

Attentive and ensemble 3D dual path networks for pulmonary nodules classification, Neurocomputing

标题:基于注意力和集成3D双路径网络的肺结节分类
来源:Neurocomputing(2019)
H. Jiang, F. Gao and X. Xu et al., Attentive and ensemble 3D dual path networks for pulmonary nodules classification, Neurocomputing, https://doi.org/10.1016/j.neucom.2019.03.103
摘要:
自动肺结节分类旨在预测候选结节是良性还是恶性。对肺癌的计算机辅助诊断具有重要意义。尽管现有方法取得了长足的进步,但仍存在一些挑战,包括缺乏细粒度表示、推理过程的可解释性以及真阳性率和假阳性率之间的权衡。为了应对这些挑战,在这项工作中,我们提出了一个新的肺结节分类框架,通过注意力和集成3D双路径网络。特别地,我们首先设计了一个上下文注意机制来模拟相邻位置之间的上下文关联,从而提高了深层特征的代表性。其次,我们使用一个空间注意机制来自动定位结节分类所需的区域。最后,我们使用多个模型的集合来提高预测的鲁棒性。在LIDC-IDRI数据库上进行了大量的实验。结果证明了所提出的技术的有效性和我们的模型比以前的最先进的优越性。
一、 解决了什么问题?
① 缺乏细粒度的表示—限制了肺结节分类的准确性
同一类结节的表示可能是互补的,提出了contextual attention mechanism(上下文注意力机制),模拟相邻位置之间的上下文相关性。上下文注意力机制为CT图像内部不同区域和相邻CT图像之间的相关性建模,并通过关注整个3D立方体的表示来学习每个位置的表示,从而提高了表示能力。
② 推理过程的可解释性(the interpretability of the reasoning procedure)
结节在整个3D-CT中的表示并不一致,所以采用了一种空间注意力机制来自动定位结节分类所需的区域。
③ 真阳性率(TPR)和假阳性率(FPR)之间的权衡
受到ensemble learning和multi-view learning在不同任务中的成功启发,不同的模型可能适用于不同的实例,使用不同模型变量的集合(集成策略)来提高预测的鲁棒性,在灵敏度和误报率之间显示出最佳的折衷。
我们基于3D双路径网络(DPNs)和注意机制构建了几个模型变体,并将它们的预测融合,得到最终的分类标签。
总结:上下文注意力机制和空间注意机制都提高分类的准确性和可解释性。集成策略进一步平衡TPR和FPR,提高预测的鲁棒性。
二、相关工作(只写出我认为有用的)
² 传统方法:手工制作的特征来表示结节+分类器来预测结节的类别
- 手工制作的特征:Gabor、局部二进制模式(LBP)、SIFT描述符等
- 分类器:监督学习方法,如支持向量机(SVM)和随机森林。
² 深度学习方法:从自动编码器中提取的深层特征进行肺结节分类;使用multi-scale CNN,然后使用multi-crop CNN来提高分类精度;基于三维深度双路径网络(DPNs)的肺结节分类。
² 本文方法: 受DeepLung的启发,使用3D DPN作为网络原型。在两个方面不同。首先,使用上下文注意机制和空间注意机制来提高表征能力。第二,使用不同模型变量的集合来提高预测的鲁棒性。
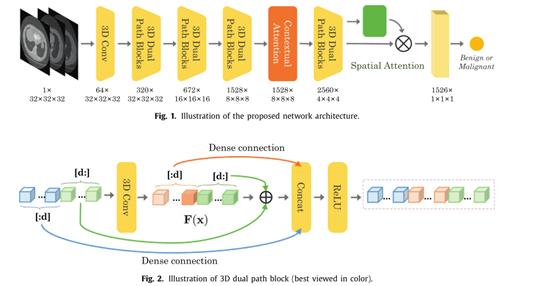
三、网络结构
1、Attentive and ensemble 3D DPNs
本文以3D-DPN为基线网络,采用两种注意机制和一种嵌入策略来提高肺结节分类的性能和可解释性。
在DPN中,双路径连接综合了残差学习和密集连接的优点,前者用于特征重用,后者用于开发新特征。在实现中,基于超参数d将输入特征映射分成两部分。一部分用于残差学习,另一部分用于密集连接。
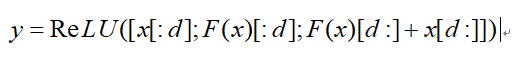
其中x是双路径连接块的输入,F是卷积函数,ReLU表示ReLU激活函数,y是输出。
在基线网络中,我们首先裁剪以预测结节位置为中心的CT数据,大小为32×32×32。最后,我们使用一个卷积层,然后使用30个3D双路径块来学习高级结节表示。最后,使用三维平均池层和二元logistic回归层预测输入结节是良性还是恶性。

表 1 本文中的主要符号
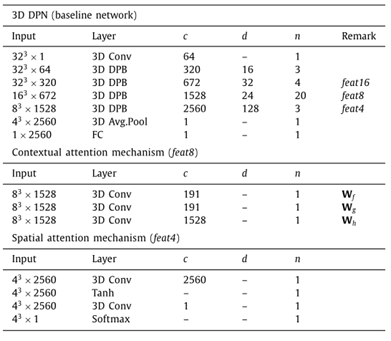
表 2 Our network architecture。每行描述一个由1个或多个相同层组成的序列,重复n次。DPB 表示一个双路径块, Conv表示一个卷积层,Avg.Pool表示一个平均池化层,FC 表示一个完全连接层。同一序列中的层有相同数量的输出通道c。在这里,上下文注意机制被添加到层feat8中,空间注意机制被添加到feat4中。如果我们将注意力机制添加到其他层,那么输入和c也会相应地改变。
2、上下文注意力机制(常看见这个词汇,但没有仔细查阅)
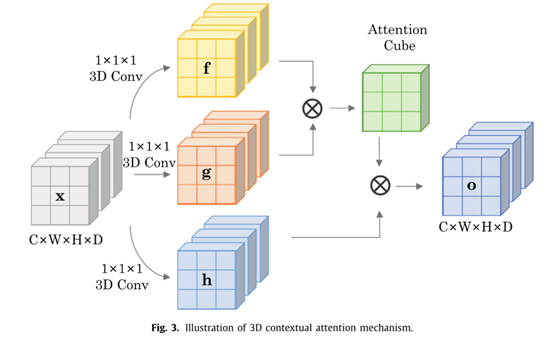
图像特征:,其中W:宽度;H:高度;D:depth of the feature maps;C:通道数量。
首先将x变换为两个特征空间f,g来计算上下文注意力,其中,。
式中,表示第i个位置对推断第j个位置的贡献程度。
上下文注意机制将某个位置的响应计算为整个多维数据集的特征加权和。注意层的输出表示为。其中:
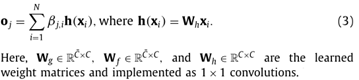
使用来减少内存和计算开销。上下文注意机制的最终输出由。其中是一个刻度参数,初始化为0,并在训练过程中自动更新。
3、空间注意力
在DPN层(如feat4)之后加入空间注意机制,DPN的输出表示为;其中表示在位置的特征向量,是通道数。
我们的空间注意机制包括两个3D卷积层,然后分别是Tanh和Softmax激活层。空间注意机制的输出是一个W×H×D立方体。注意立方体中的元素表示相应的局部属性对肺结节分类的重要性。
学习到的空间注意力表示为:,其中乘以局部激活向量:
,之后被送入下一层进行肺结节分类。
4、目标函数
将肺结节分类任务定义为二元分类问题,并在学习过程中使用二元交叉熵损失。BCE损失计算如下:
其中是the ground-truth binary label;=1表示输入结节是恶性的,=0是良性的。是利用我们的模型预测的标签, n是样本数.
5、Ensemble
为了进一步提高肺结节分类的鲁棒性,采用集成学习的思想,将不同模型的输出进行融合,得到最终的预测结果。考虑了提出框架的四个变体,包括:
• 3D DPN (M 0 ) : the baseline network with no attention;
• 3D DPN + CoA8 (M 1 ) : 3D DPN with a contextual attention mechanism at layer feat8 ;
• 3D DPN + SpA4 (M 2 ) : 3D DPN with a spatial attention mechanism at layer feat4 ; and
• 3D DPN + CoA8 + SpA4 (M 3 ) : 3D DPN with a contextual attention mechanism at layer feat8 and a spatial attention mechanism at layer feat4
在推理阶段,每个模型输出一个二进制标签。阈值设置为0.5,即如果预测概率大于0.5,则输入结节被标记为恶性。我们得到了一个基于加权投票策略(weighted voting strategy)的最终预测。预测公式如下:
其中x是输入的CT图像,y是最终预测,α=[α0,α1,α2,α3]是与前面列出的模型相关的加权因子。为了方便起见,我们在实验中设置α=[1,1,1,1]/4,即所有这些模型对最终结果的贡献相等。给定一个候选结节,如果至少两个模型预测它是恶性的,那么它就被标记为恶性。
四、数据库及性能指标
使用LUNA16的设置在LIDC-IDRI数据集上进行实验,最后,共有1004个结节残留,其中450个结节呈阳性。在折叠1-5上评估我们的方法,并报告平均性能。in the ablation study,由于有限的计算预算,我们只在第5倍上评估我们的方法。
性能指标:
① 计算四个广泛使用的指标,包括准确性、敏感性(即真阳性率、TPR或召回率)、假阳性率(FPR)和F1分数作为性能标准。准确度表示正确预测的恶性/良性结节的百分比;敏感性表示正确预测恶性结节的百分比,对CAD至关重要;FPR表示正确预测良性结节的百分比;F1分数评估敏感性和FPR之间的权衡。准确度、灵敏度和F1分数越高,FPR值越低,则表明性能越好。总的来说,F1的最高分数代表了最好的表现。
② 为了评估所提出的技术,即上下文注意力、空间注意力和整体策略的有效性,进行了一系列的消融研究。
③ 计算复杂度
五、实现及实验结果
² 数据增强:首先随机将4×4×4 pitch设为0,将大小为32×32×32的结节垫成36×36×36。然后,我们从填充数据中随机裁剪32×32×32,并对数据进行水平翻转、垂直翻转、z轴翻转。
² 优化:Adam优化器;学习率=0.0002;momentum parameters β1 = 0 . 5 and β2 = 0 . 999;epochs=700。
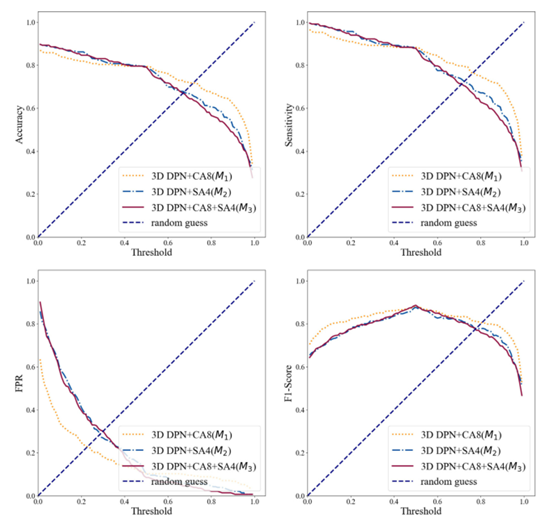
图 1 阈值对三种模型变量的影响。随着阈值的增加,准确度和灵敏度都会下降;而FPR则相反。当阈值为0.5时,三种模型均达到最佳F1评分,说明它们都达到了灵敏度和FPR之间的最佳平衡。因此,在所有其他实验中,我们将阈值设置为0.5。
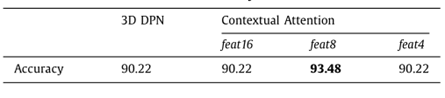
图 2 不同层次的上下文注意力对第五折的影响。在中间层特征映射(即feat8)中具有上下文注意机制的模型比在其他级别的特征映射(如feat16和feat4)上具有上下文注意机制的模型的性能最好。原因可能是:一方面,上下文注意机制通过更大的特征图获得更多证据;另一方面,更高层次的表征在表示结节是良性还是恶性方面更为有力。feat8实现了代表性和特征map大小之间的最佳平衡。此外,与没有注意的基线模型(3D-DPN)相比,具有上下文注意机制的模型没有表现出性能下降。

图 3 不同层次的空间注意力对第五折的影响。在高层次特征地图(即feat4)上具有空间注意机制的模型比其他层次特征地图(如feat16和feat8)具有空间注意机制的模型的性能最好。原因可能是高级表示最接近预测层,对预测节点是良性还是恶性最有效。此外,与空间注意机制的模型比较,一致地优于基线,证明了所提出的空间注意机制的有效性。
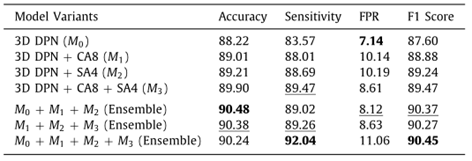
图 4 集合策略的影响。与单个模型相比,集成运算的增益约为0。准确度和F1分数均提高0.5-1%。此外,使用所有四个模型变型的集合达到最好的F1分数。这些结果表明,集成策略可以更好地权衡灵敏度和FPR,从而提高结节分类的鲁棒性。
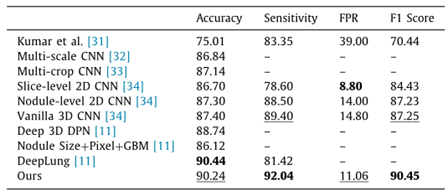
图 5 与其他算法比较。我们的方法获得了最高的灵敏度和F1分数。在计算机辅助诊断中,正确发现恶性结节的敏感性即真阳性率(TPR)非常重要。此外,F1得分最高意味着我们的方法在TPR和FPR之间达到了最佳的折衷。值得注意的是,我们的方法在精确度上与DeepLung不相上下,但在F1得分方面明显优于它。回想一下,DeepLung不仅使用了DPN特征,还使用了原始像素、结节大小等信息,
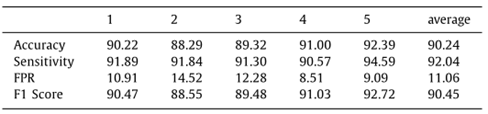
图 6 在所有5折数据库上的性能。该方法在所有子集上都显示出一致的有效性,证明了它的鲁棒性。

图 7 学习到的上下文注意力的视觉化。为了清晰起见,我们将CT图像和注意力以2D的形式显示出来,对于每个子图,左边的灰色图像是原始的CT图像块,红色的点表示查询位置,左边的灰度图像是与相应的注意图合并的。在这里,注意力地图被调整到CT图像的大小,并以灰色图像显示(即,较亮的区域表示更高的注意力值)

图 8 显示了将每个模型应用于尺寸为32×32×32的三维CT图像立方体时的计算时间。计算时间以毫秒(ms)为单位所提出的注意机制稍微增加了推理阶段的时间消耗,但显著提高了肺结节的分类性能。
六、展望
未来,我们将致力于进一步提高分类精度,采用多任务学习、度量学习和稀疏编码。此外,利用多视图特征可以提高预测精度,在各种任务中表现出令人鼓舞的性能。

