
数据分析---大数据及机器学习
常用的库:Numpy、Pandas、Matplotlib、Scipy等;
编辑器:IPython和Jupyter notebook(Anaconda包含);
1.Numpy:Numerical Python缩写,主要用于数值计算。
2.Pandas:数据分析的主要工具。
3.matplotlib:绘制数据图表
4.scipy:科学计算领域针对不同标准问题的包的集合。强大的科学计算方法(矩阵分析、信号分析、数理分析等)
一、Numpy
安装方法:pip install numpy / conda install 一般自带;
引导:import numpy as np 约定熟成;
ndarray-多维数组对象:np.ndarray()实例化对象;
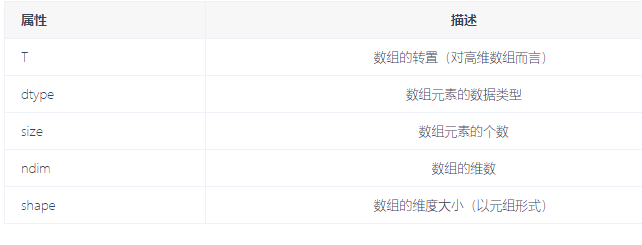
常用属性:T(高维数组转置)、ndim维度、shape形状、size总长、dtype元素类型;
创建方法:array()将列表转为数组、arange()等同range、linspace()、zeros()全0数组、ones()全1数组、empty()空数组、eye()单位矩阵;
基本操作:索引arr[1][2]; 切片arr[0:2], 倒序arr[::-1]和arr[,::-1];变形reshape{(48,)/(6,8)(-1,4)} ;级联concatenate(obj1,obj2,axis=0/1/2).
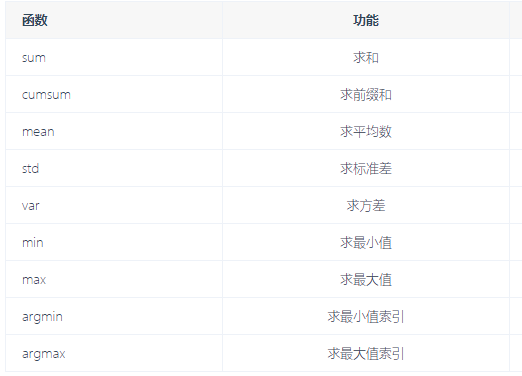
聚合操作:求和Sum,最大/小Max/Min,平均Mean,平方Square,四舍五入Rint,正负号Isnan等等。


快速排序:np.sort()
二、Pandas
安装方法:pip install Pandas
引导:import pandas as pd 约定熟成;
Series(一维)和DataFrame
1、Series
1)Series的创建
两种创建方式:
(1) 由列表或numpy数组创建默认索引为0到N-1的整数型索引Series(data=[1,2,3,4,5])
2)Series的索引和切片
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的是个Series类型)。
(1) 显式索引:
- 使用index中的元素作为索引值 - 使用s.loc[](推荐):注意,loc中括号中放置的一定是显示索引注意,此时是闭区间
(2) 隐式索引:
- 使用整数作为索引值
- 使用.iloc[](推荐):iloc中的中括号中必须放置隐式索引注意,此时是半开区间
3)Series的基本概念
对Series元素进行去重s = Series([1,1,2,2,3,4,5,56,6,7,78,8,89]) s.unique()
可以使用pd.isnull(),pd.notnull(),或s.isnull(),notnull()函数检测缺失数据
2、DataFrame == mysql的table************重点*************
DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values
最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列。
此外,DataFrame会自动加上每一行的索引。
使用字典创建的DataFrame后,则columns参数将不可被使用。
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN。
2)DataFrame的索引
- 通过类似字典的方式 df['q']
- 通过属性的方式 df.q可以将DataFrame的列获取为一个Series。返回的Series拥有原DataFrame相同的索引,且name属性也已经设置好了,就是相应的列名。
三、Matplotlib
四、Scipy

 浙公网安备 33010602011771号
浙公网安备 33010602011771号