3.pot地址写入和读取及电影爬取代码实现
爬虫-python+Qt -电影爬取代码实现
完整代码
'''
pip install lxml -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
'''
#1-导包QApplication:需要运行qt的gui程序,必须创建一个app对象
import signal
from multiprocessing import Process
from PySide2.QtWidgets import QApplication, QMessageBox
#2-导包QFile,需要打开一个ui文件
from PySide2.QtCore import QFile
#3-py代码需要加载ui文件到内存中
from PySide2.QtUiTools import QUiLoader#需要加载你设计的ui文件
import requests
import os
from lxml import etree
from PySide2.QtCore import QStringListModel
import subprocess
import shutil
import threading
import psutil
#获取xpath
def content_xpath(html):
content=html.content.decode('utf-8')
return etree.HTML(content)
class Nmplayer:
def __init__(self):
super(Nmplayer, self).__init__()
#设置UI文件只读
qfile=QFile('nmgksearch.ui')
qfile.open(QFile.ReadOnly)
qfile.close()
#加载UI文件
self.ui =QUiLoader().load(qfile)
#设置默认窗体大小
# self.ui.resize(500,800)
#绑定UI事件
self.ui.potbutton.clicked.connect(self.get_pot_path)
self.ui.searchbutton.clicked.connect(self.get_main_html)
self.ui.searchedit.returnPressed.connect(self.get_main_html)
self.ui.resultslist.doubleClicked.connect(self.choose_movie)
self.ui.episodelist.doubleClicked.connect(self.choose_episode)
self.ui.playallbutton.clicked.connect(self.play_all_episode)
self.ui.clearbutton.clicked.connect(self.clear_source)
#初始化参数
self.pot_path = self.ui.potedit.text()
self.get_pot_path()
self.search_url='https://www.nmgk.com/index.php?s=vod-s-name'
self.mother_url='https://www.nmgk.com/'
self.headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'
}
self.search_name=''
self.results_name=[]
self.results_update=[]
self.results_href=[]
self.s=''
self.pic_path='./images/'
self.movie_info=''
self.episode_name=[]
self.episode_href=[]
self.m3u8_url=''
self.play_all_string=''
self.pre_html=''
def send_requests(self,req):
# 创建一个会话
self.s = requests.Session()
# 获取请求前数据
prepare = self.s.prepare_request(req)
self.pre_html = self.s.send(prepare)
return self.pre_html
#首页多线程发送请求
def main_thread(self):
thread1 = threading.Thread(target=self.get_main_html)
thread1.start()
#首页多线程发送请求
def choose_movie_thread(self):
thread2 = threading.Thread(target=self.choose_movie)
thread2.start()
def get_pot_path(self):
self.pot_path=self.ui.potedit.text()
#如果文件不存在,就创建并写入
if not os.path.exists('pot.config'):
with open('pot.config','w') as f:
f.write(self.pot_path)
#有用户输入内容
elif self.pot_path !='':
with open('pot.config','r') as f :
read_path=f.readline()
#判断用户输入的是不是跟配置文件一致,如果不是以用户的为主
if read_path !=self.pot_path:
#删除原来的文件
os.remove('pot.config')
with open('pot.config','w') as f:
f.write(self.pot_path)
else:
with open('pot.config', 'r') as f:
self.pot_path=f.readline()
#回显输入地址
if self.pot_path:
self.set_placeholdertext()
def set_placeholdertext(self):
self.ui.potedit.setPlaceholderText(self.pot_path)
#1-搜索页
#发送请求获取搜索结果
def get_main_html(self):
#获取用户输入的搜索内容
self.search_name=self.ui.searchedit.text()
data ={
'wd':self.search_name
}
#发送搜索请求,返回结果,结果为一个网页
req = requests.Request(method='get', url=self.search_url,params=data,headers=self.headers)
main_pre_html=self.send_requests(req)
# main_pre_html=requests.get(url=self.search_url,params=data,headers=self.headers)
#获取xpath
print(self.pre_html)
main_html_xpath=content_xpath(main_pre_html)
#通过xpath定位获取名字,更新,链接
self.get_results(main_html_xpath)
self.show_results_list()
#获取搜索结果
def get_results(self,htmlx):
self.results_name=[]
results_name=htmlx.xpath("//div[@class ='itemname']/a/text()")
results_update=htmlx.xpath("//div[@class ='cateimg']/a/i/text()")
self.results_href=htmlx.xpath("//div[@class ='cateimg']/a/@href")
#构造展示效果,瑞克和莫蒂第四季-----10集全
for n ,u in zip(results_name,results_update):
result_str=n+'-----'+u
self.results_name.append(result_str)
#展示搜索结果,需要通过字符串列表模型这个类来设置,再通过模型来展示
def show_results_list(self):
qlist=QStringListModel()
qlist.setStringList(self.results_name)
self.ui.resultslist.setModel(qlist)
self.ui.resultslist.setToolTip('双击选择')
#2-详情页
# 双击搜索结果的记录进行选择,跳转到详情页面
def choose_movie(self,index):
#https://www.nmgk.com//vod/8314.html
movie_href=self.mother_url+self.results_href[index.row()]
#发送请求,获取详情页面的内容
req = requests.Request(method='get', url=movie_href, headers=self.headers)
movie_pre_html = self.send_requests(req)
#获取网页xpath结构
movie_html_xpath=content_xpath(movie_pre_html)
#获取图片
self.get_movie_pic(movie_html_xpath)
#回写图片
self.set_pixmap()
#获取描述并回写
self.get_movie_info(movie_html_xpath)
#获取集数及对应的链接
self.get_episode(movie_html_xpath)
#回写集数
self.set_episodelist()
#获取图片,生成图片文件
def get_movie_pic(self,htmlx):
#xpath回来是一个列表
movie_pic_pre_url=htmlx.xpath("//div[@class='video_pic']//img/@src")[0]
pic_name=movie_pic_pre_url.split('/')[-1]
movie_pic_url=self.mother_url+movie_pic_pre_url
self.pic_path +=pic_name
#发送请求,获取图片信息
req = requests.Request(method='get', url=movie_pic_url, headers=self.headers)
res_pic = self.send_requests(req)
#res_pic.content是一段字节码二进制文件
#./images/picname,把获取到的二进制文件生成图片存放到images下面
if not os.path.exists('./images'):
os.mkdir('./images')
with open(self.pic_path,'wb') as f :
f.write(res_pic.content)
#设置图片到页面展示
def set_pixmap(self):
self.ui.piclable.setPixmap(self.pic_path)
#获取描述
def get_movie_info(self,htmlx):
self.movie_info=htmlx.xpath("//div[@class='intro-box-txt']/p[2]/text()")[0]
self.ui.episodeinfo.setText(self.movie_info)
#获取集数名称和链接
def get_episode(self,htmlx):
self.episode_name=htmlx.xpath("//div[@id='ji_show_1_0']//div[@class='drama_page']/a/text()")
self.episode_href=htmlx.xpath("//div[@id='ji_show_1_0']//div[@class='drama_page']/a/@href")
#把集数名称回写到GUI中
def set_episodelist(self):
qlist=QStringListModel()
qlist.setStringList(self.episode_name)
self.ui.episodelist.setModel(qlist)
self.ui.episodelist.setToolTip('双击播放单集')
#3-播放页
#选择集数进行播放
def choose_episode(self,index):
episode_url=self.mother_url+self.episode_href[index.row()]
#根据选择的集数,发送请求获取信息
req = requests.Request(method='get', url=episode_url, headers=self.headers)
episode_pre_html = self.send_requests(req)
episode_html_xpath=content_xpath(episode_pre_html)
#获取页面的m3u8地址
self.get_m3u8(episode_html_xpath)
#通过m3u8地址进行播放
self.play_episode()
def get_m3u8(self,htmlx):
pre_m3u8 =htmlx.xpath("//div[@id='cms_player']/iframe/@src")[0]
self.m3u8_url =pre_m3u8.split('=')[-1]
#只打开一个播放器窗口进行播放
def play_episode(self):
try:
subprocess.Popen(self.pot_path+' '+self.m3u8_url + ' /autoplay')
except Exception as e:
QMessageBox.warning(
self.ui,
'请看提示',
'请确认是否输入播放器地址')
#把所有集数加入到播放器列表中
def play_all_episode(self):
#通过遍历发请求获取所有m3u8地址
try:
for href in self.episode_href:
total_url=self.mother_url+href
req = requests.Request(method='get', url=total_url, headers=self.headers)
episode_pre_html = self.send_requests(req)
episode_html_xpath = content_xpath(episode_pre_html)
self.get_m3u8(episode_html_xpath)
subprocess.Popen(self.pot_path+ ' ' + self.m3u8_url + ' /add')
except Exception as e:
QMessageBox.warning(
self.ui,
'请看提示',
'请确认是否输入播放器地址')
#清除缓存:清除images,清除播放器列表,关闭播放器
def clear_source(self):
if os.path.exists('./images'):
shutil.rmtree('./images')
# 清空播放列表D:\soft\PotPlayer\Playlist
playlist = os.path.dirname(self.pot_path) + '\Playlist'
if playlist:
print(playlist)
shutil.rmtree(playlist)
# subprocess.CompletedProcess(self.pot_path,returncode=1)
# print("----------------------------- show all processes info --------------------------------")
# # show processes info
# pids = psutil.pids()
# for pid in pids:
# p = psutil.Process(pid)
# # get process name according to pid
# process_name = p.name()
#
# print("Process name is: %s, pid is: %s" % (process_name, pid))
pids = psutil.pids()
for pid in pids:
p = psutil.Process(pid)
# get process name according to pid
process_name = p.name()
# kill process "sleep_test1"
if 'PotPlayerMini64.exe' == process_name:
print("kill specific process: name(%s)-pid(%s)" % (process_name, pid))
os.kill(pid, signal.SIGINT)
#这个方法会弹出cmd命令黑框
# process_name=self.pot_path.split('\\')[-1]
# os.system(f'taskkill /f /im {process_name}' )
if __name__ == '__main__':
app =QApplication()
app.setStyle('Fusion')
windows =Nmplayer()
windows.ui.show()
app.exec_()
效果
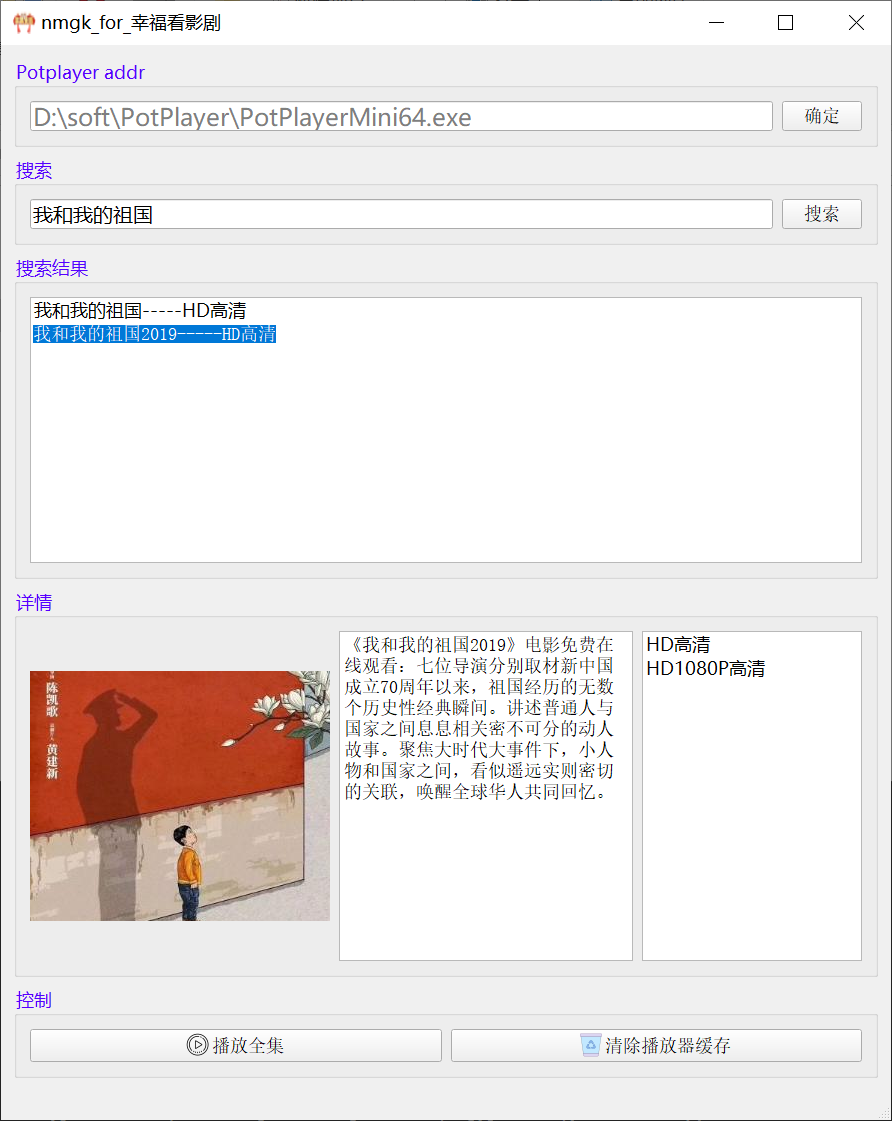
问题记录
-
1、
Traceback (most recent call last):
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 132, in choose_movie
self.get_movie_pic(movie_html_xpath)
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 141, in get_movie_pic
movie_pic_url=self.mother_url+movie_pic_pre_url
TypeError: can only concatenate str (not "list") to str- 原因;xpath定位返回是一个列表
- 解决方案:取列表第一个元素
-
2、
Traceback (most recent call last):
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 132, in choose_movie
self.get_movie_pic(movie_html_xpath)
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 148, in get_movie_pic
with open(self.pot_path,'wb') as f :
FileNotFoundError: [Errno 2] No such file or directory: '' -
原因:文件不存在
-
解决方案:增加文件存在判断
-
3、
ERROR: Could not find a version that satisfies the requirement lxml (from versions: none)
ERROR: No matching distribution found for lxml- 原因:当前镜像源没有匹配的版本
- 解决方案:更换镜像源:pip install lxml -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
-
4、
raise ValueError("check_hostname requires server_hostname")
ValueError: check_hostname requires server_hostname- 原因:request跟系统不兼容
- 解决方案:使用session会话进行发请求
-
5、
Traceback (most recent call last):
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 186, in choose_episode
self.play_episode()
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 193, in play_episode
subprocess.Popen(self.pot_path+' '+self.m3u8_url)
File "D:\soft\python3.8\lib\subprocess.py", line 854, in init
self._execute_child(args, executable, preexec_fn, close_fds,
File "D:\soft\python3.8\lib\subprocess.py", line 1307, in _execute_child
hp, ht, pid, tid = _winapi.CreateProcess(executable, args,
OSError: [WinError 87] 参数错误。- 原因:未输入播放器地址
- 解决方案:输入播放器地址,再播放
-
6、
Traceback (most recent call last):
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 215, in
windows =Nmplayer()
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 55, in init
self.get_pot_path()
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 100, in get_pot_path
with open('pot.config', 'r') as f:
FileNotFoundError: [Errno 2] No such file or directory: 'pot.config' -
原因:文件不存在
-
解决方案:增加文件存在判断
-
7、
Traceback (most recent call last):
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 96, in get_pot_path
os.remove('pot.config')
PermissionError: [WinError 32] 另一个程序正在使用此文件,进程无法访问。: 'pot.config' -
原因:打开文件的同时进行删除文件
-
解决方案:打开文件,读取完成,关闭后再进行删除
-
8、
Traceback (most recent call last):
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 190, in choose_episode
self.play_episode()
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 197, in play_episode
subprocess.Popen(self.pot_path+' '+self.m3u8_url + ' /autoplay')
File "D:\soft\python3.8\lib\subprocess.py", line 854, in init
self._execute_child(args, executable, preexec_fn, close_fds,
File "D:\soft\python3.8\lib\subprocess.py", line 1307, in _execute_child
hp, ht, pid, tid = _winapi.CreateProcess(executable, args,
FileNotFoundError: [WinError 2] 系统找不到指定的文件。 -
原因:文件不存在
-
解决方案:增加文件存在判断
-
9、
Traceback (most recent call last):
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 237, in clear_source
os.kill(pid, signal.SIGKILL)
AttributeError: module 'signal' has no attribute 'SIGKILL'
kill specific process: name(PotPlayerMini64.exe)-pid(3460) -
原因:win10已经没有此信号:signal.SIGKILL
-
解决方案:更换信号为signal.SIGINT
-
10、
Traceback (most recent call last):
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 130, in get_main_html
main_html_xpath=content_xpath(main_pre_html)
File "D:/py project/DevTools/爬虫/nmgk.com/nmgkplayer.py", line 31, in content_xpath
content=html.content.decode('utf-8')
AttributeError: 'NoneType' object has no attribute 'content' -
原因:返回结果为空
-
解决方案:进行判空
