09 序列化实现十大接口(包括ListSerializer)
目录
一、十大接口
十大接口就是我们一开始在学习drf框架时,学到的接口规范,我们知道通过两条url路径就可以实现10个接口,完成10种不同的功能,不同的请求
先来介绍一下,实现的是哪十大接口
get请求
实现查看单条数据
实现查看所有数据
post请求
实现增加一条数据
实现增加多条数据
delete请求
实现删除一条数据
实现删除多条数据
put请求
实现整体将一条数据进行修改
实现整体将多条数据进行修改
patch请求
实现将一条数据的局部数据修改
实现将多条数据的局部数据修改
二、所有技术
下面我们就用一个图书管理系统为例,来实现上面所描述的十大接口,先来看看图书馆里系统实现这十大接口功能需要用到哪些技术点吧
1. 数据库
既然我们是做后端开发的,完成接口的,哪我们肯定是免不了和数据库接触的,所以我们既然是用图书管理系统的
我们就将所有的数据保存在数据库中
2. 重写exception_handler异常方法
因为drf自己的异常模块它只处理一些大的异常,一些小的异常信息,它不做处理,所以我们自己自定义方法来处理
drf不处理的异常信息
3. 重写Response响应数据方法
可以实现自己的Response方法,可以响应我们自己想要返回的数据
4. ModelSerializer 序列化组件
帮我们实现后端数据对象序列化为字典数据返回给前台
实现前台数据字典反序列化为数据对象保存在后端数据库中
5.ListSerializer 组件
这个方法里面我们会用到它的update方法。
三、前期准备
1. 创建Django项目
我们创建的是django的项目,但是我们用的rest_Framework的规范,使用的是Rest_Framework
drf的规范
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.serializers import Serializer,ModelSerializer,ListSerializer
from rest_framework.renderers import JSONRenderer,BrowsableAPIRenderer
from rest_framework.views import exception_handler
from rest_framework.parsers import JSONParser,MultiPartParser,DjangoMultiPartParser
·
·
·
2. 注册rest_framework
# settions.py
INSTALLED_APPS = [
# 在此配置中注册
'rest_framework'
]
3. 配置国际化
就是将所有前台的能看到的信息都显示成中文,并且是国际化的时间
# settings.py
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
USE_I18N = True
USE_L10N = True
USE_TZ = False
4. 配置数据库
# settings.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'book_sys',
'USER':'root',
'PASSWORD':'123',
'HOST':'127.0.0.1',
'POST':3303
}
}
# 导入pymysql在settings配置中直接写也可以,在settings中注册的包中的__init__.py文件中写可以
import pymysql
pymysql.install_as_MySQLdb()
四、数据表准备(models.py)
1. 表设计准备
# models.py
from django.db import models
# Base 是作为基表的,因为它内部定义的字段,在很多子表中都用到了
# Base类中Meta类的abstract属性设为True,代表这张基表他的名称空间都可以被子类用,但是这张表不会被创建出来
class Base(models.Model):
is_delete = models.BooleanField(default=False)
create_time = models.DateField(auto_now_add=True)
class Meta:
abstract = True
# 书表
class Book(Base):
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5,decimal_places=2)
#多对多字段------外键 authors
# ManyToManyField字段不提供设置on_delete,如果想设置关系表级联,只能手动定义关系表
authors = models.ManyToManyField(to='Author',related_name='books',db_constraint=False)
#一对多字段-------外键 publish
# db_delete=models.DO_NOTHING表示外键字段publish的Publish表,的数据没了,但是不影响book表
# 出版社被删了,但是还是属于该出版社
# 也就是说实际上出版社是被删了,但是在数据库中还是存在的,只是用一个字段记录他是否删除
# 如果直接删了的话,因为我们是断了关联的,所以就会造成book表会产生脏数据
publish = models.ForeignKey(to='Publish',related_name='books',db_constraint=False, on_delete=models.DO_NOTHING)
class Meta:
# db_table 是控制改模型表存在数据库中用的表名
db_table = 'api_book'
# verbose_name_plural是在django后台管理显示的名字
verbose_name_plural = '书籍表'
def __str__(self):
return self.name
# 作者表
class Author(Base):
name = models.CharField(max_length=32)
sex = models.IntegerField(choices=[(0,'男'),(1,'女')],default=0)
class Meta:
db_table = 'api_author'
verbose_name_plural = '作者表'
def __str__(self):
return self.name
# 作者详情表
class AuthorDetail(Base):
phone = models.CharField(max_length=11)
author = models.OneToOneField(to='Author',
related_name='detail',
db_constraint=False,
on_delete=models.CASCADE)
class Meta:
db_table='api_AuthorDetail'
verbose_name_plural = '作者详情表'
# 出版社表
class Publish(Base):
name = models.CharField(max_length=32)
address = models.CharField(max_length=255)
class Meta:
db_table = 'db_publish'
verbose_name_plural = '出版社表'
2. 表准备知识点总结
一、author 是外键字段,关联着作者表的id
1. 一对一的外键一般是放在查的频率比较高的哪一方,但是如果将外键放在Author表中的话,很有可能出现脏数据
2. 我们知道被关联表Author表的数据被删除时,关联表AuthorDetail表的数据也会被级联删除的
3. 也就是说作者表中的作者被删掉以后,与作者对应的作者详情表的记录数据也被删除了,但是吐过把外键放在作 者表中的话,作者表就是关联表了
4. 删除关联表中的数据,被关联表是不会受影响的,也就是说一个作者的基本信息被删了,但他的详细信息没有被 删除,那它就变成了脏数据了
5. 所以一般我们的外键放在哪里其实是根据实际的开发需求来的
二、 related_name='detail' /反向查询通过别名detail,不需要再表名小写/表名小写_set
1. 我们知道外键在哪张表中,那张表查关联数据就是正向查询
2. ORM中正向查询直接是字段名,就能查出关联的数据对象
3. 反向查询要表名小写,查出对象,为什么反向查询直接表名小写就可以了呢?
# 在创建外键字段的时候,models内部帮我们规定了方向查询的时候是表名小写,
# 如果查的是多条数据的话,那就是表名小写_set
# 实际上创建外键字段的时候,自动帮我们设置了related_name = '规则',所以这个字段我们可以传
# 当我们自己上传related_name参数的时候,它会默认将我们传进去的值作为反向查询时的一个别名
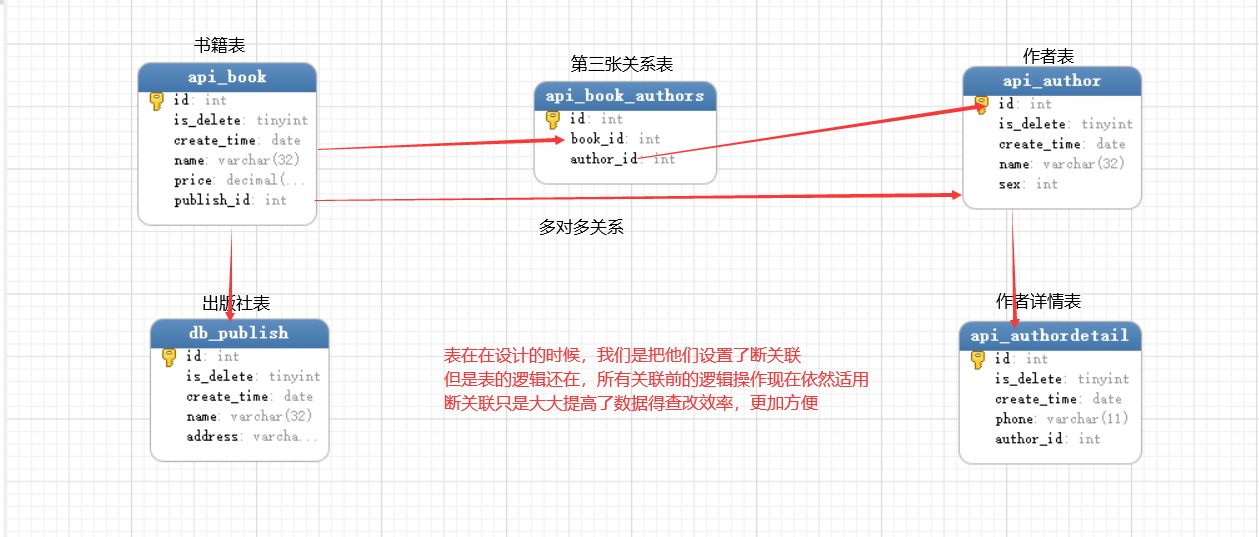
三、 db_constraint=False/通过db_constraint参数设置表之间的关系,False表示表于表之间断关联了,表之间 没有任何的限制条件
1. 但是两张表对应的逻辑还在,也就是说通过连表的操作查询数据都是可以通过ORM正常去操作的,
2. 只是不在限制表之间的级联关系了(增加数据)
3. 我们知道在我们将两张表设置关联以后,我们添加数据要先添加被关联表数据,关联表的数据才可以被创建
4. 删除-必须先删除关联表数据,被关联表数据才能被删除,而这样对数据表的限制就很大,不利于数据表的维护
''' 断关联:
1、表之间没有外键关联,但是有外键逻辑关联(有充当外键的字段)
2、断关联后不会影响数据库查询效率,但是会极大提高数据库增删改效率(不影响增删改查操作)
3、断关联一定要通过逻辑保证表之间数据的安全
'''
四、on_delete=models.CASCADE 设置表与表之间的级联删除
django 1X 版本 关联表之间是默认级联删除的,但是由于我们设置断关联,所以我们要设置on_delete
3. 数据库迁移
打开命令终端:对着敲如下代码
->python manage.py makemigrations--只会生成迁移记录,
->python manage.py migrate--真正在数据库中创建表
打开数据库可视化工具,可以看到如下表的视图
4. 向表中添加数据
设计表时,我们已经设置了段关联了,所以现在我们不用管关联前得一些添加数据得限制了,随便先添加那一个表中得数据都可以
比如作者和作者信息表是一对一的关系,关联之前我们必须要先添加作者表得数据才可以添加作者详情表得数据,上面创建表时我们是把外键设置在了作者详情表中,所以我们现在就先来添加作者详情表得数据(关联表得数据),在添加被关联表得数据也不会错误
# 给作者详情表中添加两条数据
id:1,is_delete:0,create_time:2019-10.21,phone:12233445566,author_id:1
id:2,is_delete:0,create_time:2019-10.22,phone:13344556677,author_id:2
# 给作者表中添加两个作者
id:1,is_delete:0,create_time:2019-10.21,name:'郭敬明',sex:0
id:2,is_delete:0,create_time:2019-10.21,name:'饶雪漫',sex:1
# 给出版社添加三个出版色
id:1,is_delete:0,create_time:2019-10-29, name:'文艺出版社',address:'北京'
id:2,is_delete:0,create_time:2019-12-03, name:'人民教育出版社',address:'上海'
id:3,is_delete:0,create_time:2019-11-06, name:'中公教育出版社',address:'南京'
# 书籍表中添加3个书
id:1,is_delete:0,create_time:2019-11-21,name:'少年的你',price:999.9,publish:1
id:2,is_delete:0,create_time:2019-11-27,name:'小时代',price:25.36,publish:2
id:3,is_delete:0,create_time:2019-10-28,name:'大约在冬季',price:789.5,publish:3
# 书和作者的第三张关系表中添加数据
id:1,book_id:1,author_id:1
id:2,book_id:1,author_id:2
id:3,book_id:2,author_id:2
id:4,book_id:3,author_id:3
五、路由层(urls.py)
# 在与项目名同名的总路由下urls.py文件中通过路由分发的形式将url分发给应用api下的子路由下
总路由:
from django.conf.urls import url,include
from django.contrib import admin
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^api/',include('api.urls')),
]
api下的子路由
from django.conf.urls import url
from . import views
urlpatterns = [
# 我们就通过一下两条url来实现十大接口
url(r'^books/$',views.Books.as_view() ),
url(r'^books/(?P<pk>\d+)',views.Books.as_view() ),
]
六、配置自定义exception_handler
首先在api应用下创建一个utils.py文件,py文件中写我们自定义的exception_handler异常方法
# api/utils.py
from rest_framework.views import exception_handler as drf_exception_handler
from rest_framework.response import Response
def exception_handler(exc,context):
# 先执行drf自己的exception_handler方法,
response = drf_exception_handler(exc,context)
# 判断执行过后的结果是否为空,为空在走我们自己的异常
if response is None:
response = Response(data={'detail':'%s' %exc})
return response
重要的一个步骤
# settings.py中配置异常模块,配置我们自己定义的
# 配置异常模块
REST_FRAMEWORK = {
'EXCEPTION_HANDLER':'api.utils.exception_handler'
}
七、配置自定义的Response模块
在api应用写创建一个response.py文件夹,用的时候,引入到views视图下用
from rest_framework.response import Response
class APIResponse(Response):
# 格式化data
def __init__(self, status=0, msg='ok', results=None, http_status=None, headers=None, exception=False, **kwargs):
data = { # json的response基础有数据状态码和数据状态信息
'status': status,
'msg': msg
}
if results is not None: # 后台有数据,响应数据
data['results'] = results
data.update(**kwargs) # 后台的一切自定义响应数据直接放到响应数据data中
super().__init__(data=data, status=http_status, headers=headers, exception=exception)
八、get请求(单查,群查)
#views.py/ get请求的两个接口
from rest_framework.views import APIView
from . import models
from .response import APIResponse
from . import serializer
class Books(APIView):
# get请求的单查和群查
# 1. 单查、群查
def get(self,request,*args,**kwargs):
# 从get请求携带的拼接参数,获取pk
# pk有值:单查
# pk没有值:群查
pk = kwargs.get('pk')
print(pk)
# 单查
if pk:
book_obj = models.Book.objects.filter(pk=pk,is_delete=False).first()
if not book_obj:
return APIResponse(1,'pk error',http_status=400)
book_data = serializer.BookModelSerializer(book_obj).data
return APIResponse(results=book_data)
# 群查
book_list_obj = models.Book.objects.filter(is_delete=False).all()
if not book_list_obj:
return APIResponse(1,'data error',http_status=400)
return APIResponse(results=serializer.BookModelSerializer(book_list_obj,many=True).data)
九、post请求(单增、群增)
# post请求的单增和群增
# 2. 单增、群增
def post(self,request,*args,**kwargs):
# 获取post请求提交的数据包数据
request_data = request.data
# 判断是否存在数据包数据
if not request_data:# 不存在直接返回
return APIResponse(1,'data error',http_status=400)
# 存在--判断是否为dict类的子类对象
if isinstance(request_data,dict):
# 是:反序列化,指定参数传给data
data_ser = serializer.BookModelSerializer(data=request_data)
# 判断校验是否为True
if data_ser.is_valid():
# True 调用save()放法,内部自动调用了create方法,得到一个对象
data_obj = data_ser.save()
# 将对象序列化返回给前台
return APIResponse(results=serializer.BookModelSerializer(data_obj).data)
else:
# 校验错误,则返回错误信息
return APIResponse(results=data_ser.errors)
# 如果data不是字典类的子类对象,则判断是否为列表的子类对象,并且不能为空的列表
elif isinstance(request_data,list) and len(request_data)!=0:
# 将前台的数据包数据反序列化
data_list_ser = serializer.BookModelSerializer(data=request_data,many=True)
# 判断校验是否正确
if data_list_ser.is_valid():
# 正确调用save()方法,自动create()方法
data_list_obj = data_list_ser.save()
# 将对象序列化返回给前台
return APIResponse(results=serializer.BookModelSerializer(data_list_obj,many=True).data)
# 如果不是字典类的子类对象,也不是列表的子类对象,则返回错误信息
else:
return APIResponse(1,'data error',http_status=400)
十、put请求(整体单改、整体群改)
# put请求的整体单改、整体群改
# 3. 整体单改、整体群改
def put(self,request,*args,**kwargs):
# 取需要更改的数据pk值
pk = kwargs.get('pk')
# 取用户数据包数据
request_data = request.data
# 判断有没有pk,有单改,没有群改
if pk:
try:# 如果有pk的时候,数据库中查的时候可能查不到,这里铺货一下异常
book_obj = models.Book.objects.get(pk=pk)
except:
return APIResponse(1,'pk error')
# 判断put请求携带的用户数据包数据是否为dict的子类对象
if isinstance(request_data,dict):
# 如果是dict的子类对象,那么将原来的book对象和前台传的数据一起给反序列化组件
# instance接收pk对应的原来的book对象
# data 接收前台携带的数据,
data_ser = serializer.BookModelSerializer(instance=book_obj,data=request_data)
# 判断反序列化校验数据是否成功
if data_ser.is_valid():
# 成功则直接save()方法--create()方法
data_obj = data_ser.save()
return APIResponse(results=serializer.BookModelSerializer(data_obj).data)
else:
return APIResponse(results=data_ser.errors)
else:
return APIResponse(1, 'data error')
# 如果没有pk,判断数据包数据是否为列表的子类对象
else:
if not isinstance(request_data,list) or len(request_data) == 0:
return APIResponse(1,'data error')
# [{pk:1,...}, {pk:3,...}, {pk:100,...}] => [obj1, obj3, obj100] + [{...}, {...}, {...}]
# 要考虑pk对应的对象是否被删,以及pk没有对应的对象
# 假设pk3被删,pk100没有 => [obj1] + [{...}]
# 注:一定不要在循环体中对循环对象进行增删(影响对象长度)的操作
obj_list = []
data_list = []
for dic in request_data:
try:
pk = dic.pop('pk')
try:
obj = models.Book.objects.get(pk=pk, is_delete=False)
obj_list.append(obj)
data_list.append(dic)
except:
pass
except:
return APIResponse(1, 'data error', http_status=400)
book_ser = serializer.BookModelSerializer(instance=obj_list,data=data_list,many=True)
if book_ser.is_valid():
book_list_obj = book_ser.save()
return APIResponse(results=serializer.BookModelSerializer(book_list_obj,many=True).data)
else:
return APIResponse(results=book_ser.errors)
十一、patch请求(局部单改、局部群改)
# path请求的局部单改,局部群改
# 4. 局部单改、局部群改
def patch(self,request,*args,**kwargs):
# 取需要更改的数据pk值
pk = kwargs.get('pk')
# 取用户数据包数据
request_data = request.data
# 判断有没有pk,有单改,没有群改
if pk:
try:
book_obj = models.Book.objects.get(pk=pk)
except:
return APIResponse(1, 'pk error')
if isinstance(request_data, dict):
# 局部修改和整体修改的逻辑一摸一样,只要在序列化的参数加partial=True
# partial=True 代表没有传的参数不做任何的校验,使用原来的值
data_ser = serializer.BookModelSerializer(instance=book_obj, data=request_data,partial=True)
if data_ser.is_valid():
data_obj = data_ser.save()
return APIResponse(results=serializer.BookModelSerializer(data_obj).data)
else:
return APIResponse(results=data_ser.errors)
else:
return APIResponse(1, 'data error')
else:
if not isinstance(request_data, list) or len(request_data) == 0:
return APIResponse(1, 'data error')
# [{pk:1,...}, {pk:3,...}, {pk:100,...}] => [obj1, obj3, obj100] + [{...}, {...}, {...}]
# 要考虑pk对应的对象是否被删,以及pk没有对应的对象
# 假设pk3被删,pk100没有 => [obj1] + [{...}]
# 注:一定不要在循环体中对循环对象进行增删(影响对象长度)的操作
obj_list = []
data_list = []
for dic in request_data:
try:
pk = dic.pop('pk')
try:
obj = models.Book.objects.get(pk=pk, is_delete=False)
obj_list.append(obj)
data_list.append(dic)
except:
pass
except:
return APIResponse(1, 'data error', http_status=400)
book_ser = serializer.BookModelSerializer(instance=obj_list, data=data_list, many=True,partial=True)
if book_ser.is_valid():
book_list_obj = book_ser.save()
return APIResponse(results=serializer.BookModelSerializer(book_list_obj, many=True).data)
else:
return APIResponse(results=book_ser.errors)
十二、delete请求(单删、群删)
# delete请求的单删和群删
# 5. 单删、群删
def delete(self, request, *args, **kwargs):
"""
单删:前台数据为pk,接口为 /books/(pk)/
群删:前台数据为pks,接口为 /books/
"""
pk = kwargs.get('pk')
# 将单删群删逻辑整合
if pk: # /books/(pk)/的接口就不考虑群删,就固定为单删
pks = [pk]
else:
pks = request.data.get('pks')
# 前台数据有误(主要是群删没有提供pks)
if not pks:
return APIResponse(1, 'delete error', http_status=400)
# 只要有操作受影响行,就是删除成功,反之失败
rows = models.Book.objects.filter(is_delete=False, pk__in=pks).update(is_delete=True)
if rows:
return APIResponse(0, 'delete ok')
return APIResponse(1, 'delete failed')
十三、自定义Serializer序列化组件
# 在api下创建一个名为Serializer的.py文件
# Serializer.py
from rest_framework import serializers
from . import models
class BookListSerializer(serializers.ListSerializer):
# 1、create方法父级ListSerializer已经提供了
# def create(self, validated_data):
# # 通过self.child来访问绑定的ModelSerializer
# print(self.child)
# raise Exception('我不提供')
# def create(self, validated_data):
# return [
# self.child.create(attrs) for attrs in validated_data
# ]
# 2、父级ListSerializer没有通过update方法的实现体,需要自己重写
def update(self, instance, validated_data):
# print(instance)
# print(validated_data)
return [
self.child.update(instance[i], attrs) for i, attrs in enumerate(validated_data)
]
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
# list_serializer_class是固定的key写法,直接转入BookListSerializer类的update方法
# 群增/群改的时候
list_serializer_class = BookListSerializer
model = models.Book
fields = ['name','price','publish_name','author_list','publish', 'authors']
# 了解
# fields = '__all__'
# exclude = ('id', 'authors','publish')
# depth = 1
# 这里是将序列化和反序列化整合在一起
extra_kwargs = {
'publish':{
'write_only':True
},
'authors':{
'write_only':True
}
}
十四、views视图层知识点总结
1. 前台携带的参数
在这个图书馆里系统中,我们在查数据的时候,增加数据、修改数据、删除数据的时候,前台都是会带着url拼接的参数或者是数据包数据来请求后端的。
我们上面的十大接口时通过两条url来完成十大请求接口的
我们完全使用了drf接口规范,当url为负数的时候,一般是查询所有资源数据
当url为负数的形式,并且在url携带参数的时候,我们是url设置了有名分组的形式,去查询所有数据资源中的某一个资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号