
图像分类基于cnn的戴口罩和不戴口罩的分类任务-详细教程文档(视频同款)
图像分类基于cnn的戴口罩和不戴口罩的分类任务-详细教程文档(视频同款)
一、环境配置
1、预备知识
如果有不知道【pycharm+anaconda】组合开发环境的,建议先看这个教程视频:
2、软件清单
本教程以【pycharm+anaconda】为组合进行开发(其他开发环境的也行,只要你有环境就行,就算你用【python解释器+记事本】也行——”不管黑猫白猫,能跑就行“)
或自行前往官网进行下载
3、依赖库清单
使用anaconda的pip或conda包管理工具下载即可,网上也有教程(搜:如何使用anaconda下载第三方库???),也可以先不下载,之后用到哪个库再下载也行;
Faker==18.7.0
opencv_contrib_python==4.7.0.72
opencv_python==4.7.0.72
opencv_python_headless==4.6.0.66
Pillow==9.0.1
Requests==2.31.0
torch==1.12.0
torchvision==0.13.0
注:以上仅供参考,版本无需指定,anaconda会自动匹配的;
二、数据采集
使用爬虫对百度图库进行批量采集图片,可指定图片关键字和数量
1、预备知识
-
需要掌握爬虫的基础知识,了解爬虫的整套流程,最低要求入门爬虫即可,建议看下这个教程(本人就是也是从这走出来的,足以学完足以爬你想爬的网页了,特别提醒:涉及国家、政治、色情登敏感网站不要爬,不然警察叔叔找你喝茶了)
-
视频地址:点我:爬取入门教程视频——入门级别最起码看完以下几部分内容:
-
p1-p4:爬虫介绍
-
p5-p8:请求过程解析
-
p9-p13:requests
-
p14-p39:re、bs4、xpath
- p40-p44:常见反爬处理方法
-
建议:最好花点时间把爬虫入门过掉,保证后面爬取百度图库的代码能理解。
2、百度图库爬虫教程
1) 分析百度图库网页
主要是判断网页属于服务器渲染还是客户端渲染,判断完属于什么渲染基本就知道网页数据在什么地方了,如何判断???知道服务器渲染和客户端渲染的区别就清楚怎么判断,一般情况数据在网页源代码里的属于服务器渲染,不在网页源代码的属于客户端渲染,详细分析过程见下:
-
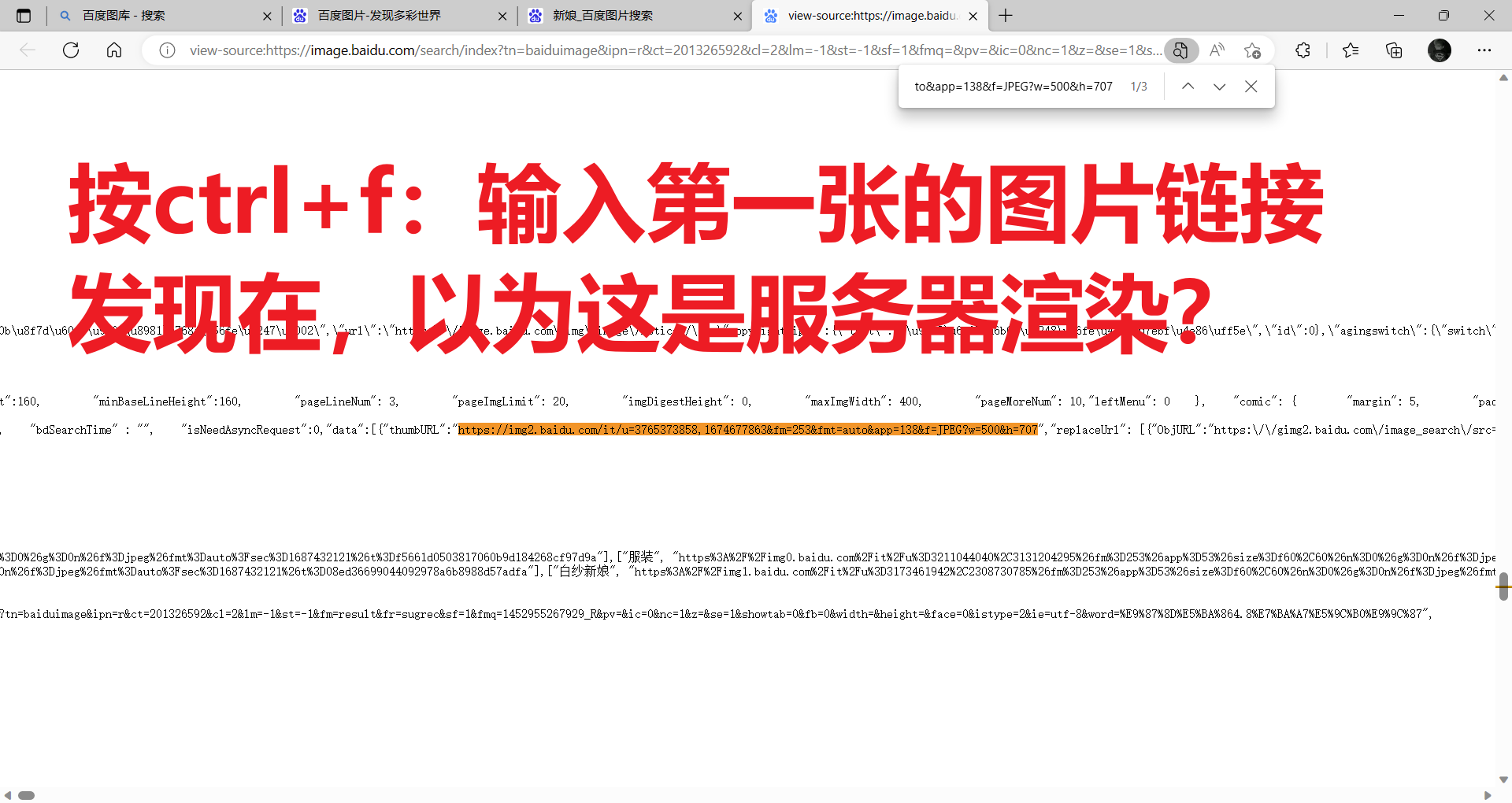
打开百度图库首页,输入关键字,按回车
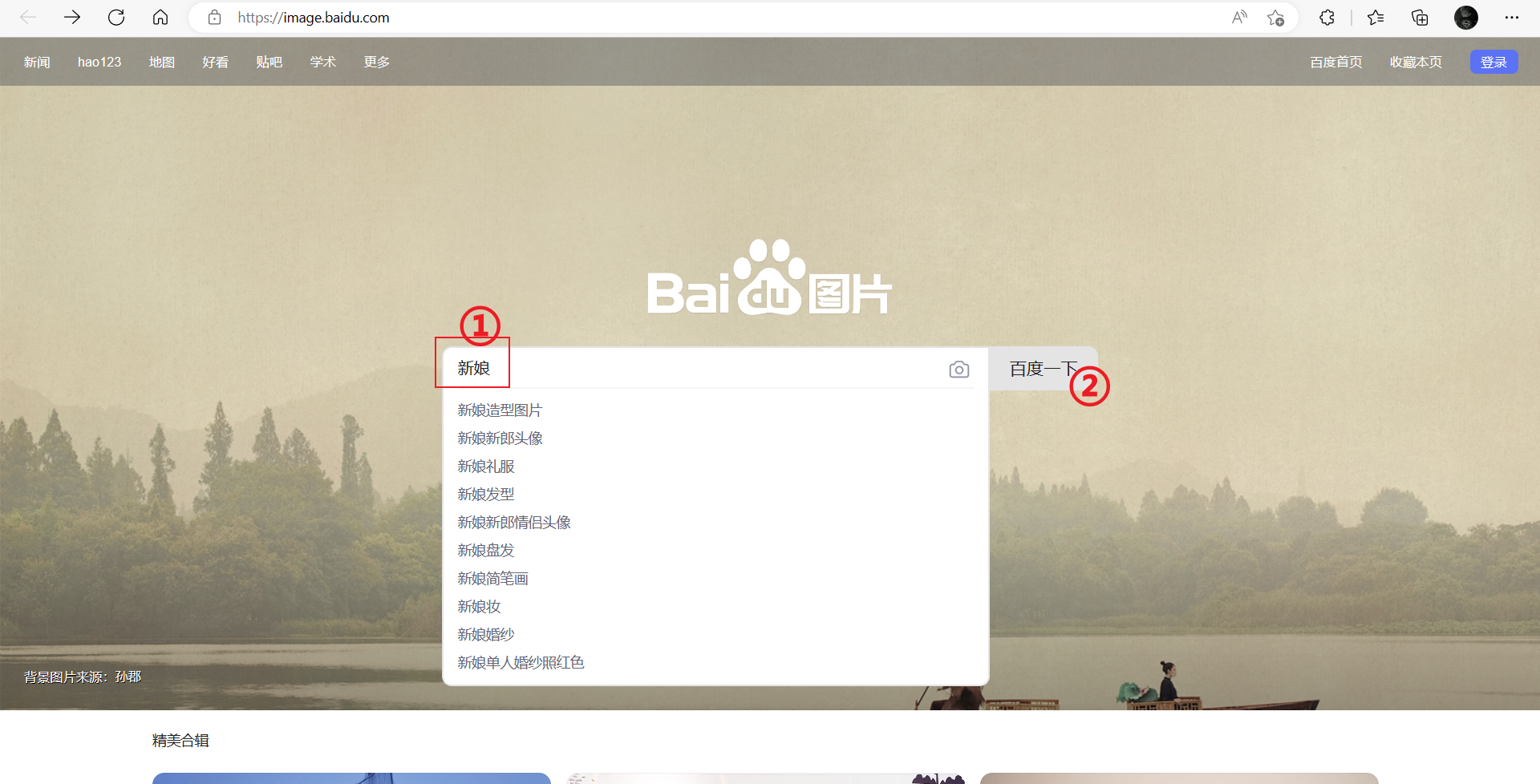
-
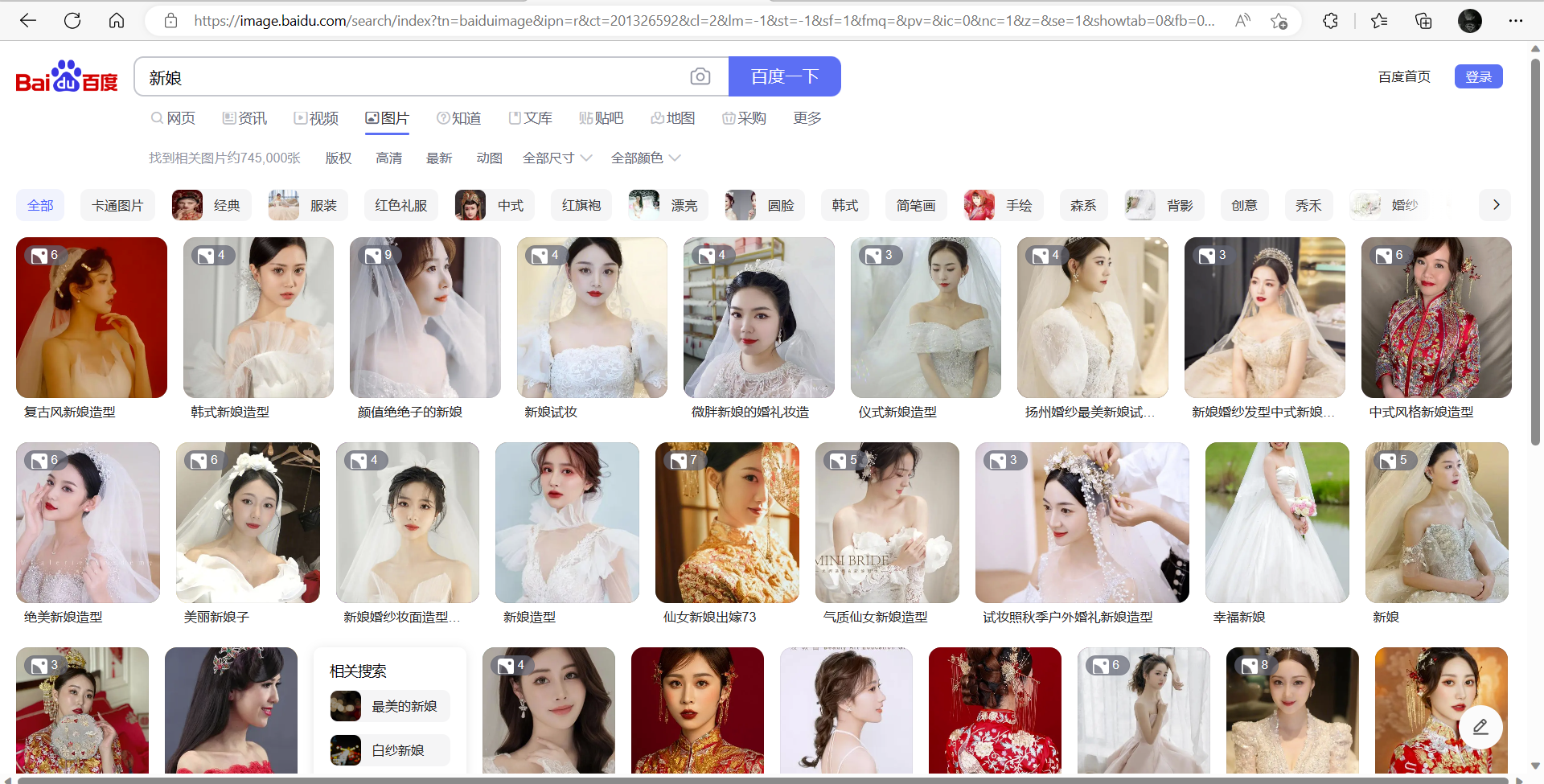
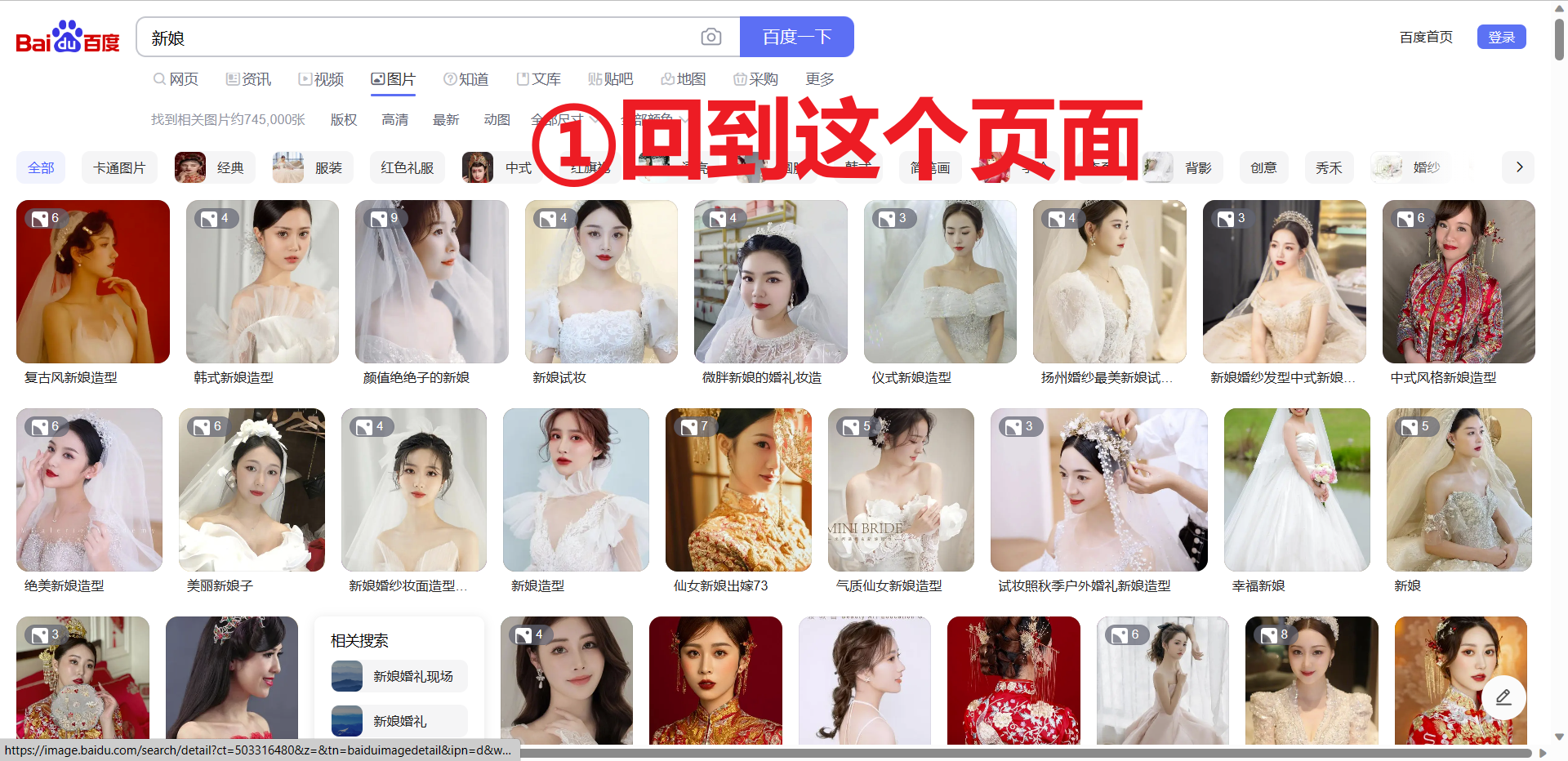
检查是不是属于服务器渲染,提前复制一张图片的链接,再右键【查看网页源代码】,只需要判断图片的链接是不是再网页源代码即可,若不在则属于服务器渲染,反之属于客户端渲染。但是根据经验,这种滚动的不断刷新的页面,一般靠前的图片的链接会出现在网页源代码里,目的就是蛊惑人心,你就以为这是服务器渲染(显然没这么简单,毕竟是百度大厂出品),兴奋的跑去敲代码,敲完只能爬个几张图片。具体分析如下:
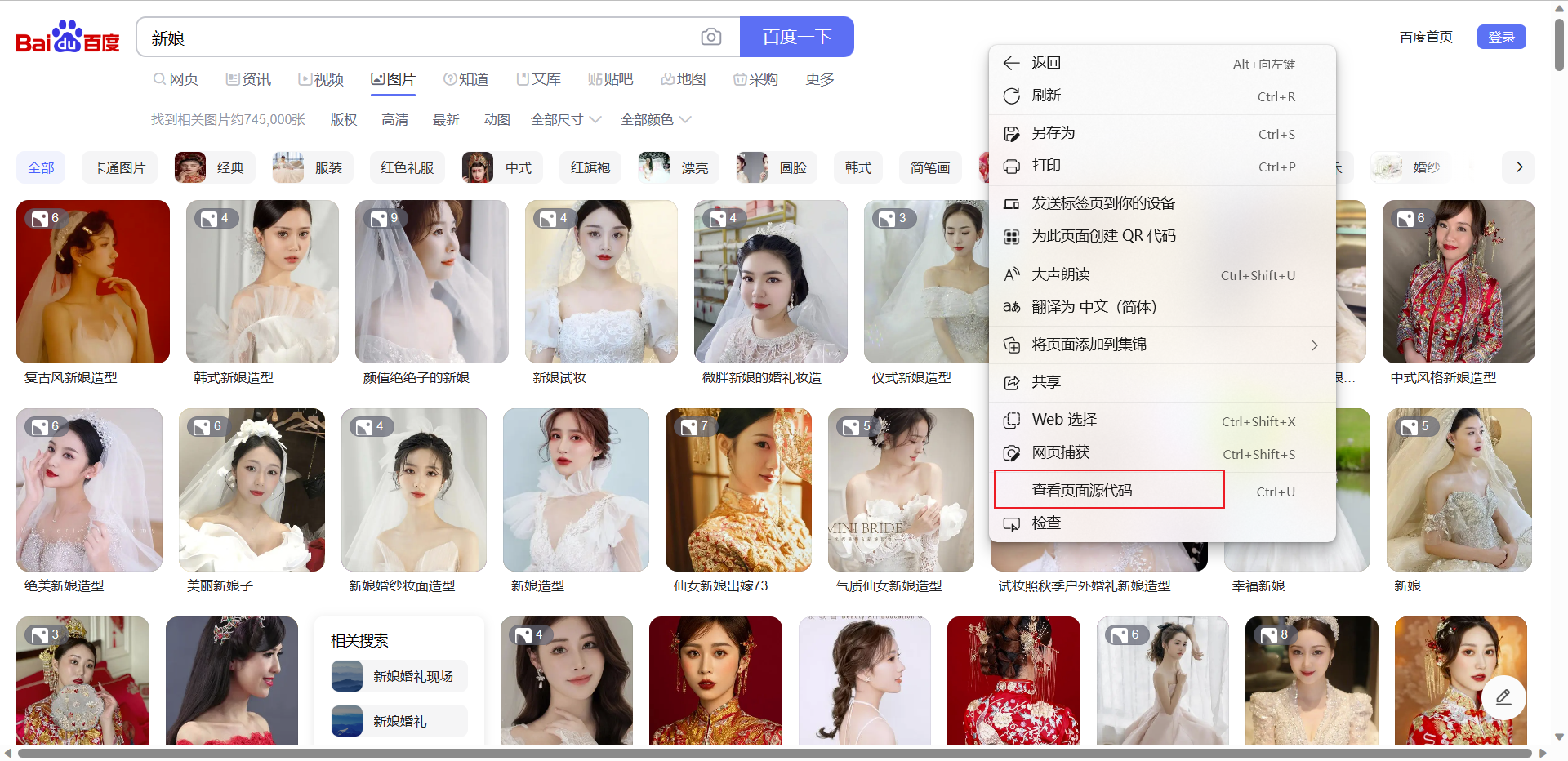
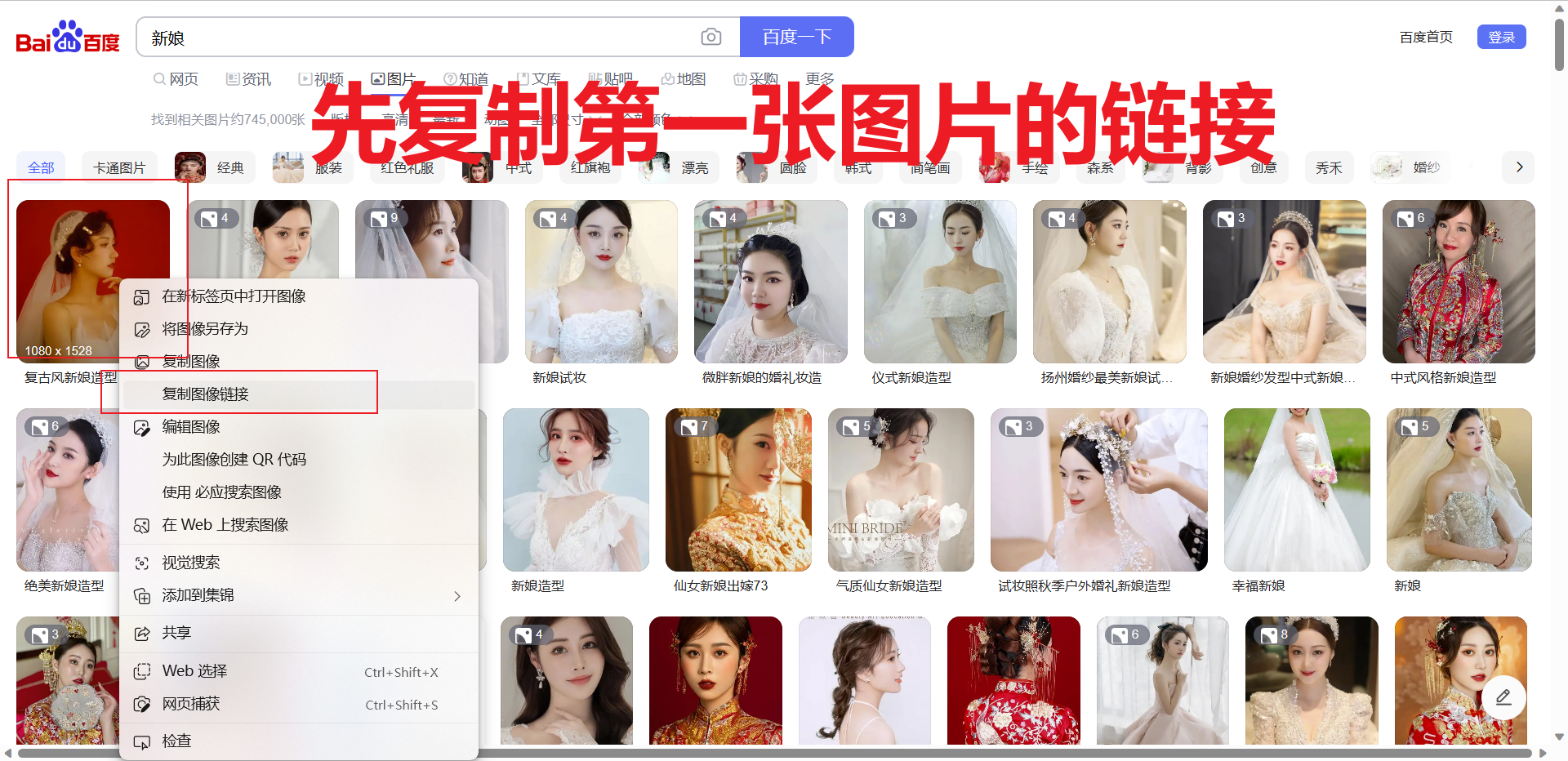
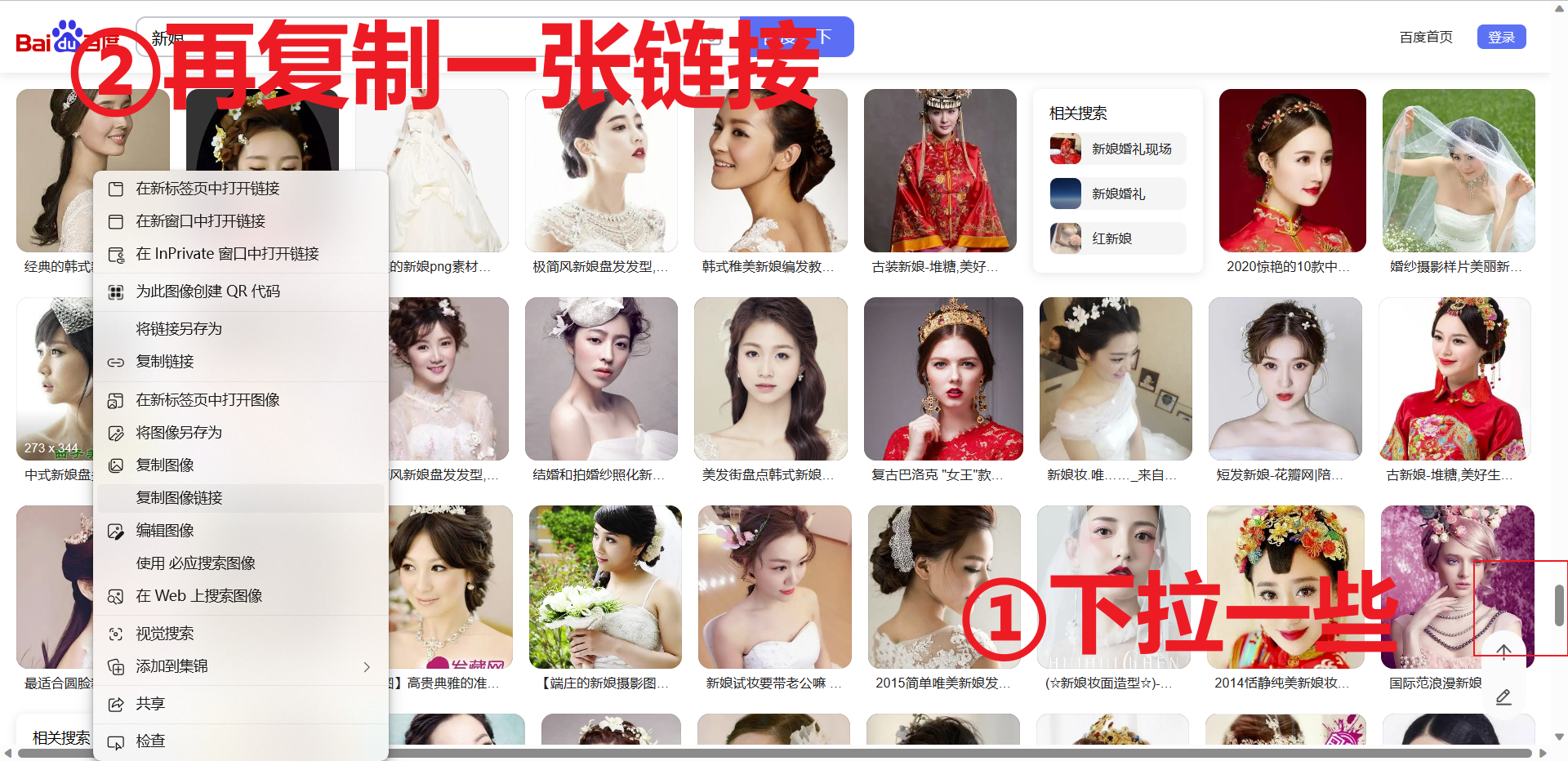
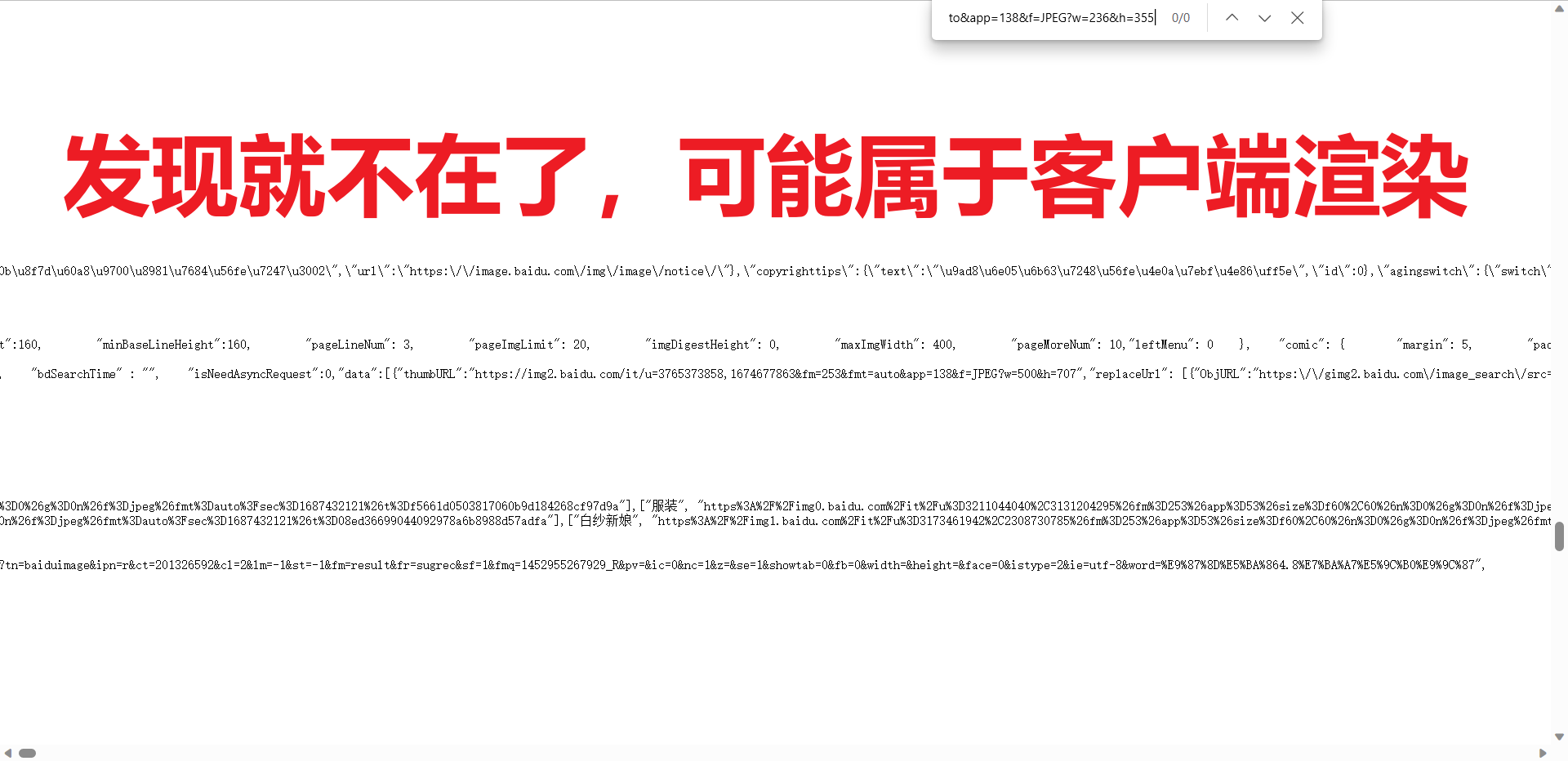
-
为了验证是不是客户端渲染,我们需要借助开发者工具,详细如下:
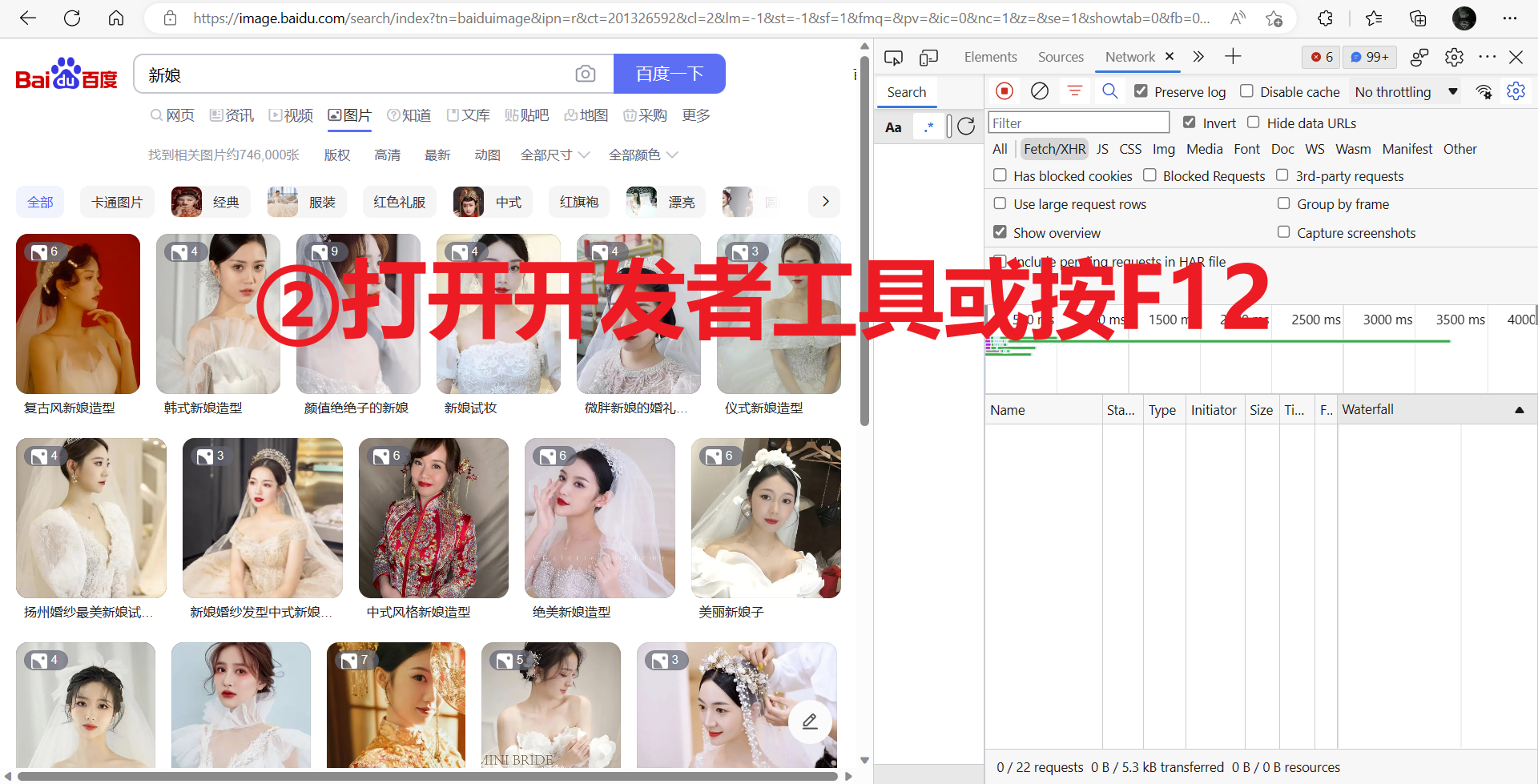
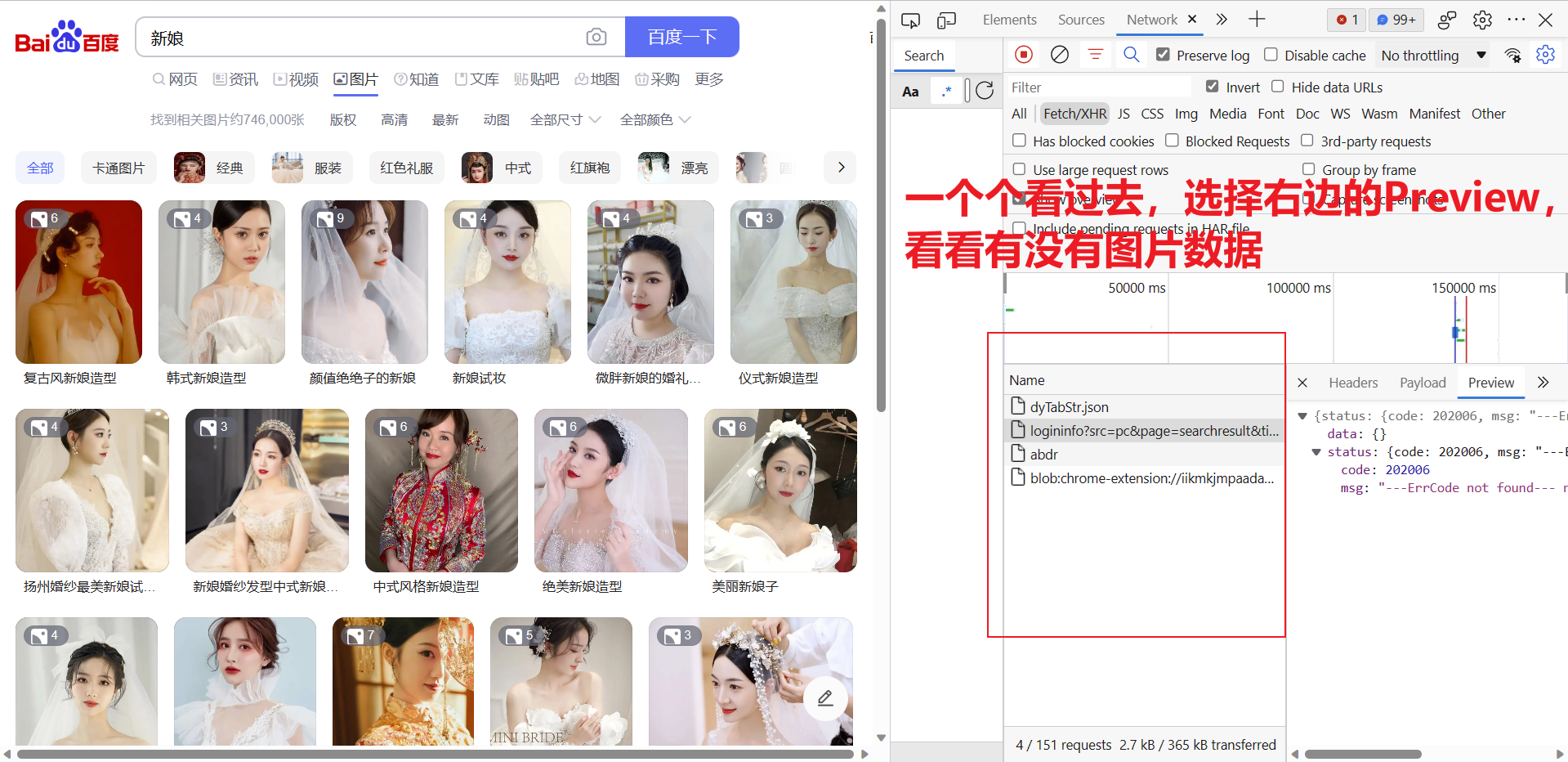
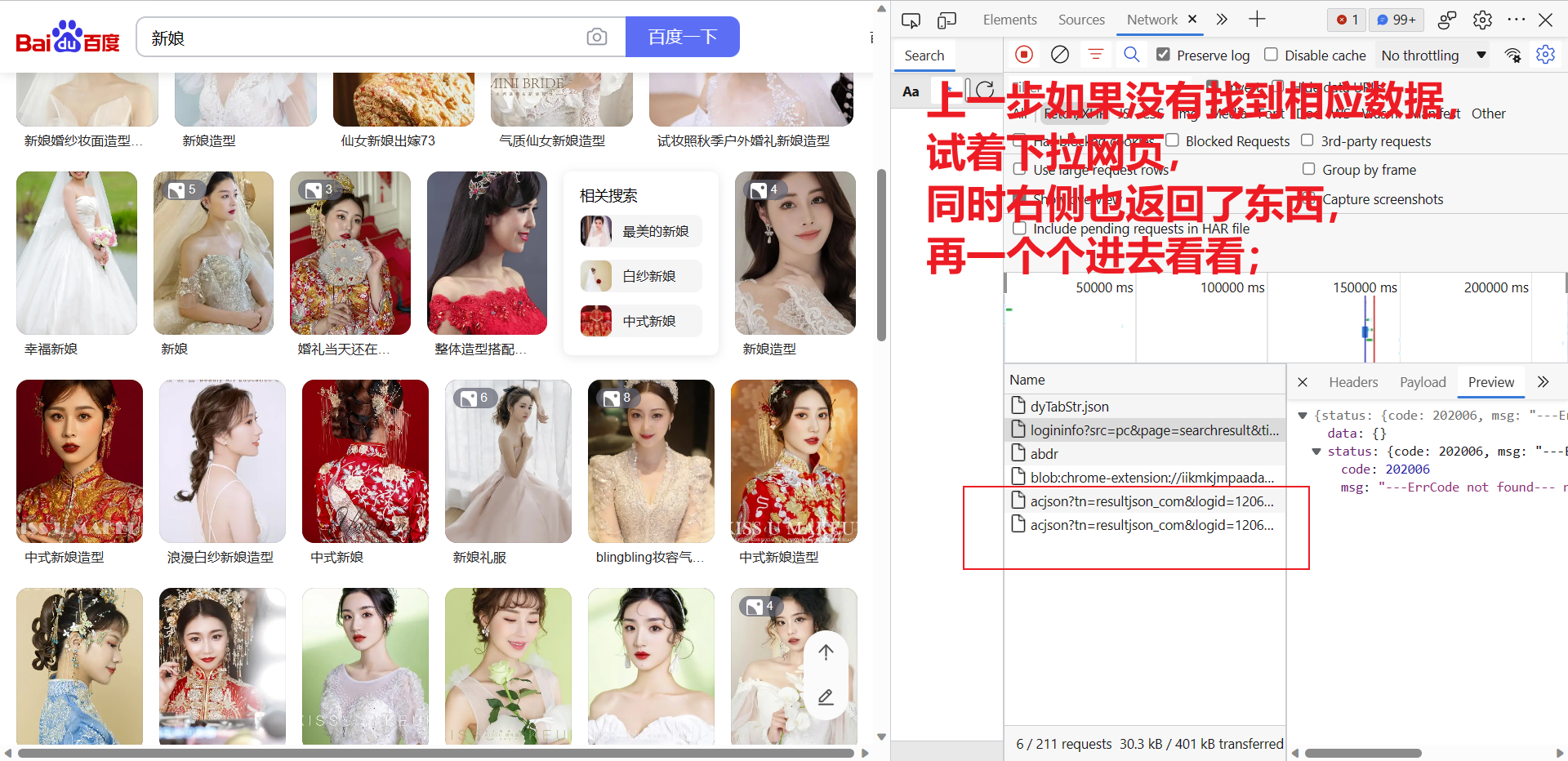
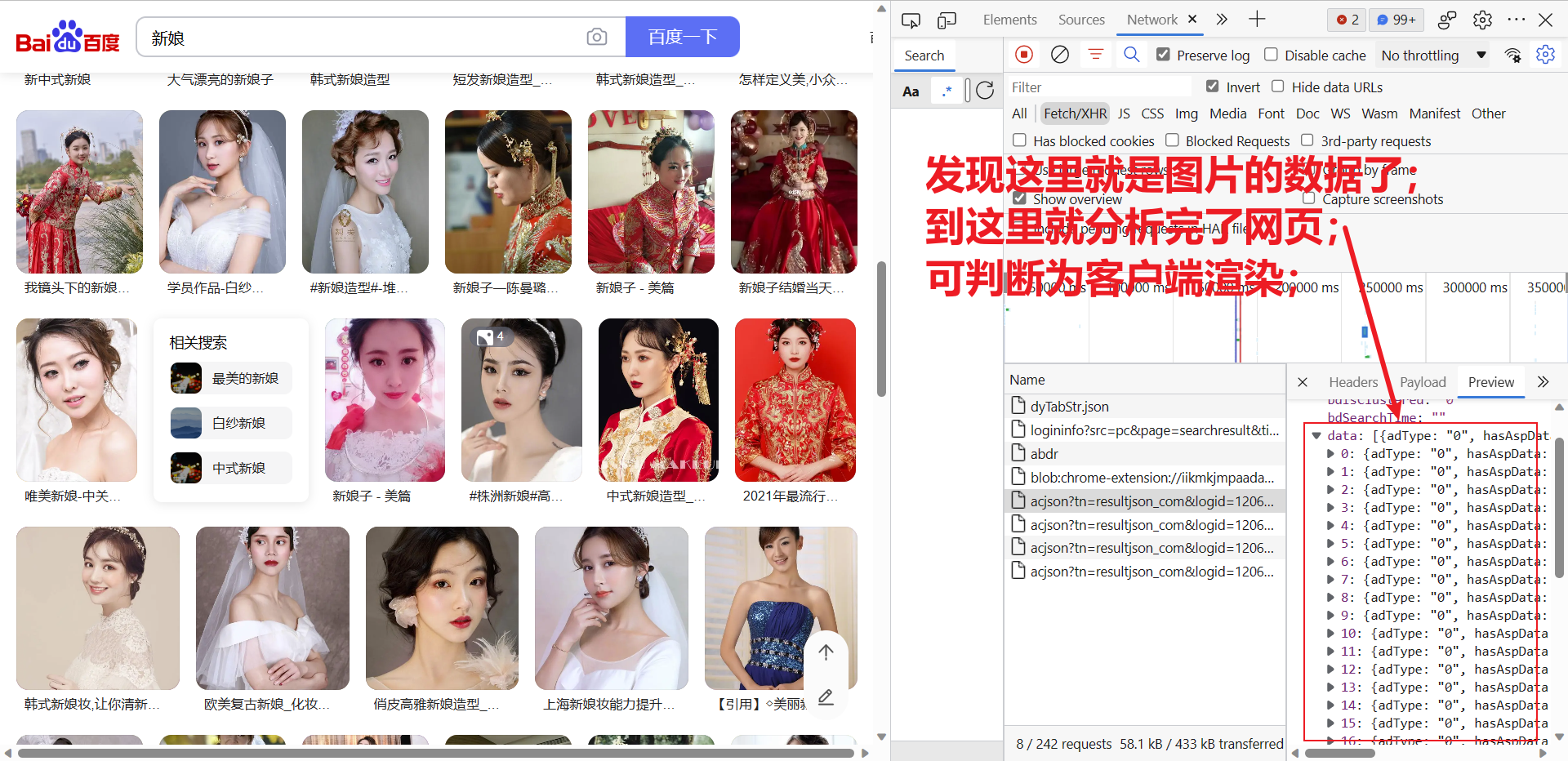
2) 请求url获取数据
我们尝试爬取一页数据,经过上一步的分析,可知我们需要请求的url不再是浏览器网址栏里的url了,而是返回的url,可以在返回的Headers中复制该url;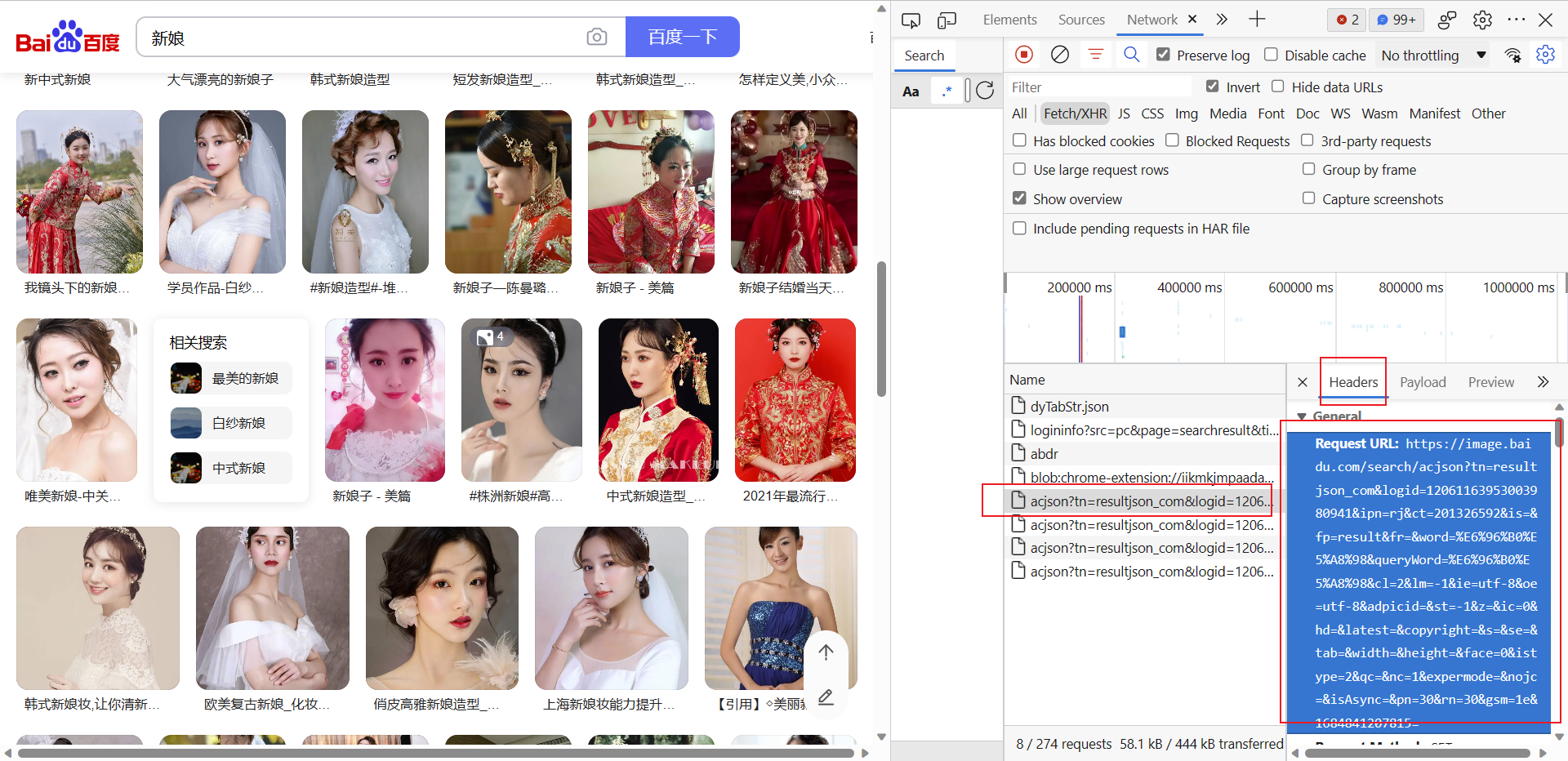
# 导入相关依赖库
import requests
# 模拟请求头——反爬
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50'
}
# 请求的url
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=12061163953003980941&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E6%96%B0%E5%A8%98&queryWord=%E6%96%B0%E5%A8%98&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1684841207815='
# 发送请求获取数据
resp = requests.get(url=url, headers=head)
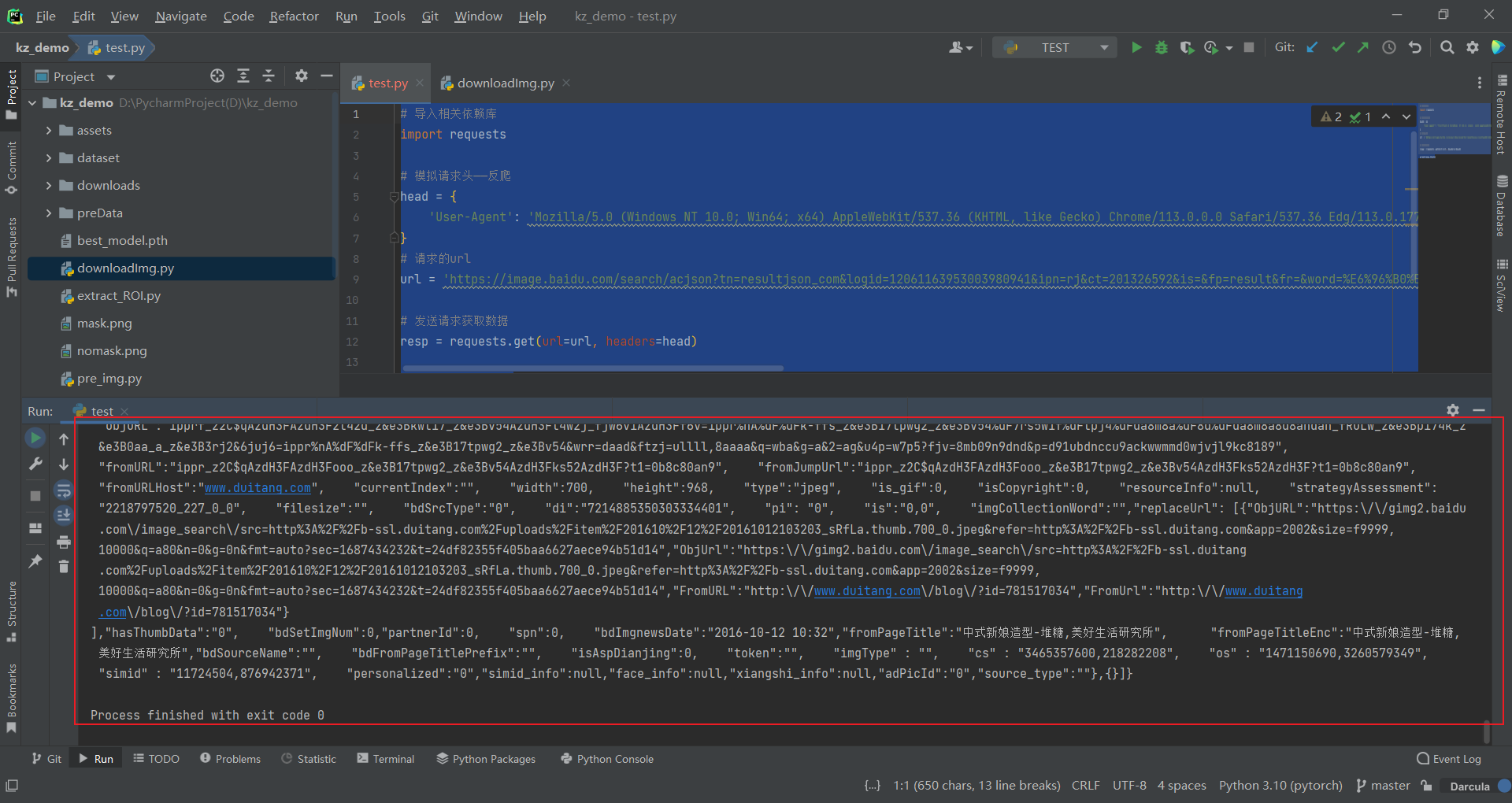
print(resp.text)
可见非常地成功返回了网页数据:
为了看看返回的数据是不是和浏览器返回的一样的,我们使用json格式化工具:https://oktools.net/json(或https://c.runoob.com/front-end/53/)
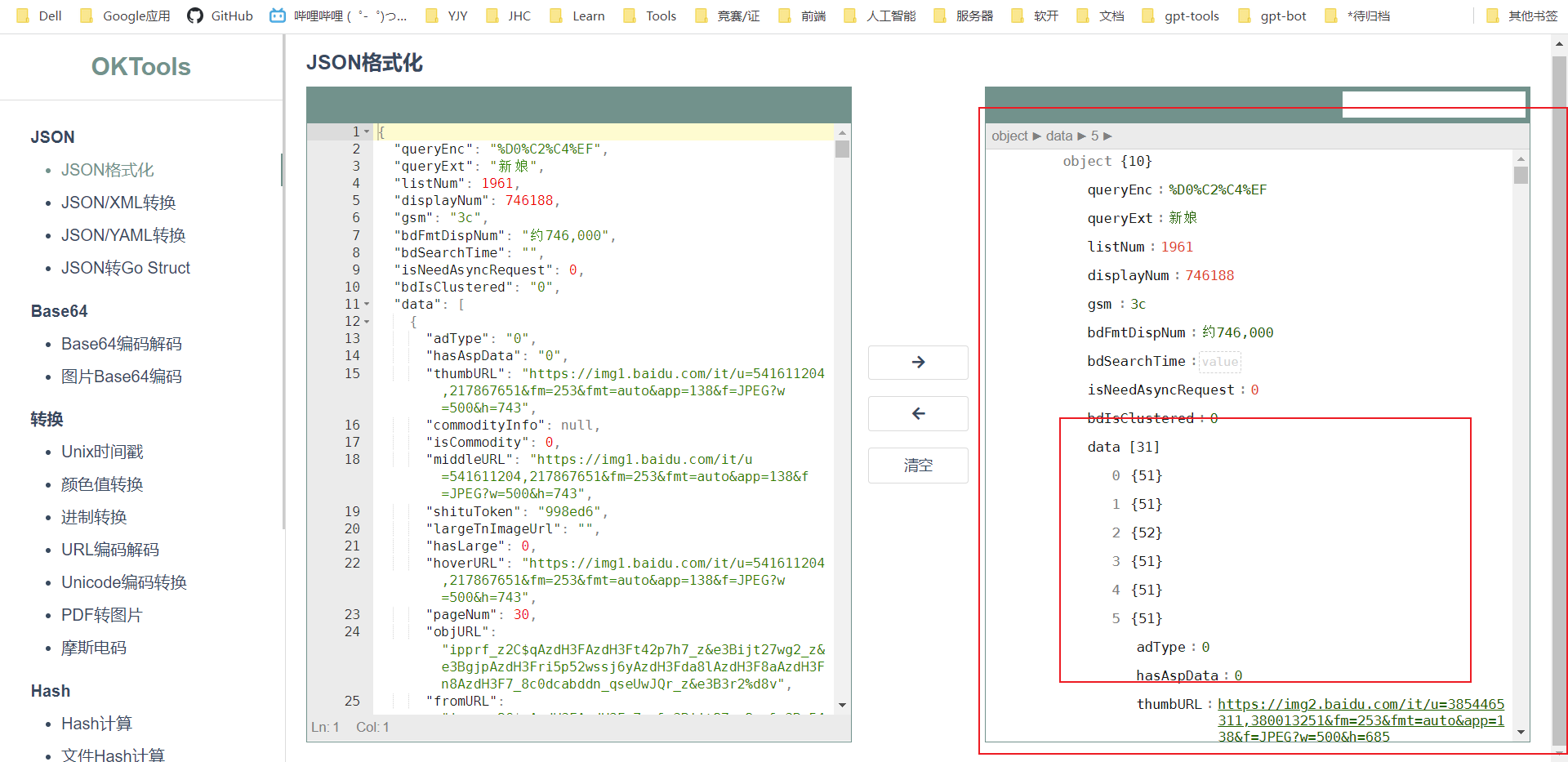
可以看到和浏览器里的是一样的,下一步就是解析返回的数据,解析到图片的url;
3) 解析数据
由于返回的格式为json,我们需要转换为json格式,然后使用字典的类似用法提取json格式里的数据,只需要指定key就能获取到相应key下的值了;先解析出data下所有数据:
# 导入相关依赖库
import requests
# 模拟请求头——反爬
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50'
}
# 请求的url
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=12061163953003980941&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E6%96%B0%E5%A8%98&queryWord=%E6%96%B0%E5%A8%98&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1684841207815='
# 发送请求获取数据
resp = requests.get(url=url, headers=head)
# print(resp.text)
# 转json,解析data所有数据
data_json = resp.json()
data = data_json['data']
print(data)
这样就返回了data下的所有数据了,接着我们只需要遍历这个data,获取到url即可(获取图片的url,需要提前看看在哪一个key下,通过分析在[‘thumbURL']下)
# 导入相关依赖库
import requests
# 模拟请求头——反爬
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50'
}
# 请求的url
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=12061163953003980941&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E6%96%B0%E5%A8%98&queryWord=%E6%96%B0%E5%A8%98&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1684841207815='
# 发送请求获取数据
resp = requests.get(url=url, headers=head)
# print(resp.text)
# 转json,解析data所有数据
data_json = resp.json()
data = data_json['data']
# print(data)
print(len(data))
# 遍历data下所有数据
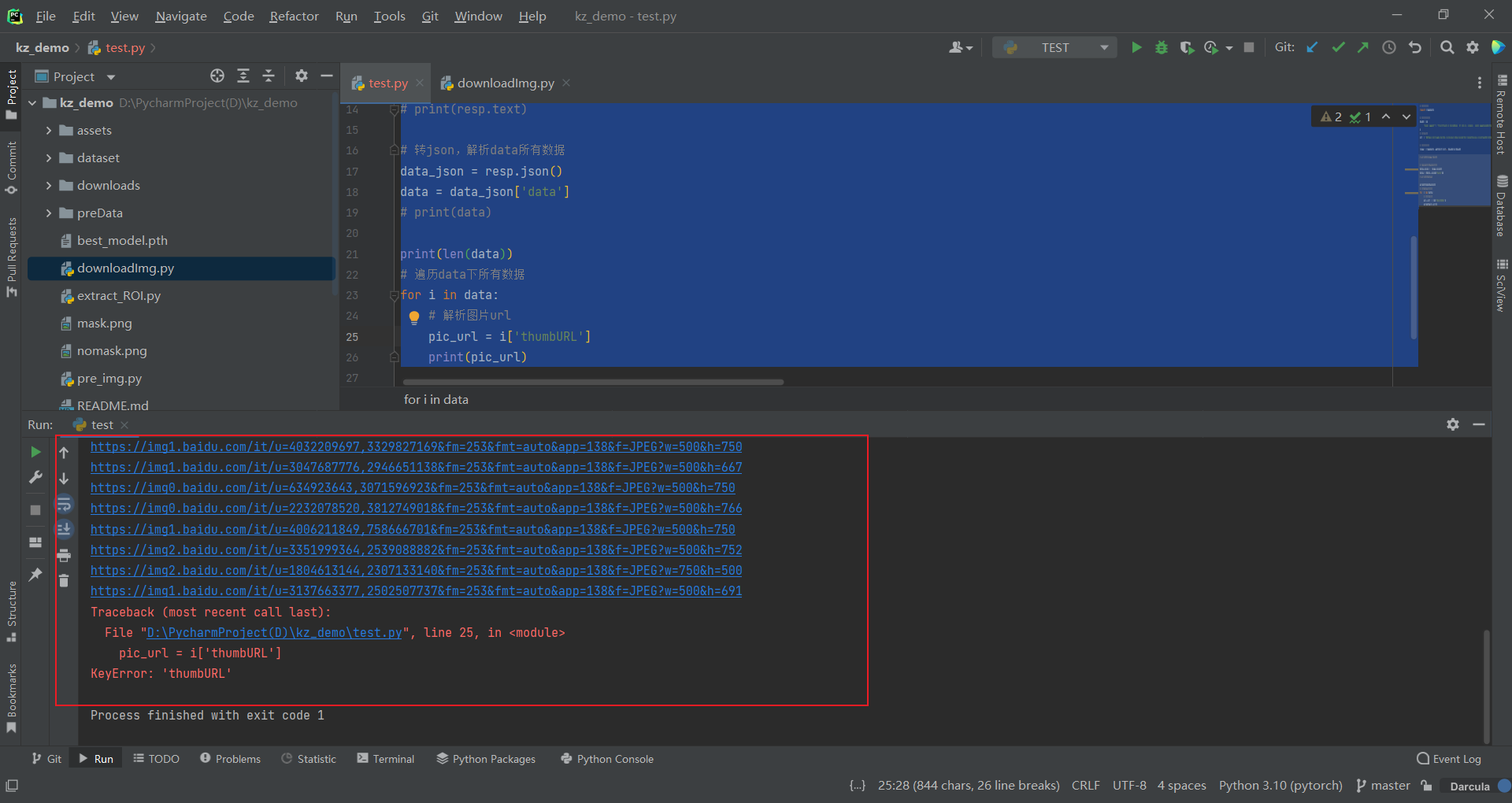
for i in data:
# 解析图片url
pic_url = i['thumbURL']
print(pic_url)
非常成功地返回了所有的图片url:
解决报错,可以添加try:
# 导入相关依赖库
import requests
# 模拟请求头——反爬
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50'
}
# 请求的url
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=12061163953003980941&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E6%96%B0%E5%A8%98&queryWord=%E6%96%B0%E5%A8%98&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1684841207815='
# 发送请求获取数据
resp = requests.get(url=url, headers=head)
# print(resp.text)
# 转json,解析data所有数据
data_json = resp.json()
data = data_json['data']
# print(data)
print(len(data))
# 遍历data下所有数据
for i in data:
try:
# 解析图片url
pic_url = i['thumbURL']
print(pic_url)
except:
pass
4) 保存数据
在获取到图片的url后,我们就可以请求图片的url,并将图片保存至本地了
# 导入相关依赖库
import requests
import os
# 模拟请求头——反爬
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50'
}
# 请求的url
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=12061163953003980941&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E6%96%B0%E5%A8%98&queryWord=%E6%96%B0%E5%A8%98&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1684841207815='
# 发送请求获取数据
resp = requests.get(url=url, headers=head)
# print(resp.text)
# 转json,解析data所有数据
data_json = resp.json()
data = data_json['data']
# print(data)
print(len(data))
# 遍历data下所有数据
s = 1
for i in data:
try:
# 解析图片url
pic_url = i['thumbURL']
print(pic_url)
# # 请求图片url
img = requests.get(pic_url, headers=head)
# 保存图片
# 设置保存的文件夹
dir='ouputs'
# 判断文件夹是否存在
if not os.path.exists(dir):
os.mkdir(dir)
with open(f'{dir}/新娘_{s}.jpg', 'wb') as f:
# 二进制的格式保存
f.write(img.content)
s += 1
except:
pass
运行完后,图片爬取成功:
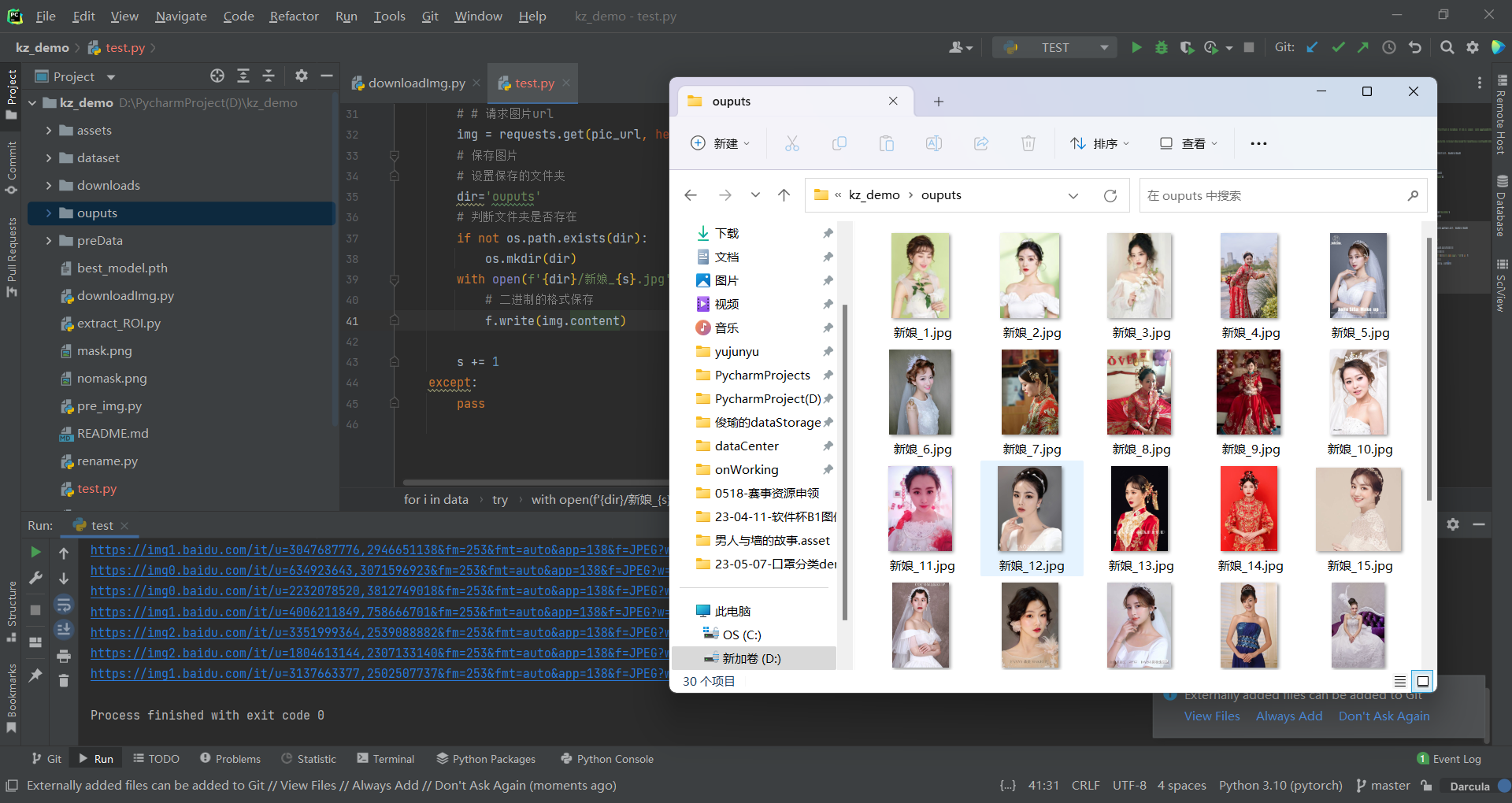
e) 批量爬取
一页数据爬取成功就成功了一大半,接下来需要批量爬取,什么叫批量爬取,简单来说就是一次性爬取多页爬取,假设我们指定爬取页数,程序就爬取多少页数据,这个时候有需要分析网页返回的url里的参数是怎么变的了;
先看看网页是怎么变的,如下:
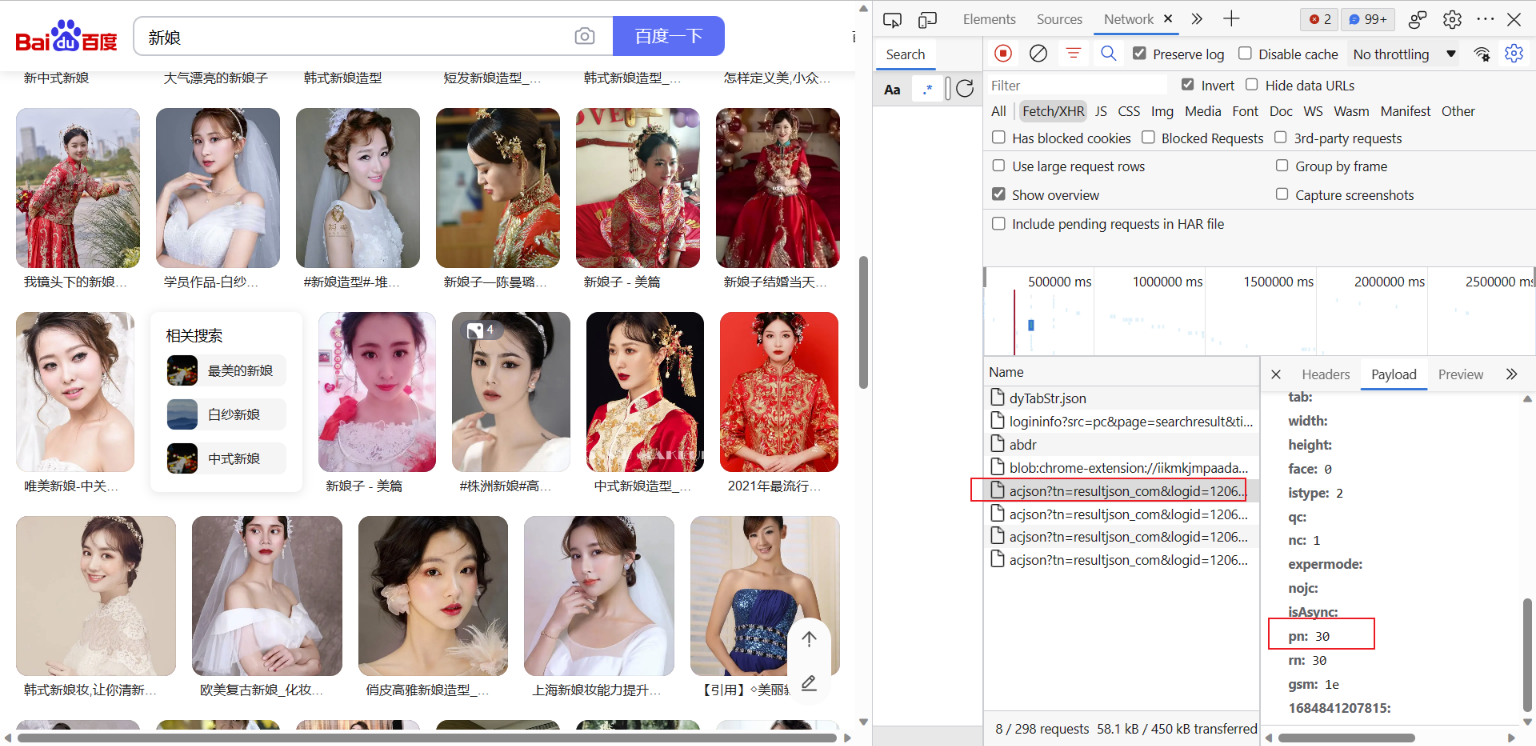
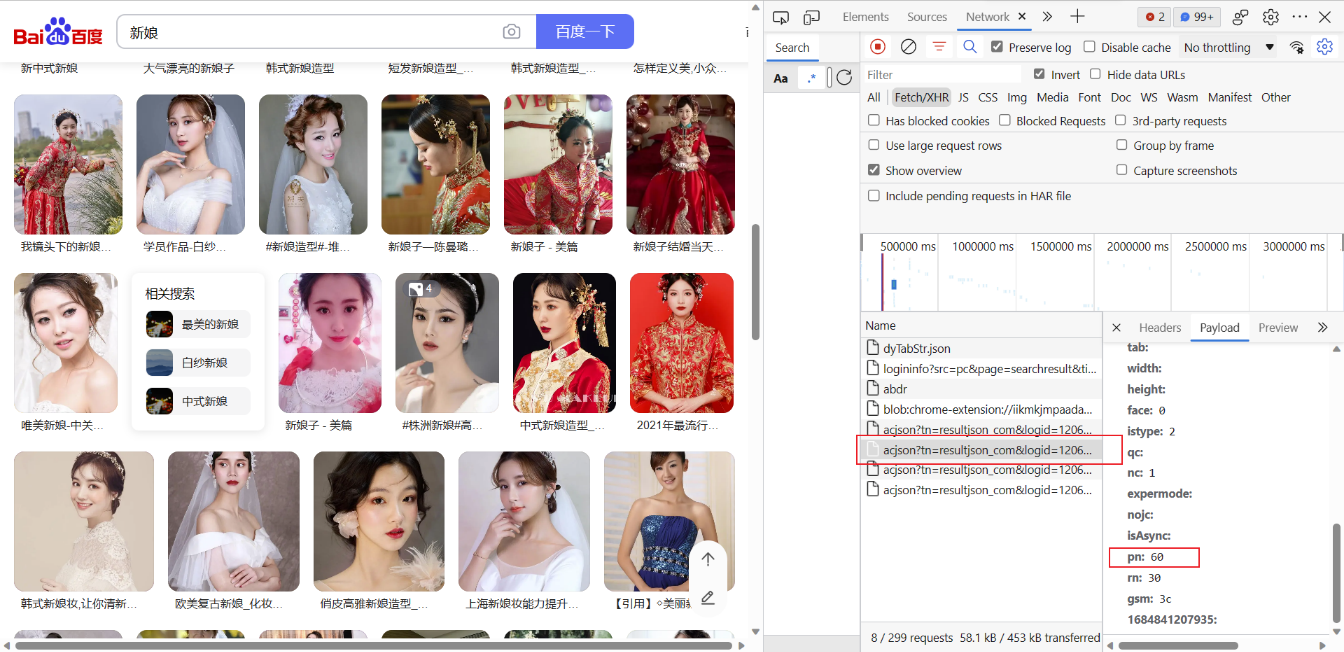
经过发现,也就是找规律,发现pn是在变化的,大概就是第一页数据pn=30,第二页pn=60,第三页pn=90,以此类推,所有我们只需要改变请求url中pn的值就行了;
现在我们假设爬10页,也就循环10次,pn每次都加30即可;根据前面爬的一页数据,知道一页30张图片,所以爬取10页,应该得到300页:
# 导入相关依赖库
import requests
import os
# 模拟请求头——反爬
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50'
}
s = 1
# 爬取10页
for page in range(30, 30 * 11, 30):
print(f'pn={page}')
# 请求的url
url = f'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=12061163953003980941&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E6%96%B0%E5%A8%98&queryWord=%E6%96%B0%E5%A8%98&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn={page}&rn=30&gsm=1e&1684841207815='
# 发送请求获取数据
resp = requests.get(url=url, headers=head)
# print(resp.text)
# 转json,解析data所有数据
data_json = resp.json()
data = data_json['data']
# print(data)
print(len(data))
# 遍历data下所有数据
for i in data:
try:
# 解析图片url
pic_url = i['thumbURL']
print(pic_url)
# # 请求图片url
img = requests.get(pic_url, headers=head)
# 保存图片
# 设置保存的文件夹
dir = 'ouputs'
# 判断文件夹是否存在
if not os.path.exists(dir):
os.mkdir(dir)
with open(f'{dir}/新娘_{s}.jpg', 'wb') as f:
# 二进制的格式保存
f.write(img.content)
s += 1
except:
pass
数据如下,300张图就没错了,也可以人工看看图片是否有误:
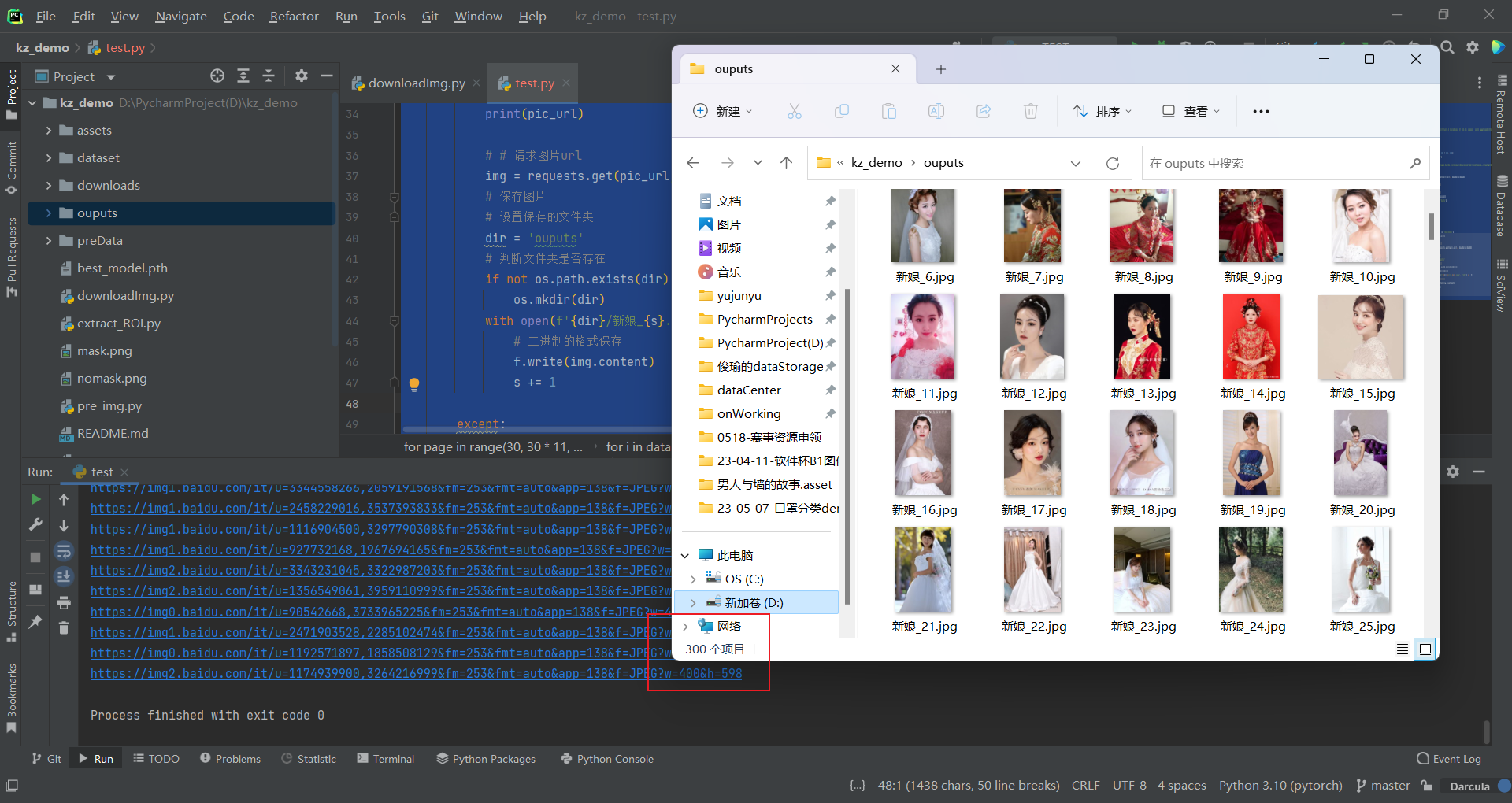
d) 优化代码
一开始我们是希望指定关键字和页数的,所以代码可以做成交互式的程序,最终运行程序,用户只需要输入爬取的关键字和数量,即可爬取图片并保存相应的数据;
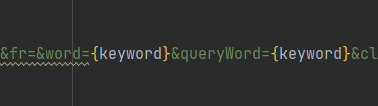
指定关键字:需要将请求url中涉及关键字的字符替换掉:
指定数量:写法不唯一,这里仅仅是我本人的写法:

优化后的代码如下:
import os
import requests
from faker import Faker
def download_images(keyword, num):
"""
爬取百度图片搜索结果中指定关键词keyword的前 num 张图片,并下载到本地文件夹。
:param keyword: 搜索关键词
:param num: 需要下载的图片数量
"""
# 创建保存图片的文件夹
dir_name = f'downloads/{keyword}'
if not os.path.exists(dir_name):
os.makedirs(dir_name)
count = 0
page_num = 0
# 持续爬取图片,直到达到指定数量
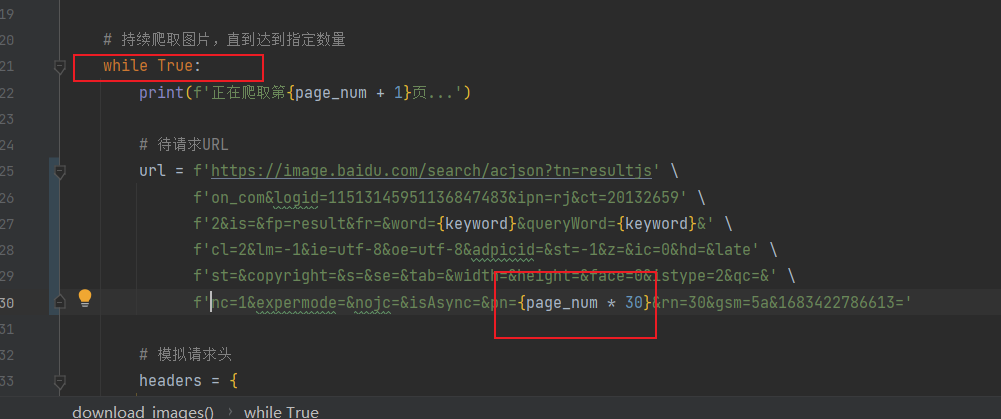
while True:
print(f'正在爬取第{page_num + 1}页...')
# 待请求URL
url = f'https://image.baidu.com/search/acjson?tn=resultjs' \
f'on_com&logid=11513145951136847483&ipn=rj&ct=20132659' \
f'2&is=&fp=result&fr=&word={keyword}&queryWord={keyword}&' \
f'cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&late' \
f'st=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&' \
f'nc=1&expermode=&nojc=&isAsync=&pn={page_num * 30}&rn=30&gsm=5a&1683422786613='
# 模拟请求头
headers = {
'User-Agent': Faker().user_agent()
}
# 发送 HTTP 请求,获取响应结果并解析 JSON 数据
response = requests.get(url, headers=headers).json()
# 遍历所有图片信息
for image_info in response['data']:
try:
# 打印当前正在下载的图片的 URL
print(f'正在下载第 {count} 张图片')
print(image_info['thumbURL'])
# 下载图片并保存到本地文件夹
image_data = requests.get(image_info['thumbURL'], headers=headers)
with open(os.path.join(dir_name, f'{keyword}_{count}.jpg'), 'wb') as f:
f.write(image_data.content)
count += 1
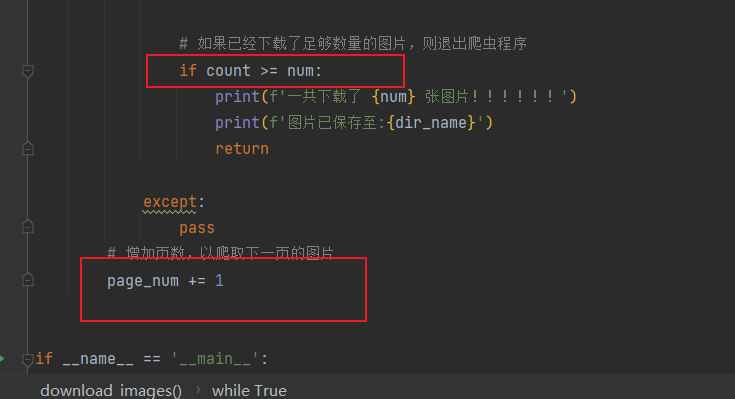
# 如果已经下载了足够数量的图片,则退出爬虫程序
if count >= num:
print(f'一共下载了 {num} 张图片!!!!!!')
print(f'图片已保存至:{dir_name}')
return
except:
pass
# 增加页数,以爬取下一页的图片
page_num += 1
if __name__ == '__main__':
keyword = input('请输入关键字:')
num = eval(input('请输入数量:'))
download_images(keyword, num)
3、完整代码
# 同上优化代码
4、采集数据
运行爬取图片的程序:先采集戴口罩的人200张,输入【戴口罩的人】、200
爬取的数据如下:
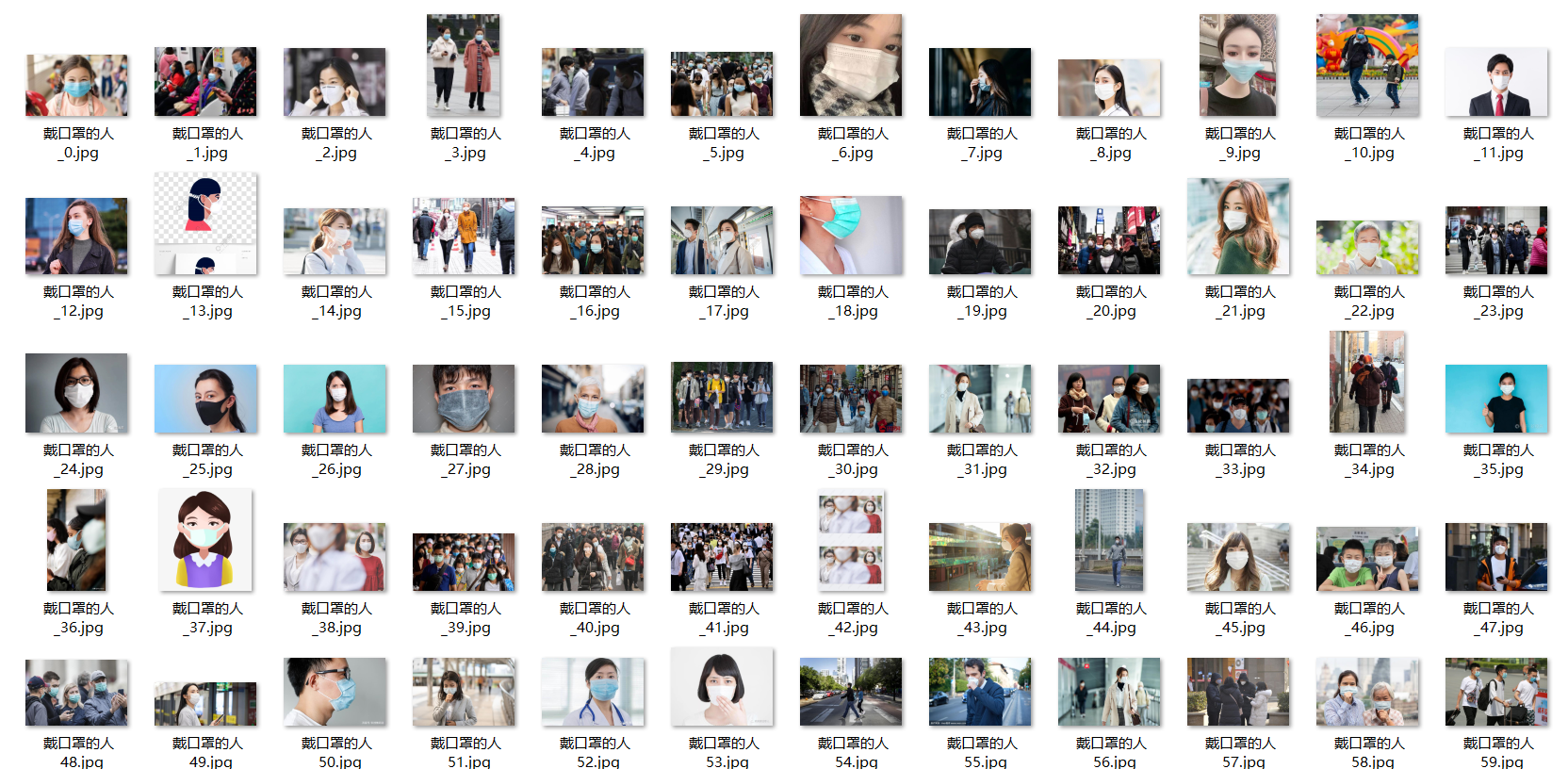
注:爬取的原始数据保存到downloads下
三、数据初筛
1、人工删图
这一步没什么技术含量,就纯人工判断图片要不要保留,看你心情,但有些很离谱的图片你保留了,没有任何意义,甚至会影响后续模型训练、预测。
人工对采集的图片进行初步筛选:删除质量不好的图片(如卡通的、非关键字的、质量差的等图片):
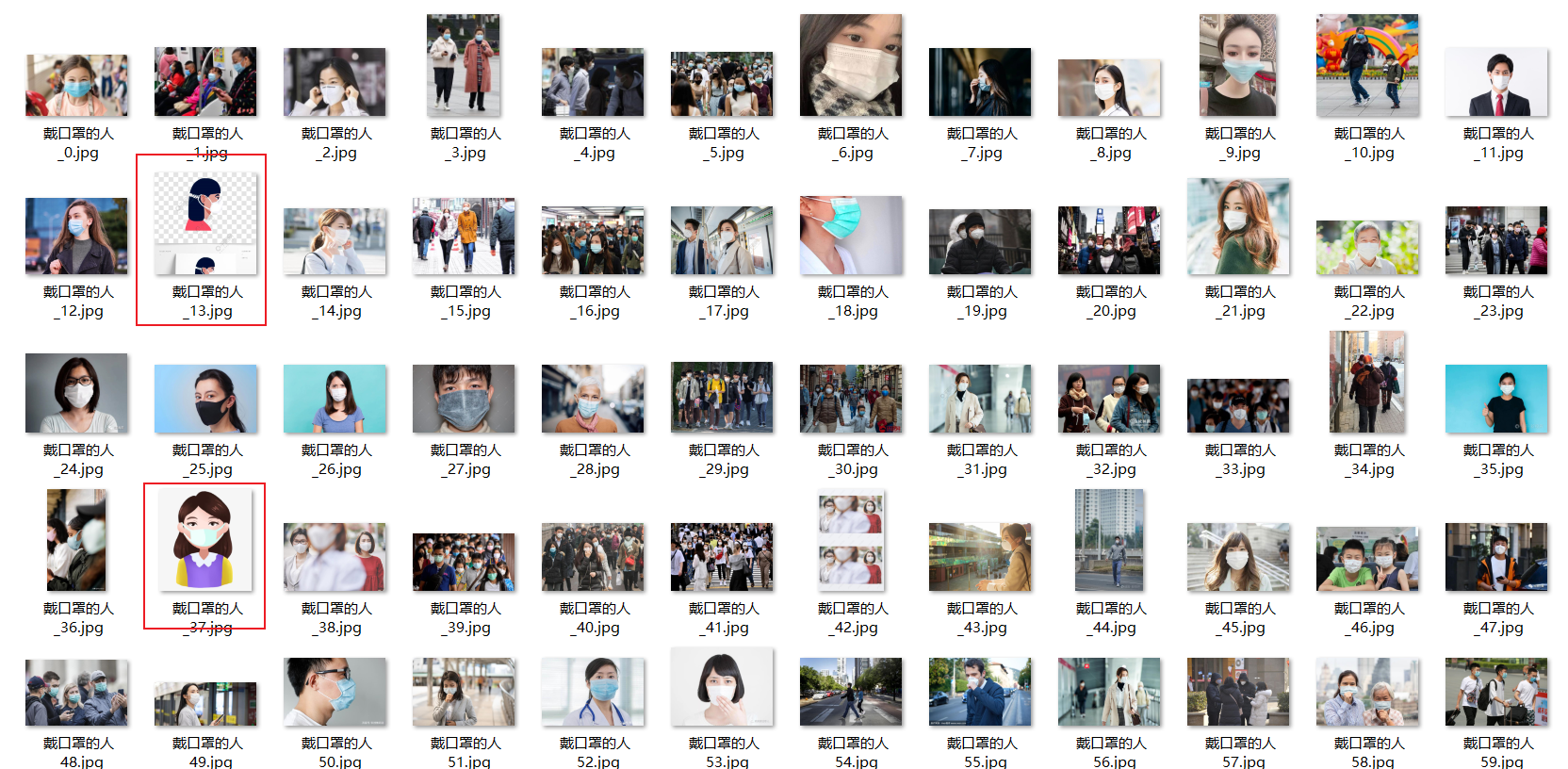
复制并初筛后如下:
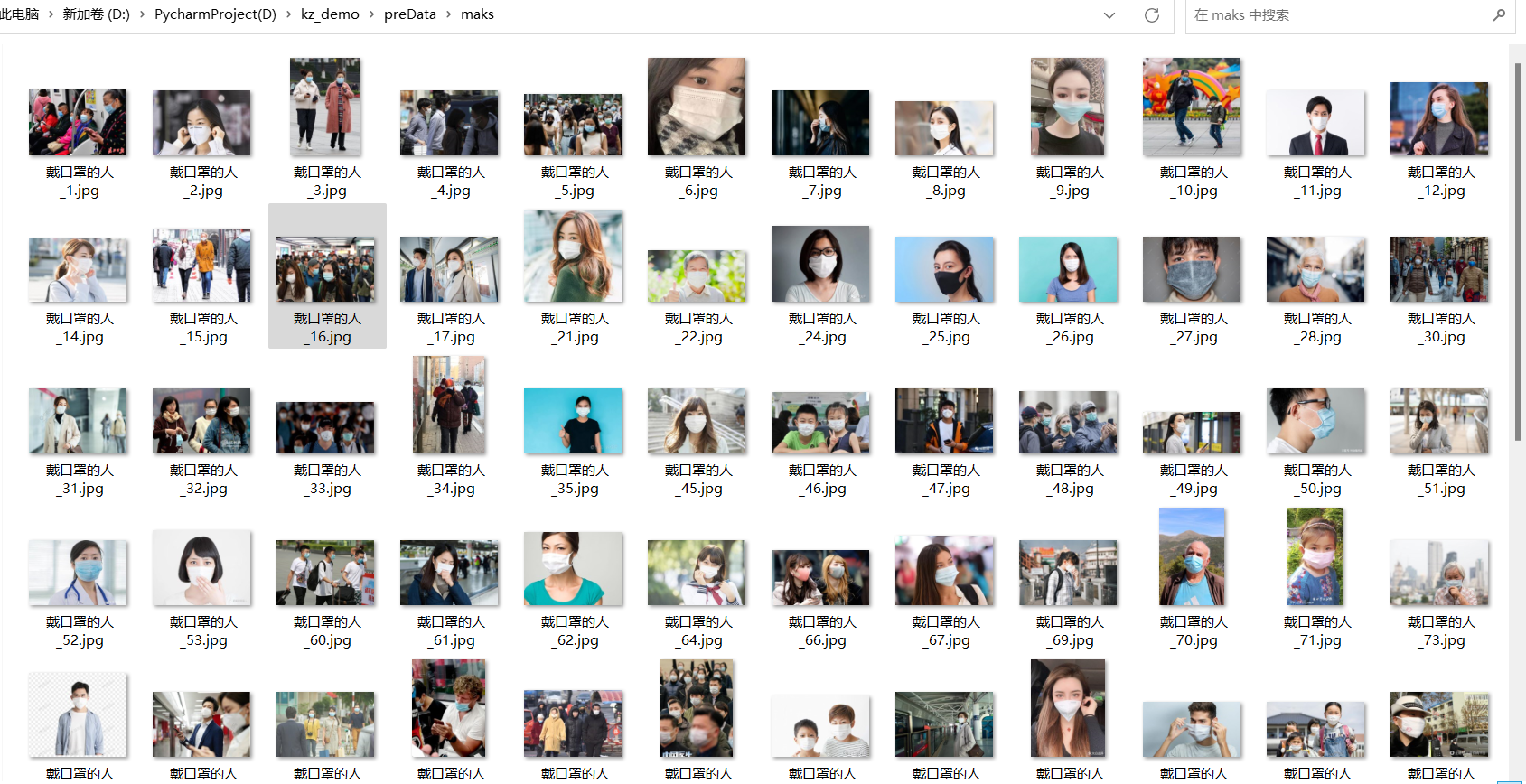
注:初筛后的数据在保存到preData/mask下
2、图片重命名
为了后续opencv的读取,需要将这些图片名进行重命名,含中文后续可能会报错(本人已踩坑过),批量进行重命名,完整代码如下:
import os
source_dir = 'preData/mask' # 源文件夹路径
k = 1
for filename in os.listdir(source_dir):
if "jpg" in filename:
old_path = os.path.join(source_dir, filename) # 原始文件路径
new_path = os.path.join(source_dir, "mask_" + str(k) + ".jpg") # 新文件路径(注意处理不戴口罩的图片时,记得修改保存的图片名,改为no_mask即可)
os.rename(old_path, new_path) # 重命名文件
k += 1
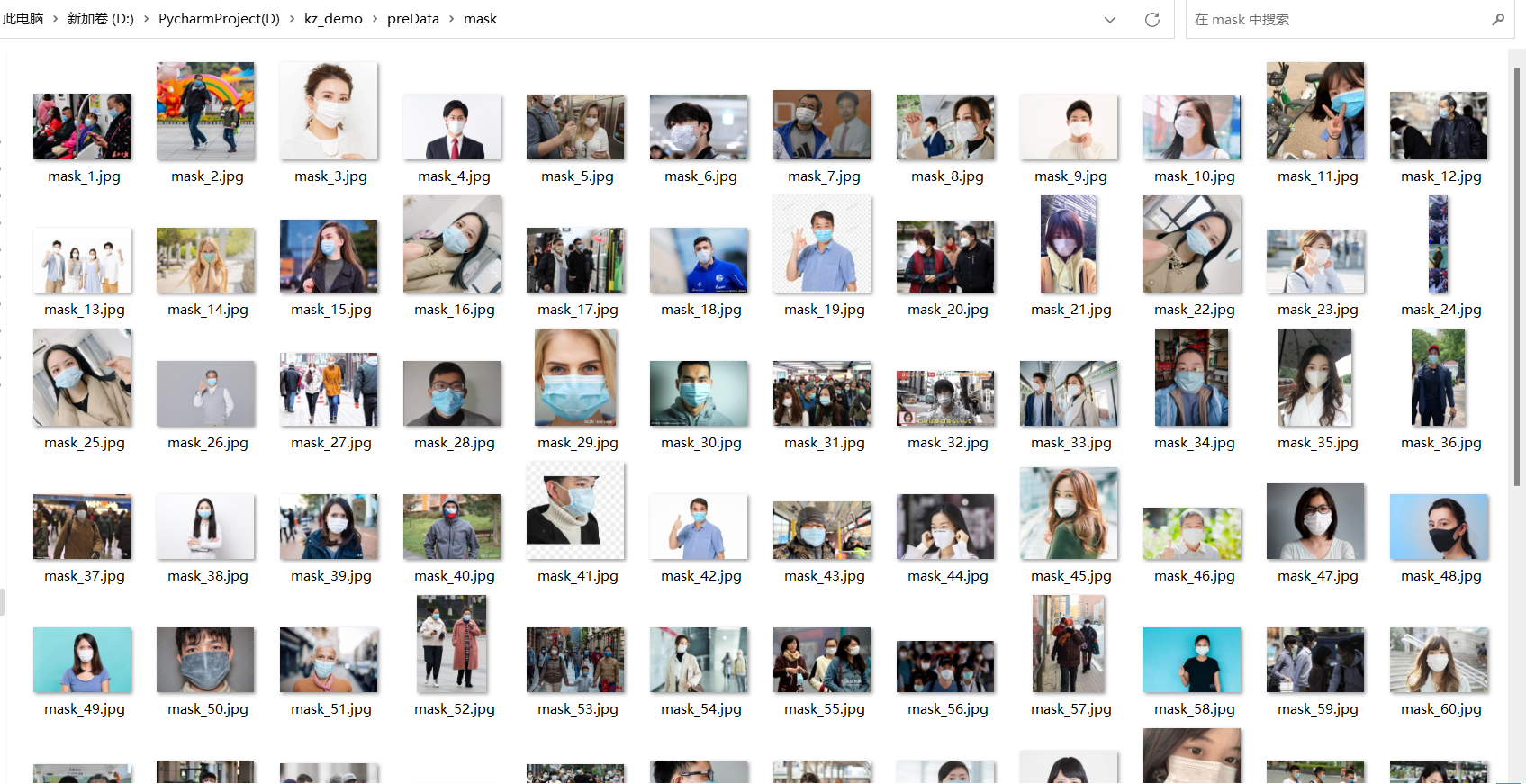
四、数据预处理
将初步筛选后的数据进一步处理:
1、先使用labelImg先对戴口罩区域进行标注;
2、再通过脚本对标注区域进行提取并保存;
最终形成戴口罩的数据集。
1、labelimg标注
1)安装:
pip install labelimg
2)启动:
labelimg

启动后界面如下:

3)标注:
a:先打开待标注的数据文件夹

b:设置标注文件的保存路径
c:保存格式设置为PascalVoc
d:w为标注模式,拖拉即可标注,设置标签名mask即可,注意保存ctrl+s,下一张为快捷键D,效果如下:

将所有戴口罩的标注完成即可;
标注文件如下:

注:标注文件保存至predata/mask下
接下去就是需要通过这些标注文件对标注区域进行提取并保存为图片;
2、提取标注区域
对xml标注文件批量处理,根据标注坐标裁剪出标注区域的图片,并另存为。完整代码如下:
# -*- codeing = utf-8 -*-
# @Time :2023/5/7 18:33
# @Author :yujunyu
import os
import xml.etree.ElementTree as ET
import cv2
k = 1
# xml文件夹路径
xml_path = 'preData/anno_nomask'
for filename in sorted(os.listdir(xml_path)):
# print(filename)
# 加载xml文件
annotation_file = os.path.join(xml_path, filename)
tree = ET.parse(annotation_file)
root = tree.getroot()
# 原始图片
img_path = root.find('path').text
img = cv2.imread(img_path)
# cv2.imshow('img', img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# 解析标注信息
for i in root.findall('object'):
# 处理某些xml没有标注的情况
try:
# 解析标签名、标注坐标
label = i.find('name').text
xmin = int(i.find('bndbox').find('xmin').text)
ymin = int(i.find('bndbox').find('ymin').text)
xmax = int(i.find('bndbox').find('xmax').text)
ymax = int(i.find('bndbox').find('ymax').text)
print(label)
print(xmin, ymin, xmax, ymax)
# 裁剪标注区域
img1 = img[ymin:ymax, xmin:xmax]
# 保存
save_dir = 'dataset/nomask'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
cv2.imwrite(os.path.join(save_dir, f'{label}_' + str(k) + '.jpg'), img1)
k += 1
except:
pass
注:最终数据集保存至dataset/mask下
效果如下:

没有戴口罩同上操作(从采集数据、数据初筛、数据预处理三步骤)再来一遍即可;

五、模型搭建
1、预备知识
由于深度学习的预备知识较为多:
- 如果没有系统地完整地学过深度学习的,理解代码会有些吃力,有时间且感兴趣的可以系统的进行学习,不学的话直接bing一下,花点时间理解理解代码也不难,推荐视频如下:
- 如果有学过深度学习,哪怕大致知道深度学习的整体开发流程,可以不用看视频教程,哪一行不懂就去搜哪行(推荐bing)
注:为五、六、七三部分的预备知识。
说明:深度学习的代码具体教程不再详细解释,不懂自己bing一下
2、搭建CNN
搭建一个cnn,输入的图片为3通道、大小为224×224,完整代码如下:
import cv2
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms
from PIL import Image
from torchvision.datasets import ImageFolder
class CNN(nn.Module):
def __init__(self, num_classes):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.relu3 = nn.ReLU()
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(64 * 28 * 28, 512)
self.relu4 = nn.ReLU()
self.dropout1 = nn.Dropout(0.5)
self.fc2 = nn.Linear(512, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.relu3(x)
x = self.pool3(x)
x = x.view(-1, 64 * 28 * 28)
x = self.fc1(x)
x = self.relu4(x)
x = self.dropout1(x)
x = self.fc2(x)
return x
model = CNN(num_classes=2)
print(model)
# class LeNet5(nn.Module):
# def __init__(self, num_classes):
# super(LeNet5, self).__init__()
# self.conv1 = nn.Conv2d(3, 6, kernel_size=5, stride=1, padding=2)
# self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# self.conv2 = nn.Conv2d(6, 16, kernel_size=5, stride=1)
# self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# self.fc1 = nn.Linear(16 * 56 * 56, 120)
# self.fc2 = nn.Linear(120, 84)
# self.fc3 = nn.Linear(84, num_classes)
#
# def forward(self, x):
# x = self.conv1(x)
# x = torch.relu(x)
# x = self.pool1(x)
# x = self.conv2(x)
# x = torch.relu(x)
# x = self.pool2(x)
# x = x.view(-1, 16 * 56 * 56)
# x = self.fc1(x)
# x = torch.relu(x)
# x = self.fc2(x)
# x = torch.relu(x)
# x = self.fc3(x)
# return x
# model = LeNet5(num_classes=2)
# print(model)
六、模型训练
训练分类模型,完整代码如下:
# 定义数据增强和预处理操作
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整图像大小为224x224
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 标准化
])
# 加载带标签的图像数据集,并划分训练集和测试集
dataset = ImageFolder(root='dataset', transform=transform)
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])
# 定义数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=32, shuffle=False)
# 定义模型
model = CNN(num_classes=2)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
best_acc = 0
epochs = 10
for epoch in range(epochs):
# 训练模型
model.train()
train_loss = 0
train_correct = 0
train_total = 0
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
train_total += labels.size(0)
train_correct += (predicted == labels).sum().item()
# 在测试集上计算准确率
model.eval()
test_loss = 0
test_correct = 0
test_total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
train_loss /= len(train_loader)
train_acc = 100 * train_correct / train_total
test_loss /= len(test_loader)
test_acc = 100 * test_correct / test_total
print('Epoch [{}/{}]\tTrain Loss: {:.4f}\tTrain Acc: {:.2f}%\tTest Loss: {:.4f}\tTest Acc: {:.2f}%'
.format(epoch+1, epochs, train_loss, train_acc, test_loss, test_acc))
# 保存最好的模型参数
if test_acc > best_acc:
torch.save(model.state_dict(), 'best_model.pth')
best_acc = test_acc
训练过程打印如下:
C:\Users\yujunyu\.conda\envs\pytorch\python.exe D:/PycharmProject(D)/kz_demo/train.py
Epoch [1/10] Train Loss: 0.9244 Train Acc: 58.33% Test Loss: 0.4006 Test Acc: 75.51%
Epoch [2/10] Train Loss: 0.4166 Train Acc: 78.65% Test Loss: 0.1748 Test Acc: 95.92%
Epoch [3/10] Train Loss: 0.1443 Train Acc: 96.88% Test Loss: 0.0624 Test Acc: 97.96%
Epoch [4/10] Train Loss: 0.0649 Train Acc: 97.92% Test Loss: 0.0944 Test Acc: 97.96%
Epoch [5/10] Train Loss: 0.0232 Train Acc: 98.96% Test Loss: 0.0984 Test Acc: 97.96%
Epoch [6/10] Train Loss: 0.0132 Train Acc: 99.48% Test Loss: 0.1068 Test Acc: 97.96%
Epoch [7/10] Train Loss: 0.0024 Train Acc: 100.00% Test Loss: 0.1299 Test Acc: 97.96%
Epoch [8/10] Train Loss: 0.0056 Train Acc: 100.00% Test Loss: 0.1367 Test Acc: 97.96%
Epoch [9/10] Train Loss: 0.0014 Train Acc: 100.00% Test Loss: 0.1239 Test Acc: 97.96%
Epoch [10/10] Train Loss: 0.0015 Train Acc: 100.00% Test Loss: 0.1458 Test Acc: 97.96%
Process finished with exit code 0
七、预测图片
使用非数据集的图片进行预测,完整代码如下:
# -*- codeing = utf-8 -*-
# @Time :2023/5/7 21:35
# @Author :yujunyu
import cv2
import torch
import torchvision
from torchvision import transforms
from PIL import Image
class CNN(torch.nn.Module):
def __init__(self, num_classes):
super(CNN, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
self.relu1 = torch.nn.ReLU()
self.pool1 = torch.nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = torch.nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.relu2 = torch.nn.ReLU()
self.pool2 = torch.nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3 = torch.nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.relu3 = torch.nn.ReLU()
self.pool3 = torch.nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = torch.nn.Linear(64 * 28 * 28, 512)
self.relu4 = torch.nn.ReLU()
self.dropout1 = torch.nn.Dropout(0.5)
self.fc2 = torch.nn.Linear(512, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.relu3(x)
x = self.pool3(x)
x = x.view(-1, 64 * 28 * 28)
x = self.fc1(x)
x = self.relu4(x)
x = self.dropout1(x)
x = self.fc2(x)
return x
# 定义数据增强和预处理操作
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整图像大小为224x224
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 标准化
])
# 加载模型参数
model = CNN(num_classes=2)
model.load_state_dict(torch.load('best_model.pth'))
model.eval()
# 加载图像
img_path = 'nomask.png'
img = Image.open(img_path)
# 进行预处理
img = transform(img)
# label_map
label_map = ['mask', 'nomask']
# 使用模型进行预测
with torch.no_grad():
outputs = model(img)
probs = torch.softmax(outputs, dim=1)
p, cls = torch.max(probs, 1)
print('待预测图片:{}\t预测概率:{}\t预测标签:{}'.format(img_path, p.numpy()[0], label_map[cls]))
# 可视化
img = cv2.imread(img_path)
cv2.putText(img, 'p:{:.2f} cls:{}'.format(p.numpy()[0], label_map[cls]), (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
cv2.imshow('res', img)
cv2.waitKey(0)
效果如下:


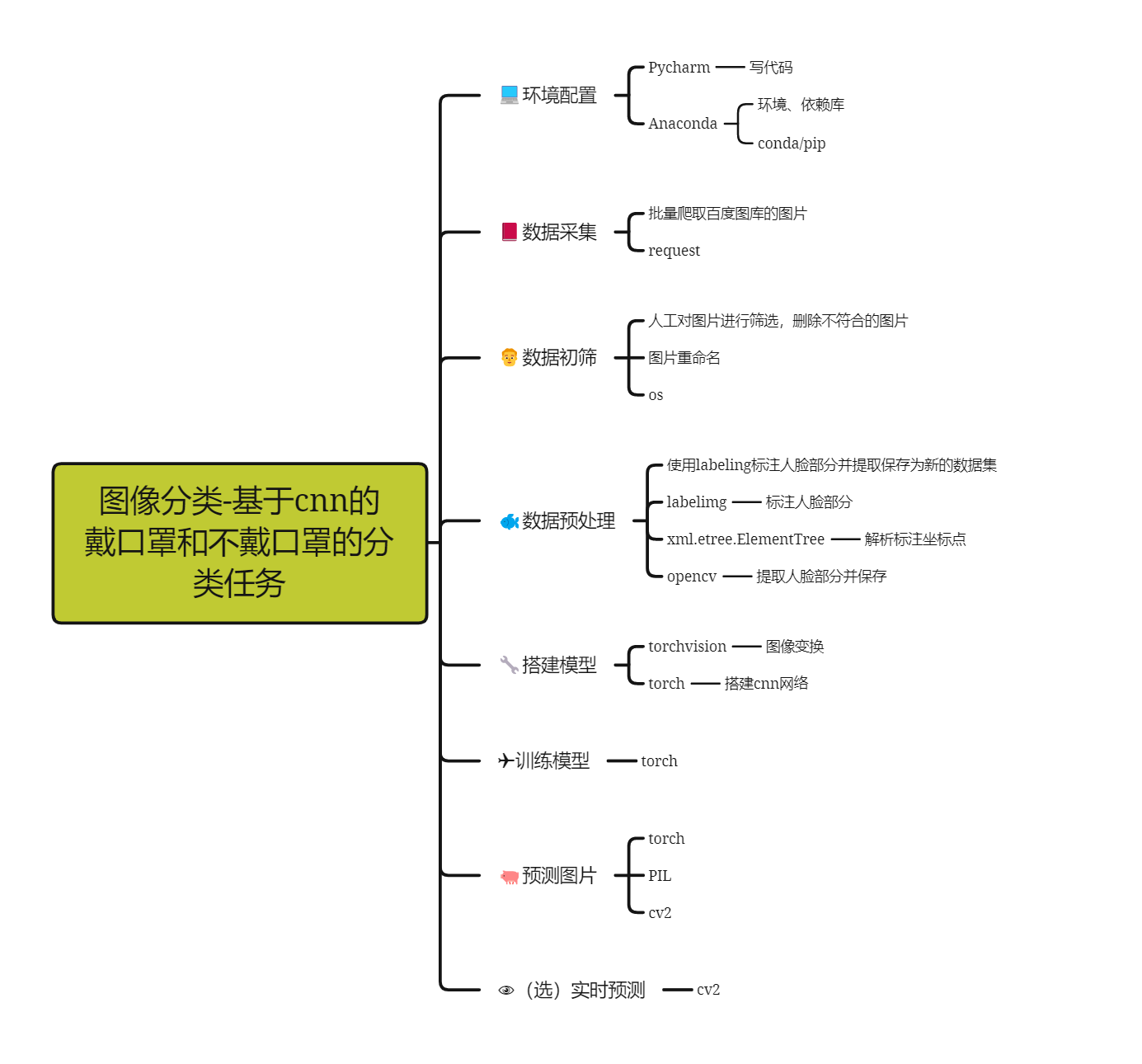
八、项目总结
本项目为深度学习中入门任务之一——图像分类,本次项目从环境配置、数据采集、数据初筛、数据预处理、模型搭建、模型训练、预测等几个模块进行开发:
- 环境配置使用pycharm+anaconda组合的开发环境;
- 数据采集部分涉及爬虫技术;
- 数据初筛的图片重命名涉及os模块;
- 数据预处理涉及labelimg、cv2、xml.etree.ElementTree等;
- 模型搭建、训练、预测使用pytorch框架;
整套项目下来需要掌握的干货非常非常多,各个部分仍需要系统的学习,才能保证类似任务能够完成开发。
注:
📕作者:蟹老板
🏠主页:https://www.cnblogs.com/xielaoban/
🈲本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利
