spark之shuffle
一、Shuffle的作用是什么?
Shuffle的中文解释为“洗牌操作”,可以理解成将集群中所有节点上的数据进行重新整合分类的过程。其思想来源于hadoop的mapReduce,Shuffle是连接map阶段和reduce阶段的桥梁。由于分布式计算中,每个阶段的各个计算节点只处理任务的一部分数据,若下一个阶段需要依赖前面阶段的所有计算结果时,则需要对前面阶段的所有计算结果进行重新整合和分类,这就需要经历shuffle过程。
在spark中,RDD之间的关系包含窄依赖和宽依赖,其中宽依赖涉及shuffle操作。因此在spark程序的每个job中,都是根据是否有shuffle操作进行阶段(stage)划分,每个stage都是一系列的RDD map操作。
二、shuffle操作为什么耗时?
shuffle操作需要将数据进行重新聚合和划分,然后分配到集群的各个节点上进行下一个stage操作,这里会涉及集群不同节点间的大量数据交换。由于不同节点间的数据通过网络进行传输时需要先将数据写入磁盘,因此集群中每个节点均有大量的文件读写操作,从而导致shuffle操作十分耗时(相对于map操作)。
三、Spark目前的ShuffleManage模式及处理机制
Spark程序中的Shuffle操作是通过shuffleManage对象进行管理。Spark目前支持的ShuffleMange模式主要有两种:HashShuffleMagnage 和SortShuffleManage
Shuffle操作包含当前阶段的Shuffle Write(存盘)和下一阶段的Shuffle Read(fetch),两种模式的主要差异是在Shuffle Write阶段,下面将着重介绍。
1、HashShuffleMagnage
HashShuffleMagnage是Spark1.2之前版本的默认模式,在集群中的每个executor上,其具体流程如下图所示:
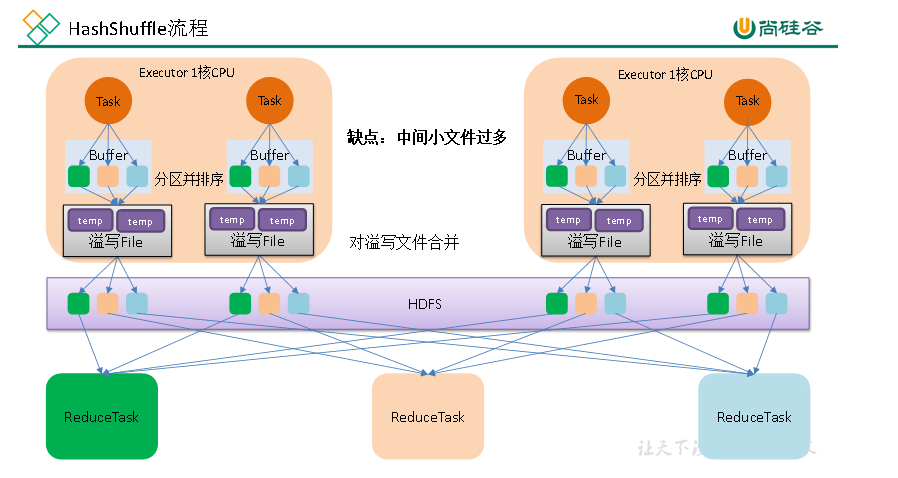
从图中可知,在executor中处理每个task后的结果均会通过buffler缓存的方式写入到多个磁盘文件中,其中文件的个数由shuffle算子的numPartition参数指定(图中partition为3)。因此Shuffle Write 阶段会产生大量的磁盘文件,整个Shuffle Write 阶段的文件总数为: Write阶段的task数目* Read阶段的task数目。
执行流程:
每一个map task将不同结果写到不同的buffer中,每个buffer的大小为32K。每个Buffer的内存是48M,buffer起到数据缓存的作用。
每个buffer文件最后对应一个磁盘小文件。
reduce task来拉取对应的磁盘小文件。
存在问题:
1. 小文件过多,耗时低效的IO操作
2.OOM,读写文件以及缓存过多
由于HashShuffleManage方式会产生很多的磁盘文件,Spark对其进行了优化,具体流程图为:
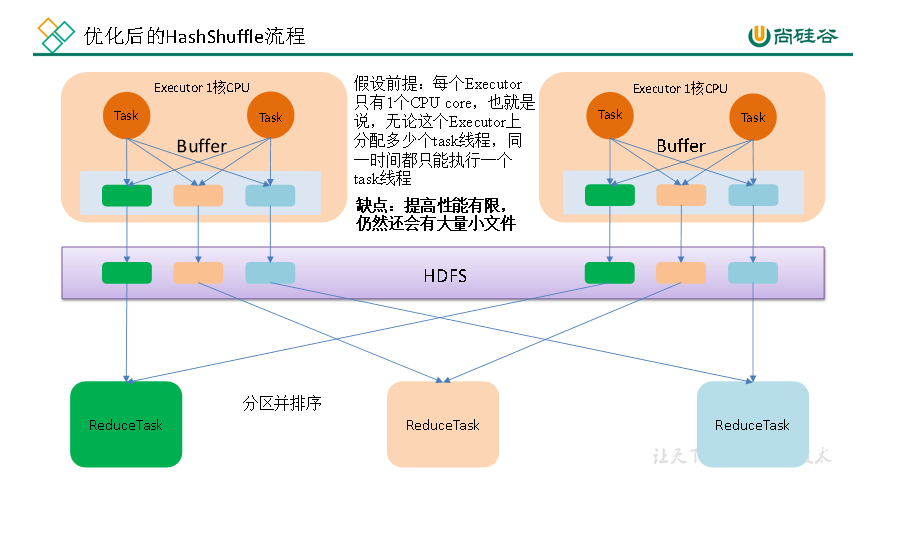
优化点为:
(1)executor处理多个task的时候只会根据Read阶段的task数目(设为m)生成对应的文件数,具体做法是:处理第一个task时生成m个文件,后续task的结果追加到对应的m个文件中。
(2)考虑到executor的并行计算能力(core数量),处理任务的每个core均会生成m个文件。
因此,优化后的HashShuffleManage最终的总文件数:Write阶段的core数量* Read阶段的task数目。
2、SortShuffleManage
SortShuffleManage是Spark1.2及以上版本默认的ShuffleManage模式,具体包含普通模式和bypass模式。
1、普通模式
在集群中的每个executor上,其普通模式的具体流程如下图所示:
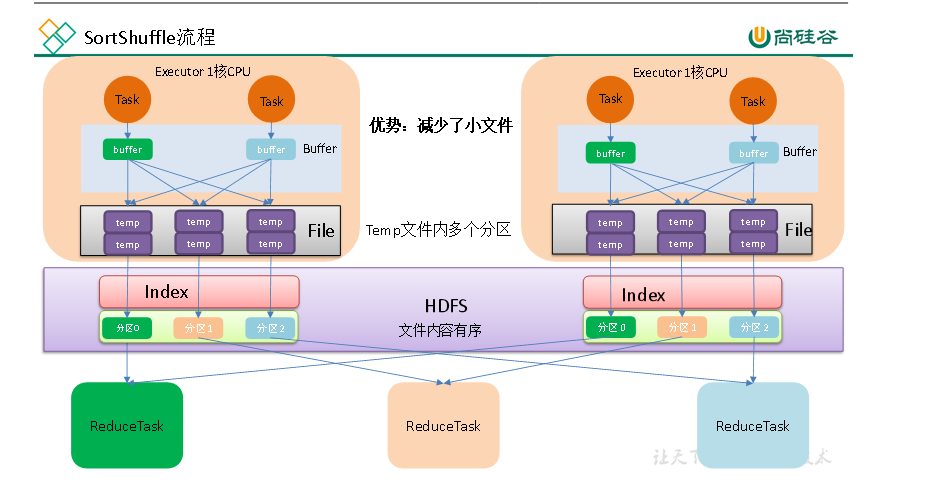
从图中可知,SortShuffleManage在数据写入磁盘文件前有两个重要操作:
(1)数据聚合,针对可聚合的shuffle操作(比如reduceBykey()),会基于key值进行数据的聚合操作,以此减少数据量。
(2)数据聚合之后会对数据进行排序操作。
(问题:基于key排序?排序的目的是什么?),
最后对每个task生成的文件进行合并,通过索引文件标注key值在文件中的位置。
因此,SortShuffleManage产生的总文件数为:Writer 阶段的task数*2
执行流程:
map task 的计算结果会写入到一个内存数据结构里面,内存数据结构默认是5M
在shuffle的时候会有一个定时器,不定期的去估算这个内存结构的大小,当内存结构中的数据超过5M时,比如现在内存结构中的数据为5.01M,那么他会申请5.01*2-5=5.02M内存给内存数据结构。
如果申请成功不会进行溢写,如果申请不成功,这时候会发生溢写磁盘。
在溢写之前内存结构中的数据会进行排序分区
然后开始溢写磁盘,写磁盘是以batch的形式去写,一个batch是1万条数据,
map task执行完成后,会将这些磁盘小文件合并成一个大的磁盘文件,同时生成一个索引文件。
reduce task去map端拉取数据的时候,首先解析索引文件,根据索引文件再去拉取对应的数据。
2、bypass模式
bypass模式流程图:
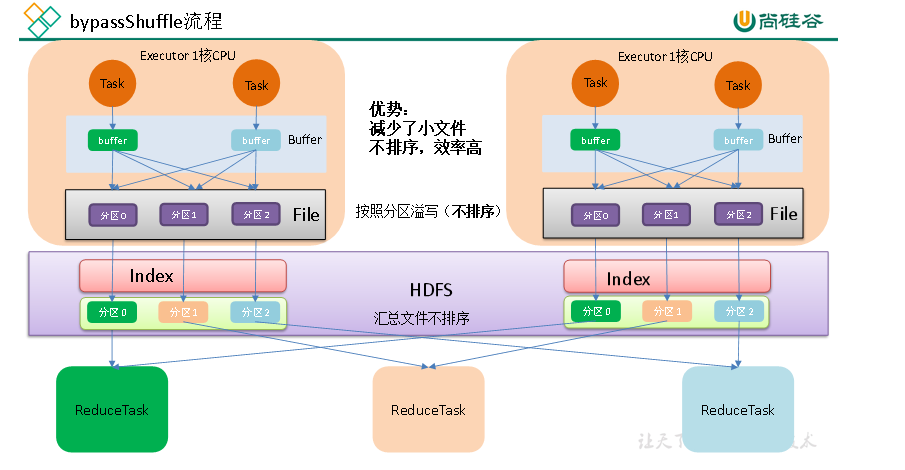
bypass模式与HashShuffleMagnage基本一致,只是Shuffle Write 阶段在最后有一个文件合并的过程,最终输出的文件个数为:Writer阶段的task数目*2
spark.shuffle.sort.bypassMergeThreshold默认值为200,即Read阶段的task数目小于等于该阈值时以及Write端是非聚合操作(比如join),会启用bypass模式,其他情况下采用普通机制。
四、Spark 程序的shuffle调优
Shuffle阶段需要将数据写入磁盘,这其中涉及大量的读写文件操作和文件传输操作,因此对节点的系统IO有比较大的影响,因此可通过调整参数,减少shuffle阶段的文件数和IO读写次数来提高性能,具体参数主要有以下几个:
1)spark.shuffle.manager
设置Spark任务的shuffleManage模式,1.2以上版本的默认方式是sort,即shuffle write阶段会进行排序,每个executor上生成的文件会合并成两个文件(包含一个索引文件)。
2)spark.shuffle.sort.bypassMergeThreshold
设置启用bypass机制的阈值(默认为200),若Shuffle Read阶段的task数小于等于该值,则Shuffle Write阶段启用bypass机制。
3)spark.shuffle.file.buffer (默认32M)
设置Shuffle Write阶段写文件时buffer的大小,若内存比较充足的话,可以将其值调大一些(比如64M),这样能减少executor的IO读写次数。
4)spark.shuffle.io.maxRetries (默认3次)
设置Shuffle Read阶段fetches数据时的重试次数,若shuffle阶段的数据量很大,可以适当调大一些。
hashShuffle:
优化前:每个task将数据按照分区器(hash/numreduce取模)计算,写入buffer
最后的小文件个数为: Task数量 * 文件类型(分区器的计算结果的种类个数)
优化后:只是多个task共用buffer缓冲区,
最后的小文件个数为: CPU核数 * 文件类型(分区器的计算结果的种类个数)
普通的SortShuffle:
合并为1个文件+1个索引文件,中间先排序后溢写
bypassSortShuffle:
不排序,不能使用预聚合算子(比如reduceByKey)
reduce task数量小于200(为了减少中间小文件的产生
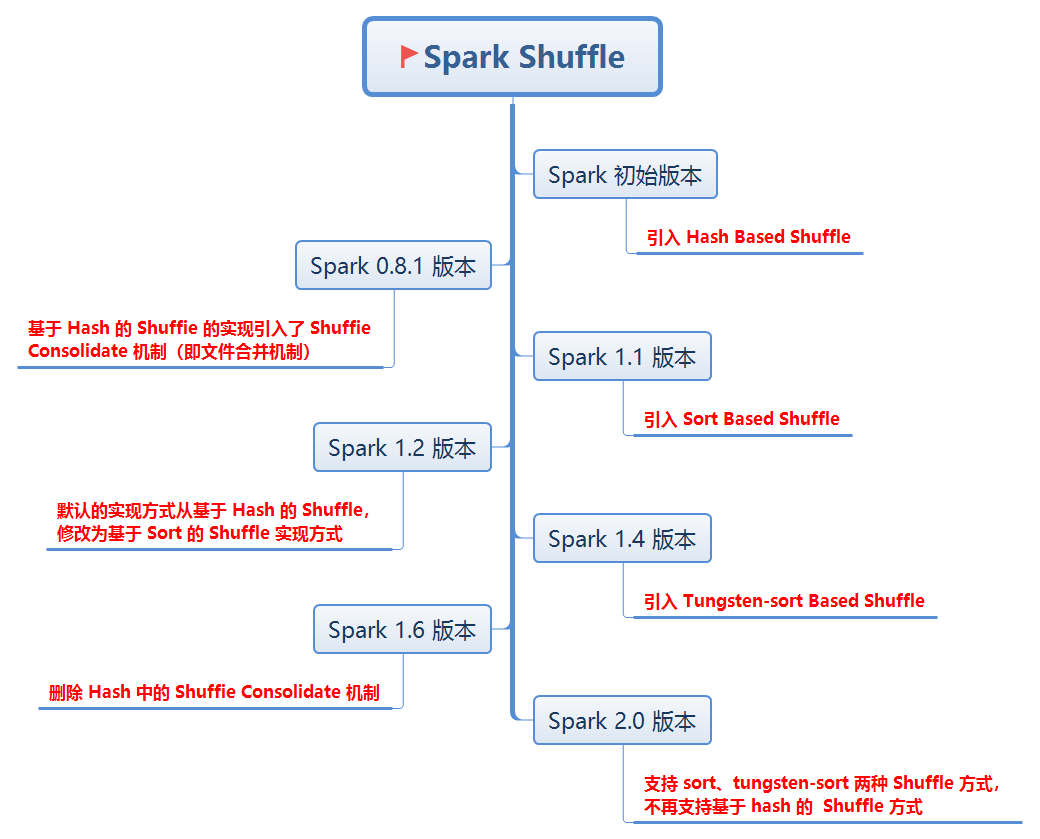
适配器spark中shuffer的版本更迭
————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号