
【博学谷学习记录】超强总结,用心分享|狂野架构师TiDB
什么是TIDB
TiDB 是一个分布式 NewSQL 数据库,它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景还适合 OLAP 场景的混合数据库。
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案,TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
1 TiDB的优势
与传统的单机数据库相比,TiDB 具有以下优势:
- 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
- 支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
- 支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
2 TiDB的组件
要深入了解 TiDB 的水平扩展和高可用特点,首先需要了解 TiDB 的整体架构。
TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server,此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件。
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:
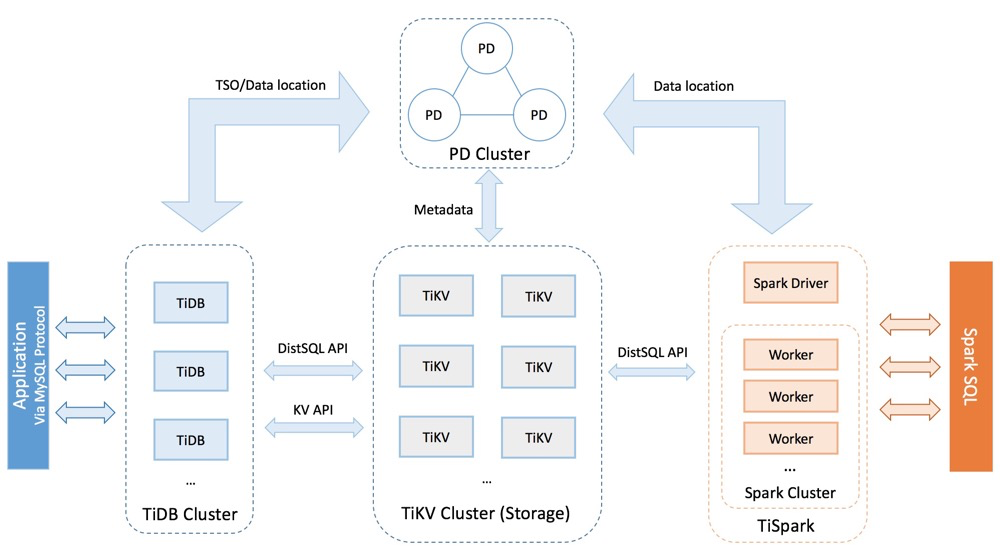
2.1 TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果,TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址。
2.2 PD (Placement Driver) Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:
- 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);
- 二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);
- 三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证数据的安全性,Raft 的 leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用,建议部署奇数个 PD 节点
2.3 TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。
存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
2.4 TiSpark
TiSpark 作为 TiDB 中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB 可以通过一套系统,同时支持 OLTP 与 OLAP,免除用户数据同步的烦恼。
2.5 TiFlash
TiFlash 是一类特殊的存储节点。
和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
3 TiKV整体架构
与传统的整节点备份方式不同的,TiKV是将数据按照 key 的范围划分成大致相等的切片(下文统称为 Region),每一个切片会有多个副本(通常是 3 个),其中一个副本是 Leader,提供读写服务。
TiKV 通过 PD 对这些 Region 以及副本进行调度,以保证数据和读写负载都均匀地分散在各个 TiKV 上,这样的设计保证了整个集群资源的充分利用并且可以随着机器数量的增加水平扩展。
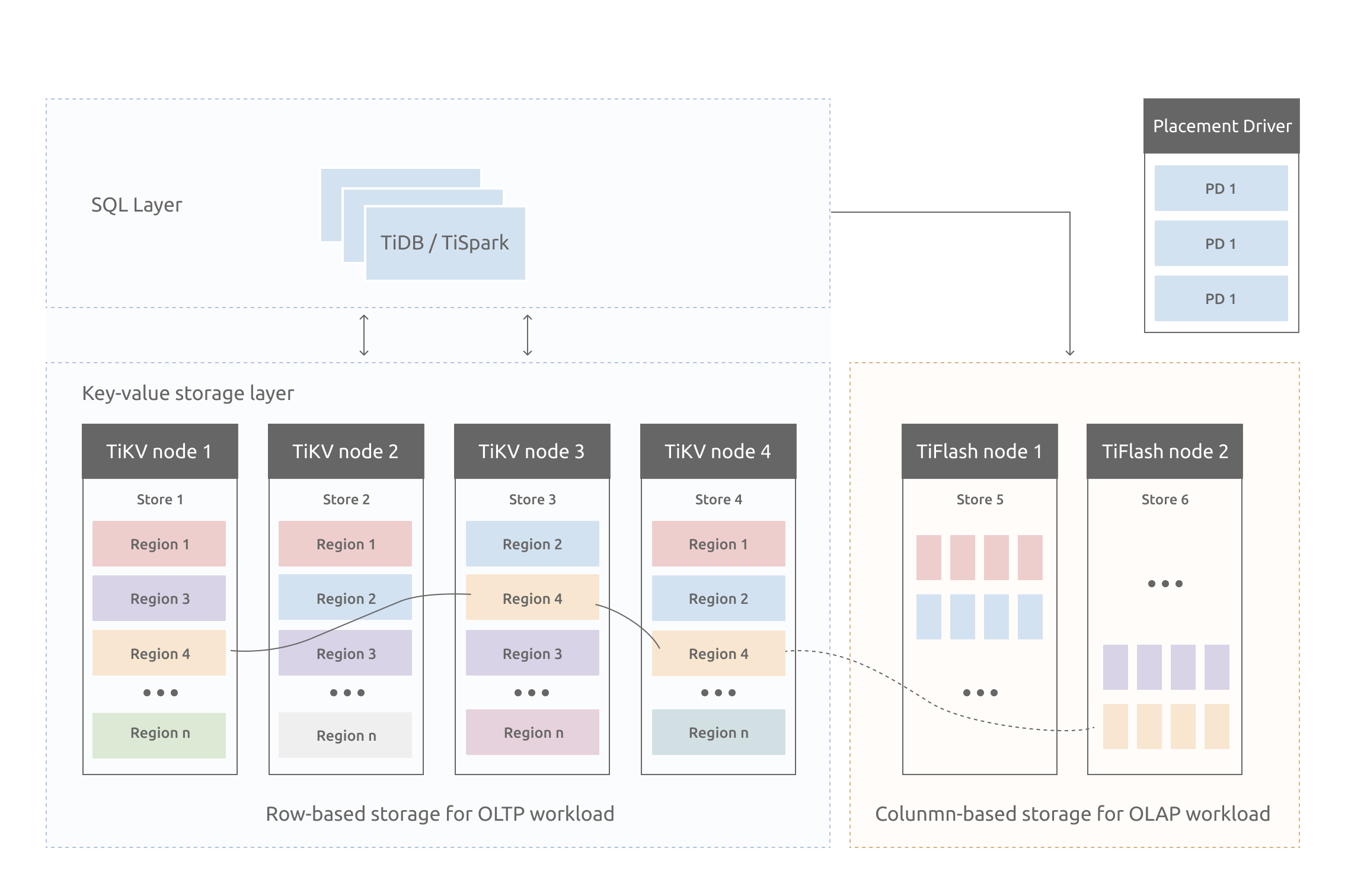
3.1 Region分裂与合并
当某个 Region 的大小超过一定限制(默认是 144MB)后,TiKV 会将它分裂为两个或者更多个 Region,以保证各个 Region 的大小是大致接近的,这样更有利于 PD 进行调度决策,同样,当某个 Region 因为大量的删除请求导致 Region 的大小变得更小时,TiKV 会将比较小的两个相邻 Region 合并为一个。
3.2 Region调度
Region 与副本之间通过 Raft 协议来维持数据一致性,任何写请求都只能在 Leader 上写入,并且需要写入多数副本后(默认配置为 3 副本,即所有请求必须至少写入两个副本成功)才会返回客户端写入成功。
当 PD 需要把某个 Region 的一个副本从一个 TiKV 节点调度到另一个上面时,PD 会先为这个 Raft Group 在目标节点上增加一个 Learner 副本(复制 Leader 的数据),当这个 Learner 副本的进度大致追上 Leader 副本时,Leader 会将它变更为 Follower,之后再移除操作节点的 Follower 副本,这样就完成了 Region 副本的一次调度。
Leader 副本的调度原理也类似,不过需要在目标节点的 Learner 副本变为 Follower 副本后,再执行一次 Leader Transfer,让该 Follower 主动发起一次选举成为新 Leader,之后新 Leader 负责删除旧 Leader 这个副本。
3.3 分布式事务
TiKV 支持分布式事务,用户(或者 TiDB)可以一次性写入多个 key-value 而不必关心这些 key-value 是否处于同一个数据切片 (Region) 上,TiKV 通过两阶段提交保证了这些读写请求的 ACID 约束。
