

网络编程
cs架构
什么是客户端/服务器架构?
不同的人有不同的答案。这要看你问的是什么人,以及指的是软件系统还是硬件系统了。但是,有一点是共通的:服务器是一个软件或硬件,用于向一个或多个客户端(客户)提供所需要的“服务”。服务器存在的唯一目的就是等待客户的请求,给这些客户服务,然后再等待其他的请求。
另一方面,客户连上一个(预先已知的)服务器,提出自己的请求,发送必要的数据,然后就等待服务器的完成请求或说明失败原因的反馈。服务器不停地处理外来的请求,而客户一次只能提出一个服务的请求,等待结果。然后结束这个事务。客户之后也可以再提出其他的请求,只是,这个请求会被视为另一个不同的事务了。
图16-1展示了如今最常见的“客户端/服务器”结构。一个用户或客户端电脑通过因特网从服务器上取数据。这的确是一个客户端/服务器架构的系统,但还有更多类似的系统满足客户端/服务器架构。而且,客户端/服务器架构也可以像应用到软件上那样应用到计算机硬件上。
1.硬件的客户端/服务器架构
打印(机)服务器是一个硬件服务器的例子。它们处理打印任务,并把任务发给相连的打印机(或其他打印设备)。这样的计算机一般是可以通过网络访问的,而且客户机器可以远程发送打印请求给它。
另一个硬件服务器的例子是文件服务器。它们一般拥有大量的存储空间,客户可以远程访问。客户端计算机可以把服务器的磁盘映射到自己本地,就像本地磁盘一样使用它们。其中,Sun公司的NetworkFile System (NFS)是使用最为广泛的网络文件系统之一。如果你事实上已经映射了一个网络上的磁盘,但你却不知道它到底是本地的还是网络的,那客户端/服务器系统就很好的完成了它们的工作。其目的就是要让用户使用起来感觉就像使用本地磁盘一样。“抽象”到“一般的磁盘访问”这一层面之后,所有的操作就都是一样的了,而让所有操作都一样的“实现”则要依靠各自的程序了。
2.软件客户端/服务器架构
软件服务器也是运行在某个硬件上的。但不像硬件服务器那样,有专门的设备,如打印机、磁盘等。软件服务器提供的服务主要是程序的运行、数据的发送与接收、合并、升级或其他的程序或数据的操作。
如今,最常用的软件服务器是Web服务器。一台机器里放一些网页或Web应用程序,然后启动服务。这样的服务器的任务就是接受客户端的请求,把网页发给客户端(如用户计算机上的浏览器),然后等待下一个客户端请求。这些服务启动后的目标就是“永远运行下去”。虽然它们不可能实现这样的目标,但只要没有关机或硬件出错等外力干扰,它们就能够运行非常长的一段时间。
数据库服务器是另一种软件服务器。它们接受客户端的保存或读取请求,完成请求,然后再等待其他的请求。它们也被设计为要能“永远”运行。
我们要讨论的最后一种软件服务器是窗口服务器。这些服务器几乎可以被认为是硬件服务器了。它们运行于一个有显示器的机器上。窗口客户端实际上是那些在运行时需要窗口环境的程序,它们一般叫做图形用户界面(GUI)程序。这些程序如果在一个DOS窗口或Unix的shell等没有窗口服务器的纯文本环境中运行,将无法启动。一旦窗口服务器可以使用时,那一切就正常了。
当世界有了网络,那这样的环境就开始变得更有趣了。一般情况下,窗口客户端的显示和窗口服务器的提供都在同一台电脑上。但在X Window之类的网络化的窗口环境中,你可以选择其他电脑的窗口服务器来做显示。即你可以在一台电脑上运行GUI程序,而在另一台电脑上显示它!
3.银行出纳是服务器吗
理解客户端/服务器架构的一个方法是,想象一个不吃不喝不睡觉的银行出纳,他依次向排成长龙的顾客们提供一个又一个的服务(图16-2)。有时,队伍可能很长,有时也可能没人。但顾客随时都可能出现。当然,在以前,是不可能有这样的出纳的。但现在的ATM机与这个模型很像。
当然,出纳就是一个运行在无限循环里的服务器。每一个顾客就是一个想要得到服务的客户。顾客到了之后,就按先来先服务(first-come-first-served, FCFS)的原则得到服务。一个事务结束后,客户就离开了,而服务器则要么马上为下一个顾客服务,要么坐着等待下一个顾客的到来。
为什么这些概念那么重要?因为,这种执行的方式就是客户端/服务器架构的特点。现在你对此已经有了大体的认识,我们就可以把客户端/服务器架构模型应用到网络编程中。
出纳运行在一个接收请求,处理请求然后再处理其他请求或等待其他客户的无限循环中。客户有可能已经排起了长龙,也有可能根本就没有客户。但是,无论如何,服务器都不会结束工作。
在完成服务之前,服务器必需要先完成一些设置。先要创建一个通讯端点,让服务器能“监听”请求。你可以把我们的服务器比做一个公司的接待员或回答公司总线电话的话务员,一旦电话和设备安装完成,话务员也就位之后,服务就可以开始了。
在网络世界里,基本上也是这样——一旦通信端点创建好之后,我们在“监听”的服务器就可以进入它那等待和处理客户请求的无限循环中了。当然,我们也不能忘记在信纸上、杂志里、广告中印上公司的电话号码。否则,就没有人会打电话进来了!
同样地,服务器在准备好之后,也要通知潜在的客户,让它们知道服务器已经准备好处理服务了,否则没有人会提请求的。比方说,你建立了一个全新的网站。这个网站非常出色,非常的吸引人,非常的有用,是所有网站中最酷的一个。但如果你不把网站的网址或者说统一资源定位符(URL)广而告之的话,没有人会知道这个网站的存在的。这个网站也就永远不见天日了。对于公司总部的新电话也是这样,你不把电话公之于众,那就没有人会打电话进来。
现在,你对服务器如何工作已经有了一个很好的认识。你已经完成了最难的那一部分。客户端的编程相对服务器端来说就简单得多了。所有的客户只要创建一个通信端点,建立到服务器的连接。然后客户端就可以提出请求了。请求中,也可以包含必要的数据交互。一旦请求处理完成,客户端收到了结果,通信就结束了。
套接字
套接字是一种具有之前所说的“通信端点”概念的计算机网络数据结构。网络化的应用程序在开始任何通讯之前都必需要创建套接字。就像电话的插口一样,没有它就完全没办法通信。
套接字起源于20世纪70年代加州大学伯克利分校版本的Unix,即人们所说的BSD Unix。因此,有时人们也把套接字称为“伯克利套接字”或“BSD套接字”。一开始,套接字被设计用在同一台主机上多个应用程序之间的通讯。这也被称作进程间通讯,或IPC。套接字有两种,分别是基于文件型的和基于网络型的。
Unix套接字是我们要介绍的第一个套接字家族。其“家族名”为AF_UNIX(在POSIX1.g标准中也叫AF_LOCAL),表示“地址家族:UNIX”。包括Python在内的大多数流行平台上都使用术语“地址家族”及其缩写“AF”。而老一点的系统中,地址家族被称为“域”或“协议家族”,并使用缩写“PF”而不是“AF”。同样的,AF_LOCAL(在2000-2001年被列为标准)将会代替AF_UNIX。不过,为了向后兼容,很多系统上,两者是等价的。Python自己则仍然使用AF_UNIX。
由于两个进程都运行在同一台机器上,而且这些套接字是基于文件的。所以,它们的底层结构是由文件系统来支持的。这样做相当有道理,因为,同一台电脑上,文件系统的确是不同的进程都能访问的。
另一种套接字是基于网络的,它有自己的家族名字:AF_INET,或叫“地址家族:Internet”。还有一种地址家族AF_INET6被用于网际协议第6版(IPv6)寻址上。还有一些其他的地址家族,不过,它们要么是只用在某个平台上,要么就是已经被废弃,或是很少被使用,或是根本就还没有实现。所有地址家族中,AF_INET是使用最广泛的一个。Python 2.5中加入了一种Linux套接字的支持:AF_NETLINK(无连接(稍后讲解))套接字家族让用户代码与内核代码之间的IPC可以使用标准BSD套接字接口。而且,相对之前那些往操作系统中加入新的系统调用、proc文件系统支持或是“IOCTL”等复杂的方案来说,这种方法显得更为精巧,更为安全。
Python只支持AF_UNIX, AF_NETLINK,和AF_INET家族。由于我们只关心网络编程,所以在本章的大部分时候,我们都只用AF_INET。
如果把套接字比做电话的插口——即通信的最底层结构,那主机与端口就像区号与电话号码的一对组合。有了能打电话的硬件还不够,你还要知道你要打给谁,往哪打。一个因特网地址由网络通信所必需的主机与端口组成。而且不用说,另一端一定要有人在听才可以。否则,你就会听到熟悉的声音“对不起,您拨的是空号,请查询后再拨”。你在上网的时候,可能也见过类似的情况,如“不能连接该服务器。服务器无响应或不可达”。
合法的端口号范围为0~65535。其中,小于1024的端口号为系统保留端口。如果你所使用的是Unix操作系统,那么就可以通过/etc/services文件获得保留的端口号(及其对应的服务/协议和套接字类型)。
面向连接
无论你使用哪一种地址家族,套接字的类型只有两种。一种是面向连接的套接字,即在通信之前一定要建立一条连接,就像跟朋友打电话时那样。这种通信方式也被称为“虚电路”或“流套接字”。面向连接的通信方式提供了顺序的、可靠的、不会重复的数据传输,而且也不会被加上数据边界。这也意味着,每一个要发送的信息,可能会被拆分成多份,每一份都会不多不少地正确到达目的地。然后被重新按顺序拼装起来,传给正在等待的应用程序。
实现这种连接的主要协议就是传输控制协议(即TCP)。要创建TCP套接字就得在创建的时候指定套接字类型为SOCK_STREAM。TCP套接字采用SOCK_STREAM这个名字,表达了它作为流套接字的特点。由于这些套接字使用网际协议(IP)来查找网络中的主机,所以这样形成的整个系统,一般会由这两个协议(TCP和IP)名的组合来描述,即TCP/IP。
无连接
与虚电路完全相反的是数据报型的无连接套接字。这意味着,无需建立连接就可以进行通讯。但这时,数据到达的顺序、可靠性及不重复性就无法保证了。数据报会保留数据边界,这就表示,数据是整个发送的,不会像面向连接的协议那样被先拆分成小块。
使用数据报来传输数据就像邮政服务一样。邮件和包裹不一定会按它们发送的顺序到达。事实上,它们还有可能根本到达不了!而且,在网络中报文甚至会重复发送,这也增加了复杂性。
既然数据报有这么多缺点,为什么还要使用它呢?(一定有能胜过流套接字的功能!)由于面向连接套接字要提供一些保证,以及要维持虚电路连接,这都是很重的额外负担。数据报没有这些负担,所以它更“便宜”。通常能提供更好的性能,更适合某些应用场合。
实现这种连接的主要协议就是用户数据报协议(即UDP)。要创建UDP套接字就得在创建的时候指定套接字类型为SOCK_DGRAM。 SOCK_DGRAM这个名字,也许你已经猜到了,来自于单词“datagram”(“数据报”)。由于这些套接字使用网际协议来查找网络中的主机,这样形成的整个系统,一般会由这两个协议(UDP和IP)名的组合来描述,即UDP/IP。



1 服务器端套接字函数 2 s.bind() 绑定地址(主机,端口号对)到套接字 3 s.listen() 开始 TCP 监听 4 s.accept() 被动接受 TCP 客户的连接,(阻塞式)等待连接的到来 5 6 客户端套接字函数 7 s.connect() 主动初始化 TCP 服务器连接 8 s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛异常 9 10 普通的套接字方法 11 s.recv() 接收 TCP 消息 12 s.recv_into() 接收 TCP 消息到指定的缓冲区 13 s.send() 发送 TCP 消息 14 s.sendall() 完整地发送 TCP 消息 15 s.recvfrom() 接收 UDP 消息 16 s.recvfrom_into() 接收 UDP 消息到指定的缓冲区 17 s.sendto() 发送 UDP 消息 18 s.getpeername() 连接到套接字(TCP)的远程地址 19 s.getsockname() 当前套接字的地址 20 s.getsockopt() 返回给定套接字选项的值 21 s.setsockopt() 设置给定套接字选项的值 22 s.shutdown() 关闭连接 23 s.close() 关闭套接字 24 s.detach() 在未关闭文件描述符的情况下关闭套接字,返回文件描述符 25 s.ioctl() 控制套接字的模式(仅支持 Windows) 26 27 面向阻塞的套接字方法 28 s.setblocking() 设置套接字的阻塞或非阻塞模式 29 s.settimeout() 设置阻塞套接字操作的超时时间 30 s.gettimeout() 获取阻塞套接字操作的超时时间 31 32 面向文件的套接字方法 33 s.fileno() 套接字的文件描述符 34 s.makefile() 创建与套接字关联的文件对象 35 36 数据属性 37 s.family 套接字家族 38 s.type 套接字类型 39 s.proto 套接字协议
OSI参考模型
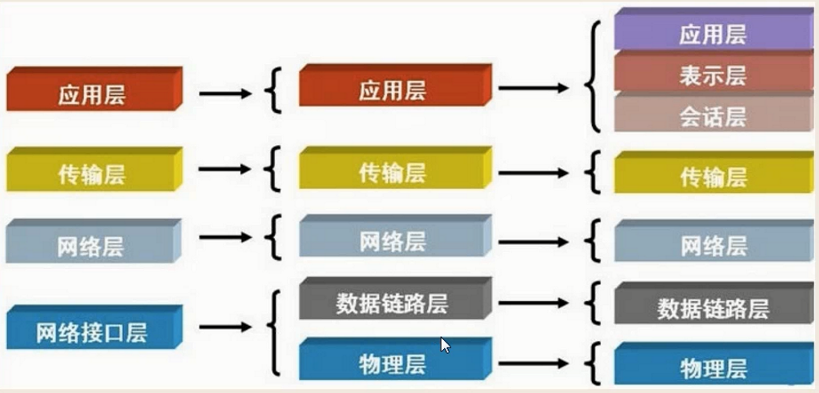
简单概述
高低电平,电信号,0101
但是单纯的0101没有意义,于是有了数据链路层,把0101分组,并且数据链路层有一个统一的以太网协议,Ethernet协议
Ethernet协议规定
l 一组电信号构成一个数据包,叫做“帧”
l 每一帧数据分为报头head和数据data两部分
跨子网通信要用到IP地址,端口找到那个软件
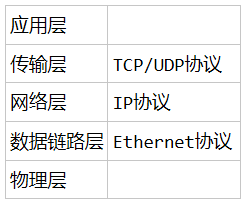
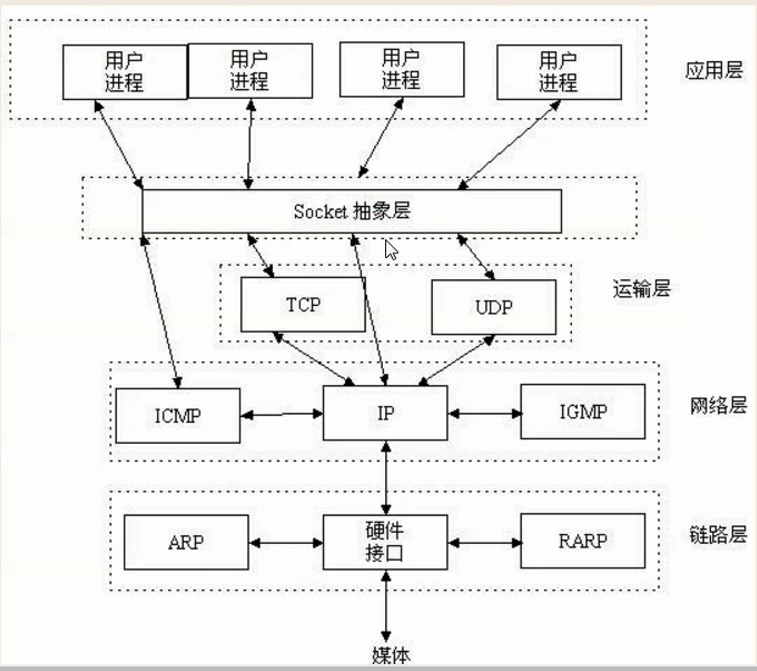
而在应用层与传输层之间,规定了一个抽象层
对于开发人员来说,只需要遵循socket协议开发,屏蔽底层细节
socket相当于IP+port


family: AF_INET/AF_VNIX
type: SOCK_STREAM或SOCK_DGRAM
proto一般不填


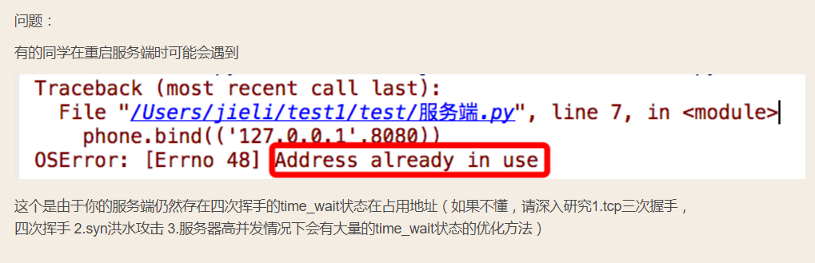
简单的socektserver
1 import socket 2 3 # stream 就是tcp协议,tcp叫流式协议 4 # dgram 就是报,udp协议 5 tcp_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) 6 tcp_server.bind(("127.0.0.1", 8080)) 7 tcp_server.listen(5) 8 conn, client_addr = tcp_server.accept() 9 print("client_addr: ", client_addr) 10 print(client_addr) 11 12 # 通讯循环 13 while True: 14 # 收消息 15 client_msg = conn.recv(1024) # 收消息 8092-8K 16 print("client_msg:", client_msg) 17 # 发消息 18 conn.send("lengmo".encode("utf-8")) 19 20 conn.close() 21 22 tcp_server.close()
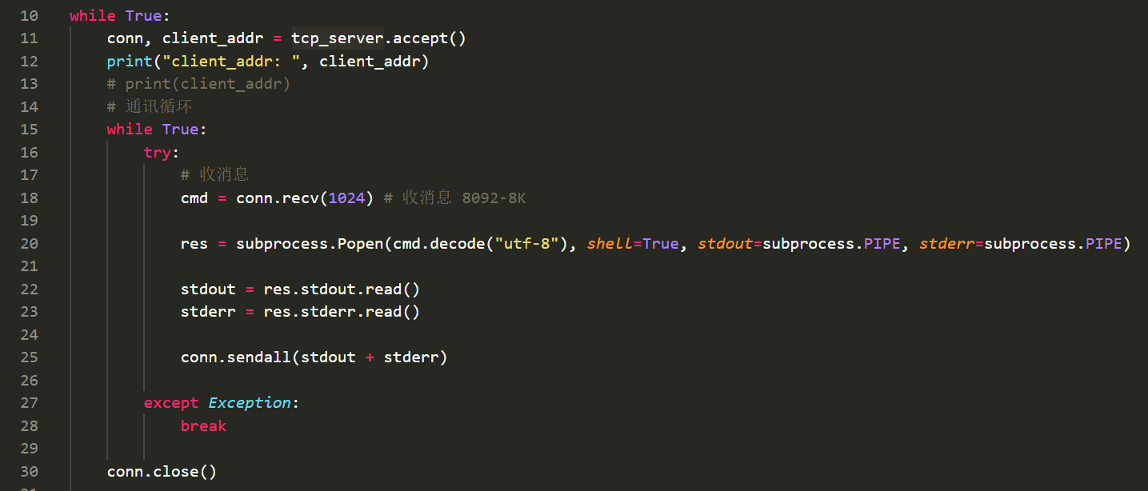
防链接断开后抛异常
1 添加一个异常处理 2 import socket 3 # stream 就是tcp协议,tcp叫流式协议 4 # dgram 就是报,udp协议 5 tcp_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) 6 tcp_server.bind(("127.0.0.1", 8080)) 7 tcp_server.listen(5) 8 conn, client_addr = tcp_server.accept() 9 print("client_addr: ", client_addr) 10 print(client_addr) 11 # 通讯循环 12 while True: 13 try: 14 # 收消息 15 client_msg = conn.recv(1024) # 收消息 8092-8K 16 print("client_msg:", client_msg) 17 # 发消息 18 conn.send("lengmo".encode("utf-8")) 19 except Exception: 20 break 21 conn.close() 22 tcp_server.close() 23 24 也可以把整个循环try起来,finally后面加conn.close()
1 importsocket 2 #stream就是tcp协议,tcp叫流式协议 3 #dgram就是报,udp协议 4 tcp_server=socket.socket(socket.AF_INET,socket.SOCK_STREAM) 5 tcp_server.bind(("127.0.0.1",8080)) 6 tcp_server.listen(5) 7 8 9 whileTrue: 10 conn,client_addr=tcp_server.accept() 11 print("client_addr:",client_addr) 12 #print(client_addr) 13 #通讯循环 14 while True: 15 try: 16 #收消息 17 client_msg=conn.recv(1024)#收消息8092-8K 18 print("client_msg:",client_msg) 19 20 #发消息 21 conn.send("lengmo".encode("utf-8")) 22 exceptException: 23 break 24 25 conn.close() 26 27 28 tcp_server.close()
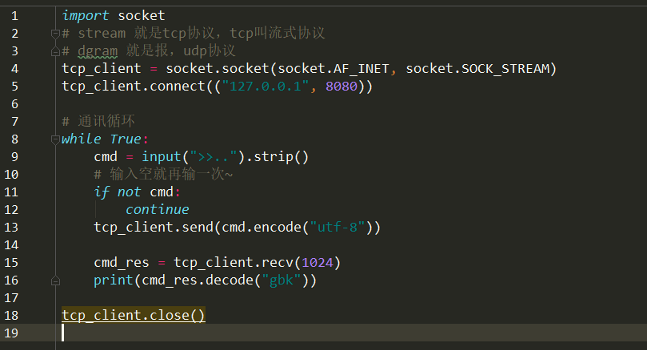
TCP可靠,三次握手四次挥手,底层每发一次消息都要确认
UD更多用在广报消息,在意实时,不需要提前建立连接
简单udp
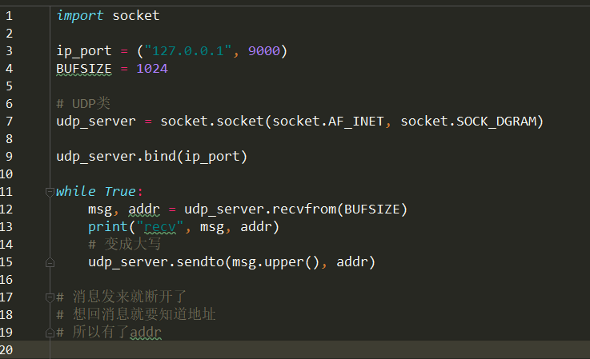
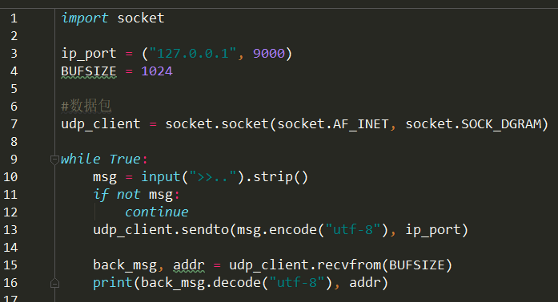
粘包问题——现象
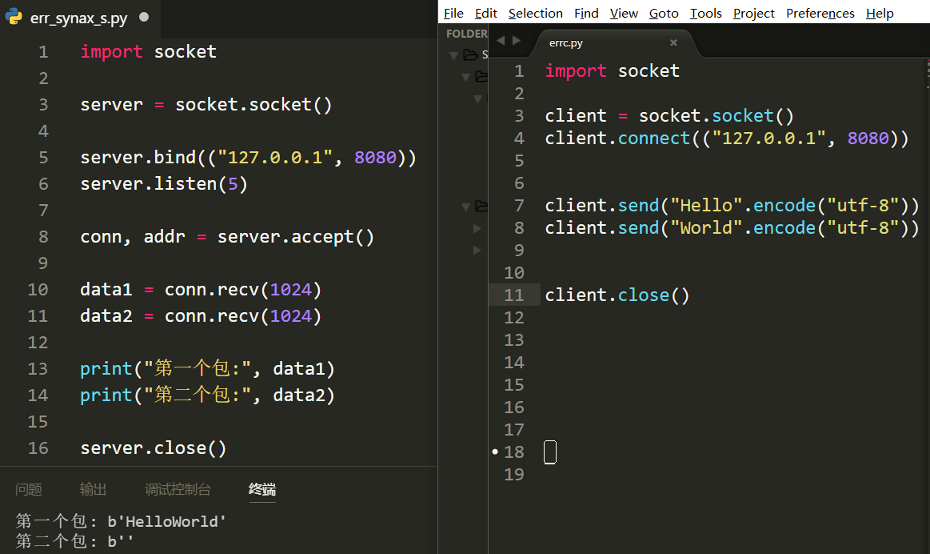
左边 server 右边 client
左边 10 和 11 行期望收到的效果和打印出的效果不同,data1 和 data2 被放到一个文件夹中
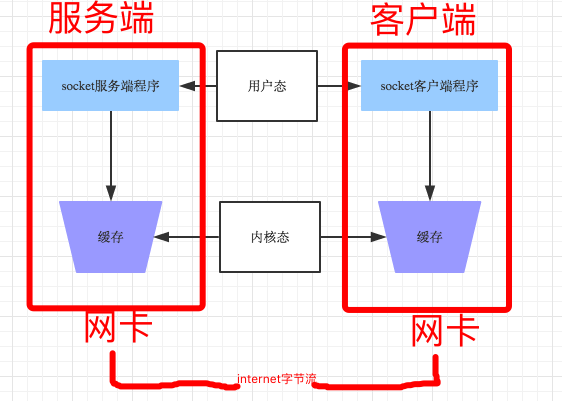
发送端可以是一K一K地发送数据,而接收端的应用程序可以两K两K地提走数据,当然也有可能一次提走3K或6K数据,或者一次只提走几个字节的数据,也就是说,应用程序所看到的数据是一个整体,或说是一个流(stream),一条消息有多少字节对应用程序是不可见的,因此TCP协议是面向流的协议,这也是容易出现粘包问题的原因。而UDP是面向消息的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,这一点和TCP是很不同的。怎样定义消息呢?可以认为对方一次性write/send的数据为一个消息,需要明白的是当对方send一条信息的时候,无论底层怎样分段分片,TCP协议层会把构成整条消息的数据段排序完成后才呈现在内核缓冲区。
例如基于tcp的套接字客户端往服务端上传文件,发送时文件内容是按照一段一段的字节流发送的,在接收方看了,根本不知道该文件的字节流从何处开始,在何处结束
所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
1. TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
2. UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
3. tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,即便是你输入的是空内容(直接回车),那也不是空消息,udp协议会帮你封装上消息头,实验略
udp的recvfrom是阻塞的,一个recvfrom(x)必须对一个一个sendinto(y),收完了x个字节的数据就算完成,若是y>x数据就丢失,这意味着udp根本不会粘包,但是会丢数据,不可靠
tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容。数据是可靠的,但是会粘包。
两种情况下会发生粘包。
发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包)
接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
1
Python struct模块
转载请标明出处(http://blog.csdn.net/lis_12/article/details/52777983).
用处
- 按照指定格式将Python数据转换为字符串,该字符串为字节流,如网络传输时,不能传输int,此时先将int转化为字节流,然后再发送;
- 按照指定格式将字节流转换为Python指定的数据类型;
- 处理二进制数据,如果用struct来处理文件的话,需要用’wb’,’rb’以二进制(字节流)写,读的方式来处理文件;
- 处理c语言中的结构体;
struct模块中的函数
| 函数 | return | explain |
|---|---|---|
| pack(fmt,v1,v2…) | string | 按照给定的格式(fmt),把数据转换成字符串(字节流),并将该字符串返回. |
| pack_into(fmt,buffer,offset,v1,v2…) | None | 按照给定的格式(fmt),将数据转换成字符串(字节流),并将字节流写入以offset开始的buffer中.(buffer为可写的缓冲区,可用array模块) |
| unpack(fmt,v1,v2…..) | tuple | 按照给定的格式(fmt)解析字节流,并返回解析结果 |
| pack_from(fmt,buffer,offset) | tuple | 按照给定的格式(fmt)解析以offset开始的缓冲区,并返回解析结果 |
| calcsize(fmt) | size of fmt | 计算给定的格式(fmt)占用多少字节的内存,注意对齐方式 |
格式化字符串
当打包或者解包的时,需要按照特定的方式来打包或者解包.该方式就是格式化字符串,它指定了数据类型,除此之外,还有用于控制字节顺序、大小和对齐方式的特殊字符.
对齐方式
为了同c中的结构体交换数据,还要考虑c或c++编译器使用了字节对齐,通常是以4个字节为单位的32位系统,故而struct根据本地机器字节顺序转换.可以用格式中的第一个字符来改变对齐方式.定义如下
| Character | Byte order | Size | Alignment |
|---|---|---|---|
| @(默认) | 本机 | 本机 | 本机,凑够4字节 |
| = | 本机 | 标准 | none,按原字节数 |
| < | 小端 | 标准 | none,按原字节数 |
| > | 大端 | 标准 | none,按原字节数 |
| ! | network(大端) | 标准 | none,按原字节数 |
如果不懂大小端,见大小端参考网址.
格式符
| 格式符 | C语言类型 | Python类型 | Standard size |
|---|---|---|---|
| x | pad byte(填充字节) | no value | |
| c | char | string of length 1 | 1 |
| b | signed char | integer | 1 |
| B | unsigned char | integer | 1 |
| ? | _Bool | bool | 1 |
| h | short | integer | 2 |
| H | unsigned short | integer | 2 |
| i | int | integer | 4 |
| I(大写的i) | unsigned int | integer | 4 |
| l(小写的L) | long | integer | 4 |
| L | unsigned long | long | 4 |
| q | long long | long | 8 |
| Q | unsigned long long | long | 8 |
| f | float | float | 4 |
| d | double | float | 8 |
| s | char[] | string | |
| p | char[] | string | |
| P | void * | long |
注- -!
- _Bool在C99中定义,如果没有这个类型,则将这个类型视为char,一个字节;
- q和Q只适用于64位机器;
- 每个格式前可以有一个数字,表示这个类型的个数,如s格式表示一定长度的字符串,4s表示长度为4的字符串;4i表示四个int;
- P用来转换一个指针,其长度和计算机相关;
- f和d的长度和计算机相关;
code,使用示例
1 #!/usr/bin/python 2 # -*- coding:utf-8 -*- 3 '''测试struct模块''' 4 from struct import * 5 import array 6 7 def fun_calcsize(): 8 print 'ci:',calcsize('ci')#计算格式占内存大小 9 print '@ci:',calcsize('@ci') 10 print '=ci:',calcsize('=ci') 11 print '>ci:',calcsize('>ci') 12 print '<ci:',calcsize('<ci') 13 print 'ic:',calcsize('ic')#计算格式占内存大小 14 print '@ic:',calcsize('@ic') 15 print '=ic:',calcsize('=ic') 16 print '>ic:',calcsize('>ic') 17 print '<ic:',calcsize('<ic') 18 19 def fun_pack(Format,msg = [0x11223344,0x55667788]): 20 result = pack(Format,*msg) 21 print 'pack'.ljust(10),str(type(result)).ljust(20), 22 for i in result: 23 print hex(ord(i)), # ord把ASCII码表中的字符转换成对应的整形,hex将数值转化为十六进制 24 print 25 26 result = unpack(Format,result) 27 print 'unpack'.ljust(10),str(type(result)).ljust(20), 28 for i in result: 29 print hex(i), 30 print 31 32 def fun_pack_into(Format,msg = [0x11223344,0x55667788]): 33 r = array.array('c',' '*8)#大小为8的可变缓冲区,writable buffer 34 result = pack_into(Format,r,0,*msg) 35 print 'pack_into'.ljust(10),str(type(result)).ljust(20), 36 for i in r.tostring(): 37 print hex(ord(i)), 38 print 39 40 result = unpack_from(Format,r,0) 41 print 'pack_from'.ljust(10),str(type(result)).ljust(20), 42 for i in result: 43 print hex(i), 44 print 45 46 def IsBig_Endian(): 47 '''判断本机为大/小端''' 48 a = 0x12345678 49 result = pack('i',a)#此时result就是一个string字符串,字符串按字节同a的二进制存储内容相同。 50 if hex(ord(result[0])) == '0x78': 51 print '本机为小端' 52 else: 53 print '本机为大端' 54 55 def test(): 56 a = '1234' 57 for i in a: 58 print '字符%s的二进制:'%i,hex(ord(i))#字符对应ascii码表中对应整数的十六进制 59 60 ''' 61 不用unpack()返回的数据也是可以使用pack()函数的,只要解包的字符串符合解包格式即可, 62 pack()会按照解包格式将字符串在内存中的二进制重新解释(说的感觉不太好...,见下例) 63 ''' 64 print '大端:',hex(unpack('>i',a)[0])#因为pack返回的是元组,即使只有一个元素也是元组的形式 65 print '小端:',hex(unpack('<i',a)[0]) 66 67 68 if __name__ == "__main__": 69 print '判断本机是否为大小端?', 70 IsBig_Endian() 71 72 fun_calcsize() 73 74 print '大端:' 75 Format = ">ii" 76 fun_pack(Format) 77 fun_pack_into(Format) 78 79 print '小端:' 80 Format = "<ii" 81 fun_pack(Format) 82 fun_pack_into(Format) 83 84 print 'test' 85 test() 86 ''' 87 result: 88 判断本机是否为大小端? 本机为小端 89 ci: 8 90 @ci: 8 91 =ci: 5 92 >ci: 5 93 <ci: 5 94 ic: 5 95 @ic: 5 96 =ic: 5 97 >ic: 5 98 <ic: 5 99 大端: 100 pack <type 'str'> 0x11 0x22 0x33 0x44 0x55 0x66 0x77 0x88 101 unpack <type 'tuple'> 0x11223344 0x55667788 102 pack_into <type 'NoneType'> 0x11 0x22 0x33 0x44 0x55 0x66 0x77 0x88 103 pack_from <type 'tuple'> 0x11223344 0x55667788 104 小端: 105 pack <type 'str'> 0x44 0x33 0x22 0x11 0x88 0x77 0x66 0x55 106 unpack <type 'tuple'> 0x11223344 0x55667788 107 pack_into <type 'NoneType'> 0x44 0x33 0x22 0x11 0x88 0x77 0x66 0x55 108 pack_from <type 'tuple'> 0x11223344 0x55667788 109 test 110 字符1的二进制: 0x31 111 字符2的二进制: 0x32 112 字符3的二进制: 0x33 113 字符4的二进制: 0x34 114 大端:0x31323334 115 小端:0x34333231 116 '''
Python参考手册struct模块链接
英文单词
| 英文 | 中文 |
|---|---|
| compact | 紧凑的,简洁的 |
| layout | 布局 |
| pad bytes | 填充字节 |
| alignment | 对齐方式 |
| maintain | 维持,保持 |
| proper | 适当的 |
| correspond | 一致,相应的 |
| platform-independent | 平台依赖,即机器,操作系统不同,对齐方式,大小端等会有差异 |
| omit | 忽略 |
| implicit | 暗含的,隐式的 |
| native | 本台电脑的 |
| presumably | 假设 |
| even if | 即使 |
| specify | 指定 |
| mechanism | 原理,机制,手法 |
| represented | 表现,表示 |
| assumed | 假定的,默认的 |
socketserver实现并发
服务端的特点:
1. 一直提供服务(链接循环),基于一个链接通信循环
2. 绑定一个唯一的地址

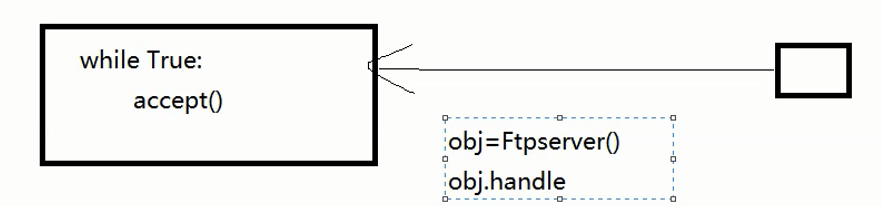
拿到这个对象执行下面的handle方法

SocketServer
我们学习了利用socket模块创建socket通信服务,但细心学习后就会发现利用socket模块创建的服务无法进行多进程的处理,当需要进行大量请求处理时,请求就会阻塞在队列中,甚至发生请求丢弃。并且如果我们需要大量的socket时,就需要重复创建许多socket、绑定端口..... ,对于程序员来说意味着重复书写大量无意义代码。
那有没有一种方式既能简化书写流程又能实现多线程开发呢 ? 答案是肯定的,这就是SocketServer模块。
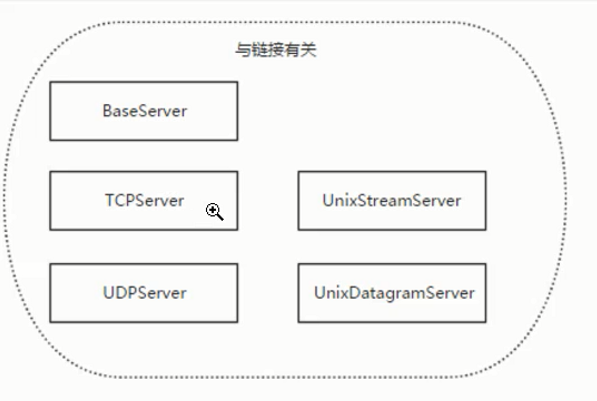
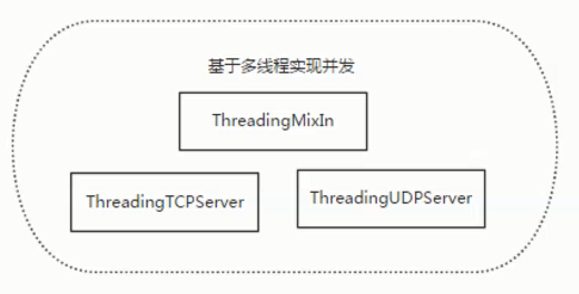
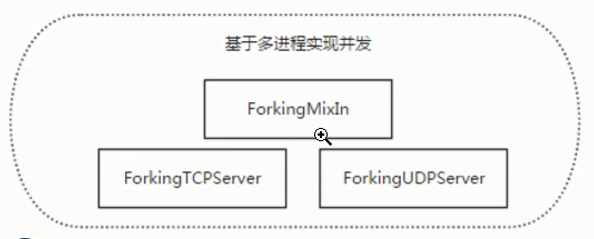
SocketServer简化了网络服务器的编写。在进行socket创建时,使用SocketServer会大大减少创建的步骤,并且SocketServer使用了select它有4个类:TCPServer,UDPServer,UnixStreamServer,UnixDatagramServer。这4个类是同步进行处理的,另外通过ForkingMixIn和ThreadingMixIn类来支持异步。
使用SocketServer的步骤简介
1. 创建服务器的步骤。首先,你必须创建一个请求处理类,它是BaseRequestHandler的子类并重载其handle()方法。
2. 实例化一个服务器类,传入服务器的地址和请求处理程序类。
3. 最后,调用handle_request()(一般是调用其他事件循环或者使用select())或serve_forever()。
集成ThreadingMixIn类时需要处理异常关闭。daemon_threads指示服务器是否要等待线程终止,要是线程互相独立,必须要设置为True,默认是False。
无论用什么网络协议,服务器类有相同的外部方法和属性。
该模块在python3中已经更名为socketserver。
举例:

#!/usr/bin/env python
# -*- coding:utf-8 -*-
import SocketServer
class MyServer(SocketServer.BaseRequestHandler):
def handle(self):
//some method....
if __name__='__main__':
server = SocketServer.ThreadingTCPServer(('127.0.0.1,9999'),MyServer)
server.serve_forever()
上面的步骤你可能会看不懂或者不理解为什么这么操作,下面我们进行详细解释。我们进行了如下的操作
一、自定义了一个MyServer类,继承自SocketServer模块中的BaseRequestHandler类。
二、在主函数中,使用SocketServer函数中的ThreadingTCPServer类进行了实例化操作。上边例子中实例化了对象为server,并在进行实例化时进行了参数的传递,参数一:服务器IP与端口号 参数二:自定义函数名称
源码分析
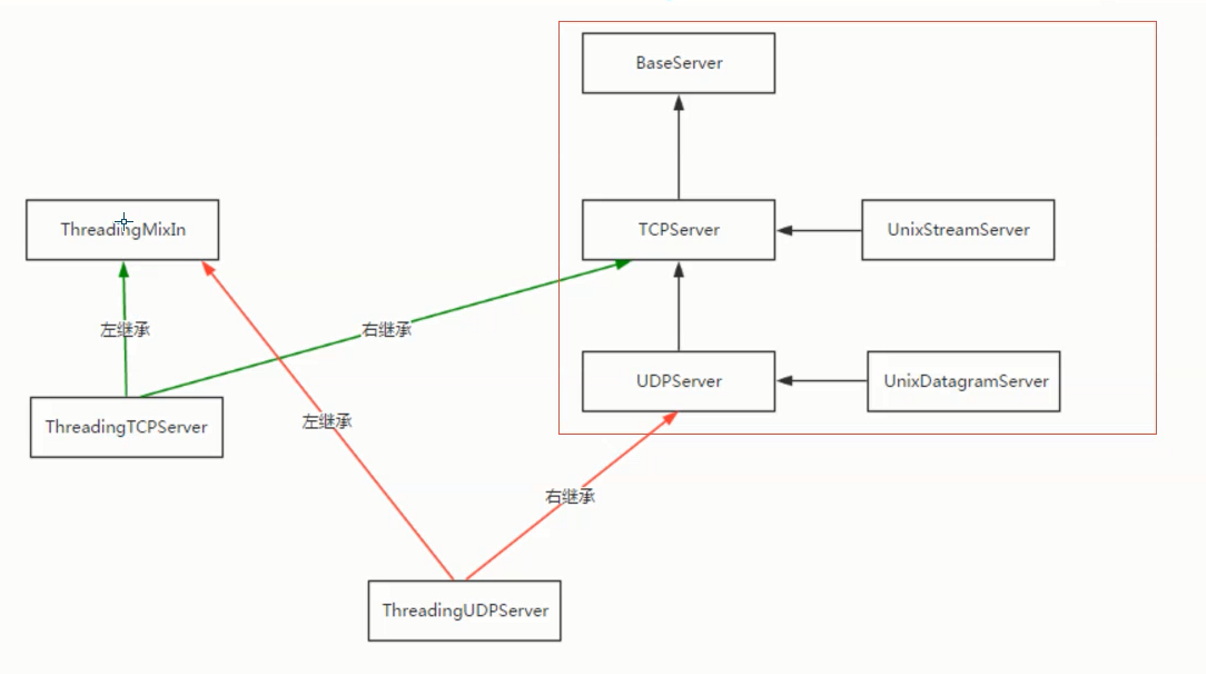
第二步中主函数操作。查看SocketServer模块源码[下面]可以发现。ThreadingTCPServer是继承自基类(ThreadingMixIn,TCPServer),但函数结构体是pass,也就是左右操作全部通过基类中方法进行执行,而基类中的TCPServer又有基类BaseServer。结构图如下
BaseServer
↑
TCPServer ThreadingMixIn
↑ ↑
ThreadingTCPServer
可以看出:ThreadingTCPServer的所有的方法都在它的基类函数中
各个基类作用分别是:
BaseServer:利用select创建多进程
TCPServer:创建每个进程的socket
ThreadingMixIn:Mix-in class to handle each request in a new thread.
第一步中的创建自定义类。继承自BaseRequestHandler类。从源码中看出他的作用就是接受请求,地址,和自定义名称,然后交给它的方法处理。默认的三个处理函数为pass,所以当我们使用时需要进行函数代码重构。
class BaseRequestHandler:
"""Base class for request handler classes.
This class is instantiated for each request to be handled. The
constructor sets the instance variables request, client_address
and server, and then calls the handle() method. To implement a
specific service, all you need to do is to derive a class which
defines a handle() method.
The handle() method can find the request as self.request, the
client address as self.client_address, and the server (in case it
needs access to per-server information) as self.server. Since a
separate instance is created for each request, the handle() method
can define arbitrary other instance variariables.
"""
def __init__(self, request, client_address, server):
self.request = request
self.client_address = client_address
self.server = server
self.setup()
try:
self.handle()
finally:
self.finish()
def setup(self):
pass
def handle(self):
pass
def finish(self):
pass
1 """Generic socket server classes.
2 This module tries to capture the various aspects of defining a server:
3 For socket-based servers:
4 - address family:
5 - AF_INET{,6}: IP (Internet Protocol) sockets (default)
6 - AF_UNIX: Unix domain sockets
7 - others, e.g. AF_DECNET are conceivable (see <socket.h>
8 - socket type:
9 - SOCK_STREAM (reliable stream, e.g. TCP)
10 - SOCK_DGRAM (datagrams, e.g. UDP)
11
12 For request-based servers (including socket-based):
13
14 - client address verification before further looking at the request
15 (This is actually a hook for any processing that needs to look
16 at the request before anything else, e.g. logging)
17 - how to handle multiple requests:
18 - synchronous (one request is handled at a time)
19 - forking (each request is handled by a new process)
20 - threading (each request is handled by a new thread)
21
22 The classes in this module favor the server type that is simplest to
23 write: a synchronous TCP/IP server. This is bad class design, but
24 save some typing. (There's also the issue that a deep class hierarchy
25 slows down method lookups.)
26
27 There are five classes in an inheritance diagram, four of which represent
28 synchronous servers of four types:
29
30 +------------+
31 | BaseServer |
32 +------------+
33 |
34 v
35 +-----------+ +------------------+
36 | TCPServer |------->| UnixStreamServer |
37 +-----------+ +------------------+
38 |
39 v
40 +-----------+ +--------------------+
41 | UDPServer |------->| UnixDatagramServer |
42 +-----------+ +--------------------+
43
44 Note that UnixDatagramServer derives from UDPServer, not from
45 UnixStreamServer -- the only difference between an IP and a Unix
46 stream server is the address family, which is simply repeated in both
47 unix server classes.
48
49 Forking and threading versions of each type of server can be created
50 using the ForkingMixIn and ThreadingMixIn mix-in classes. For
51 instance, a threading UDP server class is created as follows:
52
53 class ThreadingUDPServer(ThreadingMixIn, UDPServer): pass
54
55 The Mix-in class must come first, since it overrides a method defined
56 in UDPServer! Setting the various member variables also changes
57 the behavior of the underlying server mechanism.
58
59 To implement a service, you must derive a class from
60 BaseRequestHandler and redefine its handle() method. You can then run
61 various versions of the service by combining one of the server classes
62 with your request handler class.
63
64 The request handler class must be different for datagram or stream
65 services. This can be hidden by using the request handler
66 subclasses StreamRequestHandler or DatagramRequestHandler.
67
68 Of course, you still have to use your head!
69
70 For instance, it makes no sense to use a forking server if the service
71 contains state in memory that can be modified by requests (since the
72 modifications in the child process would never reach the initial state
73 kept in the parent process and passed to each child). In this case,
74 you can use a threading server, but you will probably have to use
75 locks to avoid two requests that come in nearly simultaneous to apply
76 conflicting changes to the server state.
77
78 On the other hand, if you are building e.g. an HTTP server, where all
79 data is stored externally (e.g. in the file system), a synchronous
80 class will essentially render the service "deaf" while one request is
81 being handled -- which may be for a very long time if a client is slow
82 to read all the data it has requested. Here a threading or forking
83 server is appropriate.
84
85 In some cases, it may be appropriate to process part of a request
86 synchronously, but to finish processing in a forked child depending on
87 the request data. This can be implemented by using a synchronous
88 server and doing an explicit fork in the request handler class
89 handle() method.
90
91 Another approach to handling multiple simultaneous requests in an
92 environment that supports neither threads nor fork (or where these are
93 too expensive or inappropriate for the service) is to maintain an
94 explicit table of partially finished requests and to use select() to
95 decide which request to work on next (or whether to handle a new
96 incoming request). This is particularly important for stream services
97 where each client can potentially be connected for a long time (if
98 threads or subprocesses cannot be used).
99
100 Future work:
101 - Standard classes for Sun RPC (which uses either UDP or TCP)
102 - Standard mix-in classes to implement various authentication
103 and encryption schemes
104 - Standard framework for select-based multiplexing
105
106 XXX Open problems:
107 - What to do with out-of-band data?
108
109 BaseServer:
110 - split generic "request" functionality out into BaseServer class.
111 Copyright (C) 2000 Luke Kenneth Casson Leighton <lkcl@samba.org>
112
113 example: read entries from a SQL database (requires overriding
114 get_request() to return a table entry from the database).
115 entry is processed by a RequestHandlerClass.
116
117 """
118
119 # Author of the BaseServer patch: Luke Kenneth Casson Leighton
120
121 # XXX Warning!
122 # There is a test suite for this module, but it cannot be run by the
123 # standard regression test.
124 # To run it manually, run Lib/test/test_socketserver.py.
125
126 __version__ = "0.4"
127
128
129 import socket
130 import select
131 import sys
132 import os
133 import errno
134 try:
135 import threading
136 except ImportError:
137 import dummy_threading as threading
138
139 __all__ = ["TCPServer","UDPServer","ForkingUDPServer","ForkingTCPServer",
140 "ThreadingUDPServer","ThreadingTCPServer","BaseRequestHandler",
141 "StreamRequestHandler","DatagramRequestHandler",
142 "ThreadingMixIn", "ForkingMixIn"]
143 if hasattr(socket, "AF_UNIX"):
144 __all__.extend(["UnixStreamServer","UnixDatagramServer",
145 "ThreadingUnixStreamServer",
146 "ThreadingUnixDatagramServer"])
147
148 def _eintr_retry(func, *args):
149 """restart a system call interrupted by EINTR"""
150 while True:
151 try:
152 return func(*args)
153 except (OSError, select.error) as e:
154 if e.args[0] != errno.EINTR:
155 raise
156
157 class BaseServer:
158
159 """Base class for server classes.
160
161 Methods for the caller:
162
163 - __init__(server_address, RequestHandlerClass)
164 - serve_forever(poll_interval=0.5)
165 - shutdown()
166 - handle_request() # if you do not use serve_forever()
167 - fileno() -> int # for select()
168
169 Methods that may be overridden:
170
171 - server_bind()
172 - server_activate()
173 - get_request() -> request, client_address
174 - handle_timeout()
175 - verify_request(request, client_address)
176 - server_close()
177 - process_request(request, client_address)
178 - shutdown_request(request)
179 - close_request(request)
180 - handle_error()
181
182 Methods for derived classes:
183
184 - finish_request(request, client_address)
185
186 Class variables that may be overridden by derived classes or
187 instances:
188
189 - timeout
190 - address_family
191 - socket_type
192 - allow_reuse_address
193
194 Instance variables:
195
196 - RequestHandlerClass
197 - socket
198
199 """
200
201 timeout = None
202
203 def __init__(self, server_address, RequestHandlerClass): 实例参数最终传递到这里(ip与端口,自定义类)
204 """Constructor. May be extended, do not override."""
205 self.server_address = server_address
206 self.RequestHandlerClass = RequestHandlerClass
207 self.__is_shut_down = threading.Event()
208 self.__shutdown_request = False
209
210 def server_activate(self):
211 """Called by constructor to activate the server.
212
213 May be overridden.
214
215 """
216 pass
217
218 def serve_forever(self, poll_interval=0.5):
219 """Handle one request at a time until shutdown.
220
221 Polls for shutdown every poll_interval seconds. Ignores
222 self.timeout. If you need to do periodic tasks, do them in
223 another thread.
224 """
225 self.__is_shut_down.clear()
226 try:
227 while not self.__shutdown_request:
228 # XXX: Consider using another file descriptor or
229 # connecting to the socket to wake this up instead of
230 # polling. Polling reduces our responsiveness to a
231 # shutdown request and wastes cpu at all other times.
232 r, w, e = _eintr_retry(select.select, [self], [], [],
233 poll_interval)
234 if self in r:
235 self._handle_request_noblock()
236 finally:
237 self.__shutdown_request = False
238 self.__is_shut_down.set()
239
240 def shutdown(self):
241 """Stops the serve_forever loop.
242
243 Blocks until the loop has finished. This must be called while
244 serve_forever() is running in another thread, or it will
245 deadlock.
246 """
247 self.__shutdown_request = True
248 self.__is_shut_down.wait()
249
250 # The distinction between handling, getting, processing and
251 # finishing a request is fairly arbitrary. Remember:
252 #
253 # - handle_request() is the top-level call. It calls
254 # select, get_request(), verify_request() and process_request()
255 # - get_request() is different for stream or datagram sockets
256 # - process_request() is the place that may fork a new process
257 # or create a new thread to finish the request
258 # - finish_request() instantiates the request handler class;
259 # this constructor will handle the request all by itself
260
261 def handle_request(self):
262 """Handle one request, possibly blocking.
263
264 Respects self.timeout.
265 """
266 # Support people who used socket.settimeout() to escape
267 # handle_request before self.timeout was available.
268 timeout = self.socket.gettimeout()
269 if timeout is None:
270 timeout = self.timeout
271 elif self.timeout is not None:
272 timeout = min(timeout, self.timeout)
273 fd_sets = _eintr_retry(select.select, [self], [], [], timeout) #调用select模块实现了多线程
274 if not fd_sets[0]:
275 self.handle_timeout()
276 return
277 self._handle_request_noblock()
278
279 def _handle_request_noblock(self):
280 """Handle one request, without blocking.
281
282 I assume that select.select has returned that the socket is
283 readable before this function was called, so there should be
284 no risk of blocking in get_request().
285 """
286 try:
287 request, client_address = self.get_request()
288 except socket.error:
289 return
290 if self.verify_request(request, client_address):
291 try:
292 self.process_request(request, client_address)
293 except:
294 self.handle_error(request, client_address)
295 self.shutdown_request(request)
296
297 def handle_timeout(self):
298 """Called if no new request arrives within self.timeout.
299
300 Overridden by ForkingMixIn.
301 """
302 pass
303
304 def verify_request(self, request, client_address):
305 """Verify the request. May be overridden.
306
307 Return True if we should proceed with this request.
308
309 """
310 return True
311
312 def process_request(self, request, client_address):
313 """Call finish_request.
314
315 Overridden by ForkingMixIn and ThreadingMixIn.
316
317 """
318 self.finish_request(request, client_address)
319 self.shutdown_request(request)
320
321 def server_close(self):
322 """Called to clean-up the server.
323
324 May be overridden.
325
326 """
327 pass
328
329 def finish_request(self, request, client_address):
330 """Finish one request by instantiating RequestHandlerClass."""
331 self.RequestHandlerClass(request, client_address, self)
332
333 def shutdown_request(self, request):
334 """Called to shutdown and close an individual request."""
335 self.close_request(request)
336
337 def close_request(self, request):
338 """Called to clean up an individual request."""
339 pass
340
341 def handle_error(self, request, client_address):
342 """Handle an error gracefully. May be overridden.
343
344 The default is to print a traceback and continue.
345
346 """
347 print '-'*40
348 print 'Exception happened during processing of request from',
349 print client_address
350 import traceback
351 traceback.print_exc() # XXX But this goes to stderr!
352 print '-'*40
353
354
355 class TCPServer(BaseServer): ThreadingTCPServer基类之一,它又有自己的基类BaseServer """Base class for various socket-based server classes.
356
357 Defaults to synchronous IP stream (i.e., TCP).
358
359 Methods for the caller:
360
361 - __init__(server_address, RequestHandlerClass, bind_and_activate=True)
362 - serve_forever(poll_interval=0.5)
363 - shutdown()
364 - handle_request() # if you don't use serve_forever()
365 - fileno() -> int # for select()
366
367 Methods that may be overridden:
368
369 - server_bind()
370 - server_activate()
371 - get_request() -> request, client_address
372 - handle_timeout()
373 - verify_request(request, client_address)
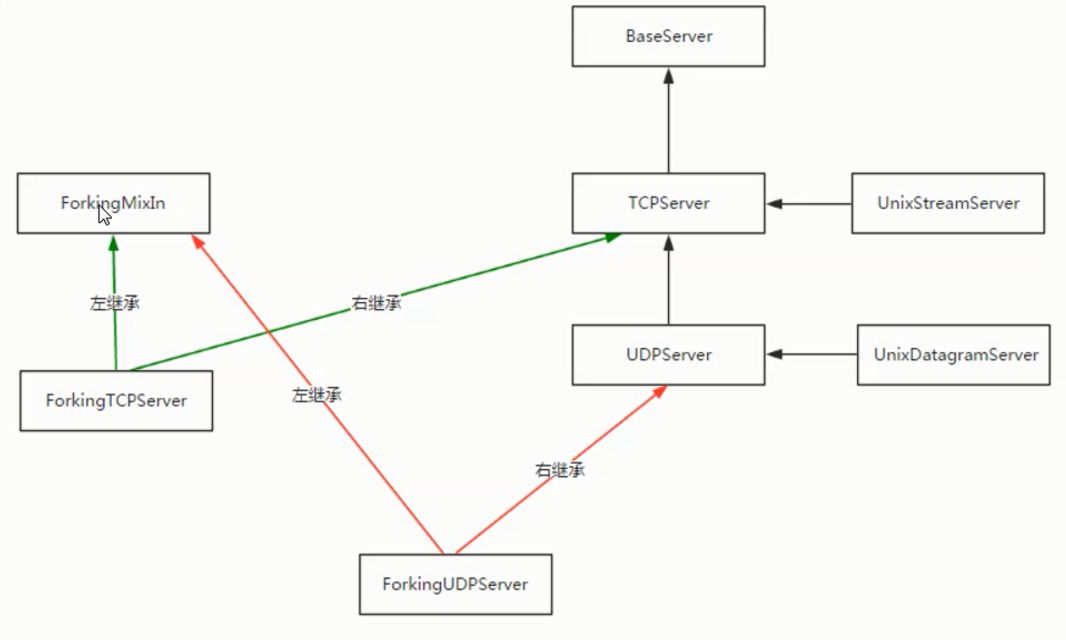
374 - process_request(request, client_address)
375 - shutdown_request(request)
376 - close_request(request)
377 - handle_error()
378
379 Methods for derived classes:
380
381 - finish_request(request, client_address)
382
383 Class variables that may be overridden by derived classes or
384 instances:
385
386 - timeout
387 - address_family
388 - socket_type
389 - request_queue_size (only for stream sockets)
390 - allow_reuse_address
391
392 Instance variables:
393
394 - server_address
395 - RequestHandlerClass
396 - socket
397
398 """
399
400 address_family = socket.AF_INET
401
402 socket_type = socket.SOCK_STREAM
403
404 request_queue_size = 5
405
406 allow_reuse_address = False
407
408 def __init__(self, server_address, RequestHandlerClass, bind_and_activate=True):
409 """Constructor. May be extended, do not override."""
410 BaseServer.__init__(self, server_address, RequestHandlerClass) 调用它自己基类函数BaseServer的初始化函数进行多线程的启动
411 self.socket = socket.socket(self.address_family,self.socket_type) 创建启动的独立线程socket
412 if bind_and_activate:
413 try:
414 self.server_bind()
415 self.server_activate()
416 except:
417 self.server_close()
418 raise
419
420 def server_bind(self):
421 """Called by constructor to bind the socket.
422
423 May be overridden.
424
425 """
426 if self.allow_reuse_address:
427 self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
428 self.socket.bind(self.server_address) 绑定地址
429 self.server_address = self.socket.getsockname()
430 def server_activate(self):
431 """
432 Called by constructor to activate the server. May be overridden.可以被重构
433 """
434 self.socket.listen(self.request_queue_size) 端口检听
435
436 def server_close(self):
437 """Called to clean-up the server.
438 May be overridden.
439 """
440 self.socket.close() 关闭socket
441
442 def fileno(self):
443 """Return socket file number.
444
445 Interface required by select().
446
447 """
448 return self.socket.fileno()
449
450 def get_request(self):
451 """Get the request and client address from the socket.
452 May be overridden.
453 """
454 return self.socket.accept()
455
456 def shutdown_request(self, request):
457 """Called to shutdown and close an individual request."""
458 try:
459 #explicitly shutdown. socket.close() merely releases
460 #the socket and waits for GC to perform the actual close.
461 request.shutdown(socket.SHUT_WR)
462 except socket.error:
463 pass #some platforms may raise ENOTCONN here
464 self.close_request(request)
465
466 def close_request(self, request):
467 """Called to clean up an individual request."""
468 request.close()
469
470
471 class UDPServer(TCPServer):
472
473 """UDP server class."""
474
475 allow_reuse_address = False
476
477 socket_type = socket.SOCK_DGRAM
478
479 max_packet_size = 8192
480
481 def get_request(self):
482 data, client_addr = self.socket.recvfrom(self.max_packet_size)
483 return (data, self.socket), client_addr
484
485 def server_activate(self):
486 # No need to call listen() for UDP.
487 pass
488
489 def shutdown_request(self, request):
490 # No need to shutdown anything.
491 self.close_request(request)
492
493 def close_request(self, request):
494 # No need to close anything.
495 pass
496
497 class ForkingMixIn:
498
499 """Mix-in class to handle each request in a new process."""
500
501 timeout = 300
502 active_children = None
503 max_children = 40
504
505 def collect_children(self):
506 """Internal routine to wait for children that have exited."""
507 if self.active_children is None:
508 return
509
510 # If we're above the max number of children, wait and reap them until
511 # we go back below threshold. Note that we use waitpid(-1) below to be
512 # able to collect children in size(<defunct children>) syscalls instead
513 # of size(<children>): the downside is that this might reap children
514 # which we didn't spawn, which is why we only resort to this when we're
515 # above max_children.
516 while len(self.active_children) >= self.max_children:
517 try:
518 pid, _ = os.waitpid(-1, 0)
519 self.active_children.discard(pid)
520 except OSError as e:
521 if e.errno == errno.ECHILD:
522 # we don't have any children, we're done
523 self.active_children.clear()
524 elif e.errno != errno.EINTR:
525 break
526
527 # Now reap all defunct children.
528 for pid in self.active_children.copy():
529 try:
530 pid, _ = os.waitpid(pid, os.WNOHANG)
531 # if the child hasn't exited yet, pid will be 0 and ignored by
532 # discard() below
533 self.active_children.discard(pid)
534 except OSError as e:
535 if e.errno == errno.ECHILD:
536 # someone else reaped it
537 self.active_children.discard(pid)
538
539 def handle_timeout(self):
540 """Wait for zombies after self.timeout seconds of inactivity.
541
542 May be extended, do not override.
543 """
544 self.collect_children()
545
546 def process_request(self, request, client_address):
547 """Fork a new subprocess to process the request."""
548 self.collect_children()
549 pid = os.fork()
550 if pid:
551 # Parent process
552 if self.active_children is None:
553 self.active_children = set()
554 self.active_children.add(pid)
555 self.close_request(request) #close handle in parent process
556 return
557 else:
558 # Child process.
559 # This must never return, hence os._exit()!
560 try:
561 self.finish_request(request, client_address)
562 self.shutdown_request(request)
563 os._exit(0)
564 except:
565 try:
566 self.handle_error(request, client_address)
567 self.shutdown_request(request)
568 finally:
569 os._exit(1)
570
571
572 class ThreadingMixIn: 基类2
573 """Mix-in class to handle each request in a new thread."""
574
575 # Decides how threads will act upon termination of the
576 # main process
577 daemon_threads = False
578
579 def process_request_thread(self, request, client_address):
580 """Same as in BaseServer but as a thread.
581
582 In addition, exception handling is done here.
583
584 """
585 try:
586 self.finish_request(request, client_address)
587 self.shutdown_request(request)
588 except:
589 self.handle_error(request, client_address)
590 self.shutdown_request(request)
591
592 def process_request(self, request, client_address):
593 """Start a new thread to process the request."""
594 t = threading.Thread(target = self.process_request_thread,
595 args = (request, client_address))
596 t.daemon = self.daemon_threads
597 t.start()
598
599
600 class ForkingUDPServer(ForkingMixIn, UDPServer): pass
601 class ForkingTCPServer(ForkingMixIn, TCPServer): pass
602
603 class ThreadingUDPServer(ThreadingMixIn, UDPServer): pass
604 class ThreadingTCPServer(ThreadingMixIn, TCPServer): pass
605
606 if hasattr(socket, 'AF_UNIX'):
607
608 class UnixStreamServer(TCPServer):
609 address_family = socket.AF_UNIX
610
611 class UnixDatagramServer(UDPServer):
612 address_family = socket.AF_UNIX
613
614 class ThreadingUnixStreamServer(ThreadingMixIn, UnixStreamServer): pass
615
616 class ThreadingUnixDatagramServer(ThreadingMixIn, UnixDatagramServer): pass
617
618 class BaseRequestHandler:
619 自定义MyServer自继承这里,主要用于处理来自每个线程的请求,函数拥有三个方法,但是每个方法的结构体都没pass,所以我们在继承以后需要对方法进行重构。
620 """Base class for request handler classes.
621
622 This class is instantiated for each request to be handled. The
623 constructor sets the instance variables request, client_address
624 and server, and then calls the handle() method. To implement a
625 specific service, all you need to do is to derive a class which
626 defines a handle() method.
627
628 The handle() method can find the request as self.request, the
629 client address as self.client_address, and the server (in case it
630 needs access to per-server information) as self.server. Since a
631 separate instance is created for each request, the handle() method
632 can define arbitrary other instance variariables.
633 """
634
635 def __init__(self, request, client_address, server): 接收请求request,客户端地址client_address,自定义server
636 self.request = request 分别赋值
637 self.client_address = client_address
638 self.server = server
639 self.setup() 首先执行setup()函数
640 try:
641 self.handle() 再执行handle()
642 finally:
643 self.finish() 最后执行finish()
644
645 def setup(self): 三个函数结构体都为pass ,需要在继承时进行方法重构
646 pass
647
648 def handle(self):
649 pass
650
651 def finish(self):
652 pass
653
654
655 # The following two classes make it possible to use the same service
656 # class for stream or datagram servers.
657 # Each class sets up these instance variables:
658 # - rfile: a file object from which receives the request is read
659 # - wfile: a file object to which the reply is written
660 # When the handle() method returns, wfile is flushed properly
661
662
663 class StreamRequestHandler(BaseRequestHandler):
664
665 """Define self.rfile and self.wfile for stream sockets."""
666
667 # Default buffer sizes for rfile, wfile.
668 # We default rfile to buffered because otherwise it could be
669 # really slow for large data (a getc() call per byte); we make
670 # wfile unbuffered because (a) often after a write() we want to
671 # read and we need to flush the line; (b) big writes to unbuffered
672 # files are typically optimized by stdio even when big reads
673 # aren't.
674 rbufsize = -1
675 wbufsize = 0
676
677 # A timeout to apply to the request socket, if not None.
678 timeout = None
679
680 # Disable nagle algorithm for this socket, if True.
681 # Use only when wbufsize != 0, to avoid small packets.
682 disable_nagle_algorithm = False
683
684 def setup(self):
685 self.connection = self.request
686 if self.timeout is not None:
687 self.connection.settimeout(self.timeout)
688 if self.disable_nagle_algorithm:
689 self.connection.setsockopt(socket.IPPROTO_TCP,
690 socket.TCP_NODELAY, True)
691 self.rfile = self.connection.makefile('rb', self.rbufsize)
692 self.wfile = self.connection.makefile('wb', self.wbufsize)
693
694 def finish(self):
695 if not self.wfile.closed:
696 try:
697 self.wfile.flush()
698 except socket.error:
699 # An final socket error may have occurred here, such as
700 # the local error ECONNABORTED.
701 pass
702 self.wfile.close()
703 self.rfile.close()
704
705
706 class DatagramRequestHandler(BaseRequestHandler):
707
708 # XXX Regrettably, I cannot get this working on Linux;
709 # s.recvfrom() doesn't return a meaningful client address.
710
711 """Define self.rfile and self.wfile for datagram sockets."""
712
713 def setup(self):
714 try:
715 from cStringIO import StringIO
716 except ImportError:
717 from StringIO import StringIO
718 self.packet, self.socket = self.request
719 self.rfile = StringIO(self.packet)
720 self.wfile = StringIO()
721
722 def finish(self):
723 self.socket.sendto(self.wfile.getvalue(), self.client_address)
服务器类型
5种类型:BaseServer,TCPServer,UnixStreamServer,UDPServer,UnixDatagramServer。 注意:BaseServer不直接对外服务。
服务器对象
-
class SocketServer.BaseServer:这是模块中的所有服务器对象的超类。它定义了接口,如下所述,但是大多数的方法不实现,在子类中进行细化。
-
BaseServer.fileno():返回服务器监听套接字的整数文件描述符。通常用来传递给select.select(), 以允许一个进程监视多个服务器。
-
BaseServer.handle_request():处理单个请求。处理顺序:get_request(), verify_request(), process_request()。如果用户提供handle()方法抛出异常,将调用服务器的handle_error()方法。如果self.timeout内没有请求收到, 将调用handle_timeout()并返回handle_request()。
-
BaseServer.serve_forever(poll_interval=0.5): 处理请求,直到一个明确的shutdown()请求。每poll_interval秒轮询一次shutdown。忽略self.timeout。如果你需要做周期性的任务,建议放置在其他线程。
-
BaseServer.shutdown():告诉serve_forever()循环停止并等待其停止。python2.6版本。
-
BaseServer.address_family: 地址家族,比如socket.AF_INET和socket.AF_UNIX。
-
BaseServer.RequestHandlerClass:用户提供的请求处理类,这个类为每个请求创建实例。
-
BaseServer.server_address:服务器侦听的地址。格式根据协议家族地址的各不相同,请参阅socket模块的文档。
-
BaseServer.socketSocket:服务器上侦听传入的请求socket对象的服务器。
服务器类支持下面的类变量:
-
BaseServer.allow_reuse_address:服务器是否允许地址的重用。默认为false ,并且可在子类中更改。
-
BaseServer.request_queue_size
请求队列的大小。如果单个请求需要很长的时间来处理,服务器忙时请求被放置到队列中,最多可以放request_queue_size个。一旦队列已满,来自客户端的请求将得到 “Connection denied”错误。默认值通常为5 ,但可以被子类覆盖。
-
BaseServer.socket_type:服务器使用的套接字类型; socket.SOCK_STREAM和socket.SOCK_DGRAM等。
-
BaseServer.timeout:超时时间,以秒为单位,或 None表示没有超时。如果handle_request()在timeout内没有收到请求,将调用handle_timeout()。
下面方法可以被子类重载,它们对服务器对象的外部用户没有影响。
-
BaseServer.finish_request():实际处理RequestHandlerClass发起的请求并调用其handle()方法。 常用。
-
BaseServer.get_request():接受socket请求,并返回二元组包含要用于与客户端通信的新socket对象,以及客户端的地址。
-
BaseServer.handle_error(request, client_address):如果RequestHandlerClass的handle()方法抛出异常时调用。默认操作是打印traceback到标准输出,并继续处理其他请求。
-
BaseServer.handle_timeout():超时处理。默认对于forking服务器是收集退出的子进程状态,threading服务器则什么都不做。
-
BaseServer.process_request(request, client_address) :调用finish_request()创建RequestHandlerClass的实例。如果需要,此功能可以创建新的进程或线程来处理请求,ForkingMixIn和ThreadingMixIn类做到这点。常用。
-
BaseServer.server_activate():通过服务器的构造函数来激活服务器。默认的行为只是监听服务器套接字。可重载。
-
BaseServer.server_bind():通过服务器的构造函数中调用绑定socket到所需的地址。可重载。
-
BaseServer.verify_request(request, client_address):返回一个布尔值,如果该值为True ,则该请求将被处理,反之请求将被拒绝。此功能可以重写来实现对服务器的访问控制。默认的实现始终返回True。client_address可以限定客户端,比如只处理指定ip区间的请求。 常用。
请求处理器
处理器接收数据并决定如何操作。它负责在socket层之上实现协议(i.e., HTTP, XML-RPC, or AMQP),读取数据,处理并写反应。可以重载的方法如下:
-
setup(): 准备请求处理. 默认什么都不做,StreamRequestHandler中会创建文件类似的对象以读写socket.
-
handle(): 处理请求。解析传入的请求,处理数据,并发送响应。默认什么都不做。常用变量:self.request,self.client_address,self.server。
-
finish(): 环境清理。默认什么都不做,如果setup产生异常,不会执行finish。
通常只需要重载handle。self.request的类型和数据报或流的服务不同。对于流服务,self.request是socket 对象;对于数据报服务,self.request是字符串和socket 。可以在子类StreamRequestHandler或DatagramRequestHandler中重载,重写setup()和finish() ,并提供self.rfile和self.wfile属性。 self.rfile和self.wfile可以读取或写入,以获得请求数据或将数据返回到客户端。
1 1 1 1

