冰河开源了全网首个完全开源的分布式全局有序序列号(分布式ID)框架!!
摘自:https://www.cnblogs.com/binghe001/p/14094261.html
冰河开源了全网首个完全开源的分布式全局有序序列号(分布式ID)框架!!
写在前面
mykit-serial框架的设计参考了李艳鹏大佬开源的vesta框架,并彻底重构了vesta框架,借鉴了雪花算法(SnowFlake)的思想,并在此基础上进行了全面升级和优化。支持嵌入式(Jar包)、RPC(Dubbo,motan、sofa、SpringCloud、SpringCloud Alibaba等主流的RPC框架)、Restful API(支持SpringBoot和Netty),可支持最大峰值型和最小粒度型两种模式。
开源地址:
为何不用数据库自增字段?
如果在业务系统中使用数据库的自增字段,自增字段完全依赖于数据库,这在数据库移植,扩容,清洗数据,分库分表等操作时带来很多麻烦。
在数据库分库分表时,有一种办法是通过调整自增字段或者数据库sequence的步长来达到跨数据库的ID的唯一性,但仍然是一种强依赖数据库的解决方案,有诸多的限制,并且强依赖数据库类型,如果我们想增加一个数据库实例或者将业务迁移到一种不同类型的数据库上,那是相当麻烦的。
为什么不用UUID?
UUID虽然能够保证ID的唯一性,但是,它无法满足业务系统需要的很多其他特性,例如:时间粗略有序性,可反解和可制造型。另外,UUID产生的时候使用完全的时间数据,性能比较差,并且UUID比较长,占用空间大,间接导致数据库性能下降,更重要的是,UUID并不具有有序性,这就导致B+树索引在写的时候会有过多的随机写操作(连续的ID会产生部分顺序写),另外写的时候由于不能产生顺序的append操作,需要进行insert操作,这会读取整个B+树节点到内存,然后插入这条记录后再将整个节点写回磁盘,这种操作在记录占用空间比较大的情况下,性能下降比较大。所以,不建议使用UUID。
需要考虑的问题
既然数据库自增ID和UUID有诸多的限制,我们就需要考虑如何设计一款分布式全局唯一的序列号(分布式ID)服务。这里,我们需要考虑如下一些因素。
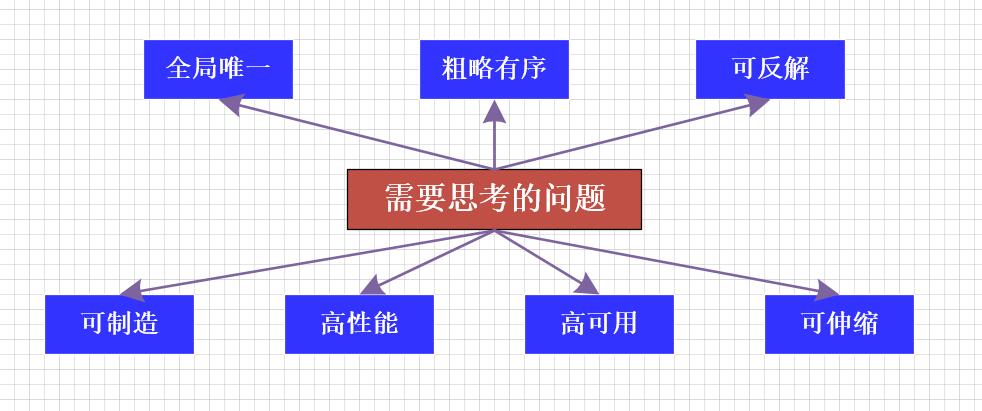
全局唯一
分布式系统保证全局唯一的一个悲观策略是使用锁或者分布式锁,但是,只要使用了锁,就会大大的降低性能。
因此,我们可以借鉴Twitter的SnowFlake算法,利用时间的有序性,并且在时间的某个单元下采用自增序列,达到全局的唯一性。
粗略有序
UUID的最大问题就是无序的,任何业务都希望生成的ID是有序的,但是,分布式系统中要做到完全有序,就涉及到数据的汇聚,需要用到锁或者分布式锁,考虑到效率,需要采用折中的方案,粗略有序。目前有两种主流的方案,一种是秒级有序,一种是毫秒级有序,这里又有一个权衡和取舍,我们决定支持两种方式,通过配置来决定服务使用其中的一种方式。
可反解
一个 ID 生成之后,ID本身带有很多信息量,线上排查的时候,我们通常首先看到的是ID,如果根据ID就能知道什么时候产生的,从哪里来的,这样一个可反解的 ID 可以帮上很多忙。
如果ID 里有了时间而且能反解,在存储层面就会省下很多传统的timestamp 一类的字段所占用的空间了,这也是一举两得的设计。
可制造
一个系统即使再高可用也不会保证永远不出问题,出了问题怎么办,手工处理,数据被污染怎么办,洗数据,可是手工处理或者洗数据的时候,假如使用数据库自增字段,ID已经被后来的业务覆盖了,怎么恢复到系统出问题的时间窗口呢?
所以,我们使用的分布式全局序列号(分布式ID)服务一定要可复制,可恢复 ,可制造。
高性能
不管哪个业务,订单也好,商品也好,如果有新记录插入,那一定是业务的核心功能,对性能的要求非常高,ID生成取决于网络IO和CPU的性能,CPU一般不是瓶颈,根据经验,单台机器TPS应该达到10000/s。
高可用
首先,分布式全局序列号(分布式ID)服务必须是一个对等的集群,一台机器挂掉,请求必须能够转发到其他机器,另外,重试机制也是必不可少的。最后,如果远程服务宕机,我们需要有本地的容错方案,本地库的依赖方式可以作为高可用的最后一道屏障。
也就是说,我们支持RPC发布模式,嵌入式发布模式和REST发布模式,如果某种模式不可用,可以回退到其他发布模式,如果Zookeeper不可用,可以会退到使用本地预配的机器ID。从而达到服务的最大可用。
可伸缩
作为一个分布式系统,永远都不能忽略的就是业务在不断地增长,业务的绝对容量不是衡量一个系统的唯一标准,要知道业务是永远增长的,所以,系统设计不但要考虑能承受的绝对容量,还必须考虑业务增长的速度,系统的水平伸缩是否能满足业务的增长速度是衡量一个系统的另一个重要标准。
设计与实现
整体架构设计
mykit-serial的整体架构图如下所示。
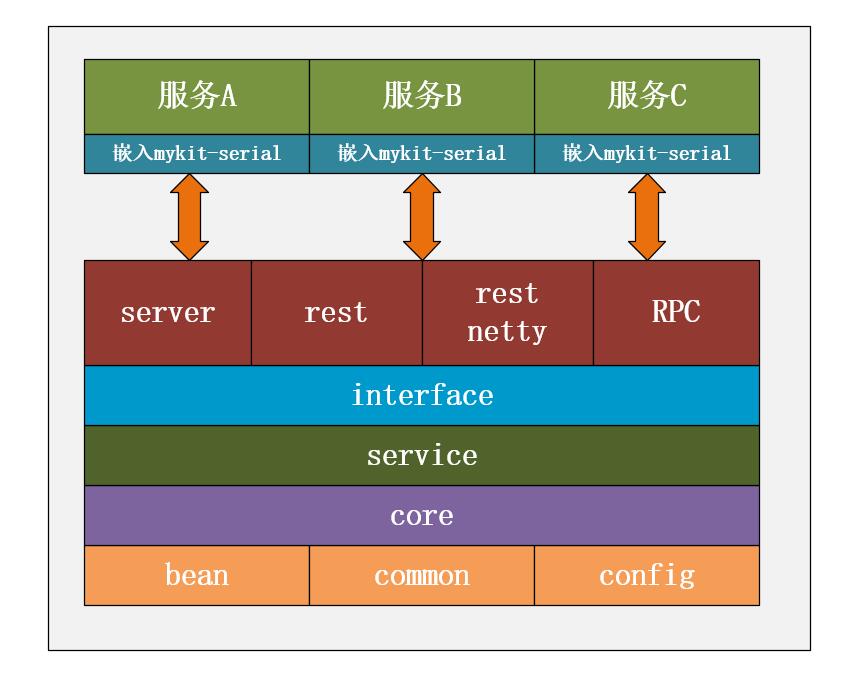
mykit-serial框架各模块的含义如下:
- mykit-bean:提供统一的bean类封装和整个框架使用的常量等信息。
- mykit-common:封装整个框架通用的工具类。
- mykit-config:提供全局配置能力。
- mykit-core:整个框架的核心实现模块。
- mykit-db:存放数据库脚本。
- mykit-interface:整个框架的核心抽象接口。
- mykit-service:基于Spring实现的核心功能。
- mykit-rpc:以RPC方式对外提供服服务(后续支持Dubbo,motan、sofa、SpringCloud、SpringCloud Alibaba等主流的RPC框架)。
- mykit-server:目前实现了Dubbo方式,后续迁移到mykit-rpc模块。
- mykit-rest:基于SpringBoot实现的Rest服务。
- mykit-rest_netty:基于Netty实现的Rest服务。
- mykit-test:整个框架的测试模块,通过此模块可以快速掌握mykit-serial的使用方式。
发布模式
根据最终的客户使用方式,可分为嵌入发布模式,RPC发布模式和Rest发布模式。
-
嵌入发布模式:只适用于Java客户端,提供一个本地的Jar包,Jar包是嵌入式的原生服务,需要提前配置本地机器ID(或者服务启动时,由Zookeeper动态分配唯一的分布式序列号),但是不依赖于中心服务器。
-
RPC发布模式:只适用于Java客户端,提供一个服务的客户端Jar包,Java程序像调用本地API一样来调用,但是依赖于中心的分布式序列号(分布式ID)产生服务器。
-
REST发布模式:中心服务器通过Restful API提供服务,供非Java语言客户端使用。
发布模式最后会记录在生成的全局序列号中。
序列号类型
根据时间的位数和序列号的位数,可分为最大峰值型和最小粒度型。
1. 最大峰值型:采用秒级有序,秒级时间占用30位,序列号占用20位
| 字段 | 版本 | 类型 | 生成方式 | 秒级时间 | 序列号 | 机器ID |
|---|---|---|---|---|---|---|
| 位数 | 63 | 62 | 60-61 | 30-59 | 10-29 | 0-9 |
2. 最小粒度型:采用毫秒级有序,毫秒级时间占用40位,序列号占用10位
| 字段 | 版本 | 类型 | 生成方式 | 毫秒级时间 | 序列号 | 机器ID |
|---|---|---|---|---|---|---|
| 位数 | 63 | 62 | 60-61 | 20-59 | 10-19 | 0-9 |
最大峰值型能够承受更大的峰值压力,但是粗略有序的粒度有点大,最小粒度型有较细致的粒度,但是每个毫秒能承受的理论峰值有限,为1024,同一个毫秒如果有更多的请求产生,必须等到下一个毫秒再响应。
分布式序列号(分布式ID)的类型在配置时指定,需要重启服务才能互相切换。
数据结构
1. 序列号
最大峰值型
20位,理论上每秒内平均可产生2^20= 1048576个ID,百万级别,如果系统的网络IO和CPU足够强大,可承受的峰值达到每毫秒百万级别。
最小粒度型
10位,每毫秒内序列号总计2^10=1024个, 也就是每个毫秒最多产生1000+个ID,理论上承受的峰值完全不如我们最大峰值方案。
2. 秒级时间/毫秒级时间
最大峰值型
30位,表示秒级时间,2^30/60/60/24/365=34,也就是可使用30+年。
最小粒度型
40位,表示毫秒级时间,2^40/1000/60/60/24/365=34,同样可以使用30+年。
3. 机器ID
10位, 2^10=1024, 也就是最多支持1000+个服务器。中心发布模式和REST发布模式一般不会有太多数量的机器,按照设计每台机器TPS 1万/s,10台服务器就可以有10万/s的TPS,基本可以满足大部分的业务需求。
但是考虑到我们在业务服务可以使用内嵌发布方式,对机器ID的需求量变得更大,这里最多支持1024个服务器。
4. 生成方式
2位,用来区分三种发布模式:嵌入发布模式,RPC发布模式,REST发布模式。
00:嵌入发布模式
01:RPC发布模式
02:REST发布模式
03:保留未用
5. 序列号类型
1位,用来区分两种ID类型:最大峰值型和最小粒度型。
0:最大峰值型
1:最小粒度型
6. 版本
1位,用来做扩展位或者扩容时候的临时方案。
0:默认值,以免转化为整型再转化回字符串被截断
1:表示扩展或者扩容中
作为30年后扩展使用,或者在30年后ID将近用光之时,扩展为秒级时间或者毫秒级时间来挣得系统的移植时间窗口,其实只要扩展一位,完全可以再使用30年。
并发处理
对于中心服务器和REST发布方式,ID生成的过程涉及到网络IO和CPU操作,ID的生成基本都是内存到高速缓存的操作,没有IO操作,网络IO是系统的瓶颈。
相对于CPU计算速度来说网络IO是瓶颈,因此,ID产生的服务使用多线程的方式,对于ID生成过程中的竞争点time和sequence,这里使用了多种实现方式
- 使用concurrent包的ReentrantLock进行互斥,这是缺省的实现方式,也是追求性能和稳定两个目标的妥协方案。
- 使用传统的synchronized进行互斥,这种方式的性能稍微逊色一些,通过传入JVM参数-Dmykit.serial.sync.lock.impl.key=true来开启。
- 使用CAS方式进行互斥,这种实现方式的性能非常高,但是在高并发环境下CPU负载会很高,通过传入JVM参数-Dmykit.serial.atomic.impl.key=true来开启。
机器ID的分配
我们将机器ID分为两个区段,一个区段服务于RPC发布模式和REST发布模式,另外一个区段服务于嵌入发布模式。
0-923:嵌入发布模式,预先配置,(或者由Zookeeper产生),最多支持924台内嵌服务器
924 – 1023:中心服务器发布模式和REST发布模式,最多支持300台,最大支持300*1万=300万/s的TPS
如果嵌入式发布模式和RPC发布模式以及REST发布模式的使用量不符合这个比例,我们可以动态调整两个区间的值来适应。
另外,各个垂直业务之间具有天生的隔离性,每个业务都可以使用最多1024台服务器。
与Zookeeper集成
对于嵌入发布模式,服务启动需要连接Zookeeper集群,Zookeeper分配一个0-923区间的一个ID,如果0-923区间的ID被用光,Zookeeper会分配一个大于923的ID,这种情况,拒绝启动服务。
如果不想使用Zookeeper产生的唯一的机器ID,我们提供缺省的预配的机器ID解决方案,每个使用统一分布式全局序列号(分布式ID)服务的服务需要预先配置一个默认的机器ID。
时间同步
使用mykit-serial生成分布式全局序列号(分布式ID)时,需要我们保证服务器的时间正常。此时,我们可以使用Linux的定时任务crontab,定时通过授时服务器虚拟集群(全球有3000多台服务器)来核准服务器的时间。
ntpdate -u pool.ntp.orgpool.ntp.org
性能
最终的性能验证要保证每台服务器的TPS达到1万/s以上。
Restful API文档
产生分布式全局序列号
- 描述:根据系统时间产生一个全局唯一的全局序列号并且在方法体内返回。
- 路径:/genSerialNumber
- 参数:N/A
- 非空参数:N/A
- 示例:http://localhost:8080/genSerialNumber
- 结果:3456526092514361344
反解全局序列号
- 描述:对产生的serialNumber进行反解,在响应体内返回反解的JSON字符串。
- 路径:/expSerialNumber
- 参数:serialNumber=?
- 非空参数:serialNumber
- 示例:http://localhost:8080/expSerialNumber?serialNumber=3456526092514361344
- 结果:{"genMethod":2,"machine":1022,"seq":0,"time":12758739,"type":0,"version":0}
翻译时间
- 描述:把长整型的时间转化成可读的格式。
- 路径:/transtime
- 参数:time=?
- 非空参数:time
- 示例:http://localhost:8080/transtime?time=12758739
- 结果:Thu May 28 16:05:39 CST 2015
制造全局序列号
- 描述:通过给定的分布式全局序列号元素制造分布式全局序列号。
- 路径:/makeSerialNumber
- 参数:genMethod=?&machine=?&seq=?&time=?&type=?&version=?
- 非空参数:time,seq
- 示例:http://localhost:8080/makeSerialNumber?genMethod=2&machine=1022&seq=0&time=12758739&type=0&version=0
- 结果:3456526092514361344
Java API文档
产生全局序列号
- 描述:根据系统时间产生一个全局唯一的分布式序列号(分布式ID)并且在方法体内返回。
- 类:SerialNumberService
- 方法:genSerialNumber
- 参数:N/A
- 返回类型:long
- 示例:long serialNumber= serialNumberService.genSerialNumber();
反解全局序列号
- 描述:对产生的分布式序列号(分布式ID)进行反解,在响应体内返回反解的JSON字符串。
- 类:SerialNumberService
- 方法:expSerialNumber
- 参数:long serialNumber
- 返回类型:SerialNumber
- 示例:SerialNumber serialNumber = serialNumberService.expSerialNumber(3456526092514361344);
翻译时间
- 描述:把长整型的时间转化成可读的格式。
- 类:SerialNumberService
- 方法:transTime
- 参数:long time
- 返回类型:Date
- 示例:Date date = serialNumberService.transTime(12758739);
制造全局序列号(1)
- 描述:通过给定的分布式序列号元素制造分布式序列号。
- 类:SerialNumberService
- 方法:makeSerialNumber
- 参数:long time, long seq
- 返回类型:long
- 示例:long serialNumber= SerialNumberService.makeSerialNumber(12758739, 0);
制造全局序列号(2)
- 描述:通过给定的ID元素制造ID。
- 类:SerialNumberService
- 方法:makeSerialNumber
- 参数:long machine, long time, long seq
- 返回类型:long
- 示例:long serialNumber= serialNumberService.makeSerialNumber(1, 12758739, 0);
制造全局序列号(3)
- 描述:通过给定的分布式序列号元素制造ID。
- 类:SerialNumberService
- 方法:makeSerialNumber
- 参数:long genMethod, long machine, long time, long seq
- 返回类型:long
- 示例:long serialNumber= serialNumberService.makeSerialNumber(0, 1, 12758739, 0);
制造全局序列号(4)
- 描述:通过给定的分布式序列号元素制造ID。
- 类:SerialNumberService
- 方法:makeSerialNumber
- 参数:long type, long genMethod, long machine, long time, long seq
- 返回类型:long
- 示例:long serialNumber= serialNumberService.makeSerialNumber(0, 2, 1, 12758739, 0);
制造全局序列号(5)
- 描述:通过给定的ID元素制造ID。
- 类:SerialNumberService
- 方法:makeSerialNumber
- 参数:long version, long type, long genMethod, long machine, long time, long seq
- 返回类型:long
- 示例:long serialNumber = serialNumberService.makeSerialNumber(0, 0, 2, 1, 12758739, 0);
FAQ
1.调整时间是否会影响ID产生功能?
未重启机器调慢时间,mykit-serial抛出异常,拒绝产生ID。重启机器调快时间,调整后正常产生ID,调整时段内没有ID产生。
2.重启调慢或调快时间有何影响?
重启机器调慢时间,mykit-serial将可能产生重复的时间,系统管理员需要保证不会发生这种情况。重启机器调快时间,调整后正常产生ID,调整时段内没有ID产生。
3.每4年一次同步润秒会不会影响ID产生功能?
原子时钟和电子时钟每四年误差为1秒,也就是说电子时钟每4年会比原子时钟慢1秒,所以,每隔四年,网络时钟都会同步一次时间,但是本地机器Windows,Linux等不会自动同步时间,需要手工同步,或者使用ntpupdate向网络时钟同步。由于时钟是调快1秒,调整后不影响ID产生,调整的1s内没有ID产生。
好了今天就到这儿吧,我是冰河,我们下期见~~
重磅福利
微信搜一搜【冰河技术】微信公众号,关注这个有深度的程序员,每天阅读超硬核技术干货,公众号内回复【PDF】有我准备的一线大厂面试资料和我原创的超硬核PDF技术文档,以及我为大家精心准备的多套简历模板(不断更新中),希望大家都能找到心仪的工作,学习是一条时而郁郁寡欢,时而开怀大笑的路,加油。如果你通过努力成功进入到了心仪的公司,一定不要懈怠放松,职场成长和新技术学习一样,不进则退。如果有幸我们江湖再见!
另外,我开源的各个PDF,后续我都会持续更新和维护,感谢大家长期以来对冰河的支持!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号