mysql大数据下查询,char和varchar对于效率的区别(未建立索引情况下)
- 问题描述:
两个表的仅有以一个字段属性不同,一个为char另外一个为varchar,(长度设定是40,同时插入相同长度内容)试问再大数据量下,哪个表的查询效率高(在不建立索引的情况下);
- 原来的理解:
原来的理解是,char的效率更高,这个理解是基于char是固定长度,空间分配好查询速度就快(这个后面就尴尬咯)
- 实际测试:
表结构如下

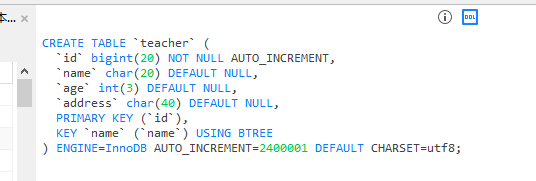
写了一个定时任务批量插入数据。。。。
后来插入到240w,写个定时任务跑爽爽的
在50w数据量下测试的结果:
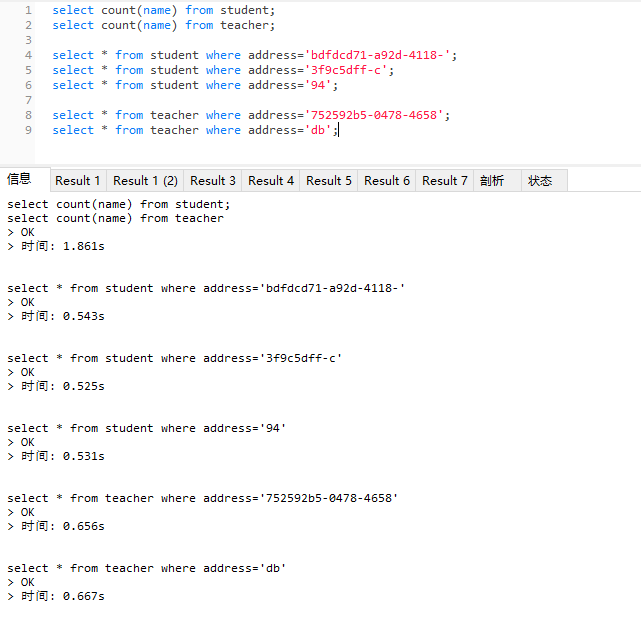
到240w后的差距就更明显。
在没有索引的情况下,mysql查询走的是主键创建的索引,通过主键查询,数据量大效率的瓶颈是磁盘的io,
当数据量大的时候,char是固定长度,占用的磁盘空间较大,查询效率就降低;
在不同的场景下,瓶颈是不同的;
相关链接:varchar与char查询速度的比较

=======================================
Deadline:2019.3.10
Title:spring bean的初始化,@bean注入的小问题
Reward:攒足三次购买东芝移动硬盘1T(1次)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号