

kubernetes 部署 Fluentd 服务
部署 Fluentd
Fluentd 是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少,另外一个工具Fluent-bit更轻量级,占用资源更少,但是插件相对 Fluentd 来说不够丰富,所以整体来说,Fluentd 更加成熟,使用更加广泛,所以我们这里也同样使用 Fluentd 来作为日志收集工具
工作原理
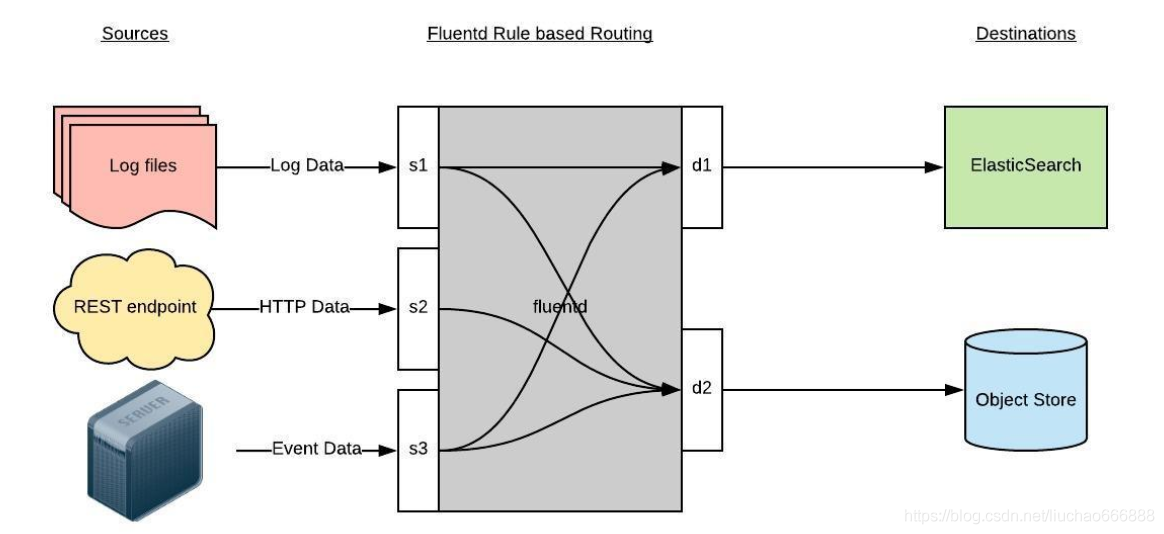
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储等等
1、首先 Fluentd 从多个日志源获取数据
2、结构化并且标记这些数据
3、然后根据匹配的标签将数据发送到多个目标服务去
配置
日志源配置
比如我们这里为了收集 Kubernetes 节点上的所有容器日志,就需要做如下的日志源配置

<source> @id fluentd-containers.log @type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。 path /var/log/containers/*.log # 挂载的服务器Docker容器日志地址 pos_file /var/log/es-containers.log.pos tag raw.kubernetes.* # 设置日志标签 read_from_head true <parse> # 多行格式化成JSON @type multi_format # 使用 multi-format-parser 解析器插件 <pattern> format json # JSON 解析器 time_key time # 指定事件时间的时间字段 time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式 </pattern> <pattern> format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/ time_format %Y-%m-%dT%H:%M:%S.%N%:z </pattern> </parse> </source>


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!