python中的循环和迭代
在Python语法中如果用for-in循环,那么就要使用迭代器协议,只要对象支持__iter__和__next__双下划线方法,那么就能够使用for-in循环。
1 class RepeaterIterator: 2 def __init__(self, source): 3 self.source = source 4 5 def __next__(self): 6 return self.source.value 7 8 9 class Repeater: 10 def __init__(self, value): 11 self.value = value 12 13 def __iter__(self): 14 return RepeaterIterator(self) 15 16 17 repeater = Repeater('Hello') 18 for item in repeater: 19 print(item)
上面的代码会在控制台循环打印"hello".
上面的for-in那一段代码可以展开成下面的但是效果相同的代码:
1 repeater=Repeater('Hello') 2 iterator = repeater.__iter__() 3 while True: 4 item = iterator.__next__() 5 print(item)
从上面可以看出,for-in只是简单的while循环的语法糖。
- 首先让repeater对象准备迭代,即调用__iter__方法来返回实际的迭代器对象。
- 然后循环反复调用迭代器对象的__next__方法,从中获取值。
看下面的例子,__iter__方法和__next__方法在同一个类中,
1 class BoundedRepeater: 2 def __init__(self, value, max_repeats): 3 self.value = value 4 self.max_repeats = max_repeats 5 self.count = 0 6 7 def __iter__(self): 8 return self 9 10 def __next__(self): 11 if self.count >= self.max_repeats: 12 raise StopIteration 13 self.count += 1 14 return self.value 15 16 17 repeater = BoundedRepeater('Hello', 3) 18 for item in repeater: 19 print(item)
如果重写上面的for-in循环的例子,移除一些语法糖,那么展开后最终就会得到下面的代码片段:
1 repeater = BoundedRepeater('Hello', 3) 2 iterator = iter(repeater) 3 while True: 4 try: 5 item = next(iterator) 6 except StopIteration: 7 break 8 print(item)
每次在此循环中调用next()时都会检查StopIteration异常,并且在必要时中断while循环。
总结:
为了支持迭代,对象需要通过提供__iter__和__next__双下划线方法来实现迭代器协议。
基于类的迭代器只是用Python编写可迭代对象的一种方法。可迭代对象还包括生成器和生成器表达式。
生成器是简化版迭代器
关键要点
- 生成器函数是一种语法糖,用于编写支持迭代器协议的对象,与编写基于类的迭代器相比,生成器能够抽象出许多样板代码。
- yield语句用来暂时中止执行生成器函数并传回值
- 在生成器中,控制流通过非yield语句离开会抛出StopInteration异常。
1 class Repeater: 2 def __init__(self, value): 3 self.value = value 4 5 def __iter__(self): 6 return self 7 8 def __next__(self): 9 return self.value
将上面的Repeater迭代器类重写为生成器类,代码如下:
1 def repeater(value): 2 while True: 3 yield value
从中可以看出,生成器看起来像普通函数,但是它没有return语句,而是用yield将数据传回给调用者。
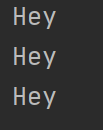
这个新的生成器能够像基于类的迭代器一样工作,用for-in循环测试一下:
1 for x in repeater('Hi'): 2 print(x)

生成器看起来像是普通函数,但是行为确完全不同。调用生成器函数并不会运行该函数,仅仅创建并返回一个生成器对象:
print(repeater('Hey'))

只有在对生成器对象上调用next()时才会执行生成器函数中的代码:
1 generator_obj = repeater('Hey') 2 print(next(generator_obj))

yield关键字像是在某种程度上停止这个生成器函数的执行,然后在稍后的时间点恢复,当函数内部调用return语句时,控制权会永久性的交还给函数的调用者。在调用yield时,虽然控制权也是交还给函数的调用者,但是却只是暂时的。
return语句会丢弃函数的局部状态,但是yield语句会暂停该函数并且保留其局部状态。实际上,这意味着局部变量和生成器函数的执行状态只是暂时隐藏起来,不会被完全抛弃,再次调用生成器的next()能够恢复执行函数。
这使得生成器能够完全兼容迭代器协议。
能够停下来的生成器
在基于类的迭代器中,可以通过手动引发StopIteration异常来表示迭代结束。因为生成器与基于类的迭代器完全兼容,所以背后仍然使用这种办法。
1 def repeat_three_times(value): 2 yield value 3 yield value 4 yield value 5 6 7 for x in repeat_three_times("hello"): 8 print(x)

该生成器在迭代三次后停止产生新值,可以确认这是通过当执行到函数结尾时引发StopIteration异常来实现的。通过下面代码来实验:
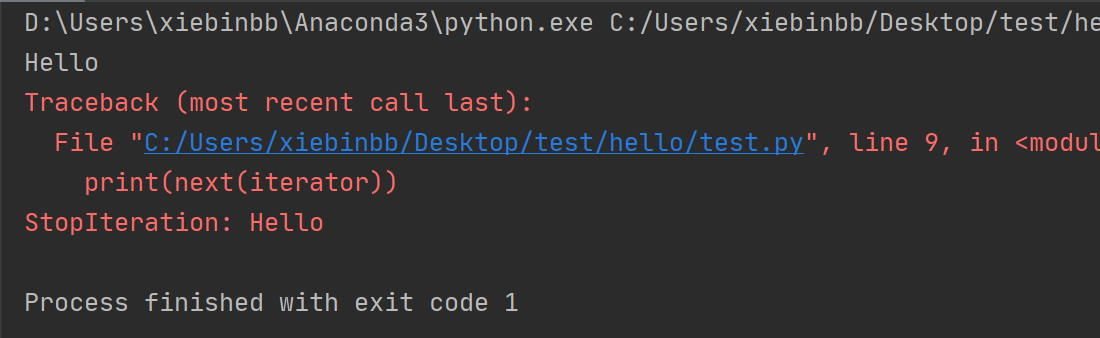
1 def repeat_three_times(value): 2 yield value 3 yield value 4 yield value 5 6 7 iterator = repeat_three_times('Hello') 8 print(next(iterator)) 9 print(next(iterator)) 10 print(next(iterator)) 11 print(next(iterator))

这个迭代器表现和预期一样,一旦到达生成器函数的末尾,就会不断抛出StopIteration以表示所有的值都用完了。
def repeat_three_times(value): yield value return value yield value iterator = repeat_three_times('Hello') print(next(iterator)) print(next(iterator)) print(next(iterator)) print(next(iterator))
当在生成器中使用return语句时会终止迭代并且产生StopIteration异常。
生成器表达式
关键要点
- 生成器表达式与列表解析式类似,但是不构造列表对象,而实像基于类的迭代器或者生成器函数那样“即时”生成值。
- 生成器表达式一经使用就不能重新启动或者重新使用。
- 生成器表达式最适合实现简单的"实时"迭代器,但是对于复杂的迭代器,最好编写生成器函数或者基于类的迭代器。
生成器为编写基于类的迭代器提供了语法糖,生成器表达式在此基础上又添加了一层语法糖。
来看一个例子:
1 iterator = ("hello" for i in range(3)) 2 print(iterator)

上面的代码和下面的代码原理相同。
1 def bounded_repeater(value, max_repeats): 2 for i in range(max_repeats): 3 yield value 4 5 6 iterator = bounded_repeater("hello", 3)
1 iterator = ("hello" for i in range(3)) 2 for x in iterator: 3 print(x) 4 5 6 for x in iterator: 7 print(x)

生成器表达式一经使用就不能重新启动。
迭代器链
关键要点:
- 生成器可以链接在一起形成高效而且可以维护的数据处理管道。
- 互相链接的生成器会逐个处理在链中通过的每个元素。
- 生成器表达式可以用来编写简洁的管道定义,但是可能会降低代码的可读性。
Python中的迭代器有一个重要特性:可以链接多个迭代器,从而编写高效的数据处理"管道".
1 def integers(): 2 for i in range(1, 9): 3 yield i 4 5 6 def squard(seq): 7 for i in seq: 8 yield i * i 9 10 11 def negated(seq): 12 for i in seq: 13 yield -i 14 15 16 chain = negated(squard(integers())) 17 print(list(chain))

如上面代码所示:
- integers生成器产生一个值,比如3
- 这个值"激活"squared生成器来处理,得到3*3=9,并且将其传递到下一个阶段。
- 由squared生成器产生的平方数立即送入negated生成器,将其修改为-9并再次yield.
生成器链可以高效执行并且很容易修改,因为链中的每一步都是一个单独的生成器函数。
下面的代码和上面代码原理一样;
1 integers = range(8) 2 squared = (i * i for i in integers) 3 negated = (-i for i in squared) 4 print(negated) 5 print(list(negated))

使用生成器表达式的唯一缺点式不能再使用函数参数进行配置,也不能在同一处理管道中多次重复使用相同的生成器表达式。
不过在构建这些管道时自由组合和匹配生成器表达式和普通生成器,有助于提高复杂管道的可读性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号