

一天在公司与几位负责紧急救援电话支持服务的同事聊天,当我询问客户主要有哪些求救电话时,他们告诉我最多的求救电话是两类:一类是数据库宕机或挂起,特别是RAC 数据库出现宕机,另外一类则是数据库坏块问题。前者在我意料之中,而后者则有点出乎我的意料。但仔细一想,事实的确可能如此。大家千万别小看数据坏块的处理,从危害程度而言,几个小小数据坏块的确可能导致客户核心数据不可访问,甚至丢失。而从技术角度而言,数据坏块处理涉及的内部机制和处理方法是非常复杂的。为此,Oracle有若干专题文章是讲述数据坏块处理的。
本章我们先从若干案例介绍起,先让大家从不同层面感触一下数据库坏块处理的多样性和复杂性,然后将详细介绍坏块的处理流程,坏块的定位和相关解决方案,例如使用DBMS_REPAIR包或设置10231事件、ROWID扫描方法等。
可怕的数据库坏块
案例1:逻辑坏块导致的坏块
第一个案例来自于国税某系统,笔者在《品悟性能优化》的第十七章曾经“绘声绘色”地叙述过。本书再次摘要该案例主要内容如下:
- 故障现象和原因
首先,了解到共有18个数据坏块,三个表核心业务表分别有一个数据坏块,其他15个坏块为索引。
其次,了解硬件特别是存储并没有报错,说明很可能是逻辑坏块。
再其次,了解到前一天的RMAN备份顺利完成,意味着RMAN备份集已经包含了数据逻辑坏块。
- 处理方案和结果
针对上述具体情况,分别制定了不同的处理方案。
- 首先不能直接通过RMAN进行恢复,因为备份集很可能已经包含了逻辑坏块,如果恢复只能同样恢复成坏块。
- 针对索引,采取重建索引到新的数据文件的方案,并获得了成功。
- 针对三个核心业务表,先采取了设置event=”10231 trace name context forever, level 10”,或者通过SKIP_CORRUPTION_BLOCKS方法,试图将坏块之外的数据读出来,但都没有成功。
- 与应用开发人员进一步沟通,发现其中一张表为汇总统计表,于是采取了重新运行汇总程序的办法,重新生成了该表并移到一个新的物理位置。
- 为减少数据损失,对剩余2张表采取了ROWID Range Scan技术。其中一个表获得了成功,但1000多万的表丢失了4条记录。而另外一个表却没有成功。
- 针对最后一张表,只好采用了最后一个不得已的招术:Oracle的内部技术DUL。最终也基本获得了成功,400多万的表丢失了10多条记录。
案例2:CPU损坏导致的坏块
- 故障现象和原因
该案例来自于某省移动BOSS系统。具体故障现象表现为:数据库实例宕机,数据库也异常关闭。在客户请求Oracle紧急现场救援服务,Oracle工程师赶到现场之后,经过分析alert.log日志发现:Online Redo Log出现坏块,Oracle在发现Redo Log校验失败之后,为保护数据,Oracle主动关闭数据库实例和数据库。
在硬件公司的积极配合下,后来发现导致该故障的最终原因是数据库服务器的CPU损坏,导致Oracle的Online Redo Log被写坏。
- 处理方案和结果
Oracle工程师在现场评估了问题原因和影响范围之后,最终确定通过RMAN进行数据库的不完全恢复,即只恢复到出现坏块的Online Redo Log的前一个。该数据库已经达到TB级,为此花费了20多个小时才完成了该核心系统的不完全恢复。由于恢复期间,数据库处于Mount状态,意味着业务不得不停顿了20多个小时。更严重的是,由于是不完全恢复,导致丢失了一个多小时的业务数据。
事后,本人在与承担具体抢救任务的同事聊天时,他坦言:其实他当时是恢复到出现坏块的Online Redo Log的前两个,而不是前一个。原因是他担心前一个也有坏块,而Oracle可能没有及时检查出来。如果出现这种不幸,那Oracle数据库还是无法打开,可能要再次进行恢复。他说宁可客户数据多丢一点,也要保证数据库尽快顺利地打开,及时恢复正常业务。他当时还很神秘地告诉我:千万别告诉客户哦,客户还以为只丢了一个日志文件的数据呢。抱歉,哥儿们,今天在这儿泄露你的秘密了。呵呵。
案例3:Oracle Bug导致的坏块
- 故障现象
2011年3月21日5:10分左右,某银行系统出现异常,具体情况如下:
- 数据库在预分配空间时出现异常,报空间分配失败
- 账务流水表出现数据块逻辑读写错误,不可读写,进而中断交易。
- smon后台进程不断尝试恢复损坏的数据块,恢复后将实例2自动关闭。
- 处理方案和结果
Oracle公司工程师在分析故障原因之后,采取了如下措施:
- 关闭ORACLE数据库一致性保护校验(初始化参数:db_block_checksum改为false)
- 删除账务流水表
- 重建账务流水表
至10:05分,最终恢复了正常业务。
在事故处理过程中,该银行还进行了恢复丢失的账务流水数据、数据追加、数据库多次全库备份、数据一致性验证等工作,在此不赘述。
- 事故原因分析
根据Oracle公司提交的故障处理报告,最终确定导致数据库出现逻辑坏块的根本原因是Bug所导致。
- 由故障引发的架构性改造
可见,上述数据坏块故障导致了该银行某系统约5小时的业务停顿。如何有效防范同类事故的发生,引起该银行各级领导和技术人员高度关注,并确定在已经通过存储镜像技术建立同城容灾系统基础上,开展数据库备援系统建设。为此,确定了建设总目标如下:
- 备援系统将与生产系统建立在同一机房。即不是地理意义上的容灾系统。
- 在发生类似上述数据坏块故障时,并不是切换到容灾系统。事实上,通过存储镜像技术建立的容灾系统,无法防范数据坏块的传播。
- 在发生类似上述逻辑坏块故障时,为降低故障影响面,也不是将生产系统直接切换到备援系统。而是优先考虑通过备援系统,快速抢救和恢复被损坏数据。
- 如果故障影响面较大,才考虑将生产系统直接切换到备援系统。
坏块处理主要流程
导致数据库坏块的原因
Oracle数据库坏块分类物理坏块和逻辑坏块。所谓物理坏块是由于硬件I/O故障或操作系统故障而引起的数据块写入错误,而逻辑坏块通常是Oracle软件问题导致,具体为数据块头信息被写坏,导致头信息与数据块内容不匹配。可见,导致数据库坏块的原因很多,例如主机硬件故障、存储硬件和软件故障、操作系统故障、Oracle软件故障等,甚至应用软件压力过大都可能导致数据库出现坏块。
但有一种坏块现象则是正常现象。即当对某个数据对象以nologging方式实施了操作,例如“alter index <索引名> rebuild nologging”,而事后又对包含该对象的数据文件通过日志进行了recover操作。这样,该对象所对应的数据块将被Oracle标识为corrupt,当访问这些坏块时, Oracle将报ORA-1578错误。这种情况下,虽然可以通过下述方法查询出哪些数据对象出现坏块,但不仅无法通过recover恢复数据,也无法通过其它手段有效地从坏块中抢救数据。客户唯一能做的就是小心、小心,再小心,不要对nologging操作的数据对象进行recover操作!
坏块处理主要流程
区区几个数据库坏块,带来的影响可能是致命的。如何提高坏块处理效率,降低坏块影响范围?就象世界处理所有紧急突发事件一样,一定要事先有预案和处理流程。以下就是Oracle公司提供的坏块处理主要流程图:

下面我们就按此流程图展开更详细的描述:
确定问题范围
首先,一旦发现出现数据库坏块,应该记录下有关坏块的所有信息,包括alert.log文件和trace文件记录的信息,确定坏块涉及的范围。例如应该评估是单个数据坏块,还是因为对nologging操作的数据对象进行recover操作之后引起的大量坏块。
此时,Oracle建议最好能通过DBVERIFY工具对坏块所在的数据文件和其它文件进行扫描,分析是否有更多坏块的存在,从而更准确地确定问题范围。如果我们获取了详细的数据文件/坏块清单,我们就可有的放矢,显著提高坏块处理效率。
Oracle建议的一些最佳实践经验如下:
- 完整记录原始的坏块出错信息,以及遇到坏块的应用模块信息。
- 将首次遇到坏块的几小时至当前时间的log信息抽取出来,单独保存为一个文件进行重点分析。
- 将log文件中涉及的trace 文件进行保存。
- 了解硬件和操作系统级是否存在报错信息。
- 查询硬件和存储是否采用异步I/O(ASYNC I/O),磁盘快速写(Fast Write Disk)等技术。
- 查询当前Oracle备份信息,备份时间、备份类型、备份地点等。
- 查询数据库是否是归档或非归档模式。
检查和替换有问题的硬件
通常而言,大部分坏块是由于硬件故障而导致的。因此,在在进行坏块数据修复之前,最好对硬件进行充分检查,特别是当出现大量数据坏块或者错误是偶发性的时候。而且,根据Oracle经验,操作系统报错可能会滞后,甚至即便操作系统检查正常,也不代表硬件就一切正常。
因此,在坏块数据修复之前,最好能将有故障或疑似有故障的硬件进行替换或修复。如有可能,最好将故障存储设备的数据文件移到正常的存储设备。具体步骤如下:
步骤如下:
- 将表空间设置为offline状态。例如:
SQL> alter tablespace userdata offline;
- 通过操作系统命令移动或复制数据文件。例如:
cp /u01/oradata/userdata01.dbf /u01/oradata/userdata01.dbf
或
mv /u01/oradata/userdata01.dbf /u01/oradata/userdata01.dbf
- 执行 alter tablespace rename datafile命令。例如:
ALTER TABLESPACE userdata RENAME DATAFILE
‘/u01/oradata/userdata01.dbf’
TO ‘/u01/oradata/userdata01.dbf’;
该命令只适合于移动非SYSTEM表空间的数据文件以及不包含活跃(active)undo、temporary的数据文件。
- 将表空间设置为online状态。例如:
SQL> alter tablespace userdata online;
- 可将原来的数据文件删除。例如:
rm /u01/oradata/userdata01.dbf
确定坏块影响的数据库对象
接下来的第三个重要步骤就是确定坏块影响的数据库对象,该步骤同样非常重要。在后面叙述坏块恢复操作时,大家就会看到:不同类型数据库对象的坏块,处理方法是完全不同的。更重要的是:大家千万别搞错坏块所在的数据文件,以及坏块所包含的数据库对象。否则,连恢复的数据库对象都搞错了,那可就是错上加错了。呵呵。
为此,Oracle官方建议最好能制定如下一张坏块信息表,以便进行坏块信息记录和处理过程跟踪:

下面将详细介绍该表格的各项内容及相关术语,以及信息获取办法:
- Original Error
即系统记录的原始错误信息,包括ORA-1578 / ORA-1110 , ORA-600及该错误的相关参数等。
- Absolute File# &AFN和Relative File# &RFN
Absolute File#表示绝对文件号,简称&AFN,表示数据库级的文件编号。而Relative File#表示相对文件号,简称&RFN,表示表空间级的文件编号。
通常而言, Oracle从8i开始,绝对文件号和相对文件号就是相同的了,除非数据库是从Oracle 7版升级和迁移而来。通过如下语句可查询出数据库的所有表空间和对应的绝对文件号和相对文件号:
SELECT tablespace_name, file_id “AFN”, relative_fno “RFN” FROM dba_data_files;
- &FILENAME
即包含坏块的数据文件名。
- &BL
即出现坏块的数据块编号。
- &TSN和&TABLESPACE_NAME
即出现坏块的表空间编号和表空间名称。
上述&AFN、&RFN、&FILENAME、&BL、&TSN和&TABLESPACE_NAME等信息,在出现坏块的原始错误信息中均可获取,例如,出错信息如下:
ORA-01578: ORACLE data block corrupted (file # 7, block # 12698)
ORA-01110: data file 22: ‘/oracle1/oradata/V816/oradata/V816/users01.dbf’
则:
&AFN : “22” (from the ORA-1110 portion of the error)
&RFN : “7” (from the “file #” in the ORA-1578)
&BL : “12698” (from the “block #” in the ORA-1578)
&FILENAME: ‘/oracle1/oradata/V816/oradata/V816/users01.dbf’
&TSN、&TABLESPACE_NAME 则通过如下语句获取:
SELECT ts# “TSN” FROM v$datafile WHERE file#=&AFN;
SELECT tablespace_name FROM dba_data_files WHERE file_id=&AFN;
&TS_BLOCK_SIZE可通过如下语句获取:
SELECT block_size FROM dba_tablespaces WHERE tablespace_name = (SELECT tablespace_name FROM dba_data_files WHERE file_id=&AFN);
另外,如果v$datafile视图不包括出错的&AFN号,并且&AFN号大于DB_FILES初始化参数,则该文件应该是TEMPFILE。为此,可通过如下语句查询出该文件名:
SELECT name FROM v$tempfile WHERE file#=(&AFN – &DB_FILES_value);
也能通过如下语句,查询出TEMPFILE的&AFN号和&RFN号:
SELECT tablespace_name, file_id+value “AFN”, relative_fno “RFN”
FROM dba_temp_files, v$parameter
WHERE name=’db_files’;
- Segment Type,Segment Owner, Segment Name
即坏块的数据段类型、属主名和数据段名称,基于&AFN和&BL值,通过如下语句可查询出这些信息:
SELECT tablespace_name, segment_type, owner, segment_name
FROM dba_extents
WHERE file_id = &AFN
and &BL between block_id AND block_id + blocks – 1;
如果坏块是TEMPFILE,则上述查询的Segment Type值将为“TEMPORARY”,其它字段将为空。
如果上述查询没有返回记录,则坏块就位于本地化管理表空间(Locally Managed Tablespace,简称LMT)的段头(Segment Header)。针对这种情况,Oracle不仅会在alert.log中进行记录,而且通过如下语句可获得进一步信息:
SELECT owner, segment_name, segment_type, partition_name
FROM dba_segments
WHERE header_file = &AFN
and header_block = &BL;
- Related Object,Recovery Options
即相关数据对象名称和恢复可选方案。限于篇幅,我们仅罗列常见类型的数据对象的处理:
- TABLE
若坏块所在的数据对象为SYS用户下的数据字典表,建议联系Oracle技术支持部门。此时,整个数据库通常需要进行恢复。
若坏块位于普通表或分区,则查询相关索引信息:
SELECT owner, index_name, index_type
FROM dba_indexes
WHERE table_owner=’&OWNER’ AND table_name=’&SEGMENT_NAME’;
并进一步确定该表是否主键存在:
SELECT owner, constraint_name, constraint_type, table_name
FROM dba_constraints
WHERE owner=’&OWNER’ AND table_name=’&SEGMENT_NAME’ AND constraint_type=’P’;
如果有主键,再确定是否有访问该主键的外键存在:
SELECT owner, constraint_name, constraint_type, table_name
FROM dba_constraints
WHERE r_owner=’&OWNER’ AND r_constraint_name=’&CONSTRAINT_NAME’;
针对普通表或分区的恢复,有如下两种策略:第一种是通过重建表的方式抢救数据。第二种则是通过DBMS_REPAIR包将坏块进行标识,将坏块进行隔离,不影响坏块之外数据的访问。后面还将详细叙述该过程。
- TABLE PARTITION
若坏块位于分区表(TABLE PARTITION),则查询是那些Partition受到影响:
SELECT partition_name
FROM dba_extents
WHERE file_id = &AFN AND &BL BETWEEN block_id AND block_id + blocks – 1;
其它操作则同上述普通表的处理,例如查询该表的索引、主键、外键信息等。
针对分区表的恢复,除上述重建等策略之外,若坏块都位于某一个分区,还可以通过如下的分区交换(exchange)方式,将该坏块数据交换到某个临时表:
Alter table <table_name> exchange partition <partition_name> with table <Temp_table_name>;
这样,DBA可以专注在这个临时表上进行坏块数据的处理,而该表的其它分区可以正常提供服务。
- INDEX
若坏块所在的数据对象为SYS用户下的数据字典表上的索引,建议联系Oracle技术支持部门。
若坏块位于普通表或分区上的索引,则查询该索引所在表:
SELECT table_owner, table_name
FROM dba_indexes
WHERE owner=’&OWNER’ AND index_name=’&SEGMENT_NAME’;
并查询该索引上是否定义了Constraint:
SELECT owner, constraint_name, constraint_type, table_name
FROM dba_constraints
WHERE owner=’&TABLE_OWNER’
AND constraint_name=’&INDEX_NAME’;
若该索引为主键,则查询是否有访问该主键的外键存在:(本文永久地址:https://www.askmac.cn/?p=16580)
SELECT owner, constraint_name, constraint_type, table_name
FROM dba_constraints
WHERE r_owner=’&TABLE_OWNER’ AND r_constraint_name=’&INDEX_NAME’;
针对索引的恢复,最好的办法就是重建(rebuild)索引,后面还将详细叙述该过程。
- INDEX PARTITION
若坏块位于分区索引,则查询哪些分区受到影响:
SELECT partition_name
FROM dba_extents
WHERE file_id = &AFN AND &BL BETWEEN block_id AND block_id + blocks – 1;
其它操作则同上述普通索引的处理,例如查询该索引所在表、主键、外键信息等。
同样地,针对分区索引的恢复,最好的办法就是重建(rebuild)索引,例如:
ALTER INDEX <Index_Name> REBUILD PARTITION <Partiton_Name>;
- TEMPORARY
若坏块位于临时表空间(TEMPORARY),则坏块并没有影响到永久数据对象,例如表、索引等。此时,应查询出使用该临时表空间的所有用户:
SELECT username FROM dba_users
WHERE temporary_tablespace=’&TABLESPACE_NAME’;
针对临时表空间的恢复,最好的办法就是创建一个新的临时表空间,并将受到影响的用户的临时表空间设置为新的临时表空间。例如:
CREATE TEMPORARY TABLESPACE temp2
TEMPFILE ‘/u01/oradata/temp02.dbf’ SIZE 500M
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 10M;
Alter user <user_name> temporary tablespace temp2;
其它数据类型,例如ROLLBACK、CACHE、CLUSTER、LOBINDEX、LOBSEGMENT、、TYPE2 UNDO、其它数据对象等,就联系Oracle技术支持部门,或请见《Handling Oracle Block Corruptions in Oracle7/8/8i/9i/10g/11g [ID 28814.1]》
选择合适的方法进行数据恢复和抢救
接下来的第四个步骤:我们终于要进行实际的数据恢复和抢救了。但这一步骤太复杂了,我们不得不另辟下面一节展开详细描述。
坏块处理八卦图
所谓“选择合适的方法进行数据恢复和抢救”,就是根据坏块所处数据对象的不同类型,例如:CACHE、CLUSTER、INDEX PARTITION、INDEX、LOBINDE、LOBSEGMENT、ROLLBACK、TABLE PARTITION、TABLE、TEMPORARY、TYPE2 UNDO、其它数据对象等,合理制定策略和具体方法进行数据恢复和抢救。
以下就是本人根据Oracle若干篇坏块处理文档总结的数据坏块处理八卦图:
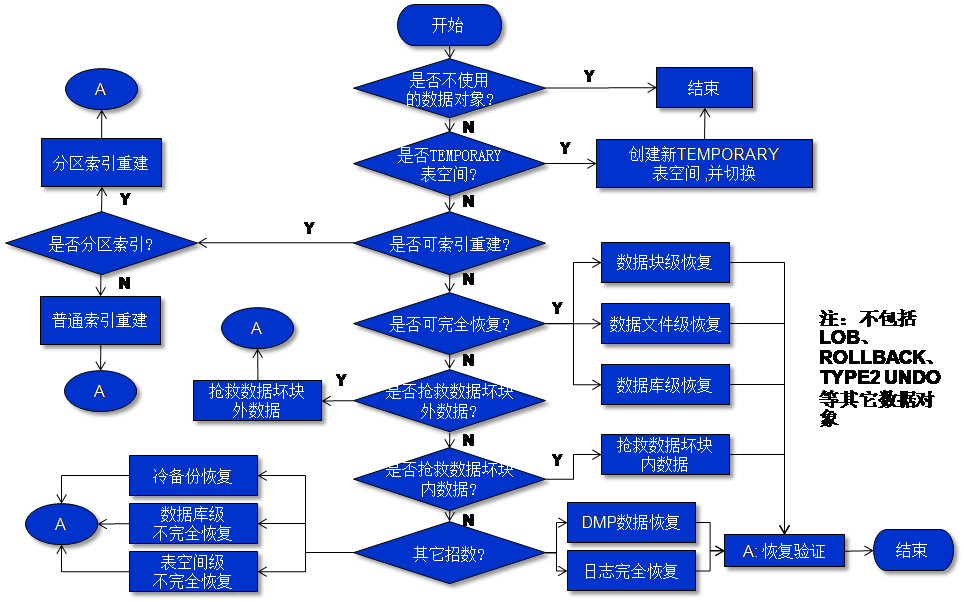
下面将详细描述上述八卦图:
- 首先判断坏块影响的数据库对象是否是已经不使用的数据对象了,如果是,则啥也不用做了。
- 其次,判断坏块影响的数据库对象是否处于临时表空间,如果是,则参照上述内容:创建一个新的临时表空间,并将受到影响的用户的临时表空间设置为新的临时表空间。
- 第三,如果坏块影响的数据库对象是索引,则进一步判断索引所在的表是否也有坏块。如果有,则先解决表的坏块问题。如果没有,则可以通过索引重建方式进行恢复。
若该索引有外键存在,则需要按如下步骤进行:
– For each foreign key
ALTER TABLE <child_table> DISABLE CONSTRAINT <fk_constraint>;
– Rebuild the primary key using
ALTER TABLE <table> DISABLE CONSTRAINT <pk_constraint>;
DROP INDEX <index_name>;
CREATE INDEX <index_name> .. with appropriate storage clause
ALTER TABLE <table> ENABLE CONSTRAINT <pk_constraint>;
– Enable the foreign key constraints
ALTER TABLE <child_table> ENABLE CONSTRAINT <fk_constraint>;
如果是分区索引,则重建索引语句如下:
ALTER INDEX … REBUILD PARTITION …;
需要注意的几点是:
(1)尽量不要使用“ALTER INDEX .. REBUILD”语句去重建非分区索引,因为该语句可能通过已经含有坏块的旧索引数据进行重建,而“ALTER INDEX … REBUILD ONLINE”和“ALTER INDEX … REBUILD PARTITION …”则不会通过已经含有坏块的旧索引数据进行重建,因此应以后两种语句方式进行索引重建。
(2)假设有坏块的索引字段是另外一个复合索引字段的子集,则Oracle可能利用该复合索引的数据进行重建。若该复合索引也有坏块,那就太不幸了。此时,最好将这两个索引都删除掉,并重建。
(3)在重新创建索引时,一定要正确设置相关存储属性,例如将新索引创建在确保没有硬件故障的表空间中。
- 第四,此时可考虑数据库的完全恢复了。但应该满足如下条件:
- 数据库处于归档状态
- 备份数据是完整的
建议通过dbv程序对备份数据检查其完整性。如果最新备份数据也含有坏块数据,则需要查找更旧的备份数据。
- 归档日志必须是完整的
从备份数据到当前时间的归档日志必须是完整的。
- 联机日志必须是完整的
- 没有对实施了nologging操作的数据对象进行recover操作。
例如,若坏块只出现在少量数据块上,则建议进行数据块级恢复。以下是数据块级恢复的相关命令:
blockrecover datafile 8 block 13;
Select * from v$database_block_corruption
blockrecover corruption list;
请注意:数据块级恢复只能做到完全恢复,而不能做到不完全恢复。
若坏块只出现在少数几个数据文件上,则建议进行数据文件级恢复。以下是数据文件级恢复的步骤和相关命令:
— 将含坏块的数据文件设置为OFFLINE状态
ALTER DATABASE DATAFILE ‘name_of_file’ OFFLINE;
— 将该文件复制到安全位置,以防备份数据也包含了坏块
cp < name_of_file > <安全位置>
— 从最新的备份数据中restore该文件至安全位置
命令略
— 通过DBVERIFY检查该文件是否包含坏块
命令略
— 假设该文件不包含坏块,则对该文件目录进行RENAME操作:
ALTER DATABASE RENAME FILE ‘old_name’ TO ‘new_name’;
— 对该文件进行recover操作
RECOVER DATAFILE ‘name_of_file’;
— 将该数据文件恢复为ONLINE状态
ALTER DATABASE DATAFILE ‘name_of_file’ ONLINE;
若坏块出现在多个数据文件上,则可以考虑进行数据库级恢复。以下是数据库级恢复的步骤和相关命令:
— 关闭数据库
Shutdown (Immediate or Abort)
— 将所有文件复制到安全位置,以防备份数据也包含了坏块
cp < name_of_file > <安全位置>
— 从最新的备份数据中restore所有文件至安全位置,但不要restore控制文件和联机日志文件
命令略
— 通过DBVERIFY检查所有文件是否包含坏块
命令略
— 将数据库启动到mount状态
Startup MOUNT
— 假设所有文件不包含坏块,则对被改动位置的文件进行RENAME操作:
ALTER DATABASE RENAME FILE ‘old_name’ TO ‘new_name’;
— 确保所有文件处于ONLINE状态:
ALTER DATABASE DATAFILE ‘name_of_file’ ONLINE;
— 对数据库进行recover操作
RECOVER DATABASE
— 打开数据库
ALTER DATABASE OPEN;
数据库完全恢复之后,建议对受影响的数据对象进行完整性检查,例如:
ANALYZE <table_name> VALIDATE STRUCTURE CASCADE;
确认是否有数据和索引不匹配的情况存在。进一步,建议在应用级检查数据的逻辑完整性。
- 第五,如果上述完全恢复仍然不能恢复坏块数据,而且被损坏的表为关键业务数据,则此时需要考虑尽可能先确保这些表的正常对外访问,并且从这些表中抢救尽可能多的数据。
此时,可供选择的办法包括:
- 通过DBMS_REPAIR包或设置10231事件,抢救坏块之外数据。
- 通过ROWID扫描方法,抢救坏块之外数据。
由于这两项技术较为复杂,我们将在下面专辟章节讲述。
DBMS_REPAIR包或设置10231事件
概述
通过DBMS_REPAIR包或设置10231事件,抢救坏块之外数据的方法,实际上是针对Oracle不同版本而言(本文永久地址:https://www.askmac.cn/?p=16580):
- Oracle 8i之上版本
通过DBMS_REPAIR.SKIP_CORRUPT_BLOCKS过程,对表设置SKIP_CORRPUPT标志,达到绕过坏块读取正常数据的目的。
- Oracle 7到Oracle 8.1版本
通过设置10231事件,达到绕过坏块读取正常数据的目的。该技术在Oracle 7.2之前,一般只针对逻辑坏块(Soft Corrupt),而无法针对因介质损坏而造成的物理坏块(Physical Corrupt)。在Oracle 7.2之后,虽然也增强了对物理坏块的至此和,但仍然不能保证能绕过所有类型的坏块。
对广大客户和现有Oracle版本而言,当然主要将使用DBMS_REPAIR.SKIP_CORRUPT_BLOCKS技术,但在本书中我们仍然将介绍设置10231事件技术。
欲使用这两类技术,必须满足如下条件:
- 坏块所在的表必须是普通表,而不能是系统数据字典表。
- 最好在Oracle技术支持部门建议和指导下,采用这两类技术。
- 已经确定了如何重建或抢救数据的办法。例如,Export,或者“create tables as select…”。
- 已经计划好了抢救数据的停机时间窗口。另外,如果有可能,最好能有一份坏块所在表的复制数据,这样可以专注在这份复制数据上进行数据抢救工作。
- 整个数据库有备份数据
- 已经准备好了重建该数据坏块表的SQL脚本,包括索引、限制、触发器等,以及相关的物理存储属性参数。
实施过程
- SKIP_CORRPUPT标志的设置
通过如下语句,可对坏块所在表进行SKIP_CORRPUPT标志的设置:
SQL> connect /as sysdba;
SQL> execute DBMS_REPAIR.SKIP_CORRUPT_BLOCKS(<用户名>,<表名>);
这样,可通过“CREATE TABLE AS SELECT”、“or ALTER TABLE <> MOVE”、Export等技术,将非坏块数据进行抢救,例如:
SQL> CREATE TABLE salvage_emp AS SELECT * FROM corrupt_emp;
设置SKIP_CORRPUPT标志之后,若进行了跳过坏块的操作,Oracle将在相关trace文件中进行记录,例如:
table scan: segment: file# 6 block# 11
skipping corrupt block file# 6 block# 12
欲清除SKIP_CORRPUPT标志,则执行如下语句:
SQL> connect /as sysdba;
SQL> execute DBMS_REPAIR.SKIP_CORRUPT_BLOCKS(<用户名>,<表名>, flags=>dbms_repair.noskip_flag);
值得注意的是:DBMS_REPAIR.SKIP_CORRUPT_BLOCKS也可针对索引进行设置,但Oracle进行index range scan操作时,只对非根节点的叶节点进行坏块跳跃,而对枝节点和根结点并不进行坏块跳跃。
- 10231事件的设置
10231事件的设置可以在session或instance级分别进行。如果采用“CREATE TABLE AS SELECT”或“or ALTER TABLE <> MOVE”进行数据抢救,则在session设置即可。如果采用Export进行数据抢救,则应在instance级进行设置。
例如,以下语句在session级设置10231事件:
SQL> ALTER SESSION SET EVENTS ‘10231 TRACE NAME CONTEXT FOREVER, LEVEL 10’;
此时,可通过“CREATE TABLE AS SELECT”、“or ALTER TABLE <> MOVE”、Export等技术,将非坏块数据进行抢救,例如:
SQL> CREATE TABLE salvage_emp AS SELECT * FROM corrupt_emp;
欲在instance级进行设置,则在初始化文件init.ora或spfile.ora文件中进行如下设置,并重启数据库:
event=”10231 trace name context forever, level 10″
抢救数据之后的处理
一旦将数据抢救完毕,例如重建新表,或者将数据export出来,则应进行如下事后处理:
- 对被抢救数据进行备份
- 保存重建表、索引的SQL脚本
- 将诊断和处理过程中,Oracle技术支持人员需要的相关诊断信息加以保存
- 删除10231事件或将清除SKIP_CORRPUPT标志
- 对原来有问题的表进行RENAME或DROP操作。如果空间富裕,最好是RENAME操作。
- 通过import操作等重建原表。
- 重建相关索引、触发器等其它对象
ROWID扫描方法
上述通过DBMS_REPAIR包或设置10231事件,抢救坏块之外数据的方法,相比即将介绍的ROWID扫描方法,更为简洁。但上述方法只适合于出现ORA-1578的情况,而且根据本人的经验,该方法经常不能有效进行数据抢救。因此,下面我们将详细介绍ROWID扫描方法。
ROWID简介
为有效使用ROWID扫描方法,我们先需要介绍一下ROWID的格式。ROWID表示每条记录在数据库中的的物理地址,在Oracle 8i之后,ROWID被表示为18位的数字字符串
‘OOOOOOFFFBBBBBBSSS’
其中:
- OOOOOO:以Base 64 Encoding 编码格式表示的数据对象序号
- FFF:以Base 64 Encoding 编码格式表示的相对文件号
- BBBBBB:以Base 64 Encoding 编码格式表示的数据块号
- SSS:以Base 64 Encoding 编码格式表示的slot或row号。
通过如下函数,可创建一条记录的ROWID:
function ROWID_CREATE(rowid_type IN number,
object_number IN number,
relative_fno IN number,
block_number IN number,
row_number IN number)
return ROWID;
— rowid_type – type (restricted=0/extended=1)
— object_number – data object number
— relative_fno – relative file number
— block_number – block number in this file
— row_number – row number in this block
ROWID扫描方法原理
以下就是该技术流程图和示意图:
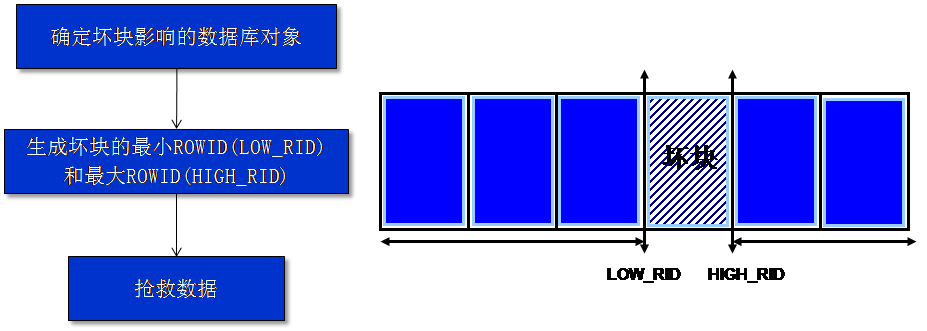
即在定位坏块之后,通过DBMS_ROWID包去生成坏块所处的最小ROWID(LOW_RID),以及最大ROWID(HIGH_RID),例如:
— 最小ROWID
SELECT dbms_rowid.rowid_create(1,<DATA_OBJECT_ID>,<RFN>,<BL>,0) LOW_RID from DUAL;
— 最大ROWID
SELECT dbms_rowid.rowid_create(1,<DATA_OBJECT_ID>,<RFN>,<BL>+1,0) HI_RID from DUAL;
针对普通表,通过如下命令抢救数据:
CREATE TABLE salvage_table AS SELECT /*+ ROWID(A) */ * FROM <owner.tablename> A WHERE rowid < ‘<low_rid>’ ;
INSERT INTO salvage_table SELECT /*+ ROWID(A) */ * FROM <owner.tablename> A WHERE rowid >= ‘<high_rid>’ ;
针对分区表,通过如下命令抢救数据:
CREATE TABLE salvage_table AS
SELECT /*+ ROWID(A) */ *
FROM <owner.tablename> PARTITION (<partition_name>) A
WHERE rowid < ‘<lo_rid>’
;
INSERT INTO salvage_table
SELECT /*+ ROWID(A) */ *
FROM <owner.tablename> PARTITION (<partition_name>) A
WHERE rowid >= ‘<hi_rid>’
但是,如果坏块处于表段头(Segment Header),ROWID扫描法则无用武之地了。通过如下语句,可知道坏块是否处于表段头:
select file_id,block_id,blocks,extent_id
from dba_extents
where owner='<owner>’
and segment_name='<table_name>’
and segment_type=’TABLE’
order by extent_id;
FILE_ID BLOCK_ID BLOCKS EXTENT_ID
——— ——— ——— ———
8 94854 20780 0 <- EXTENT_ID ZERO is segment header
即上述语句中,如果EXTEND_ID为0,则表示是表段头。
如何从坏块中抢救数据?
首先,Oracle公司认为,既然数据已经坏了,坏块数据被完全抢救出来的可能性就微乎其微了。即便这样,可供选择的办法有:
通过索引从坏块中抢救数据
通过ROWID扫描法,可以通过索引从坏块中抢救被索引字段的数据。以下就是详细过程:
- 如果需要抢救的字段是非空值(Not Null)字段,则使用Fast Full Scan访问方式:
SELECT /*+ INDEX_FFS(X <index_name>) */
<index_column1>, <index_column2> …
FROM <tablename> X
WHERE rowid >= ‘<low_rid>’
AND rowid < ‘<hi_rid>’ ;
其中,<low_rid>、<hi_rid>通过上述dbms_rowid.rowid_create语句产生。
- 如果需要抢救的字段是允许空值(Null)字段,则不能使用Fast Full Scan,而必须使用Range Scan访问方式。为此,必须设置索引前缀字段的最小值条件,才能确保使用Range Scan访问方式:
SELECT /*+ INDEX(X <index_name>) */
<index_column1>, <index_column2> …
FROM <tablename> X
WHERE rowid >= ‘<low_rid>’
AND rowid < ‘<hi_rid>’
AND <index_column1> >= <min_col1_value>;
这样,如果坏块所在表的索引越多,从索引中抢救数据也可能越多。通过查询dba_ind_columns视图可查询表的索引信息。
通过LogMiner技术
通过LogMiner技术,也可能对坏块数据进行一定的抢救。即从日志文件中找到最初加载到坏块的Insert或Update语句,并从这些语句中抢救出相关数据。
寻求Oracle Support支持
针对表的坏块数据,通过寻求Oracle Support支持,可以通过相关内部工具,对坏块数据进行抢救。欲通过此方法进行进行抢救,请在MOS网站中创建SR。
坏块抢救的最后招数
- 从容灾数据库进行抢救
如果通过Data Guard配置了容灾数据库,由于Data Guard具有防止坏块传播功能,因此,可考虑在容灾数据库对相关数据对象进行抢救。
- 从头恢复的一种场景
假设某个数据文件出现坏块,而且数据库没有物理备份,但保留了该数据文件创建之后的所有归档日志,则可以通过如下方式进行恢复:
— 重新创建该数据文件
ALTER DATABASE CREATE DATAFILE ‘….’ [as ‘…’] ;
— 对该数据文件进行恢复操作
RECOVER DATAFILE ‘….’
— 将该数据文件进行恢复为Online状态
ALTER DATABASE DATAFILE ‘….’ ONLINE;
- 不完全恢复
无论何种数据类型的坏块,都可以通过不完全恢复技术,将整个数据库,或者将坏块所在的表空间恢复到坏块发生之前的某个时刻。但这种技术运用的前提是确定了坏块出现的准确时间,而且将导致整个数据库,或某些表空间数据的大范围回退。
- 冷备份恢复
假设数据库为非归档模式,并且有完好的冷备份数据,则可以进行冷备份恢复,但只能恢复到冷备份的时间点。也可通过冷备份数据克隆一个数据库,并从此克隆数据库中进行数据抢救。
- 逻辑恢复
最后一个招数之一就是通过逻辑备份数据(Export,Data Pump)进行恢复了。逻辑恢复只能恢复到备份时间点,不能实现完全恢复。当然,也可通过逻辑备份数据克隆一个数据库,并从此克隆数据库中进行数据抢救。
本章参考资料及进一步读物
本章参考资料及进一步读物:
| 序号 | 资料类别 | 资料名称 | 资料概述 |
| 1. | My Oracle Support | 《Master Note for Handling Oracle Database Corruption Issues (Doc ID 1088018.1)》 | 这就是有关数据库坏块问题的资料入口。坏块的解释;坏块的种类;表、索引、IOT、LOB等各类数据对象坏块的处理;各类坏块诊断工具等,应有尽有。 |
| 2. | My Oracle Support | 《Handling Oracle Block Corruptions in Oracle7/8/8i/9i/10g/11g (Doc ID 28814.1)》 | 这就是本章主要参考的文档。 |
| 3. | My Oracle Support | 《Extracting Data from a Corrupt Table using DBMS_REPAIR or Event 10231 (Doc ID 33405.1)》 | 这是从坏块表中抽取数据的最简单办法。尽管不一定奏效,但值得一试。 |
| 4. | My Oracle Support | 《Extracting Data from a Corrupt Table using ROWID Range Scans in Oracle8 and higher (Doc ID 61685.1)》 | 虽然这篇文章介绍的从坏块表中抽取数据方法有点复杂,但效果还是不错的。 |
| 5. | My Oracle Support | 《Best Practices for Avoiding and Detecting Corruption (Doc ID 428570.1)》 | 对付坏块最有效的办法就是防患于未然。看看这篇防范坏块的最佳实践经验文章吧:设置DB_BLOCK_CHECKING、DB_BLOCK_CHECKSUM参数;RMAN备份加强逻辑坏块检查;定期运行dbv;定期对主要表进行analyze操作… … |
| 6. | My Oracle Support | 《How to identify all the Corrupted Objects in the Database with RMAN (Doc ID 472231.1)》 | RMAN可是允许坏块存在的。该文档描述了如何查找RMAN备份数据中的坏块,以及所对应的数据段。 |
| 7. | My Oracle Support | 《How to identify the corrupt Object reported by ORA-1578 / RMAN / DBVERIFY (Doc ID 819533.1)》 | 该文章介绍根据ORA-1578错误信息,或者根据RMAN和DBVERIFY的坏块信息,查询对应数据对象的办法。 |
运行维护篇
本人曾在10余年前从数据库应用开发人员转为一个网站的专职DBA,当我把数据库安装好,把备份恢复做好,然后就开始发木了:DBA还应该做什么工作?可能现在很多专职DBA还有类似困惑。Oracle 11g联机文档《Oracle® Database Administrator’s Guide》第一章描述了DBA的11大任务:评估数据库服务器硬件、安装数据库软件、数据库规划、性能监控和优化、备份和恢复数据库、下载和安装补丁… ….
本篇就将从运行维护角度介绍几项DBA应该做的典型工作:数据库健康检查、防止人为错误的FLASHBACK技术运用、版本和补丁管理、数据库空间和碎片管理、数据库安全性评估和加固… …
希望DBA们看过之后,会发出这样的感慨:哦,原来DBA有那么多事情可做哦!
转载自:

 posted on
posted on

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2020-08-12 PostgreSQL DB与插件下载
2019-08-12 Postgresql 进程和内存结构
2019-08-12 Postgresql 内存分配
2019-08-12 Deepgreen & Greenplum DBA小白普及课之三
2019-08-12 DBA 有哪些工作
2019-08-12 Deepgreen/Greenplum 删除节点步骤
2019-08-12 Greenplum Segment 的检测机制