04 Djang 路由层urls.py
一、前言
在前面的一小结学习,我们们已经能够利用命令行和pycharm去创建Django的项目了,也知道Django项目的目录文件是用来干什么的以及用django框架开发web项目时的注意事项。
二、路由器
事实上,在Django的安装及详情使用这里就已经分析过每个文件作用,这里我们来详细的说明以下urls.py文件的作用,它是Django的路由层,那么问题来了,什么叫做路由器呢?
这里不得不重新提到我们的OSI网络模型:

路由器:是连接两个或多个网络的硬件设备,在网络间起网关的作用,是读取每一个数据包中的地址然后决定如何传送的专用智能性的网络设备。它能够理解不同的协议,例如某个局域网使用的以太网协议,因特网使用的TCP/IP协议。这样,路由器可以分析各种不同类型网络传来的数据包的目的地址,把非TCP/IP网络的地址转换成TCP/IP地址,或者反之;再根据选定的路由算法把各数据包按最佳路线传送到指定位置。所以路由器可以把非TCP/ IP网络连接到因特网上。
路由器:又可以称之为网关设备。路由器就是在OSI/RM中完成的网络层中继以及第三层中继任务,对不同的网络之间的数据包进行存储、分组转发处理,其主要就是在不同的逻辑分开网络。而数据在一个子网中传输到另一个子网中,可以通过路由器的路由功能进行处理。在网络通信中,路由器具有判断网络地址以及选择IP路径的作用,可以在多个网络环境中,构建灵活的链接系统,通过不同的数据分组以及介质访问方式对各个子网进行链接。路由器在操作中仅接受源站或者其他相关路由器传递的信息,是一种基于网络层的互联设备。
三、路由层(urls.py)
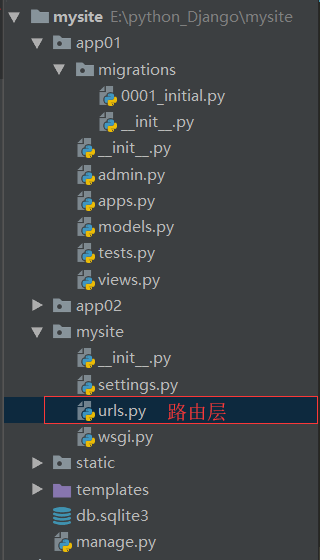
Django中的路由指的就是urls.py文件,称之为路由层
路由层即用户请求地址与视图函数的映射关系,如果被一个网站比喻成一本字典的话,我们这个路由(urls.py)就号比是这个字典的目录,在Django中路由默认在urls.py文件中,如下图:
四、简单的路由配置
# urls.py路由配置文件
from Django.conf.urls import url
# 有一条条映射关系组成的urlpatterns这个列表称之为路由表
urlpatterns = [
url(regex,view,kwargs=None,name=None),
#url本质就是一个函数
]
函数url关键参数介绍:
- regex:正则表达式,用来匹配客户端访问url地址的路径部分
- 例如:url的地址为http: //127.0.0.1:8000/index/,正则表达式要匹配的部分是index/
- view:通常是一个url对应的视图函数,用来处理业务逻辑
- kwargs:略(用法详见有名分组)
- name:略(用法详见反向解析)
案例如下:
# urls.py文件
from django.conf.urls import url
from django.contrib import admin
from app01 import views # 导入视图函数模块views.py
urlpatterns = [
url(r'^admin/',admin.site.urls),# 这里是新建一个django项目默认自带的,不用管它
url(r'^index/$',views.index),#这是新增的一条地址与视图函数的对应关系
]
# views.py视图函数文件
from django.shortcuts import render
from django.shortcuts import redirect
from django.shortcuts import HttpResponse # 导入HttpResponse,用来生成响应信息,就是直接可以返回字符串,将字符串处理过后响应给客户端
def index(request):
return HttpResponse('这是index.page')
测试如下:
# 启动服务端方式一:命令行
-->:python manage.py runserver 8001 # 这里启动的时候,可以指定端口号:8001,默认为8000
在浏览器中输入http://127.0.0.1:8001/index/ 就会看到‘我是index.page’
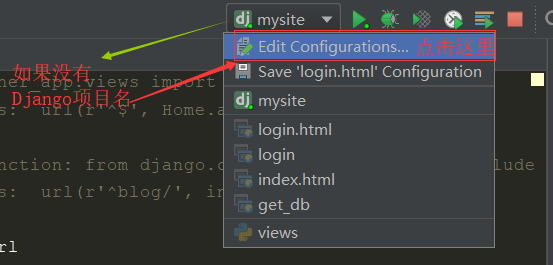
# 启动服务端方式二:直接在pycharm窗口中启动
-->:这里要提前在下图中进行配置:
pycharm窗口:启动Django项目server端方法如下图:

4.1 注意一
刚刚我们在浏览器输入:Http: //127.0.0.1:8001/index/,Django会拿着路径部分index/去路由表(urls.py文件)中自上而下匹配正则表达式,一旦匹配成功,则会立即执行该路径对应的视图函数,也就是上面路由表(urls.py文件)中的uelspatterns列表中的url('^index/$',views.index)-----也就是views.py视图函数文件的index函数
4.2 注意二
当我们在浏览器中输入:Http: //127.0.0.1:8001/index,Django同样会拿着路径部分index去路由表中自上而下匹配正则表达式,看起来好像是匹配不到正则表达式(r'^index/$' 匹配的是必须以/结尾,所以必会匹配到成功index),但是实际上我们依然在浏览器宽口中看到了 ‘我是indexpage’,其原因如下:
在配置文件settings.py中有一个参数APPEND_SLASH,该参数有连个值True/False:
-
当APPEND_SLASH = True(如果配置文件中没有该配置,则默认值为True),并且用户请求的url地址的路径部分不是以/结尾,例如请求的url地址为:Http: //127.0.0.1:8001/index,Django也会拿着部分地址 index 去路由表中匹配正则表达式,发现匹配不成功,那么Django会在路径后加/(index/)在去路由表中匹配,去过还匹配不到,会返回路径找不到,如果匹配成功,则会返回重定向信息给浏览器,要求浏览器重新向Http: //127.0.0.1:8001/index/地址返送请求。
-
当APPEND_SLASH = False时,则不会执行上述过程,即以但url地址的路径部分匹配失败就立即返回路劲未找到,不会做任何的附加操作
五、路由分组

什么是分组,为何要分组呢?
比如我们开发了博客系统,当我们需要根据文章的id查看指定的文章时,浏览器在发送请求时需要向候田传递参数(文章的id号),可以使用 Http: //127.0.0.1:8001/article/?id=3,也可以直接将参数放到路径中 Http: //127.0.0.1:8001/article/3/
针对后一种方式Django就需要直接从路劲中获取参数,这就用到了正则表达式的分组功能了,分组分为两种:无名分组与有名分组
5.1 无名分组
# urls.py文件
from django.conf.urls import url
from django.contrib import admin
from app01 import views # 添加app001应用中的views视图函数文件
urlpatterns = [
url(r'^admin',admin.site.urls),
# 下面的正则表达式会匹配url地址的路径部分为:article/数字/,匹配成功的分组部分会以位置参数的形式传给视图函数,有几个分组就传几个位置参数
url(r'aritcle/(\d+)/$',view.article),#(\d+)代表匹配数字1-无穷个
]
# views.py视图文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
# 需要额外增加一个形参用于接收传递过来的分组数据
def article(request,article_id):
return HttpResponse('id为 %s 的文章内容....' %article_id)
# 测试
python.manage.py runserver 8001
在浏览器输入:http: //127.0.0.1:8001/article/3 会看到:id为3的文章内容....
5.2 有名分组
# urls.py文件
from django.conf.urls import url
from django.contrib import admin
from app01 import views # 添加app001应用中的views视图函数文件
urlpatterns = [
url(r'^admin',admin.site.urls),
# 下面的正则表达式会匹配url地址的路径部分为:article/数字/,匹配成功的分组部分会以关键字参数(article_id=..)的形式传给视图函数,有几个分组就传几个关键字参数
url(r'aritcle/(?P<article_id>\d+)/$',view.article),#(\d+)代表匹配数字1-无穷个
]
# views.py视图文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
# 需要额外增加一个形参用于接收传递过来的分组数据
def article(request,article_id):
return HttpResponse('id为 %s 的文章内容....' %article_id)
# 测试
python.manage.py runserver 8001
在浏览器输入:http: //127.0.0.1:8001/article/3 会看到:id为3的文章内容....
5.3 无名分组和有名分组的区别
无名分组和有名分组都是为了获取路径中参数,并传递给视图函数,区别如下:
- 无名分组是以位置参数的形式传递给对应的视图函数,此时在路由表(urlpatterns)中的正则中有几个无名分组,那么在其对应的视图函数中,就要有几个位置参数去接收,在上面的例子中,只有一个无名分组3 ,那么传递给视图函数的则是(views.article(request,'3'))
- 有名分组是以关键字参数的形式传递给对应的视图函数的,此时在路由表(urlpatterns)中的正则中有几个又名分组,那么在其对应的视图函数中,可以用**kwargs来收参数,也可以直接写成关键字参数的形式,上面的例子则是
views.article(request,article_id='3')
注意:无名分组和又名分组不要混合使用
六、路由分发
随着Django项目的功能的增加,app应用会越来越多,路由也会越来越多,每个app都会有属于自己的路由,如果再讲所有的路由都放在一张路由表中,会导致结构不清晰,不便于项目的维护和管理,所以我们应该将app自己的路由交由自己来管理,然后再总路由表中做分发,具体做法如下:
6.1 创建两个app
# 新建项目mysite1---此处用命令行命令创建
# 切换到存储项目的目录下
django-admin startproject mysite1
# 切换到新建的项目下
# 创建两个app项目(app01和app02)
python3 startapp app01
python3 startapp app02
此处注意以下三点:
- 自己用命令行创建的django项目,需要自己手动去创建templates文件夹来存放需要用到的.html文件
- 并且去settings的TEMPLATES中配置:'DIRS': [os.path.join(BASE_DIR,'templates')]
- 在settings的INSTALLED_APPS中去配置‘app01’ ‘app02’
6.2 手动在app中创建urls.py存放自己的路由
1. app01下的urls.py路由表文件
from django.conf.urls import url
# 导入app01 的views
from app01 import views
urlpatterns = [
url(r'^index/$',views.index),
]
app01下的views.py视图函数文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
def index(request):
return HttpResponse('我是app01下的index页面。。。。。')
2. app02下的urls.py路由表文件
from django.conf.urls import url
# 导入app02 的views
from app02 import views
urlpatterns = [
url(r'^index/$',views.index),
]
app02下的views.py视图函数文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
def index(request):
return HttpResponse('我是app02下的index页面。。。。。')
6.3 总的mysite1文件夹的路由表中urls.py
from django.conf.urls import url,include
from django.contrib import admin
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 因为功能太多,所以在总的路由表中,做路由分发,分发给各个app功能应用
# 新增的两条路由,注意不能以$结尾
# include函数就是做分发操作的,当浏览器输入http://127.0.0.1:8001/app01/index时
# 会先进入到总路由表中进行匹配,正则表达式r'^app01/'会先匹配成功路径app01/
# 然后include功能函数就会去app01下的urls.py中继续匹配剩余的路径部分
url(r'app01/',include('app01.urls')),
url(r'app02/',include('app02.urls'))
]
测试:
# 先启动项目server端---命令行式:python manage.py runserver 8001
1.在浏览器中输入:Http://127.0.0.1:8001/app01/index/
会看到我是app01下的index页面。。。
2.在浏览器中输入:Http://127.0.0.1:8001/app02/index/
会看到我是app02下的index页面。。。
七、反向解析
问题:在软件开发初期,url地址的路径设计可能并不完美,后期需要进行调整,如果项目中很多地方都使用了改路径,一旦该路径发生了变化,就意味着所有使用改路径的地方都需要进行修改,这是一个非常麻烦的操作。
解决方案:就是在编写一条url( regex,view,kwargs=None,name=None)时,可以通过参数name为url地址的路径部分起一个别名,项目中就可以通过别名来获取这个路径。以后无论路径发生如何变化别名与路径始终保持一致。
上述这样通过别名获取路径的过程称之为反向解析:也就是说,通过一串字符串反向解析为访问这个地址的路径
案例:登录成功后跳转到index.html页面
# urls.py路由文件中
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/',admin.site.urls),
# login/别名的为login_page
url(r'^login/$',views.login,name='login_page'),
# index/别名的为index_page
url(r'^index/$',views.index,name='index_page'),
]
# views.py视图函数文件中
from django.shortcuts import render
from django.shortcuts import reverse
from django.shortcuts import redirect
from django.shortcuts import HttpResponse
def login(request):
if request.method == 'GET':
# 当为浏览器为get请求时,返回login.html页面,
# 页面中{% url'login_page' %}会被反向解析成路径:/login/
return render(request,'login.html')
# 当浏览器为post请求时,可以从request.POST中取出请求体数据
name = request.POST.get('name')
pwd = request.POST.get('pwd')
if name == 'cecilia' and pwd == '123':
# reverse会将别名index_page反向解析为路径/index/
url = reverse('index_page')
# 重定向到/index/
return redirect(url)
else:
return HttpResponse('用户名密码错误!')
def index(request):
return render(request,'index.html')
# login.html页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>登录页面</title>
</head>
<body>
<!--login_page必须要加引号-->
<form action="{% url 'login_page' %}" method="post">
{% csrf_token %} <!--强调这一行必须要加,后续会说明-->
<p>用户名:<input type="text" name="name"></p>
<p>密码:<input type="password" name="pwd"></p>
<p>提交:<input type="submit" value="提交"></p>
</form>
</body>
</html>
# index.html页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首页</title>
</head>
<body>
<h3>我是index页面</h3>
</body>
</html>
测试:
# 先启动django项目server端----命令行
python manage.py runserver 8001
1. 在浏览器输入:Http://127.0.0.1:8001/login
# 会看到登录页面,输入正确的用户名密码会跳转到index.html
2.当我们修改路由表中匹配路径的正则表达式时,程序其他部分都不用修改
总结:
在views.py视图函数文件中,反向解析的使用:
url = reverse('index_page')
在login.html文件中,反向解析的使用
{% url 'login_page'%}
扩展阅读:如果路径存在分组的方向解析使用
# urls.py路由文件
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/',admin.site.urls),
url(r'^article/(\d+)/$',view.article,name='article_page'),#无名分组
url(r'^user/(?p<uid>\d+)/$',view.article,name='user_page'),#有名分组
]
# 1. 针对无名分组,比如我们要反向解析处:/article/1/这种路径,写法如下
在views.py中,反向解析的使用
url = reverse('article_page',args=(1,))
在模板login.html文件中,反向解析的使用
{% url 'article_page' 1 %}
# 2.针对有名分组,比如我们要反向解析出:/user/1 这种路径,写法如下
在view.py中,反向解析的使用
方式一: url = reverse('article_page',args=(1,))
方式二: url = reverse('user_page',kwargs={'uid':1})
在模板login.html文件中,反向解析的使用
方式一:{% url 'article_page' 1 %}
方式二:{% url 'user_page' uid=1 %}
总结:无名分组和有名分组的反向解析,只要记一种就行了。
八、名称空间
当我们的项目下创建了多个app,并且每个app下都针对匹配的路径起了别名,如果别名存在重复,那么在返回解析时则会出现覆盖,如下
8.1 创建两个app
# 新建项目mysite2---此处用命令行命令创建
# 切换到存储项目的目录下
django-admin startproject mysite2
# 切换到新建的项目下
# 创建两个app项目(app01和app02)
python3 startapp app01
python3 startapp app02
此处注意以下三点:
- 自己用命令行创建的django项目,需要自己手动去创建templates文件夹来存放需要用到的.html文件
- 并且去settings的TEMPLATES中配置:'DIRS': [os.path.join(BASE_DIR,'templates')]
- 在settings的INSTALLED_APPS中去配置‘app01’ ‘app02’
8.2 手动在app中创建urls.py存放自己的路由
1. app01下的urls.py路由表文件
from django.conf.urls import url
# 导入app01 的views
from app01 import views
urlpatterns = [
# 为匹配的路径app01/index/起别名’index_page‘
url(r'^index/$',views.index,name='index_page'),
]
2.app02下的urls.py路由文件
from django.conf.urls import url
# 导入app02 的views
from app02 import views
urlpatterns = [
# 为匹配的路径app02/index/起别名’index_page‘,与app01中的别名相同
url(r'^index/$',views.index,name='index_page'),
]
8.3 在每个app下的views.py中编写视图函数
在视图函数中正对别名’index_page‘ 做反向解析
1. app01下的views.py视图函数文件
from django.shortcuts import reverse
from django.shortcuts import render
from django.shortcuts import HttpResponse
def index(request):
url = reverse('index_page')
return HttpResponse('我是app01下的index页面。。。,反向解析结果为%s' %url)
app02下的views.py视图函数文件
from django.shortcuts import reverse
from django.shortcuts import render
from django.shortcuts import HttpResponse
def index(request):
url = reverse('index_page')
return HttpResponse('我是app02下的index页面。。。,反向解析结果为%s' %url)
8.4 总的mysite2文件夹的路由表中urls.py
from django.conf.urls import url,include
from django.contrib import admin
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 因为功能太多,所以在总的路由表中,做路由分发,分发给各个app功能应用
# 新增的两条路由,注意不能以$结尾
# include函数就是做分发操作的,当浏览器输入http://127.0.0.1:8001/app01/index时
# 会先进入到总路由表中进行匹配,正则表达式r'^app01/'会先匹配成功路径app01/
# 然后include功能函数就会去app01下的urls.py中继续匹配剩余的路径部分
url(r'app01/',include('app01.urls')),
url(r'app02/',include('app02.urls'))
]
8.5 测试:(覆盖问题)
# 先启动项目server端---命令行式:python manage.py runserver 8001
1.在浏览器中输入:Http://127.0.0.1:8001/app01/index/
会看到我是app02下的index页面。。。,反向解析的结果为/app02/index/
2.在浏览器中输入:Http://127.0.0.1:8001/app02/index/
会看到我是app02下的index页面。。。,反向解析的结果为/app02/index/
在测试时,我们发现如论在浏览器中输入:Http: //127.0.0.1:8001/app01/index/ 还是
Http: //127.0.0.1:8001/app02/index/ 针对别名’index_page‘方向解析的结果都是/app02/index/,覆盖了app01下别名的解析。
8.6 解决办法
解决办法:就是避免使用相同的别名,如果就想使用相同的别名,那就需要用到django中名称空间的概念了,将别名放到不同的名称空间中,这样即便是出现重复,彼此也不会冲突,具体做法如下
-
总( mysite2 下)urls.py在做路由分发时,指定名称空间
from django.conf.urls import url,include from django.contrib import admin # 总路由表 urlpatterns = [ url(r'^admin/', admin.site.urls), # 传给include功能一个元组,元组的第一个值是路由分发的地址 # 第二个值是我们为名称空间起的名字 url(r'^app01/',include(('app01.urls','app01'))), url(r'^app02/',include(('app02.urls','app02'))) ] -
修改每个app下的views.py中的视图函数,针对不同的名称空间中的别匿名’index_page‘做反向解析
app01下的view.py视图函数
from django.shortcuts import reverse from django.shortcuts import render from django.shortcuts import HttpResponse def index(request): # 解析的是名称空间app01下的别名’index_page‘ url = reverse('app01:ndex_page') return HttpResponse('我是app01下的index页面。。。,反向解析结果为%s' %url)app02下的view.py视图函数
from django.shortcuts import reverse from django.shortcuts import render from django.shortcuts import HttpResponse def index(request): # 解析的是app02下的名称空间的别名’index_page‘ url = reverse('app02:index_page') return HttpResponse('我是app02下的index页面。。。,反向解析结果为%s' %url)
8.7 测试(解决测试问题)
python manage.py runserver 8001
浏览器输入:Http://127.0.0.1:8001/app01/index/ 反向解析的结果是/app01/index/
浏览器输入: Http://127.0.0.1:8001/app02/index/ 反向解析的结果是/app02/index/
8.8 总结+补充
1. 在视图函数中基于名称空间的反向解析,用法如下
url = reverse('名称空间的名字:待解析的别名')
2.在模板里基于名称空间的反向解析,用法如下
{% url '名称空间的名字:待解析的别名'%}
九、Django2.0版的re_path与path
9.1 re_path
Django 2.0 中的re_path 与 Django 1.0 的 url 一样,传入的第一个参数都是正则表达式
from django.urls import re_path # django 2.0 中的re_path
from django.conf.urls import url # 在django2.0中同样可以导入1.0中的url
urlpatterns = [
# 用法完全一致
url(r'^app01/',include(('app01.urls','app01'))),
re_path(r'^app02/',include(('app02.urls','app02'))),
]
9.2 path
在Django 2.0 中新增了一个path功能,用来解决:数据类型转换问题与正则表达式冗余问题,如下
# urls.py 文件
from django.urls import re+path
from app01 import views
urlpatterns = [
# 问题一:数据类型转换
# 正则表达式会将请求路径中的年份匹配成功然后以str类型传递函数year_archive
# 在函数year_archive中如果想要以int类型的格式处理年份,则必须进行数据类型转换
re_path(r'^articles/(?P<year>[0-9]{4})/$',views.year_archive),
# 问题二:正则表达式冗余
# 下述三个路由中匹配article_id 采用了同样的正则表达式,重发编写了三遍,存在冗余问题,并且极不容易管理,因为以但articles_id规则需要改变,则必须同时修改三处的代码
re_path(r'^articles/(?P<article_id>[a-zA-z0-9]+)/detail/$',view,detail_view),
re_path(r'^articles/(?P<article_id>[a-zA-z0-9]+)/edit/$',view,edit_view),
re_path(r'^articles/(?P<article_id>[a-zA-z0-9]+)/delete/$',view,delete_view),
]
# views.py视图文件
from django.shortcuts import render,HttpResponse
def year_archive(request,year):
print(year,type(year))
return HttpResponse('year_archive page')
def detail_view(request,article_id):
print(article_id,type(article_id))
return HttpResponse('detail_view page')
def edit_view(request,article_id):
print(article_id,type(article_id))
return HttpResponse('edit_view page')
def delete_view(request,article_id):
print(article_id,type(article_id))
return HttpResponse('delete_view page')
django2.0中的path如何解决上述两个问题的呢?请看示例
# urls.py路由文件
from django.urls import re+path
from app01 import views
urlpatterns = [
# 问题一的结局方案
path('^articles/<int:year>/',views.year_archive),
# <int:year>相当于一个有名分组,其中int是django提供的转换器
# 相当于正则表达式,专门用于匹配数字类型
# 而year则是我们为有名分组名的名,并且int会将匹配成功后的结果转换位整型后按照格式(year=整型值),传给函数year_archive
# 问题二的解决办法
# 用一个int转换器可以替代对出正则表达式
path('^articles/<int:article_id>/detail/',view,detail_view),
path('^articles/<int:article_id>edit/',view,edit_view),
path('^articles/<int:article_id>delete/',view,delete_view),
]
强调:
- path 与 re_path 或者1.0中的url的不同之处是,传给path的第一个参数不在是正则表达式,而是一个完全匹配的路径,相同指出是第一个参数中的匹配字符不用加前导斜杠
- 使用尖括号(<>)从url中捕获值,相当于有名分组
- <>中可以包含一个转化器类型(converter type),比如使用<int:name>使用了转化器int。如没有转化器将匹配任何字符串,当然也包括 / 字符
django:默认支持5中转换器(Path converters)
str:匹配处理路径分隔符(/)之外的非空字符串,这是默认的形式
int:匹配正整数,包含0
slug:匹配字母,数字及斜杠、下划线组成的字符串
uuid:匹配格式化的uuid,如075194d3-6885-417e-a8a8-6c931e272f00
path:匹配任何非空字符串,包含路径分隔符(/)(不能用?)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号