

flink系列-9、flink的状态与容错
1、理解 State(状态)
1.1、State
- 对象的状态
- Flink 中的状态:一般指一个具体的 task/operator 某时刻在内存中的状态(例如某属性的值)。
- 注意:State 和 Checkpointing 不要搞混。
- checkpoint 则表示了一个 Flink Job,在一个特定时刻的一份全状态快照,即包含一个 job 下所有 task/operator 某时刻的状态。
- 状态的作用
- 增量计算
- 聚合操作
- 机器学习训练模式
- 容错
- Job故障重启
- 升级
1.2、状态的分类

1、Operator State
- 绑定到特定 operator 并行实例,每个 operator 的并行实例维护一个状态
- 与 key 无关
- 例如:一个并行度为 3 的 source,如果只考虑一个算子需要一个逻辑状态的情形,那么他就有 3 个状态
- 支持的数据类型
- ListState<T>
- BroadcastStage<K, V>
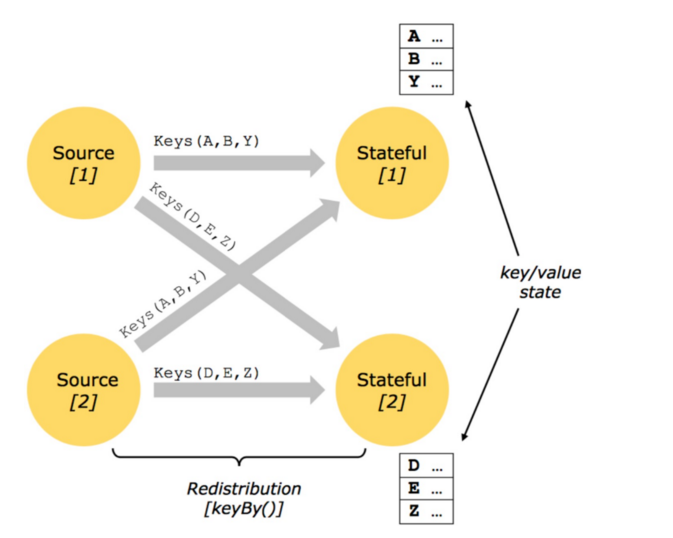
2、Keyed State
- 基于 KeyedStream 之上的状态,dataStream.keyBy(),只能在作用于 KeyedStrem 上的 function/Operator 里使用
- KeyBy 之后的 Operator State,可理解为分区过的 Operator State
- 每个并行 keyed Operator 的每个实例的每个 key 有 一个Keyed State
- 由于每个 key 属于一个 keyed operator 的并行实例,因此我们可以将其简单地理解为 <operator,key>
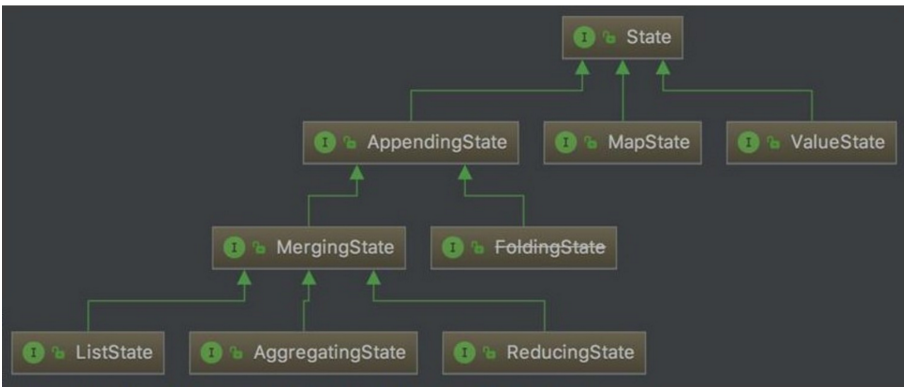
- 支持的数据结构
- ValueState:保留一个可以更新和检索的值
- update(T)
- value()
- ListState<T>:保存一个元素列表
- add(T)
- addAll(List)
- get(T)
- clear()
- ReducingState<T>:保存一个值,该值表示添加到该状态所有值的聚合。
- add(T)
- AggregatingState<IN,OUT><in,out>:保存一个值,该值表示添加到该状态的所有值的聚合。(与ReducingState 相反,聚合类型添加到该状态的元素可以有不同类型)
- add(T)
- FoldingState<T,ACC><t,acc>:不推荐使用
- add(T)
- MapState<UK,UV><uk,uv>:保存一个映射列表
- put(UK,UV)
- putAll(Map<uk,uv>)
- get(UK)
3、状态的表现形式
- Keyed State 和 Operator State,可以以两种形式存在:原始状态和托管状态。
- 通常在 DataStream 上的状态推荐使用托管的状态,当用户自定义 operator 时,会使用到原始状态。
- Managed stage(托管状态):
- 托管状态是指 Flink 框架管理的状态,上面提到的都是,如 ValueState,ListState,MapState 等。
- 通过框架提供的接口来更新和管理状态的值
- 不需要序列化
- 推荐使用
- Raw stage(原始状态)
- 由用户自行管理的具体的数据结构,Flink 在做 checkpoint 的时候,使用 byte[] 来读写状态内 容,对其内部数据结构一无所知
- 需要序列化
- 除非自定义实现。
- Managed stage(托管状态):
4、Operator State 与K eyed State的 Redistribute(重新分配)
1)、Operator State Redistribute Redistribute
- 当 Operator 改变并发度的时候(Rescale),会触发状态的 Redistribute,即 Operator State 里的 数据会重新分配到 Operator 的 Task 实例
- 例如:某 Operator 的并行度由 3 改为 2
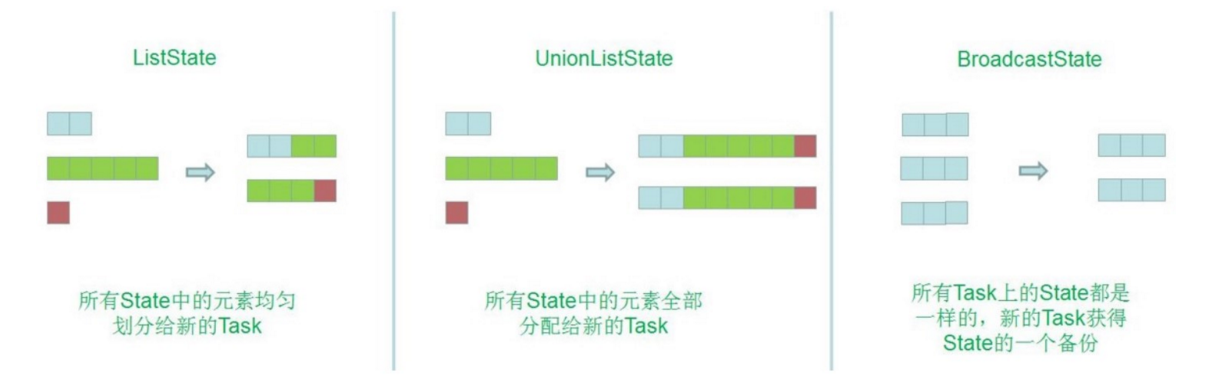
- 不同数据结构的动态扩展方式不一样:
- ListState:并发度在改变的时候,会将并发上的每个 List 都取出,然后把这些 List 合并到一个新的 List,然 后根据元素的个数在均匀分配给新的 Task
- UnionListState:相比于 ListState 更加灵活,把划分的方式交给用户去做,当改变并发的时候,会将原来 的 List 拼接起来。然后不做划分,直接交给用户(每个 Task 给全量的状态,用户自己划分)
- BroadcastState:如大表和小表做 Join 时,小表可以直接广播给大表的分区,在每个并发上的数据都是完 全一致的。做的更新也相同,当改变并发的时候,把这些数据COPY到新的Task即可。
- 以上是 Flink Operator States 提供的 3 种扩展方式,用户可以根据自己的需求做选择。
2)、Keyed State 的 Redistribute
- Keyed State Redistribute
- Key 被 Redistribute 哪个 task,他对应的 Keyed State 就被 Redistribute 到哪个 Task
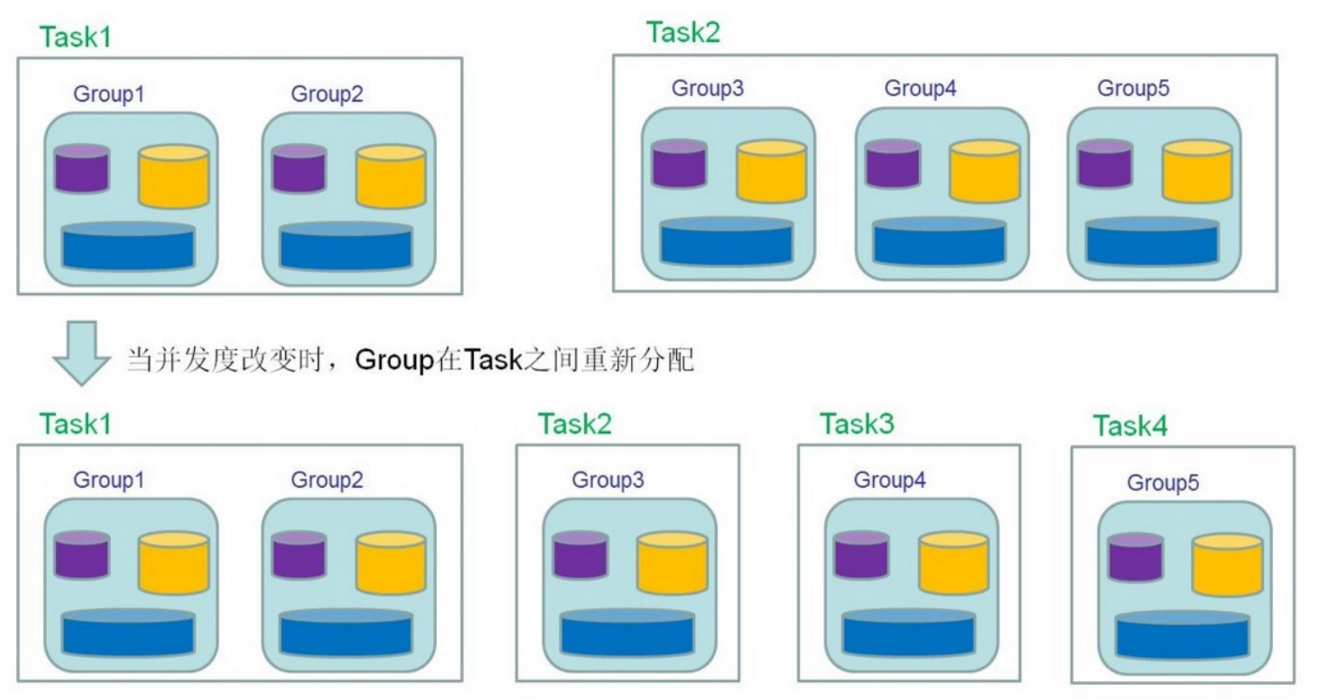
- Keyed State Redistribute 是基于 Key Group 来做分配的:
- 将 key 分为 group
- 每个 key 分配到唯一的 group
- 将 group 分配给 task 实例
- KeyGroup 由最大并行度的大小所决定的
- Keyed State 最终分配到哪个 Task:group ID 和 taskID 是从0开始算的
- hash=hash(key)
- KG=hash % numOfKeyGroups
- Subtask=KG* taskNum / numOfKeyGroups
二、CheckPoint
2.1、状态容错
- 有了状态自然需要状态容错,否则状态就失去意义了
- Flink 状态容错的机制就是 checkpoint
概念
- 所谓 checkpoint,就是在某一时刻,将所有 task 的状态做一个快照 (snapshot),然后存储到 State Backend (有全量 和 增量)
- 一种连续性绘制数据流状态的机制(周期性的),该机制确保即使出现故障,程序的状态最终也将为数据流中的每一条记录提供 exactly once(只处理一次)的语意保证(只能保证 flink 系统内,对于 sink 和 source 需要依赖的外部的组件一同保证)
- 全局快照,持久化保存所有的 task / operator 的 State
特点:
- 轻量级容错机制
- 可异步
- 全量 vs 增量
- Barrier 机制(保证 exactly-once 语义)
- 失败情况可回滚至最近一次成功的 checkpoint(自动)
- 周期性(无需人工干预)
基本原理:
- 通过往 source 注入 barrier
- barrier 作为 checkpoint 的标志
- barrier
-
全局异步化是 snapshot 的核心机制
-
Flink 分布式快照的核心概念之一就是数据栅栏(barrier)。这些 barrier 被插入到数据流中,作为数据流的一部分和数据一起向下流动。
-
Barrier 不会干扰正常数据,数据严格有序。
-
一个 barrier 把数据流分割成两部分:一部分进入到当前快照,另一部分进入下一个快照。
-
每一个 barrier 都带有快照 ID,并且 barrier 之前的数据都进入了 此快照。
-
Barrier 不会干扰数据流处理,所以非常轻量。多个不同快照的多个 barrier 会在流中同时出现,即多个 快照可能同时创建。

-
使用 Checkpointing 的前提条件:
- 在一定时间内可回溯的 datasource(故障时可以回溯数据),常见的:
- 一般是可持久化的消息队列:例如 Kafka、RabbitMQ、Amazon Kinesis、Google PubSub
- 也可以是文件系统:HDFS、S3、GFS、NFS、Ceph
- 可持久化存储 State 的存储系统,通常使用分布式文件系统(Checkpointing 就是把 job 的所有状态都周期性持久化到存储里)
- 一般是 HDFS、S3、GFS、NFS、Ceph
2.2、状态容错示意图
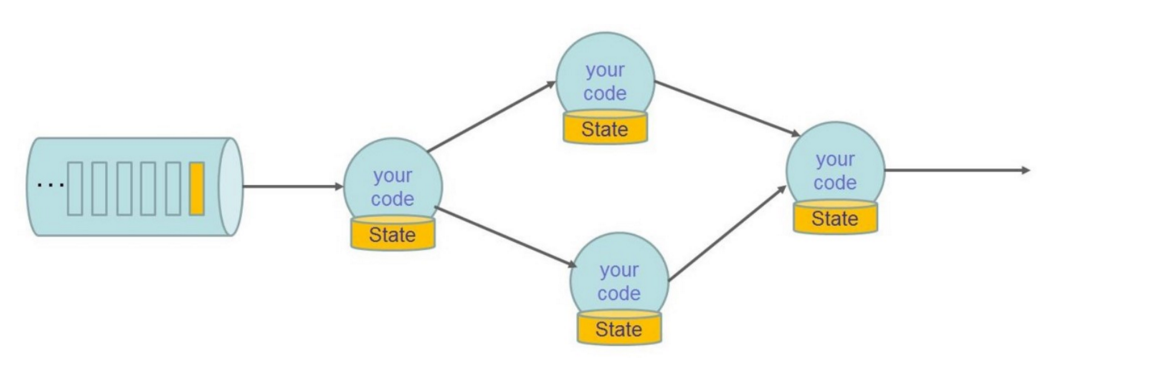
checkpoint:
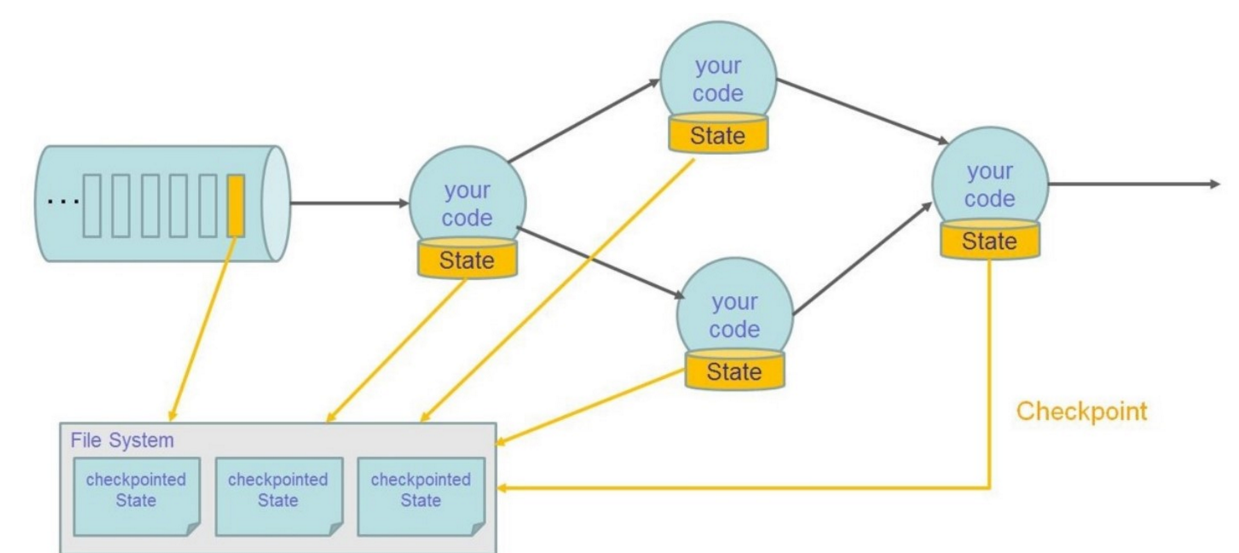
Restore:
- 恢复所有状态
- 设置 source 的位置(例如:Kafka 的 offset)

2.3、使用CheckPoint
1、开启checkPoint
- checkPoint默认是禁用的
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //start a checkpoint every 1000 ms 1000-checkpoint时间间隔 env.enableCheckpointing(1000); //advanced options: checkpoint保证形式 //set mode to exactly-once (this is the default) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); //make sure 500 ms of progress happen between checkpoints 两次间隔最小时间,如果上次没有完成会等待完成在执行下一次 env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500); //checkpoints have to complete within one minute,or are discarded ;超时时间 env.getCheckpointConfig().setCheckpointTimeout(60000); //allow only one checkpoint to be in progress at the same time; checkpoint 并行度 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); //enable externalized checkpoints which are retained after job cancellation;任务结束,checkpoint是否保留 env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
2、CheckpointConfig设置说明
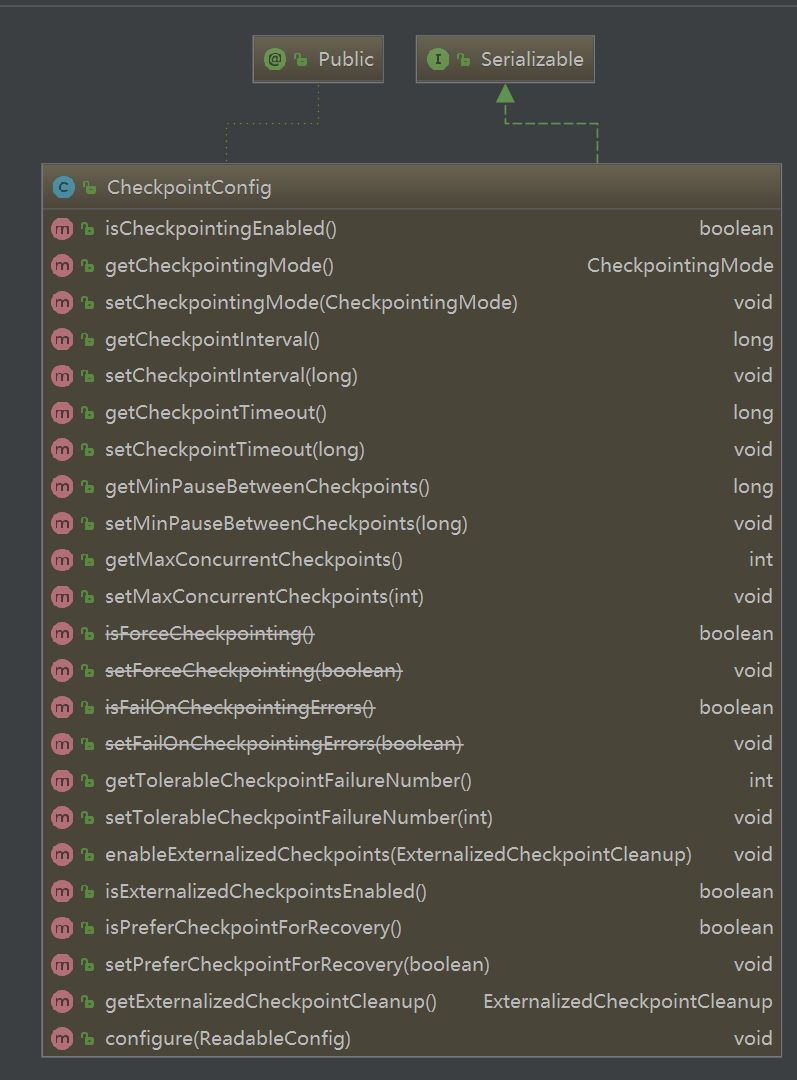
- checkpointMode

-
//set mode to exactly-once (this is the default) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
- 保留策略
-
默认情况下,检查点不被保留,仅用于从故障中恢复作业。可以启用外部持久化检查点,同时指定保留策略
-
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:在作业取消时保留检查点。注意,在这种情况下,必须在取消后手动清理检查点状态。
-
ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:当作业被 cancel 时,删除检查点。检查点状态仅在作业失败时可用。
-
- checkpointing的超时时间:超过时间没有完成则会被终止
-
//checkpoints have to complete within one minute, or are discarded env.getCheckpointConfig().setCheckpointTimeout(60000);
-
- checkpointing最小间隔:用于指定上一个 checkpoint 完成之后最小等多久可以出发另一个 checkpoint,当指 定这个参数时,maxConcurrentCheckpoints 的值为1
-
//make sure 500 ms of progress happen between checkpoints env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
-
- maxConcurrentCheckpoints:指定运行中的 checkpoint 最多可以有多少个(设定 checkpointing 最小间隔时本 参数即为1)
-
//allow only one checkpoint to be in progress at the same time env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
-
- failOnCheckpointingErrors 用于指定在 checkpoint 发生异常的时候,是否应该fail该task,默认为true,如果设 置为false,则 task 会拒绝 checkpoint 然后继续运行
-
env.getCheckpointConfig().setFailOnCheckpointingErrors(true);
-
3、选择 State Backend
- State Backend 就是用来保存快照的地方
- 用来在 Checkpointing 机制中持久化所有状态的一致性快照,这些状态包括:
- 非用户定义的状态:例如,timers、非用户自定义的 stateful operators(connectors,windows)
- 用户定义的状态:就是前面讲的用户自定义的 stateful operato 所使用的 Keyed State and Operator State
目前 Flink 自带三个开箱即用 State Backend:
- MemoryStateBackend(默认)
- MemoryStateBackend 在 Java 堆上维护状态。Key/value 状态和窗口运算符使用哈希表存储值和计时器等
- Checkpoint 时,MemoryStateBackend 对 State 做一次快照,并在向 JobManager 发送 Checkpoint 确认完成的消息中带上此快照数据,然后快照就会存储在 JobManager 的堆内存中
- MemoryStateBackend 可以使用异步的方式进行快照(默认开启),推荐使用异步的方式避免阻塞。如果 不希望异步,可以在构造的时候传入false(也可以通过全局配置文件指定),如下
-
StateBackend backend = new MemoryStateBackend(10*1024*1024,false); env.setStateBackend(backend);
-
-
限制
-
单个 State的 大小默认限制为 5MB,可以在 MemoryStateBackend 的构造函数中增加
-
不论如何配置,State 大小都无法大于 akka.framesize(JobManager 和 TaskManager 之间发送的最大消息的大小默认是 10MB )
-
JobManager 必须有足够的内存大小
-
-
- 适用场景
- 本地开发和调试
- 小状态 job,如只使用 Map、FlatMap、Filter...或 Kafka Consumer
- 适用场景
-
FsStateBackend
-
FsStateBackend 需要配置一个文件系统的URL, 如 "hdfs://namenode:40010/flink/checkpoint"。
-
FsStateBackend 在 TaskManager 的内存中持有正在处理的数据。Checkpoint 时将 state snapshot 写入文件系统目录下的文件中。
-
文件的路径等元数据会传递给 JobManager,存在其内存中。
-
FsStateBackend 可以使用异步的方式进行快照(默认开启),推荐使用异步的方式避免阻塞。如果不希望异 步可以在构造的时候传入 false(也可以通过全局配置文件指定),如下:
-
StateBackend backend = new FsStateBackend("hdfs://namenode:40010/flink/checkpoints",false); env.setStateBackend(backend);
-
- 适用场景
- 大状态、长窗口、大键/值状态的 job
- 所有高可用性的情况
-
-
RocksDBStateBackend
-
RocksDBStateBackend 需要配置一个文件系统的 URL 如"hdfs://namenode:40010/flink/checkpoint"
-
RocksDBStateBackend 将运行中的数据保存在 RocksDB 数据库中,状态存储在 TaskManager 数据目录中,在 Checkpoint 时,整个 RocksDB 数据库将被 Checkpointed 到配置的文件系统和目录中。文件的路径等元数据会传递给 JobManager,存在其内存中。
-
RocksDBStateBackend 总是执行异步快照
-
限制
-
RocksDB JNI API 是基于 byte[],因此 key 和 value 最大支持大小为 2^31 个字节(2GB)。RocksDB 自身在支持较大 value 时候有问题
-
- 适用场景
- 超大状态,超长窗口、大键/值状态的 job
- 所有高可用性的情况
- 与前两种状态后端对比:
- 目前只有 RocksDBStateBackend 支持增量 checkpoint(默认全量)
- 状态保存在数据库中,即使用 RockDB 可以保存的状态量仅受可用磁盘空间量的限制,相比其他的状态后端可保存更大的状态,但开销更大(读/写需要反序列化/序列化去检索/存储状态),吞吐受到限制
-
三种 StateBackend 总结如下:

- 配置 StateBackend
- 全局配置(配置文件 conf/flink-conf.yaml),设置集群保存 checkpoint 类型和存储路径
-
# The backend that will be used to store operator state checkpoints state.backend: filesystem #Directory.for storing checkpoints state.checkpoints.dir: hdfs:namenode:40010/flink/checkpoints
- 每个 job 单独配置 State Backend(可覆盖全局配置) ,设置计算任务的
-
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));
4、配置恢复策略
Flink 支持不同的重启策略,这些策略控制在出现故障时如何重新启动 job
| Restart Strategy | 配置项 | 默认值 | 说明 |
| 固定延迟(Fixed delay) | restart-strategy:fixed-delay |
如果超过最大重试次数,作业最终会失败,在连续两次重启尝试之间等待固定的时间 | |
| restart-strategy.fixed-delay.attempts:3 |
1或者Integer.MAX_VAL (启用checkpoint但未指定重启策略时) | ||
| restart-strategy.fixed-delay.delay:10s | akka.ask.timeout或者10s(启用checkpoint但 未指定重启策略时) | ||
| 失败率(Failure rate) | restart-strategy:failure-rate | 在失败后重新启动作业,但是当超过故障率(每个时间间隔的故障)时,作业最终会失败,在连续两次重启尝试之间等待固定时间 | |
| restart-strategy:failure-rate.max-failures-per-interval:3 | 1 | ||
| restart-strategy.failure-rate.failure-rateinterval:5min | 1 minute | ||
| restart-strategy:failure-rate.delay:10s | akka.ask.timeout |
||
| 无重启(No restart) | restart-strategy:none | 如果没有启用checkpoint,则使用无重启(no restart)策略 |
- 如果没有启用 checkpointing,则使用无重启(no restart)策略。
- 如果启用了 checkpointing,但没有配置重启策略,则使用固定延迟(fixed-delay)策略,其中尝试重启 次数是 Integer > MAX_VALUE
- 重启策略可以在 flink-conf.yaml 中配置,表示全局的配置。也可以在应用代码中动态指定,会覆盖全局配 置
2.4、checkpoint demo
1、operatorState 的 checkPoint 容错案例:
import java.util.concurrent.TimeUnit import org.apache.flink.api.common.functions.RichFlatMapFunction import org.apache.flink.api.common.restartstrategy.RestartStrategies import org.apache.flink.api.common.state.{ListState, ListStateDescriptor} import org.apache.flink.api.common.time.Time import org.apache.flink.api.common.typeinfo.{TypeHint, TypeInformation} import org.apache.flink.configuration.{ConfigConstants, Configuration} import org.apache.flink.runtime.state.filesystem.FsStateBackend import org.apache.flink.runtime.state.{FunctionInitializationContext, FunctionSnapshotContext} import org.apache.flink.streaming.api.CheckpointingMode import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction import org.apache.flink.streaming.api.environment.CheckpointConfig import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.util.Collector import scala.collection.mutable.ListBuffer /** * OperatorState的checkPoint容错恢复 * 想知道两次事件 xxd 之间,一共发生多少次其他事件,分别是什么事件 * 事件流:xxd a a a a a f d d xxd ad d s s d xxd… * 当事件流中出现字母e时触发容错 * 输出: * (8,a a a a a f d d) * (6,ad d s s d) */ object OperatorStateRecovery { def main(args: Array[String]): Unit = { import org.apache.flink.api.scala._ //生成配置对象 val config = new Configuration() //开启spark-webui config.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true) //配置webui的日志文件,否则打印日志到控制台 config.setString("web.log.path", "/tmp/logs/flink_log") //配置taskManager的日志文件,否则打印日志到控制台 config.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, "/tmp/logs/flink_log") //配置tm有多少个slot config.setString("taskmanager.numberOfTaskSlots", "4") // 获取local运行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(config) //设置全局并行度为1,好让所有数据都跑到一个task中,以方便测试 env.setParallelism(1) //隔多长时间执行一次ck 毫秒 env.enableCheckpointing(1000L) val checkpointConfig: CheckpointConfig = env.getCheckpointConfig //保存EXACTLY_ONCE checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) //每次ck之间的间隔,不会重叠 checkpointConfig.setMinPauseBetweenCheckpoints(2000L) //每次ck的超时时间 checkpointConfig.setCheckpointTimeout(10L) //如果ck执行失败,程序是否停止 checkpointConfig.setFailOnCheckpointingErrors(true) //job在执行CANCE的时候是否删除ck数据 checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION) //指定保存ck的存储模式 val stateBackend = new FsStateBackend("file:/tmp/flink/checkpoints", true) //异步同步 // val stateBackend = new MemoryStateBackend(10 * 1024 * 1024,false) // val stateBackend = new RocksDBStateBackend("hdfs://ns1/flink/checkpoints",true) env.setStateBackend(stateBackend) //恢复策略,恢复三次,间隔0秒 env.setRestartStrategy( RestartStrategies.fixedDelayRestart( 3, // number of restart attempts Time.of(0, TimeUnit.SECONDS) // delay ) ) val input: DataStream[String] = env.socketTextStream("localhost", 6666) input .flatMap(new OperatorStateRecoveryRichFunction) .print() env.execute() } } //由于使用了本地状态所以需要checkpoint的snapshotState方法把本地状态放到托管状态中 class OperatorStateRecoveryRichFunction extends RichFlatMapFunction[String, (Int, String)] with CheckpointedFunction { //托管状态 @transient private var checkPointCountList: ListState[String] = _ //原始状态 private var list: ListBuffer[String] = new ListBuffer[String] //flatMap函数处理逻辑 override def flatMap(value: String, out: Collector[(Int, String)]): Unit = { if (value == "xxd") { if (list.size > 0) { val outString: String = list.foldLeft("")(_ + " " + _) out.collect((list.size, outString)) list.clear() } } else if (value == "e") { 1 / 0 } else { list += value } } //再checkpoint时存储,把正在处理的原始状态的数据保存到托管状态中 override def snapshotState(context: FunctionSnapshotContext): Unit = { checkPointCountList.clear() list.foreach(f => checkPointCountList.add(f)) println(s"snapshotState:${ list }, Time=${System.currentTimeMillis()}") } //从statebackend中恢复保存的托管状态,并将来数据放到程序处理的原始状态中 // 出错一次就调用一次这里,能调用几次是根据setRestartStrategy设置的 override def initializeState(context: FunctionInitializationContext): Unit = { val lsd: ListStateDescriptor[String] = new ListStateDescriptor[String]("xxdListState", TypeInformation.of(new TypeHint[String] {})) checkPointCountList = context.getOperatorStateStore.getListState(lsd) if (context.isRestored) {// 出错恢复 import scala.collection.convert.wrapAll._ for (e <- checkPointCountList.get()) { list += e } } println(s"initializeState:${list},Time=${System.currentTimeMillis()}") } }
2、Keyed State 容错实现方法
- Keyed State 之过期超时策略
- 由于 Keyed State 太多,所以 flink 提供了针对 Keyed State TTL 的设置
- 任何类型的 keyed State 都可以设置 TTL。如果 TTL 已配置,且状态已过期,则将以最佳方式处理
- 所有 State collection 都支持条目级别的 TTL,即 list、map 中的条目独立 expire
- 用法
-
StateTtlConfig ttlConfig = StateTtlConfig .newBuilder(Time.seconds(1)) .setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) .setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) .build(); ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class) stateDescriptor.enableTimeToLive(ttlConfig);
-
-
Refresh 策略(默认是 OnCreateAndWrite):设置如何更新 keyedState 的最后访问时间
-
StateTtlConfig.UpdateType.Disabled - 禁用TTL,永不过期
-
StateTtlConfig.UpdateType.OnCreateAndWrite - 每次写操作均更新 State 的最后访问时间(Create、 Update)
-
StateTtlConfig.UpdateType.OnReadAndWrite - 每次读写操作均更新State的最后访问时间
-
-
- 状态可见性(默认是NeverReturnExpired):设置是否返回过期的值(过期尚未清理,此时正好被访问)
- StateTtlConfig.StateVisibility.NeverReturnExpired - 永不返回过期状态
- StateTtlConfig.StateVisibility.ReturnExpiredlfNotCleanedUp - 可以返回过期但尚未清理的状态值
- 状态可见性(默认是NeverReturnExpired):设置是否返回过期的值(过期尚未清理,此时正好被访问)
-
- TTL time 等级
- setTimeCharacteristic(TimeCharacteristic timeCharacteristic)
- 目前只支持 ProcessingTime
- TTL time 等级
- Keyed State之过期状态清理
- 清理策略
- 默认:已经过期的数据被显示读取时才会清理(可能会导致状态越来越大) FULL_STATE_SCAN_SNAPSHOT:在 checkpoint 时清理 full snapshot 中的 expired state
- CleanupFullSnapshot()
- 不适用于在 RocksDB state backend 上的 incremental checkpointing
KeyedState的checkPoint容错恢复 :
import java.util.concurrent.TimeUnit import org.apache.flink.api.common.functions.RichFlatMapFunction import org.apache.flink.api.common.restartstrategy.RestartStrategies import org.apache.flink.api.common.state.{StateTtlConfig, ValueState, ValueStateDescriptor} import org.apache.flink.api.common.time.Time import org.apache.flink.api.common.typeinfo.{TypeHint, TypeInformation} import org.apache.flink.configuration.{ConfigConstants, Configuration} import org.apache.flink.runtime.state.filesystem.FsStateBackend import org.apache.flink.streaming.api.CheckpointingMode import org.apache.flink.streaming.api.environment.CheckpointConfig import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.util.Collector import scala.collection.mutable /** * KeyedState的checkPoint容错恢复 * 将输入格式为"字符串 数字"的字符串转换成(字符串,数字)的元组类型 * 事件流:xxd 666 * 当事件流中出现"任意字符串 888"时触发容错 * 输出: * (xxd,666) */ object KeyedStateRecovery { def main(args: Array[String]): Unit = { import org.apache.flink.api.scala._ //生成配置对象 val config = new Configuration() //开启spark-webui config.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true) //配置webui的日志文件,否则打印日志到控制台 config.setString("web.log.path", "/tmp/logs/flink_log") //配置taskManager的日志文件,否则打印日志到控制台 config.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, "/tmp/logs/flink_log") //配置tm有多少个slot config.setString("taskmanager.numberOfTaskSlots", "4") val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(config) //并行度设置为1,是想让所有的key都跑到一个task中,以方便测试 env.setParallelism(1) //隔多长时间执行一次ck env.enableCheckpointing(1000L) val checkpointConfig: CheckpointConfig = env.getCheckpointConfig //保存EXACTLY_ONCE checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) //每次ck之间的间隔,不会重叠 checkpointConfig.setMinPauseBetweenCheckpoints(2000L) //每次ck的超时时间 checkpointConfig.setCheckpointTimeout(10L) //如果ck执行失败,程序是否停止 checkpointConfig.setFailOnCheckpointingErrors(true) //job在执行CANCE的时候是否删除ck数据 checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION) //指定保存ck的存储模式 val stateBackend = new FsStateBackend("file:/tmp/flink/checkpoints", true) // val stateBackend = new MemoryStateBackend(10 * 1024 * 1024,false) // val stateBackend = new RocksDBStateBackend("hdfs://ns1/flink/checkpoints",true) env.setStateBackend(stateBackend) //恢复策略 env.setRestartStrategy( RestartStrategies.fixedDelayRestart( 3, // number of restart attempts Time.of(3, TimeUnit.SECONDS) // delay ) ) val input: DataStream[String] = env.socketTextStream("localhost", 6666) //因为KeyedStateRichFunctionString中使用了keyState,所以它必须在keyBy算子的后面 input .map(f => { val strings: mutable.ArrayOps[String] = f.split(" ") (strings(0), strings(1).toInt) }) .keyBy(0) .flatMap(new KeyedStateRecoveryRichFunctionString) .print() env.execute() } } //由于没有使用本地的状态所以不需要实现checkpoint接口 class KeyedStateRecoveryRichFunctionString extends RichFlatMapFunction[(String, Int), (String, Int)] { //ValueState是Key的state类型,是只能存在于KeyedStream的operator中 @transient private var sum: ValueState[(String, Int)] = null override def flatMap(value: (String, Int), out: Collector[(String, Int)]): Unit = { println(s"state value:${sum.value()}") //当value值为888时,触发异常 if (value._2 != 888) { sum.clear() sum.update(value) out.collect(value) } else { 1 / 0 } } //在operator启动时执行一次 //如果operator出现异常,在恢复operator时会被再次执行 override def open(parameters: Configuration): Unit = { //keyState的TTL策略 val ttlConfig = StateTtlConfig //keyState的超时时间为10秒 .newBuilder(Time.seconds(10)) //当创建和更新时,重新计时超时时间 .setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) //失败时不返回keyState的值 .setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) //失败时返回keyState的值 // .setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp) //ttl的时间处理等级目前只支持ProcessingTime .setTtlTimeCharacteristic(StateTtlConfig.TtlTimeCharacteristic.ProcessingTime) .build //从runtimeContext中获得ck时保存的状态 val descriptor = new ValueStateDescriptor[(String, Int)]("xxdValueState", TypeInformation.of(new TypeHint[(String, Int)] {})) descriptor.enableTimeToLive(ttlConfig) sum = getRuntimeContext.getState(descriptor) } }
三、SavePoint
概念:
- savepoint可以理解为是一种特殊的 checkpoint,savepoint 就是指向 checkpoint 的一个指针。
- 实际上也是 使用通过 checkpointing 机制创建的 streaming job 的一致性快照,可以保存数据源的 offset、并行操作状态 也就是流处理过程中的状态历史版本。
- 需要手动触发,而且不会过期,不会被覆盖,除非手动删除。
- 正常 情况下的线上环境是不需要设置 savepoint 的。除非对 job 或集群做出重大改动的时候, 需要进行测试运行。
- 可以从应用在过去的任意做了 savepoint 的时刻开始继续消费,具有可以 replay 的功能
Savepoint由两部分组成:
- 数据目录:稳定存储上的目录,里面的二进制文件是 streaming job 状态的快照
- 元数据文件:指向数据目录中属于当前 Savepoint 的数据文件的指针(绝对路径)
与Checkpoint的区别:
- Savepoint 相当于备份(类比数据库备份)、Checkpoint 相当于 recovery log
- Checkpoint 是 Flink 自动创建的 "recovery log" 用于故障自动恢复,由 Flink 创建,不需要用户交互。用户 cancel 作业时就删除,除非启动了保留机制(External Checkpoint)
- Savepoint 由用户创建,拥有和删除,保存点在作业终止后仍然存在。
作用:
- job 开发新版本(更改 job graph、更改并行度等等),应用重新发布
- Flink 版本的更新
- 业务迁移,集群需要迁移,不容许数据丢失

