean = A == 0 && B == 0L // 复制一个累加器 override def copy(): FieldAccumulator = { val newAcc = new FieldAccumulator newAcc.A = this.A newAcc.B = this.B newAcc } // 重置累加器为0 override def reset(): Unit = { A = 0 ; B = 0L } // 用累加器记录汇总结果 override def add(v: SumAandB): Unit = { A += v.A B += v.B } // 合并两个累加器 override def merge(other: AccumulatorV2[SumAandB, SumAandB]): Unit = { other match { case o: FieldAccumulator => { A += o.A B += o.B} case _ => } } // 当Spark调用时返回结果 override def value: SumAandB = SumAandB(A,B) }
累加器调用方法如下:
package com.spark.examples.rdd import org.apache.spark.SparkConf import org.apache.spark.SparkContext class Driver extends App{ val conf = new SparkConf val sc = new SparkContext(conf) val filedAcc = new FieldAccumulator sc.register(filedAcc, " filedAcc ") // 过滤掉表头 val tableRDD = sc.textFile("table.csv").filter(_.split(",")(0) != "A") tableRDD.map(x => { val fields = x.split(",") val a = fields(1).toInt val b = fields(2).toLong filedAcc.add(SumAandB (a, b)) x }).count }
2.2、广播变量
- val broad: Broadcast[Array[Int]] = sc.broadcast(arr)
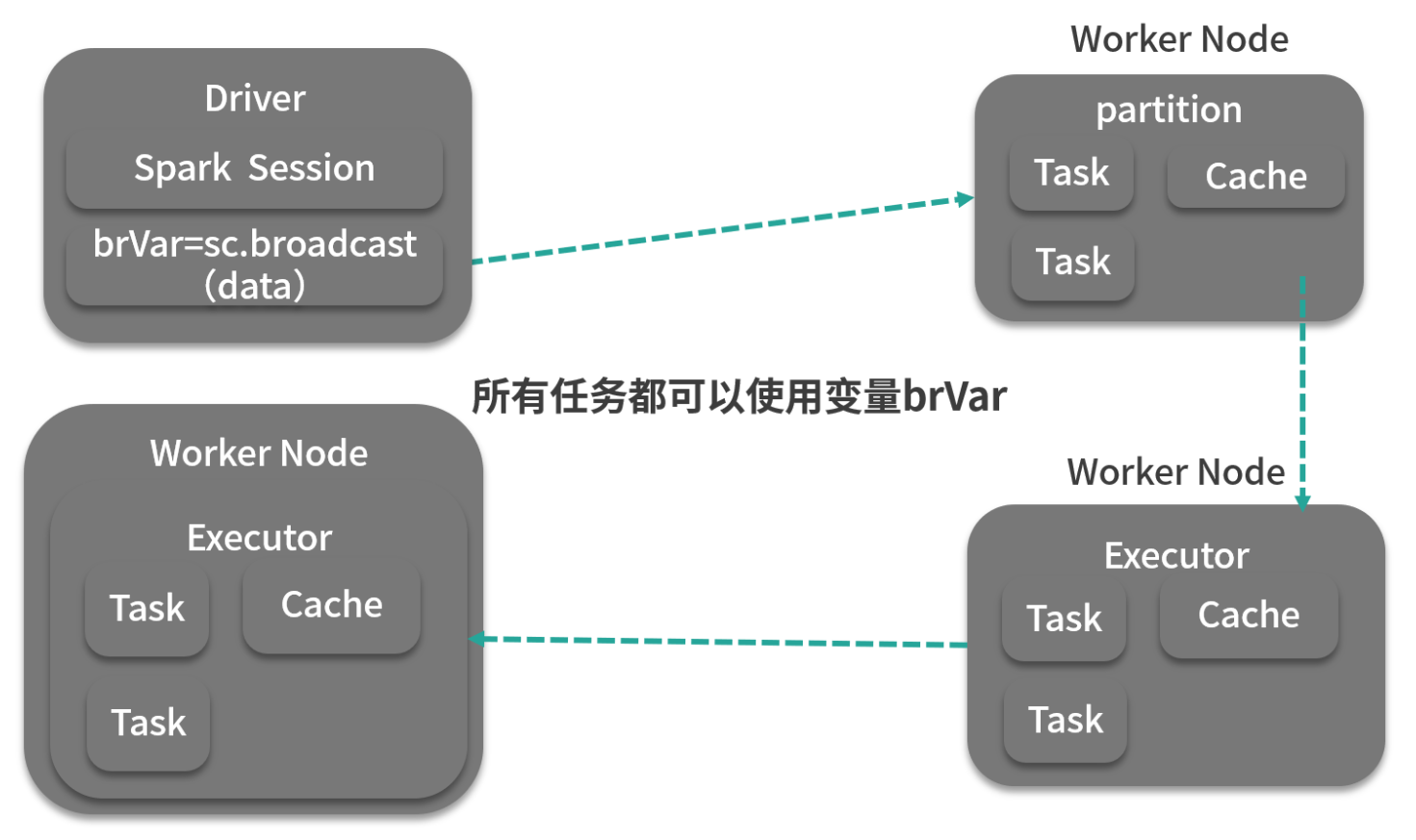
- 广播变量通常情况下,当一个RDD的很多操作都需要使用driver中定义的变量时,每次操作,driver都要把变量发送给worker上的executor中的所有task一次,如果这个变量中的数据很大的话,会产生很高的传输负载,导致执行效率降低。使用广播变量可以使程序高效地将一个很大的只读数据发送给多个worker节点,而且对每个worker节点只需要传输一次,每次操作时executor可以直接获取本地保存的数据副本,不需要多次传输。减少内存消耗和网络传输
- Spark 广播机制运作方式是这样的:Driver 将已序列化的数据切分成小块,然后将其存储在自己的块管理器 BlockManager 中,当 Executor 开始运行时,每个 Executor 首先从自己的内部块管理器中试图获取广播变量,如果以前广播过,那么直接使用;如果没有,Executor 就会从 Driver 或者其他可用的 Executor 去拉取数据块。一旦拿到数据块,就会放到自己的块管理器中。供自己和其他需要拉取的 Executor 使用。这就很好地防止了 Driver 单点的性能瓶颈,如下图所示:
-
广播变量会持续占用内存,当我们不需要的时候,可以用 unpersist 算子将其移除,这时,如果计算任务又用到广播变量,那么就会重新拉取数据。
- 还可以使用 destroy 方法彻底销毁广播变量,调用该方法后,如果计算任务中又用到广播变量,则会抛出异常。
import org.apache.spark.broadcast.Broadcast import org.apache.spark.rdd.RDD import org.apache.spark.{Accumulator, SparkConf, SparkContext} /** * spark的共享变量:累加器,广播变量 * @author xiandongxie */ object SparkBroadCastDemo { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("SparkBroadCastDemo").setMaster("local") val context = new SparkContext(conf) var arr: Array[Int] = Array(1, 2, 3, 4, 5) val sourceRDD: RDD[Int] = context.parallelize(arr, 5) // 广播变量 val broad: Broadcast[Array[Int]] = context.broadcast(arr) // 累加器 val acc: Accumulator[Int] = context.accumulator(0) val reduceResult: Int = sourceRDD.reduce((a, b) => { val broadT: Array[Int] = broad.value //这是使用的广播变量 println(s"broad:${broadT.toList}") //这是使用的外部变量 println(s"arr:${arr.toList}") //累加结果只能使用累加器,不能使用外部变量,因为在分布式环境下,外部变量是不同步的 acc.add(1) a + b }) println(reduceResult) println(acc) } }
结果:
broad:List(1, 2, 3, 4, 5)
arr:List(1, 2, 3, 4, 5)
broad:List(1, 2, 3, 4, 5)
arr:List(1, 2, 3, 4, 5)
broad:List(1, 2, 3, 4, 5)
arr:List(1, 2, 3, 4, 5)
broad:List(1, 2, 3, 4, 5)
arr:List(1, 2, 3, 4, 5)
15
4
广播变量在一定数据量范围内可以有效地使作业避免 Shuffle,使计算尽可能本地运行,Spark 的 Map 端连接操作就是用广播变量实现的。
举个例子
比如对海量的日志进行校验,日志可以简单认为是如下的格式:
表 A:校验码,内容
需要根据校验码的不同,对内容采取不同规则的校验,而检验码与校验规则的映射则存储在另外一个数据库:
表 B:校验码,规则
如果不考虑广播变量,通常有这么两种做法:
1. 直接使用 map 算子,在 map 算子中的自定义函数中去查询数据库,那么有多少行,就要查询多少次数据库,这样性能非常差。
2. 先将表 B 查出来转化为 RDD,使用 join 算子进行连接操作后,再使用 map 算子进行处理,这样做性能会比前一种方式好很多,但是会引起大量的 Shuffle 操作,对资源消耗不小。
当考虑广播变量后,可以将小表进行广播,广播到每个 Executor 的内存中,供 map 函数使用,这就避免了 Shuffle,虽然语义上还是 join(小表放内存),但无论是资源消耗还是执行时间,都要远优于前面两种方式。
黑色线为不使用广播变量的情况,绿色线为使用广播变量的情况


