高性能队列设计
本文已整理致我的 github 地址 https://github.com/allentofight/easy-cs,欢迎大家 star 支持一下
这是一个困扰我司由来已久的问题,近年来随着我司业务的急遽发展,单表数据量越来越大,这样会导致读写性能急遽下降,自然而然的我们想到了分库分表,不过众所周知分库分表规则比较复杂,而且业务代码可能需要大改(由于数据分布在不同的库表里,业务需要判断到底去哪些表取数,并且取完后需要将数据再聚合在一起返回前端),所以经过横向对比我们采用了阿里开源的分库分表中间件 Cobar,这样的话一来 Cobar 根据我们设定的规则分库分表了,二来原来调用 SQL 的地方只需改成调用 Cobar 即可,Cobar 会自动根据我们写的 SQL 去各个分库分表里查询并将结果返回给我们,我们业务层的代码几乎不需要改动(即对应用是透明的)
如图示:使用 cobar 进行分库分表后,可以看到业务代码几乎不需要改动
所以问题是?
使用 Cobar 确实解决了分库分表和对业务代码侵入性的问题,但由于又引入了一个中间层,导致可用性降低,为了防止 Cobar 不可用等造成的影响,我们需要监控 Cobar 的各项性能指标,如 SQL 执行时间,是否失败,返回行数等,这样方便我们分析 Cobar 的各项指标,这就是我们常说的 SQL 审计(记录数据库发生的各种事件),那怎么样才能高效记录这些事件而又不对执行业务代码的线程造成影响呢?
要记录上报这些审计事件,肯定不能在执行业务代码的线程里执行,因为这些事件属于业务无关的代码,如果在业务线程里执行,一来和业务代码藕合,二来如果这些审计事件传输(记录审计事件总要通过磁盘或网络记录下来)遇到瓶颈会对正常的业务逻辑造成严重影响。我们可以修改一下 cobar 代码,在 cobar 里的执行逻辑中拿到这些事件后,把这些事件先缓存在队列中,让另外的线程从这些队列里慢慢取出(消费),然后再将这些数据上报,这样业务线程可以立即返回执行其他正常的业务逻辑。
2 (1) 注:虚线部分为对 cobar 中间件的改造,业务调用是无感知的 如图示,主要步骤如上图所示
客户端请求后执行 cobar cobar 执行后将「执行时间」,「是否失败」,「返回行数」等写入队列 写入队列后业务线程立即返回,然后可以执行正常的业务逻辑 后台线程则不断取出 event 通过 UDP 传给另外一个机器,写入 kafka 进行上报
小伙子不错啊,一看这架构图就知道有点东西,但我这里有点疑问,在第二步中,为啥不把 SQL 审计的那些指标直接写入 kafka 呢,如下
kafaka 不是号称写入性能可达几十甚至上百万吗,像上述这样实现架构上实现不是更简单吗
这是个很好的问题,有以下两个原因
我们是对 cobar 工程本身进行修改,然后将其打成 jar 包再集成到应用程序中来的,如果采用上面的设计,那就意味着要在 cobar 工程中引入对 kafka 的依赖,而我们只想对 cobar 作少量的修改,不想依赖太多第三方的库 这也是最重要的,引入 kafka 本身会导致可用性降低,有可能会阻塞业务线程,在 kafka Producer 中,设计了一个消息缓冲池,客户端发送的消息首先会被存储到缓冲池中,同时 Producer 启动后还会启动一个 sender 线程不断地获取缓冲池中的消息将其发送到 Broker 中 如图示,我们在构建 kafka producer 时,会有一个自定义缓冲池大小的参数
buffer.memory,默认大小为 32M,因此缓冲池的大小是有限制,那如果这个缓存池满了怎么办,RecordAccumulator 是 Kafaka 缓冲池的核心类,官方对其注释写得非常清楚The accumulator uses a bounded amount of memory and append calls will block when that memory is exhausted, unless this behavior is explicitly disabled.
也就是说如果缓存池满 了,消息追加调用将会被阻塞,直到有空闲的内存块,这样的话只要 Kafka 集群负载很高或者网络稍有波动,Sender 线程从缓冲池捞取消息的速度赶不上客户端发送的速度,就会造成客户端(也就是 Cobar 执行线程)发送被阻塞,这样的话可能导致线上几乎所有接口调用雪崩,系统不可用,导致严重的灾难!
而原来的设计看似复杂,但实际上符合软件设计中的分层原则,这样的设计有两个好处,如下图示:
首先 Cobar 执行线程将审计信息丢给队列后立即返回,我们只要设计这样的不阻塞高效的队列即可 后台线程取出后通过 UDP 传给另外的 agent,Cobar 执行线程所在的 JVM 和 agent 的 JVM 是不同的(毕竟部署在不同的机器上),做到了 JVM 的隔离,也更安全
小伙子果然有两把刷子,单独拎出上图的 cobar 执行线程与后台线程通过队列通信的模块,可以看到它就是个典型的生产者消费者模型
所以现在问题的关键就转化为如何设计这样的队列了,它要满足两个条件
cobar 执行线程写入队列无论如何都不会阻塞 写入队列要足够快(吞吐率要高),毕竟我司是大厂,巅峰期可能会达到每秒几万的 QPS
没错,不愧是大佬,一眼看透问题的本质,只要能设计好这样的队列,所有问题就迎刃而解了
恩,那你就来谈谈如何设计这样的队列吧。
虽然我心中已经有数,但为了展示我高超的
吹牛对队列熟练运用的能力,我决定由浅入深地来讲解一下队列的演进史,这样可以把队列的选型了解得明明白白
你高兴就好。
高性能队列的实现思路
1.队列的表示:数组 or 链表?
队列(Queue)是一种线性表,是一种先进先出的数据结构,主要由数组和链表组成,队列只允许在后端(称为 rear)进行插入操作,在前端(称为 front)进行删除操作
这两者优缺点都很明显,但总的来说数组的执行效率更高,为啥,这里简单介绍下 CPU 的运行原理,由于内存太慢,所以在 CPU 和 内存间设置了多道缓存(L1,L2,L3三级缓存,其中 L1,L2 缓存为每个 CPU 核独有的, L3是共享的)以提升 CPU 的执行效率,CPU 执行取数时,先从 L1查找,没有再从 L2查找,L2 没有则从 L3,查找,L3还是没有的话就会从内存加载。
但需要注意的是,CPU 从内存加载数据时并不是以字节为单位加载,它是以 cacheline 的形式来加载的,cacheline 是从内存加载或写入的最小单位,在 X86 架构中,一个cacheline 由内存里连续的 64 个 byte组成的,而数组是在内存里连续分配的,所以它一次性能被加载多个数据到 cache 中,而链表中 node 的空间是分散在非连续的内存地址空间中,所以总的来说数组由于利用了 cache line 的连续加载特性对缓存更友好,性能会更好。
链表对扩容更友好?
这应该是不少人支持使用链表的一个重要原因了,如果空间不够大,需要扩容怎么办,对于链表来说,很简单,在 rear 结点后新增一个节点,将 rear 结点的 next 指针指向它即可,非常方便,但对于数组来说就没那么容易了,它需要先生成一个原来 n(一般是 2) 倍大小的新数组,再把老数组里的数据给移过去,如下图所示
如果光从扩容这一角度来看,确实链表更优秀,但我们不要忘了消费者消费完后是要把链表对应的节点给释放掉的,在高并发下,就会造成频繁的 GC,造成严重的性能影响
估计有人就会反驳了,如果数组中的元素被消费完了,难道不要被移除?这样的话岂不是也会存在高并发下的频繁 GC?总不能一开始给这个数组分配一个无限大的空间吧,这样的话就成了无界队列,这样的话还没等你数组填满就 OOM 了。
这是个好问题,实际上对于数组来说,我们可以使用一个小 trick,既可以让它变成有界(即固定大小,无需扩容)数组,也可以避免频繁 GC,更可以避免数组扩容带来的性能问题,怎么做,将线性数组改造成循环数组(RingBuffer)
如图示,假设数组的初始化大小为 7,当生产者把数组的七个元素都填满时(此时 0,1,2三个元素已经被消费者消费完了),如果生产者还想再填充数据,由于 0,1,2对应的三位元素已经被消费了,属于过期无效的元素了,所以生产者可以从头开始往里填充元素,只要不超过消费者的进度即可,同理,如果消费者对应的指针达到数组的末端,下一次消费也就回到数组下标 0 开始消费,只要不超过生产者进度即可。
我们将将数组的首尾拼接就形成了一个 ringbuffer
有人会说绕圈了怎么定位数组的具体下标?对数组大小取模即可,生产者/消费者对应的数组下标都是累加的,以以上情况为例,当前生产者的下标为 6,下一个下标就是 7,而当前数组大小为 7,于是 7 对应的数组下标即为 7%7 = 0,与实际相符。但需要注意的是取模操作是个很昂贵的操作,所以我们可以用位运算来代替,但位运算要求数组的大小为 2^n(想想为什么),于是取模操作可以用 index & (2^n -1 ) 来代替(index 为 生产者/消费者对应的下标)。
综上,设计一个这样大小为 2^n(这里有两层含义,一是大小为 2^n,二是数组有界) 且由数组表示的 ringbuffer 有「对缓存友好」,「对 GC 友好」两个重要特性,在高并发下对性能的提升是非常有帮助的。
2. 无锁
只选好 ringbuffer 是不够的,在高并发下,多个生产者/消费者极有可能争用 ringbuffer 的 同一个 index,如下图示:
为了避免这种情况,最容易想到的是加锁,但显然加锁会存在严重的性能问题:
线程如果争用不到锁失败,会阻塞(由用户态进入内核态),唤醒时又会从内核态进入用户态,我们知道这种不断地在用户态和内核态间进行切换的操作是非常昂贵的
线程 cache miss 的开销,一开始线程可能被分配在 cpu core 1 上,但经过阻塞,唤醒后又被调度到了 cpu core 2 上,导致原来在 core 1 上加载的缓存无用武之地, 线程在 core 2 又得重新从内存加载数据
如果业务线程被阻塞了,那很可能出现对应的服务都无法使用的情况(毕竟业务线程负责接收返回用户的请求),会造成严重的线上问题
综上所述使用锁是不行的,一种有效的方式是使用 CAS 自旋不断尝试获取对应的 index,这种方式也就是我们所说的无锁的方式

也许有人担心 CAS 性能比较低,我们可以用 JDK 8 之后对 atomic 类引入的 unsafe 的 getAndAddInt 方法来替换,如下:
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
它使用的是 CPU 的 fetch-and-add 指令,性能上比 CAS 要强很多(实测是 6 倍于 CAS 的性能,见文末参考链接),skywalking 的队列就是用的 getAndInt 来代替 CAS,达到了很高的性能。
不愧是通过了我们简历筛选的男人,那么 JDK 里的内置队列能否符合这样的条件呢
不能,我们先来看看 JDK 内置队列有哪些,以及它们有哪些特点
image-20210621091619682 可以看到,最接近高性能队列「有界环形数组」和「无锁」这两个特性的只有 ArrayBlockingQueue 这一个队列,但很可惜它是有锁的,而且它是生产者和消费者共用同一把锁(可重入锁 Reentrantlock),这意味着生产与消费无法同时进行,显然无法满足我们的要求。我们可以对 ArrayBlockingQueue 进行改造,把此锁干掉,用无锁比如 CAS 的方式来实现,这样不就解决了吗,高性能队列 disruptor就是这么干的
小伙子果然不错,居然用过 disruptor,看得出来你对 disruptor 还挺了解的,说得头头是道,那我考你两个问题,这两个问题如果答得不错,直接发 offer
disruptor 确实满足了你说的「使用了大小为 2^n 的 ringbuffer 数组」和「无锁」两个特性,除此之外它还利用了哪些优化的点,在我看来你的这两个点确实重要,但最关键也是我最在意的一个点还没有提到 disruptor 是阻塞的吗,也就是说如果 ringbuffer 满了会不会阻塞向 ringbuffer 投递事件的业务线程
第一题,disruptor 在初始化的时候为数组填充了所有事件类对象,这些对象不会消亡,也就避免了 GC,不同的事件只是值不一样而已,所以新增的事件会复用数组中的对象,只是将其属性值修改而已,另外这么做还有一个好处:避免 CPU 在高并发时分配大量的对象造成 CPU 飙升
第二题,是阻塞的,所以如果要把 disruptor 应用到我们开头的设计架构中,可能 cobar 执行线程会有阻塞风险,想要不阻塞可以使用 skywalking 的队列,它是非阻塞的,性能也很给力(正常 cobar 压测5.5w/s,而用 skywalking 的队列只损失 1.8%,可以接受)
第一题你的回答是没问题的,但不是我想要的答案,我给你提示一下,在 ArrayBlockingQueue 中,连续定义了这三个变量
/** items index for next take, poll, peek or remove */
int takeIndex;
/** items index for next put, offer, or add */
int putIndex;
/** Number of elements in the queue */
int count;在多线程的情况下会发生什么?
第二题回答完全错误,实际上 disruptor 是有非阻塞方法的,你用它的话性能几乎没有损失 (disruptor 最大特点是高性能,其 LMAX 架构可以获得每秒6百万订单,用1微秒的延迟获得吞吐量为 100K+)
你看看,明明可以用更好的 disruptor,却要用损失了性能 1.8% 的次优队列,很遗憾,这次面试就到此为止吧,不过鉴于你之前的表现不错,也让我转身了,我不妨指点你一下,log4j2 也用了 disruptor,你想想 log4j2 是如此常见的组件,是各大公司的标配,如果日志生产的 ringbuffer 队列满了,按你的说法岂不是会影响业务线程?建议回去好好研读下 log4j2 还有 disruptor 的源码,半年后再见

少扯这些没用的,好好回去修炼内功吧,慢走不送


小伙子,又见面了,上次临走时问的两个问题思考的如何了
第一个问题,按大佬的提示我查阅了一些资料,其实大佬想听的是伪共享和缓存行填充吧
确实如此,那你给我解释下什么是伪共享,又是如何用缓存行填充来解决伪共享的呢
在前文中我们已经知道了 cacheline 的原理,内存的最小读取和写入单元是 64 字节的 cacheline,而 ArrayBlockingQueue 的如下三个属性是连接定义的,
int takeIndex;
/** items index for next put, offer, or add */
int putIndex;
/** Number of elements in the queue */
int count;表现在内存中就是连续分配的空间,这样的话它们极有可能一起作为一个 cacheline 加载到 cache 中
假设线程 A 执行入队操作,就会修改 putIndex,根据 CPU 的缓存一致性协议(如 MESI 协议),修改 putIndex 会导致其所在的 cacheline 都失效,此时假设线程 B 执行出出队操作,需要读取 takeIndex,但由于其所在的 cacheline 已经失效,所以 CPU-2 必须重新去内存中读取 takeIndex 所在的 cacheline,而我们知道 CPU 中的三级缓存与内存效率相差几十上百倍,这样的话在多线程环境下由于 cacheline 频繁失效毫无疑问会造成严重的性能问题,这就是我们所说的伪共享。

恩,解释得不错,那怎么解决呢
解决方式就要按大佬所说的缓存行填充来解决,在 takeIndex, 前后添加 7 个 long 类型的属性变量,就可以保证 takeIndex 和 putIndex 不在同一个 cacheline 上了,这样针对 takeIndex 和 putIndex 的修改就不会互相影响对方了
3

不错,能否举例一下 disruptor 中对缓存行填充以避免伪共享的问题,在 disruptor 用到很多这样的例子
我们先来看下 ringbuffer 的定义
abstract class RingBufferPad
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields<E> extends RingBufferPad
{
private final long indexMask;
private final Object[] entries;
protected final int bufferSize;
protected final Sequencer sequencer;
}
public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E>
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
可以看到在 RingBufferFields 前后分别填充了 7 个 long 类型的变量,这 14 个变量没有任何实际用wt途,只是用来做缓存行填充之用。
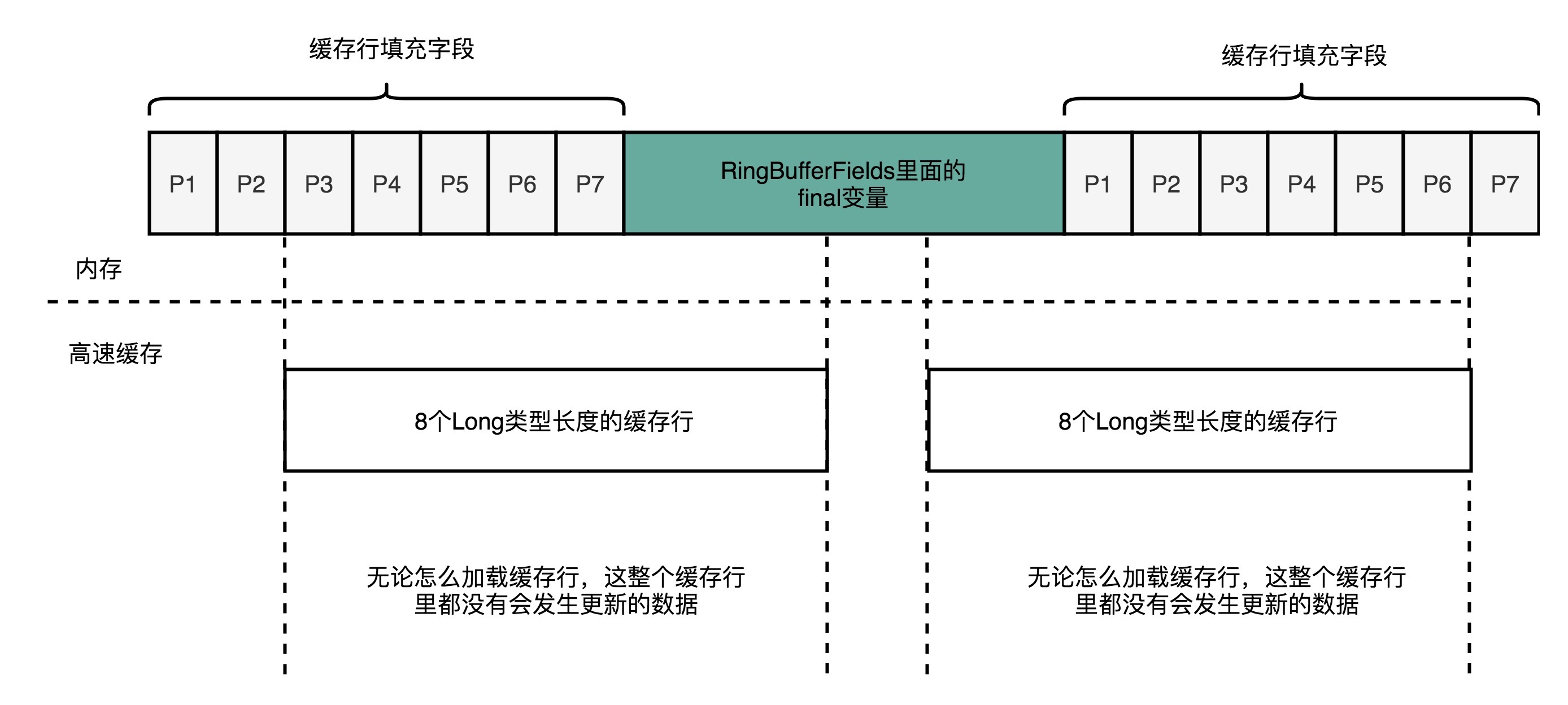
可以看到填充之后无论怎么加载缓存行,缓存行都没有要更新的数据,另外注意到 RingBufferFields 里面定义的变量都是 final 的,意味着第一次写入之后就不会再被修改,也就意味着一旦加载入 CPU Cache 中,就不会被换出 Cache 了,也就是说这些值都一直会是 CPU Cache 的访问速度,而不是内存的访问速度
第一个问题过关了,接下来说说第二个问题吧, disruptor 的队列满了之后会阻塞业务线程吗
disruptor 的 ringbuffer 提供了两个方法,一个是 publishEvent,这个方法如果在 ringbuffer 满了之后继续往里添加事件是会阻塞的,而另一个 tryPublishEvent 方法则不会,队列满了之后会返回 false,业务线程还是可以继续执行滴,log4j2 就是用了这个方法这样根据其返回值为 false 即可判断 ringbuffer 满了,我们就可以做相当的处理了(比如丢弃 log 事件)
看得出来小伙子确实用心读了源码,过去半年表现进步明显哦,恭喜你顺利进入二面
总结
disruptor 是 LMAX 公司开源的一款高性能队列,每秒支持 600w 的吞吐量,相当于用 1 微秒的延迟就获取了 100K+ 的吞吐量,性能极高,简单总结一下它主要用到了以下三个手段:
环形数组:ringBuffer,由于数组在内存空间中是连续分配的,而内存换入换出的最小单元是 64kb 的 cacheline,所以一次性会把数组的多个元素写入 CPU Cache 中以提高效率,另外对数组的大小是有要求的,为了支持位运算取模以提高效率,必须将数组大小设置为2^n。 数组对象预填充,在 disruptor 初始化时为就为数组的每个坑位都初始化填充了事件对象,这些对象不会消失也就避免了频繁 GC,之后生产者要新增事件对象,也会复用相应坑位的事件对象,只是修改其对象属性而已,通过预分配对象的方式,避免了高并发下频繁分配对象导致的 CPU 和内存飙升。 缓存行填充避免伪共享,这也是 diruptor 最大的亮点,在 disruptor 中你可以看到很多这样的例子,利用缓存行填充可以保证不会造成 cacheline 失效从而造成频繁从内存读取导致的性能瓶颈 使用 CAS 自旋而不是 Reentrantlock 这样重量级锁来获取生产者/消费者的 index,避免了锁的开销,提升并发能力。 使用 volatile 而不是锁来修改同一个变量,在 disruptor 中生产者会竞争数组的 index 坑位(用的 Sequence类的 value 值),disruptor 使用了 volatile 而不是锁来保证了变量的可见性
另外 disruptor 提供了阻塞(publishEvent) 和非阻塞(tryPublishEvent)两种方法,针对我们文章开头 cobar 的使用场景,建议使用 tryPublishEvent 这种非阻塞的方式来向 ringbuffer 投递事件,不然一旦阻塞会导致线上 cobar 执行线程停顿的重大故障!
disruptor 到底有多强悍,可能看听数据大家没有感觉,那我们来看一张针对 log4j2 的压测图

log4j2 总共有三种工作机制,全局异步(Loggers all async),Appender 异步( Async Appender)以及同步(Sync),可以看到全局异步最快,几乎是 Appender 异步的 10 倍以上,为什么同样提异步,性能相差这么大,因为全局异步用的是 disruptor ,而 Appender 异步用的是 ArrayBlockingQueue,可以看到 disruptor 被称为高性能队列之王的名头可不是盖的。
另外除了 disruptor,大家也可以看看 skywaking 的队列,它的性能虽然没有 disruptor 这么强,但对一般的业务场景也是足够的(在我司 cobar 压测 5.5w/s,使用了 skywalking 后仅损失了 1.8%,也是很强悍的),它也是阻塞的,另外它在队列满的时候可以选择「阻塞」,「覆盖」,「忽略」三种策略,我们选择了覆盖。
更多精品文章,欢迎大家扫码关注「码海」

 浙公网安备 33010602011771号
浙公网安备 33010602011771号