AI机器学习时序序列特征提取实现分类预测实战
最近有位做医疗项目的同学咨询有一批人员的身高、体重、性别、年龄、心电图、是否有心脏病等数据是否可以根据这些数据预测某个人是否有心脏病的迹象。这当然是可以的,AI机器学习不就是干这事的吗?这是一个典型的分类算法。根据这些人体特征来判断是否存在潜在的疾病。问题是如何对心电图进行特征提取,提取出相关的特征,让模型进行学习和训练。
拿到数据后,第一步,我们首先来看一下数据。
一、数据探索
1、读入数据
导入numpy、pandas、matplotlib三大件,读入数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_csv('data_csv.csv')
df
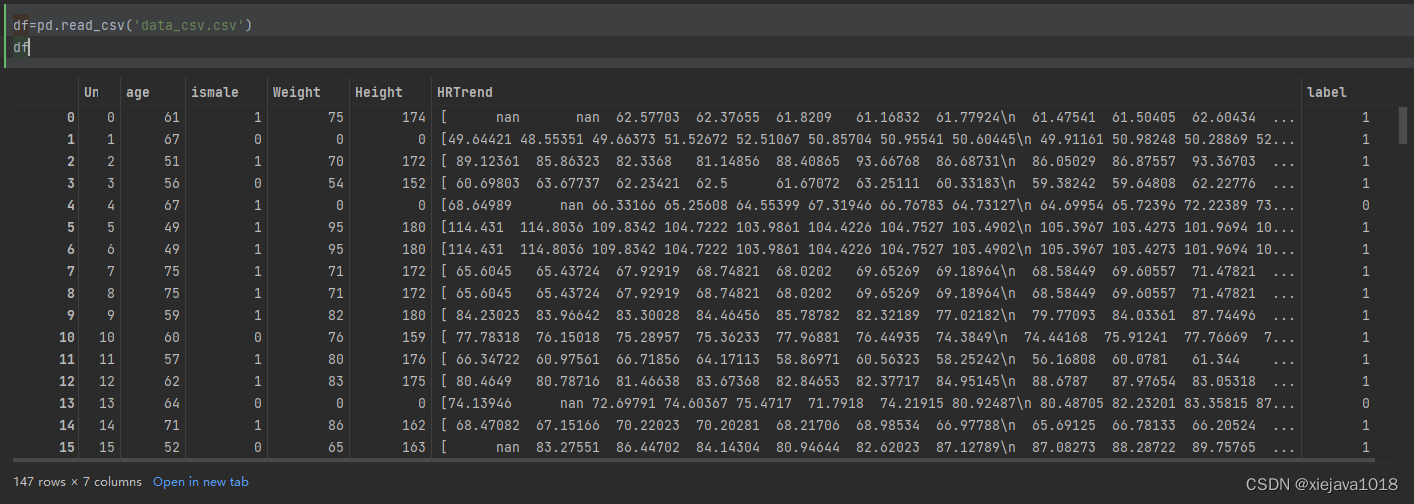
数据集中有age年龄、ismale性别、Weight身高、Height体重、HRTrend心电图、label是否有心脏病(1,是有心脏病、0是无心脏病)
这里看到主要的几个关键性的指标。HRTrend是csv中载入的时候数据是文本字符串格式,还有nan及\n等字符串,我们要将这些数据进行清洗规则化,将其转化为数组。
2、数据处理
先拿一个样本数据来看看数据的情况。对它进行相应的处理,包括去掉回车换行符、去多余空格、然后以空格作为分隔形成数组。
HRTrend_Data=df['HRTrend'][1][1:len(df['HRTrend'][1])-1]
HRTrend_Data=HRTrend_Data.replace('\n','') #替换掉换行符
HRTrend_Data=HRTrend_Data.replace('nan',str(0)) #将nan补0
HRTrend_Data=re.sub(' +', ' ', HRTrend_Data).strip() #去掉多余的空格
HRTrend_Data=np.asarray([float(s) for s in HRTrend_Data.split(' ')]) #将字符串通过空格分隔,转换成数组
pd.DataFrame(HRTrend_Data).plot()
HRTrend_Data
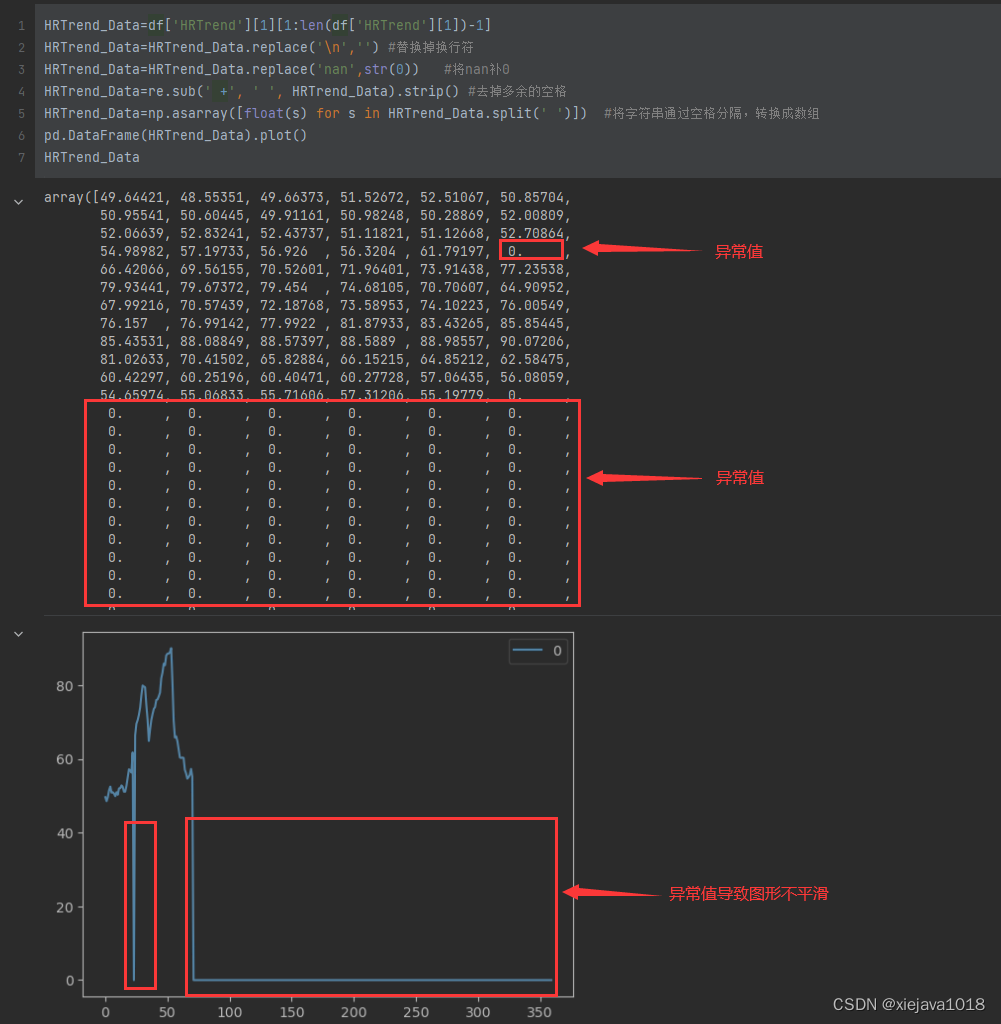
这个图形不是很规则不平滑,看数据是因为异常值太多,后面的数据都是0,这些0都是因为数据为Non补充进来的,有可能是应为数据采集的时候某个点位没有采集到。我们需要将这些异常值给处理掉。
对于中间为0的,我们可以通过采用前值填充或者后值填充(也就是用前面的值或后面的值来替代为0的值),后面全部为0的部分要去掉。因为会影响到一些关键性的特征,如均值、50%的值、70%的值等。
df_HRTrend1=pd.DataFrame(HRTrend_Data)
df_HRTrend1.describe()
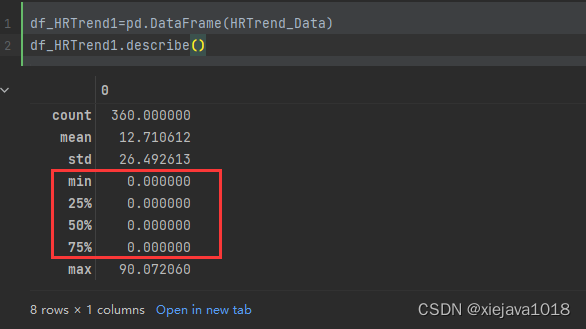
可以看到,这些异常值将会很大程度的影响一些关键特征,所以我们要处理异常值。
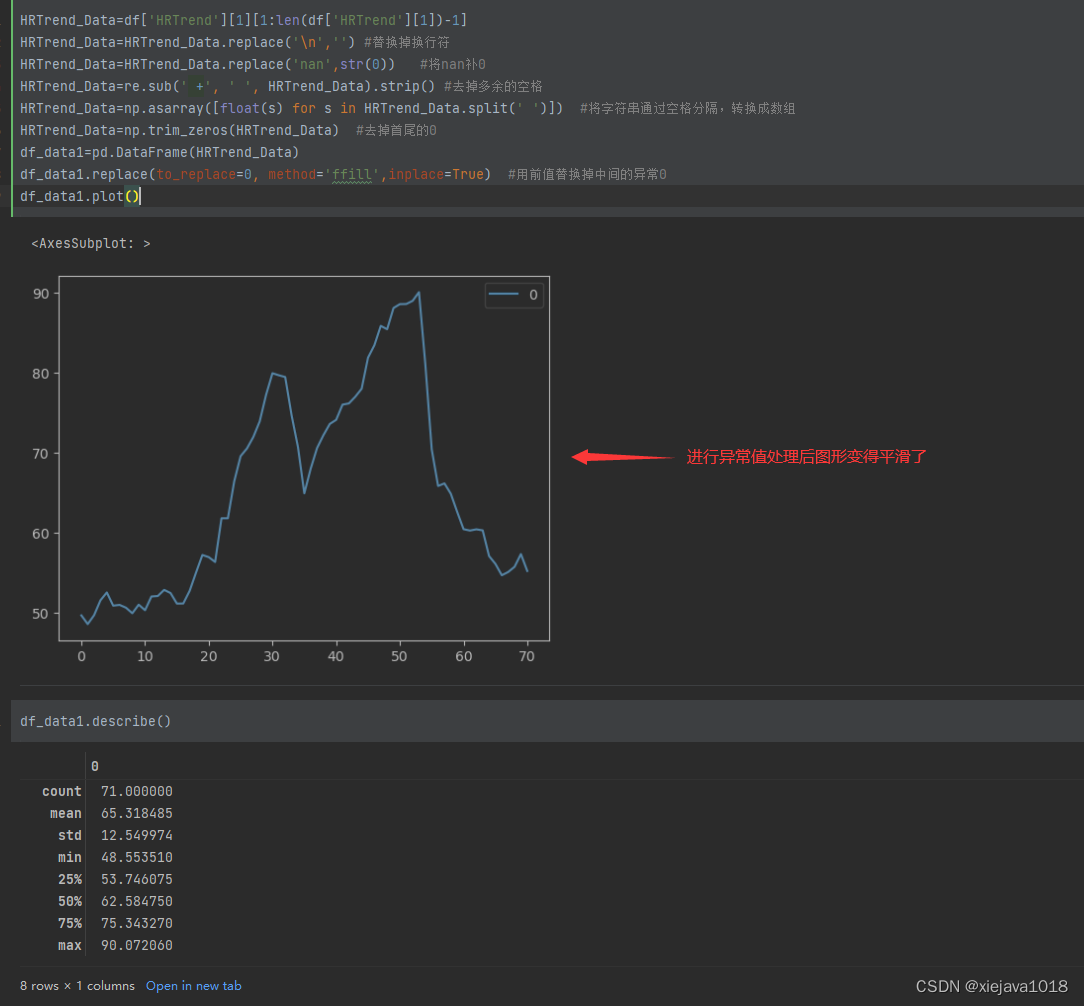
HRTrend_Data=np.trim_zeros(HRTrend_Data) #去掉首尾的0
df_data1=pd.DataFrame(HRTrend_Data)
df_data1.replace(to_replace=0, method='ffill',inplace=True) #用前值替换掉中间的异常0
df_data1.plot()
df_data1.describe()
把刚对一个样本处理的过程写成一个函数,应用到所有的样本数据。
def procdata(df_dataclumn):
ary_data=df_dataclumn[1:len(df_dataclumn)-1]
ary_data=ary_data.replace('\n','')
ary_data=ary_data.replace('nan',str(0))
ary_data=re.sub(' +', ' ', ary_data).strip()
ary_data=np.asarray([float(s) for s in ary_data.split(
 浙公网安备 33010602011771号
浙公网安备 33010602011771号