Python二十行代码实现hexo的md文件格式解析
最近用django+Vue实现了一个博客应用,原来的hexo的博客用着也挺好,想继续留着用,于是就想将hexo生成的.md的博客内容文件解析后直接写到django的博客数据库里做同步显示。
hexo生成的.md文件内容主要分两部分,一部分是博客的信息、一部分是博客内容,博客信息包括标题、目录、标签、发布日期等,博客内容就是具体博客写的内容主体了。
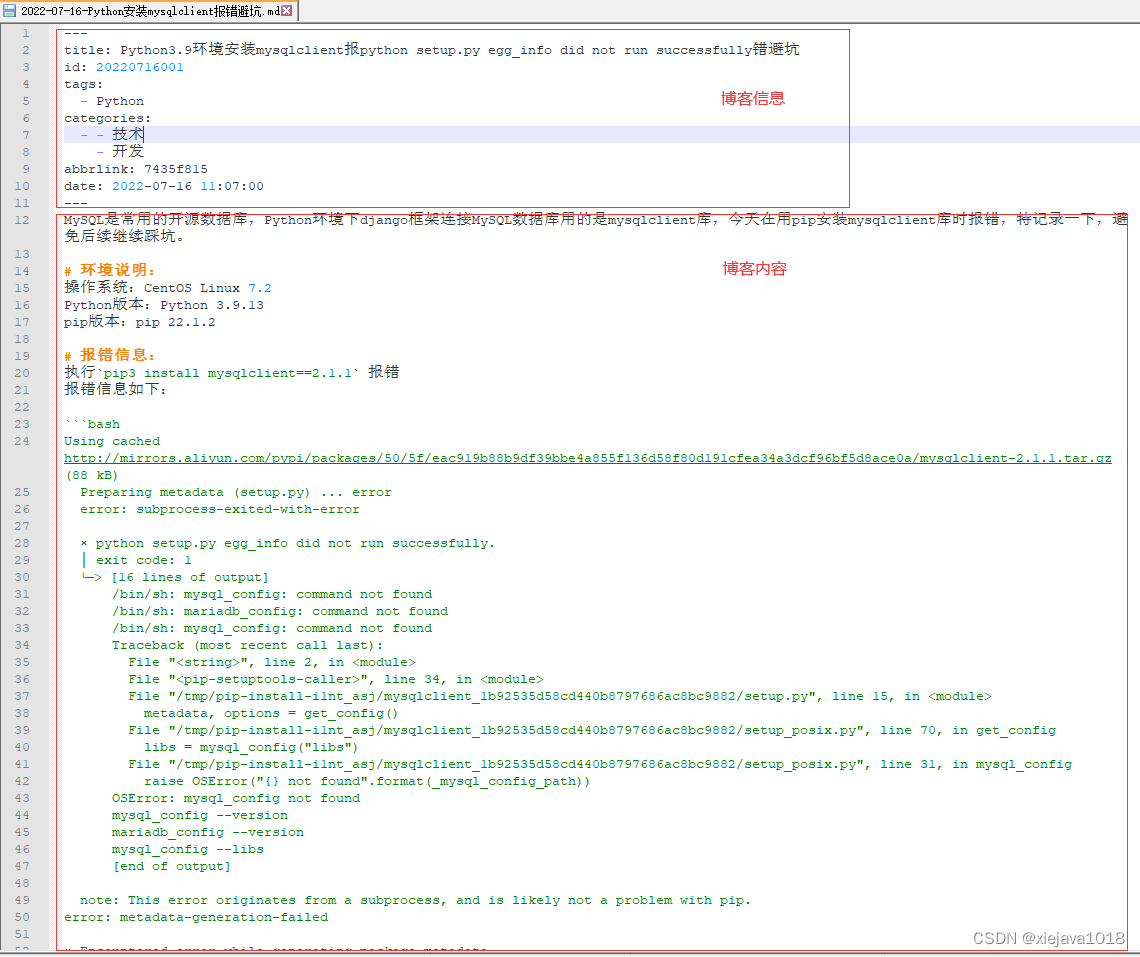
其中博客信息通过"—“来区分,夹在两个”—“块之间。博客的信息是yaml来描叙的需要解析并提取出相应的字段及内容,博客内容就更简单了直接是markdown描叙的不需要再解析了。
这里要做的事情就是提取两个”—“符号之间的内容,并解析相应的字段,提取两个”—"符号后面的内容作为博客的内容,形成字典,便于后面的入库。
代码示例如下:
yaml的解析可以直接用Python的PyYAML库
pip install PyYAML
# -*- coding: utf-8 -*-
"""
:author: XieJava
:url: http://ishareread.com
:copyright: © 2021 XieJava <xiejava@ishareread.com>
:license: MIT, see LICENSE for more details.
"""
import yaml
'''将md文件转成blog对象'''
def parseblog(blog_md_file):
#读md文件
md_f = open(blog_md_file, "r",encoding='utf-8')
md_f_str=md_f.read()
#解析两个---之间的内容
pattern='---'
blog_data={}
pattern_list=list(pattern_search(md_f_str, pattern))
if len(pattern_list)>=2:
blog_info_str=md_f_str[pattern_list[0]+len(pattern):pattern_list[1]]
blog_data=yaml.load(blog_info_str,Loader=yaml.SafeLoader)
blog_data['content']=md_f_str[pattern_list[1]+len(pattern):]
md_f.close()
return blog_data
'''分割符号匹配检索'''
def pattern_search(string,pattern):
index=0
while index<len(string)-len(pattern):
index=string.find(pattern,index,len(string))
if index==-1:
break
yield index
index+=len(pattern)-1
if __name__ == '__main__':
blog_data=parseblog('E:\\CloudStation\\personal\\xiejavablog\\myhexo\\myblog\\source\\_posts\\2022-07-19-Vue3解析markdown解析并实现代码高亮显示.md')
print(blog_data)
效果:
可以看到hexo的md文件正确解析出来,形成字典。后续可以直接进行入库操作了。

Python的库还是很丰富实用的,用Python二十行代码就实现hexo的md文件格式解析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号