

黑马程序员 java基础之HashMap和TreeMap
Map集合概述
/* Map<K,V>: K (key)- 此映射所维护的键的类型 V (Value)- 映射值的类型 Map集合:该集合存储键值对.一对一对往里存.而且要保证键的唯一性 */ package map; import java.util.*; class MapDemo { public static void main(String[] args) { //测试LinkedHashMap->存入顺序和取出顺序一致 //此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序) LinkedHashMap<String,String>lm = new LinkedHashMap<String,String>(); lm.put("1","abc"); lm.put("2","bcd"); lm.put("3","abc"); lm.put("4","abcd"); lm.put("5","abc"); System.out.println(lm); lm.put("5","defg"); System.out.println(lm); } } /* 重要的实现类: Hashtables:底层是哈希表数据结构,不可以存入null键null值.HashTable是线程同步的.效率低 JDK 1.0 为了成功地在哈希表中存储和获取对象,用作键的对象必须实现 hashCode 方法和 equals 方法。 HashMap:底层是哈希表数据结构,可以存入null键null值.HashMap是线程非同步的.效率高 JDK1.2 依然需要实现hashCode和equals TreeMap:①底层是红黑树(自平衡二叉查找树)数据结构.线程不同步. ②可以用于给map集合中的键(Key)进行排序和Set很像. 其实,set底层就是使用了Map集合 HashSet 底层用到了 HashMap 很好解释了为什么要复写hashCode和equals TreeSet 底层用到了 TreeMap 而TreeMap运用的就是红黑树 */
Map常用操作:
/*
一些常用操作:
.添加
V put(K key, V value)
将指定的值与此映射中的指定键关联(可选操作)。
void putAll(Map<? extends K,? extends V> m)
从指定映射中 将所有映射关系 复制到此映射中(可选操作)。
.删除
void clear()
V remove(Object key)
如果存在一个键的映射关系,则将其从此映射中移除(可选操作)。
.判断
boolean containsKey(Object key)
如果此映射包含 指定键的映射关系,则返回true.
boolean containsValue(Object Value)
如果此映射将 一个或多个键映射到指定值 ,则返回true.
.获取
V get(Object key)
返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。
int size()
返回此映射中的 键-值映射 关系数。
Collection<V> values()
返回此映射中包含的值(Value)的 Collection 视图。
※Set<Map.Entry<K,V>> entrySet()
返回此映射中包含的映射关系的 Set 视图。
※ Set<K> keySet()
返回此映射中包含的键的 Set 视图。
*/
package map;
import java.util.*;
class MapDemo2{
public static void print(Object obj){
System.out.println(obj);
}
public static void main(String[] args){
Map<String,String> map = new HashMap<String,String>();
//添加元素
print("put "+map.put("01","zhangsan"));//null 原来HashMap中没有01对应的value->返回null
print("put "+map.put("01","heihei"));//zhangsan 返回旧的01对应的heihei,并且把01对应的zhangsan替换掉(保证key唯一性)
/*
也就是说,在添加时,新的key=value与旧的key=value
出现key相同->新value会覆盖旧value,并且返回旧value.
*/
map.put("02","Lisi");
map.put("03","wangwu");
print("containsKey: "+map.containsKey("04"));//false
print("remove04: "+map.remove("04"));//null
print("remove02: "+map.remove("02"));//Lisi
print(map);//{01=zhangsan,03=wangwu}//依然元素转换成字符串形式输出,使用的是AbstractMap中的toString();
//注意打印顺序和存入顺序可能不同->底层使用的为哈希表
//获取
print("get01: "+map.get("01"));//zhangsan
print("get04: "+map.get("04"));//null
map.put(null,"maliu");//虽然可以加入,但没有意义
map.put("04",null);//同上
//可以通过get方法的返回值来判断一个键是否存在,返回是否为null判断
Collection<String> coll = map.values();
print(coll);
print(map);
}
}
entrySet()与keySet()
/*
怎样将Map中所有value,Key取出?
.Set<K> keySet()
将Map中所有的Key存入到Set集合.
因为set集合具备迭代器.利用迭代器取出Key,
根据Map中的get方法,
获取每一个键对应的值.
Map集合的取出原理:将map集合转成set集合,在通过迭代器取出
(画一个示意图)
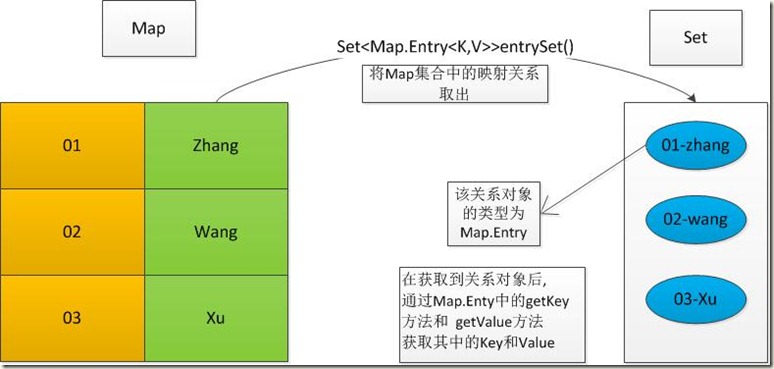
.Set<Map.Entry<K,V>> entrySet()
将map结合中的映射关系存入到了set集合中,而这个关系的数据类型就是Map.Entry
(画一个示意图)
Map.Entry:表示Map中的关系类型
而Map.Entry<K,V>:指定关系中Key和Value的操作类型
Set<Map.Entry<K,V>>:泛型嵌套
老毕经典比喻:(霸气侧漏(*^__^*))
假如存入的键值对为丈夫和妻子(当然了一夫一妻制:一个丈夫对应一个妻子)
①keySet:把Map中的丈夫取出来放在Set->通过丈夫找出对应的妻子
②entrySet:把Map中的丈夫和妻子的关系取出来(假设为结婚证)->存放在Set中
->通过结婚证,结婚证上有丈夫和妻子啊(Map.Entry)
->调用结婚证特有方法(getKey,getValue)
->获取到丈夫和妻子
*/
package map;
import java.util.*;
class MapDemo3{
public static void main(String[] args){
Map<String,String> map = new HashMap<String,String>();
map.put("02","zhang");
map.put("03","wang");
map.put("04","xu");
//获取map集合中所有key的Set集合
Set<String> s = map.keySet();//Set<String>里面指明key的泛型,因为获取的是key的集合
for(Iterator<String>it = s.iterator();it.hasNext();)
System.out.println(map.get(it.next()));
//entrySet方法,注意用的HashMap存入和取出的顺序不一定一致
Set<Map.Entry<String,String>> s2= map.entrySet();
for(Iterator<Map.Entry<String,String>> it2 = s2.iterator();it2.hasNext(); ){
Map.Entry<String,String> me=it2.next();
System.out.println(me.getKey()+"..."+me.getValue());
}
}
}
/*
分析Map.Entry:
其实Entry也是一个接口,它是Map接口中的一个内部接口.
src中:
//接口经过编译后生成.class文件,可以类比下 内部类
public interface Map<K,V>{
public static interface Entry<K,V>{
K getKey();
V getValue();
V setValue(V value);
}
}
为什要把Entry定义在Map内部?
Entry表示Map中Key与Value的关系,其实Key和Value被
封装在了Entry类(HashMap中一个内部类实现了Map中的Entry接口)中.
static class Entry<K,V> implements Map.Entry<K,V>{
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
.....
}
*/

HashMap集合示例:
/*
每一个学生都有对应的归属地
学生Student,地址String.
学生属性:姓名和年龄相同的视为同一个学生
保证学生的唯一性
*/
//描述学生
//注意这里需要存入到HashMap中
//之前HashSet之所以需要复写hashCode和equals
//因为底层用的其实是HashMap(更确切的说是哈希表)
//为了能够实现对哈希表中的元素进行存储和获取->用作Key的对象需要复写这两个方法
//要想存入到HashMap中,更需要复写
package map;
import java.util.*;
class Student implements Comparable<Student>{//如果Studet继承Person使用Person扩展性更好
private String name;
private int age;
Student(String name,int age){
this.name=name;
this.age=age;
}
public int hashCode(){
return name.hashCode()+age*37;
}
public boolean equals(Object obj){
if(!(obj instanceof Student))
// return false; 返回false没意义,因为不同对象比较没意义
throw new ClassCastException("类型不匹配");//比较好
else
return this.name==((Student)obj).name && this.age==((Student)obj).age;
}
//按姓名比较
public int compareTo(Student stu){
int num=this.name.compareTo(stu.name);
if(num==0)
return this.age-stu.age;
else
return num;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
}
class MapTest{
public static void main(String[] args){
Map<Student,String> map = new HashMap<Student,String>();
map.put(new Student("01",12),"abc");
map.put(new Student("01",12),"bcd");//与第一个key相同,value不同
map.put(new Student("01",12),"abc");//与第一个key,value均相同
map.put(new Student("02",23),"abc");//与第一个key不同,value相同
/*
取出结果:
entrySet: keySet:
-12-abc abc
-23-abc abc
*/
//keySet
//Set<Student> s = map.keySet();
for(Iterator<Student> it = map.keySet().iterator();it.hasNext(); ){
System.out.println(map.get(it.next()));
}
//entrySet
//Set<Map.Entry<Student,String>> s2 = map.entrySet();
for(Iterator<Map.Entry<Student,String>> it = map.entrySet().iterator();it.hasNext(); ){
Map.Entry<Student,String> me=it.next();
Student stu = me.getKey();
System.out.println(stu.getName()+"..."+stu.getAge()+"..."+me.getValue());
}
}
}
/*
需求:对学生对象的年龄进行升序排序
因为数据是以键值对形式存在的.
所以要使用可以排序的Map集合-TreeMap
*/
package map;
import java.util.*;
//自定义比较器,按年龄进行比较
class MyComp implements Comparator<Student>{
public int compare(Student stu_1,Student stu_2){
int num=stu_1.getAge()-stu_2.getAge();
if(num==0)
return stu_1.getName().compareTo(stu_2.getName());
return num;
}
}
class MapTest2{
public static void printMap(Map<Student,String> map){
for(Iterator<Map.Entry<Student,String>> it = map.entrySet().iterator();it.hasNext(); ){
// map.entrySet().iterator();//首先获得一个存储关系对象的集合实体
Map.Entry<Student,String> me=it.next(); //调用iterator()获取一个相应的迭代器实体
Student stu = me.getKey();
System.out.println(stu.getName()+"..."+stu.getAge()+"..."+me.getValue());
}
}
public static void main(String[] args){
Map<Student,String> map = new TreeMap<Student,String>(new MyComp());
map.put(new Student("zhang",18),"BJ");
map.put(new Student("liu",12),"SH");
map.put(new Student("wang",20),"NJ");
map.put(new Student("xu",16),"TJ");
//在构造一个新的TreeMap,使用自然顺序排序
Map<Student,String> map2 = new TreeMap<Student,String>(map);
System.out.println(map);//输出map集合,其中按Key从小到大顺序排列
//但这样输出的Key为对象字符串形式.
printMap(map);
System.out.println("\n");
printMap(map2);
}
}
TreeMap练习2:
/*
"sdfgzxcvasdfxcvdf"
获取该字符串中的字母出现次数
希望打印结果:a(1)c(2)......
每一个字母都有对应的次数.
说明字母和次数之间都有映射关系
当发现有映射关系(一个对应一个)时,可以选择map集合
什么时候使用map集合?
像上面的情况那样(数据之间存在映射关系)->首先考虑map集合
思想:
①首先把字符串转化成字符数组
②拿着字符去map集合中遍历->遍历完未找到a(可以令其返回null)->存入a,1(表示出现一次)
->找到转③
③说明a在map中存在对应的key,此时,取出a对应的value->令value自增->重新存入
④其余字符同理
*/
package map;
import java.util.*;
class TreeMapTest{
//方法一:利用containsKey
public static String charCount(String str,Map<Character,Integer> tm){
char[] ch = str.toCharArray();//转换成字符数组,便于操作
for(int i=0;i<ch.length;++i){
Character c=new Character(ch[i]);
if(!tm.containsKey(c))//没有该Key,加入Map集合
tm.put(c,new Integer(1));
else//有,则替换掉该key对应的value
tm.put(c,new Integer(tm.get(c).intValue()+1));
}
StringBuilder sb = new StringBuilder();
//利用entrySet->转换成指定格式的字符串返回
for(Iterator<Map.Entry<Character,Integer>>it=tm.entrySet().iterator();it.hasNext();){
Map.Entry<Character,Integer> me=it.next();
sb.append("("+me.getKey()+")"+me.getValue());
}
return sb.toString();
}
//方法二:利用get
public static String charCount_2(String str,Map<Character,Integer> tm){
char[] ch = str.toCharArray();
for(int i=0,count=0;i<ch.length;++i,count=0){
if((ch[i]<'a'||ch[i]>'z')&&(ch[i]<'A'||ch[i]>'Z'))//非字母字符,不再计数
continue;
Integer value=tm.get(ch[i]);
if(value!=null)
count=value;//count简化了两次调用put
++count;
tm.put(ch[i],count);
/*
if(value==null)//Key没有对应的Value,返回null,加入集合
tm.put(ch[i],1);
else
tm.put(ch[i],value+1);
*/
}
String mapStr="";//存储集合字符串形式
//利用entrySet->转换成指定格式的字符串返回
for(Iterator<Map.Entry<Character,Integer>>it=tm.entrySet().iterator();it.hasNext();){
Map.Entry<Character,Integer> me=it.next();
mapStr += "("+me.getKey()+")"+me.getValue();
}
return mapStr;
}
public static void main(String[] args){
TreeMap<Character,Integer> tm = new TreeMap<Character,Integer>();
String str = "abae+c";
//System.out.println(charCount(str,tm));
//如果再次使用同一个Map,第二种方法,在遍历a时,会把a对应的Value+1
System.out.println(charCount_2(str,tm));
}
}
/*
//TreeMap/HashMap在使用迭代器方法时,使用了集合的增,删方法时,也会报并发修改异常
tm.put('b',1);
while(it.hasNext())
{
tm.put('a',1);
System.out.println(it.next());
}
*/
/*
总结:该题和以前做过的一个去除集合中的重复元素
使用的同一个算法:
①新建一个集合容器
②每次添加看看该容器是否包含添加的元素
③有则不在添加,没有则加入.
*/
