
2023-2-1-openMMLab AI实战营 笔记(一)
一、计算机视觉基础
概念及应用
计算机视觉任务:图像分类(classification)、目标检测(object detection)、图像分割(segmentation)。
其中图像分割又分为语义分割(semantic segmentation)、实例分割(instance segmentation)。后者不仅将像素抠出来还区分类别。
计算机视觉处理任务:

12年Alex net之后,深度学习的使用错误率不断下降。
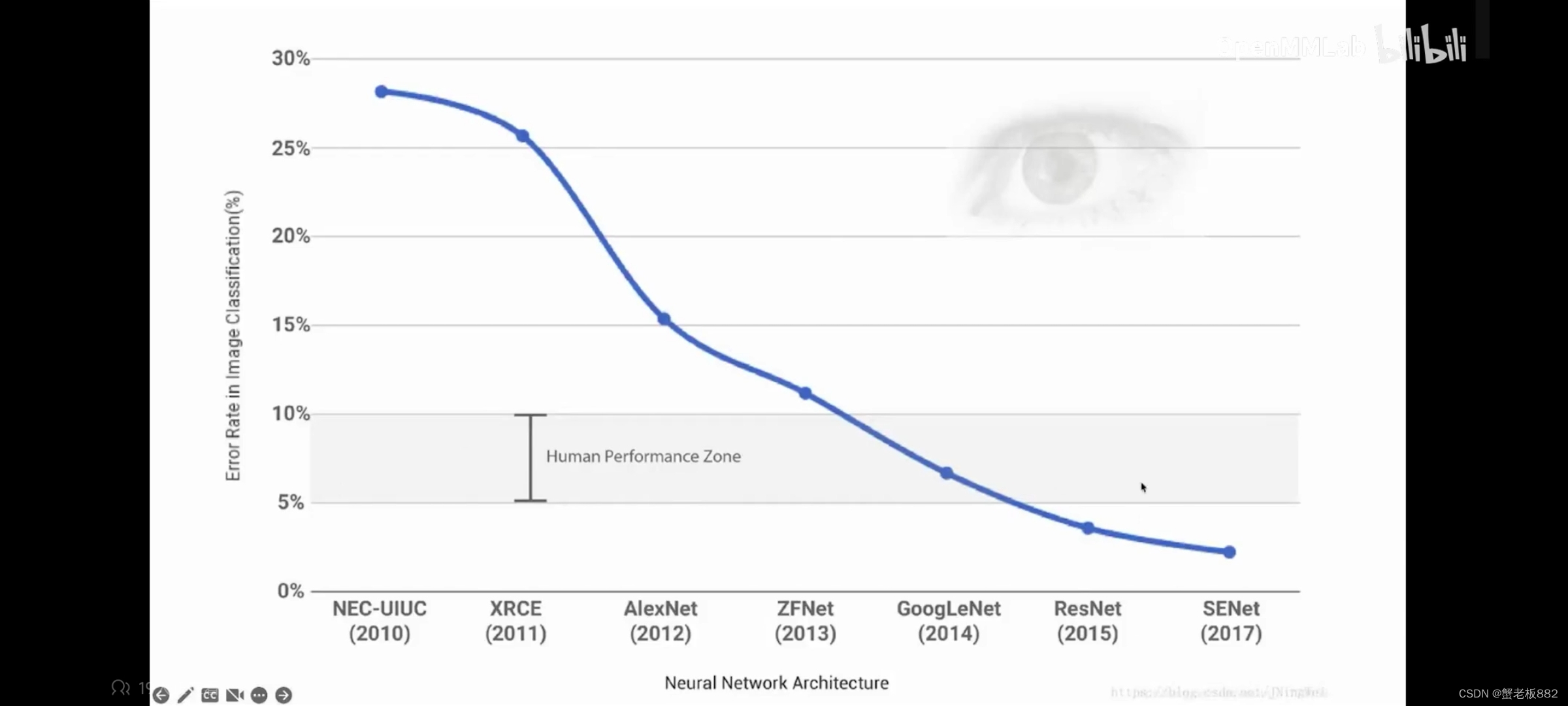
层数不断增加 错误率不断下降。
计算机视觉:让计算机学会“看”的学科,研究如何自动理解图像和视频中的内容。图像分类,目标检测,图像分割。
图像分类:经常也称为图像识别,识别图像中的物体是什么。比如扫一扫识物。
人脸检测:单个人脸检测。目标检测分为通用目标检测和特定目标检测。
计算机视觉应用场景:无人驾驶避障车道检测
动漫特效:图像生成,迁移
虚拟人物:人脸关键点检测 cg
视频理解和自动剪辑:
计算机视觉的发展:
早期萌芽(1960-1980)
统计机器学习与模式识别(1990-2000)
视觉特征
imageNet
初见成效的视觉系统(~2010)
深度学习时代(2012~)
AlexNet(hinton图灵奖获得者 图像分类),fast rcnn(目标检测)
时至今日(~)
文字描述生成图片,视觉大模型,神经渲染 citynerf。
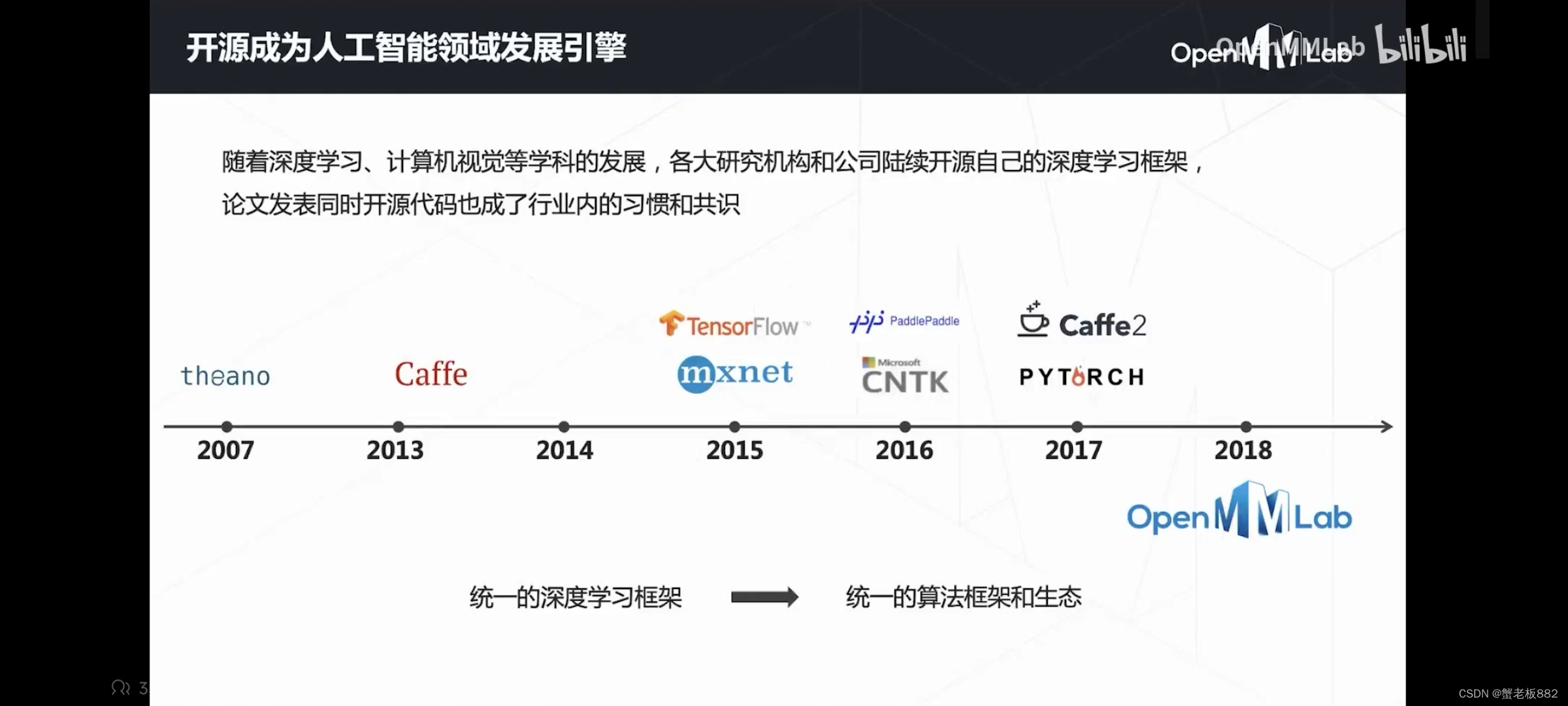
各大开源深度学习框架:
二、openMMLab算法体系
总体现状:一个统一先进的底层架构;20+计算机视觉研究方向;300+经典、前沿算法;2000+预训练模型。
开源历程:2018~
总体架构概览:
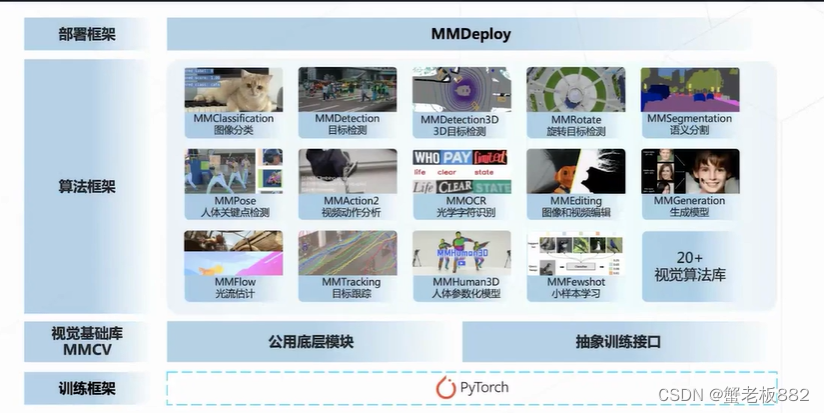
算法训练-部署一体化:MMDeploy库部署各种设备上
算法框架介绍:
MMDetection:目标检测、实例分割、全景分割(基于实例分割,+背景分割)
MMDetection3D:3D目标检测
MMClassification:图像分类;具有丰富的模型库(VGG、ResNet、...)
MMSegmentation:图像分割;无人驾驶、遥感、医疗影像
MMPose&MMHuman3D:人体分析(2D/3D、图像/视频、形状/关键点、全身/人脸/人手)
MMTracking:追踪(视频物体检测、单目标追踪、多目标追踪)
MMAction2:视频行为理解(行为识别、时序动作识别、时空动作识别)
MMOCR:文本检测和文字识别
MMEditing:图像像素处理(图像修复、抠图、超分辨率、图像生成)
OpenMMLab 2.0,更强
三、机器学习及神经网络基础
机器学习基础
机器学习:从数据中学习经验,以解决特定问题
监督学习:数据之间存在某种关系,如何基于样本推断关系?有标签。
无监督学:数据自身是否存在某种规律?无标签。
自监督学习:
强化学习:如何和环境交互,以获得最大利益?自适应环境。
机器学习的分类问题

机器学习流程:训练(采集数据、标注数据、训练数据)、验证(训练集、测试集、验证集)、应用(部署到实际业务系统)
以下关于神经网络就简单过了一遍,没有具体做笔记。
神经网络结构
线性分类器无法拟合曲线,神经网络属于非线性;
神经网络训练
卷积神经网络
为什么需要CNN?——参数量大、没有考虑图像本身的二维结构
卷积神经网络:卷积层和池化层、全连接层
pytorch环境配置与基础使用
pytorch官网
pytorch基本模块:
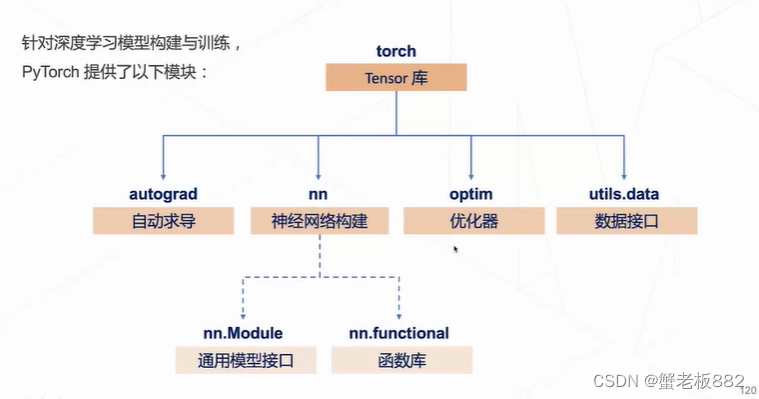
torch库:
多维数组的数据结构tensor(0维就是标量、1维就是向量、2维就是矩阵(一页纸)、3维就是很多矩阵叠在一起(很多纸叠在一起,一本书)、4维就是一本本书叠在一起,一层书,5维就是很多层书,书柜。
多维数组的运算
多计算后端支持
torch.autugrad自动求导: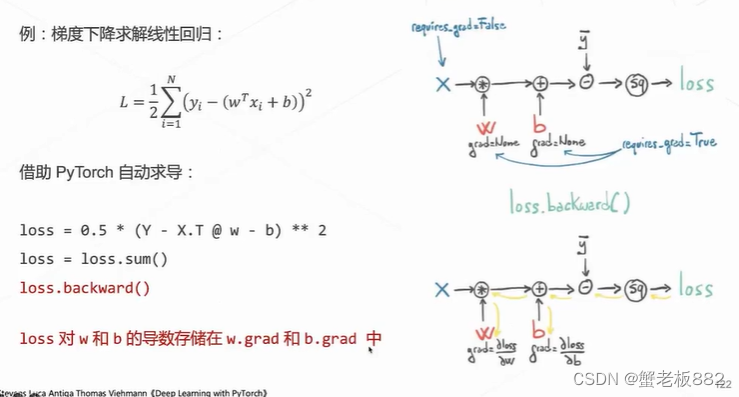
torch.nn.functional 函数库:

torch.nn.Module 通用模型封装:
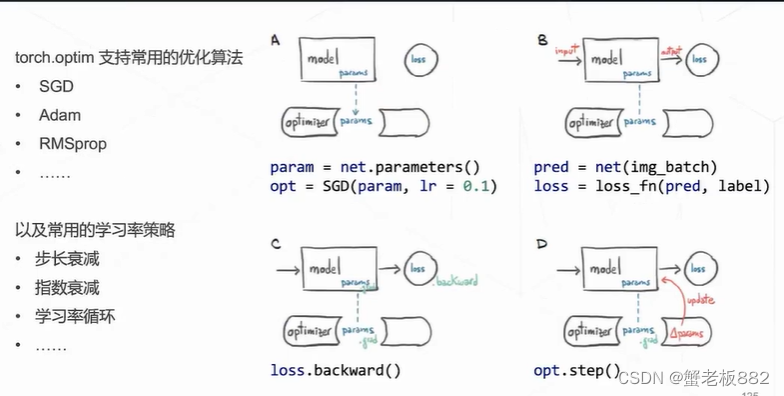
torch.optim 优化器:
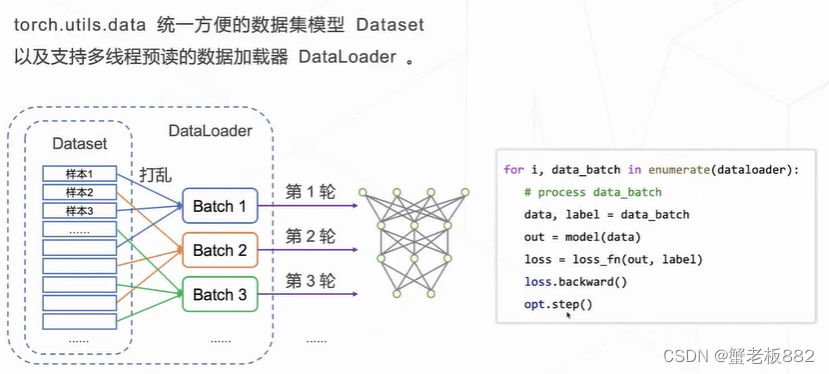
torch.utils.data 数据工具:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律