

1. MongoDB 多引擎体系 -- WiredTiger
MongoDB v.3.0之前的版本,默认使用MMAP(MMap引擎)方式对内存中的数据进行写盘存储,遭受了很多诟病。比如并发受限的表锁、不支持压缩、不可控的IO操作等,MMAP甚至不能称作一个完整的存储引擎(笔者的个人观点),对数据(Btree的数据页、索引页)的操作甚至要依赖os的mmap(in_page_cache)刷盘,并且os的page 4k为IO单元对数据库本身就是不友好的,再加上其实数据库自身应该比OS更懂数据的layout,比如哪些是热数据,哪些是索引(较数据页更需要留在内存里)来组织LRU。
MongoDB v3.0版本一个重大的更新是加入了WiredTiger,也使得Mongo代码架构里支持了StorageEngine的抽象层(接口层更多细节,参见@林青 大神的文章http://www.atatech.org/articles/56080),为后面RocksDB、Memory等做了铺垫。WiredTiger引擎(后面简称wt引擎)面向多核、Page IO优化做了很多工作(比如加入HazardPointer、分离锁,为了增大并发内存Page结构和磁盘Page结构解耦以及支持变长Page-面向大吞吐设备的IO适配)。很多测试报告显示使用了wt之后Mongo的性能有很大提升。本文通过项目里对wt的子模块进行了解,主要关注cache相关设计,更多wt引擎相关请见后续文章。
2. WiredTiger整体架构
wt引擎是基于btree索引实现的,和InnoDB引擎有很多设计和名词上相似的地方,大家可以类比。wt对外的api接口是以table(类比Mysql的表和MongoDB的collection) + kv存储形式提供的,key是int64_t类型(类似MongoDB的_id),value是byte[]类型(这里通过byteArray来实现MongoDB上层schema free的bson结构)。上层通过cursor方式来实现数据的search/insert/update/remove操作。内部通过journal_log、checkpoint、cache(btree/cache_evict)、block_manager子模块协调访问IO存储(这里主要列出本文相关模块,sweep、transaction、bloom/lsm等未列出)

session 模块,负责和wt引擎上层交互的句柄,每个session会关联多个cursor,cursor属于一个sessioncache 模块,主要有内存中的btree page(数据页,索引页,溢出页)构成evict 模块,如果cache内存紧张,触发cache淘汰,便利btree,并根据lru排序淘汰Journal 模块,WAL log,类似InnoDB的redolog,保证数据持久化,通过定时和定量阈值来flushcheckpoint 模块,类似InnoDB checkpoint机制,异步执行btree刷盘,checkpoint之后通知log模块更新log_ckpt_lsn(lsn概念和InnoDB一致)block manager模块,负责磁盘IO的读写,cache、evict、checkpoint模块均通过该模块访问磁盘
3. cache pool
wt有个shard cache(cache pool)的概念,MongoDB并未使用。因为cache本身的功能和InnoDB buffer pool类似,这里暂且把wiredTiger的cache称作cache pool也算合理。cache pool主要存放内存中btree page为单位的页,页类型及cache pool相关运行参数可见 http://gitlab.alibaba-inc.com/dds/dds-documents/blob/develop/社区教程文档/wiredTiger_cache_运行参数.md,cache的读入和淘汰写入都是以page为单位(基本上所有存储引擎都是如此)。基本结构如图:

(图片来自WiredTiger Github官方wiki)
- 基本page类型:
root_page(btree根节点),internal_page(索引页),leaf_page(数据页, 叶子节点) - 结构:每个page被包含在一个REF里面(可以看做是page的容器), root_page/internal_page 包含一个refArray数组,包含下层节点的指针,home(红色线)指向父节点
wt的btree相较于InnoDB有些不一样的地方(详细结构见https://github.com/wiredtiger/wiredtiger/wiki/Reconciliation-overview),InnoDB的内存中的page结构和磁盘上的page结构是一样的,都是紧凑的binary,修改产生的脏页会in place的更新到原有磁盘的page上, 这样的好处是刷盘时,直接把16k的page,按字节数组的方式一次性刷下去即可。
WiredTiger将磁盘上的page读上来之后,会在内存中构建成另外一种复杂结构,这个结构较binary结构好处就是可以重新组织或嵌入具有更高并发性的结构,比如wt使用的HazardPointer,对page刷盘时,其实就是对该页的HazardPointer的'写获取'操作,并且在刷盘时保持 原有磁盘上的page不变,直接找一个新的page空间,把内存里page的修改(保存在page的modify_list中)变成磁盘page的结构写入 ,这个page刷盘的过程称为reconcile(wt里很多生僻的名词)。这样的好处是对不修改原有page,就能更好的并发,并且不像InnoDB一样,需要一个DoubleWriteBuffer保证非disk block 512B写时对原有页可能发生conrrupt。(这里有个小问题,如果是更新都写入新page,如果每次都只是更新page中很小的数据,数据的空间占用会比较大,待验证?!)
WiredTiger也提供了类似InnoDB的checkpoint机制:每个客户端的写请求会先通过journal进行持久化,这里类似redolog都是顺序IO,并且提供了类似innodb_flush_log_at_trx_commit的{j: true}参数。那么,在wt里面产生的cache脏页,就用在后台'慢慢'的刷。当写入到一定程度或者时间后,或作一次checkpoint把cache中的数据刷入磁盘,并且做fsync, 然后通知journal更新checkpoint offset,即可丢弃之前的journal。这里在每次checkpoint后,都会产生一个新的root page(也就是一个新的btree,一个bree对应一个物理文件),同时会在journal写入这个checkpoint事件。
3.1 cache pool 刷盘
写请求写入journal后就可以保证Durability,后续wt引擎遇到如下情况时,会触发cache的刷盘动作:
-
checkpoint
checkpoint时会遍历所有btree,把btree的所有leaf_page做reconcile操作,然后对重新分配root_page,触发的阈值包括:
- journal容量达到阈值,默认2G
- 每隔60s执行一次
-
cache evict
evict线程会根据现在cache的使用量,分段扫描一些page(可能是drity page或clean page),进行淘汰,释放cache空间,主要受如下4个参数影响:
eviction_trigger:cache总使用量达到该百分比时,触发evict操作
eviction_target:触发上述参数evict后,需要将cache总使用量降低到该百分比水位,才停止evict
eviction_dirty_trigger:cache脏页使用量到该百分比时,触发evict操作
eviction_dirty_target:触发上述参数evict后,需要将cache脏页使用量降低到该百分比水位,才停止evict
(WiredTiger v2.8.1 一般情况使用情况eviction_trigger > eviction_target > eviction_dirty_trigger > eviction_dirty_target,WiredTiger v2.9之后版本对着四个参数的意义进行了调整!)
-
application evict
如果写入量一直很大,那么用户请求处理线程就会阻塞并参与evict的执行,这也是一种保护措施,当IO量很大时,做到同步阻塞上面的请求
4 cache evict
4.1 evict线程模型
cache evict在wt v2.8.1早期版本时,采用的是server-worker模型,1个server线程负责扫描btree找到一些page,然后进行lru排序,放入一个evict_queue中,再由worker线程消费,进行page evict动作。后面v2.8.1在MongoDB v3.2.9这个版本中,对线程模型进行了升级, 将server线程和worker线程合并(worker通过抢一把evict_pass_lock锁来成为server),相当于N个worker线程,同一时刻,有一个worker会成为server,负责执行evict_pass(扫描btree,并填充evict_queue)的工作,较少了切换的代价 。并且把原来单一的evict_queue变成了两个,降低了server、worker之间操作一个queue的概率减少冲突,增加了并发。
虽然线程模型做了调整,但从功能上还是server-worker的模式,见下图:


4.2 Btree扫描策略
每次evict_server执行cache pass是对所有btree的一次扫描,会根据当前cache情况最多扫描100个page出来。__btree的扫描是迭代的,结束时会记录当前扫描道德btree的位置,下次继续从这个地方开始walk,每个btree最多扫描出10个page,如果这个btree被exclusive独占,如checkpoint正在访问这个btree,则跳过__ ,这是为了让btree所有page都有可能被扫描到。如果扫描了足够多的page,则会停止本次cache pass,进入page的evict阶段。
这个扫描策略应该可以page尽可能全的被覆盖,但其实不具备LRU的特性(evict_queue里的page排序是基于LRU,也就是说扫描出来的page是会使用LRU)。如果看一下HBase或者InnoDB的分级扫描策略,就会感觉wt引擎的这种阶段性扫描在某些场景下还是不够友好的。比如 InnoDB的分级cache,会把buffer pool中的page list分成两部分,new_list和old_list,分别占5/8和3/8左右,新访问使用的page会在old_list里,如果这个page被再次访问到,则移动到new_list,如不访问则可能在old_list里被淘汰掉 。这就防止了select * from table类似这种fullScan时对buffer pool的污染 (详情可参考 http://dev.mysql.com/doc/refman/5.6/en/innodb-buffer-pool.html ),这里wt引擎其实做的还有欠缺。
4.3 LRU策略
扫描完成后的evict_queue,需要对每个里面page做评分排序,每个page的评分由page->read_gen(可理解成page的存活周期,如果经历过cache淘汰越多,但没被淘汰,就越高), 以及page类型共同决定,见代码:
-
/*
-
* 获得page的评分,分数越低越容易被淘汰掉
-
*/
-
static inline uint64_t
-
__evict_read_gen(const WT_EVICT_ENTRY *entry)
-
{
-
WT_BTREE *btree;
-
WT_PAGE *page;
-
uint64_t read_gen;
-
-
btree = entry->btree;
-
-
page = entry->ref->page;
-
-
// 周期最老的页,需要马上evict,给最低分WT_READGEN_OLDEST == 1
-
if (page->read_gen == WT_READGEN_OLDEST)
-
return (WT_READGEN_OLDEST);
-
-
// 如果dhandle(btree文件)已经要被回收,同样给最低分
-
if (!WT_PAGE_IS_INTERNAL(page) &&
-
F_ISSET(btree->dhandle, WT_DHANDLE_DEAD))
-
return (WT_READGEN_OLDEST);
-
-
// 如果page为空,也给最低分
-
if (__wt_page_is_empty(page))
-
return (WT_READGEN_OLDEST);
-
-
// 如果是internal page索引页, 则加上一个倾斜分数1000000分,
-
// 这里是希望索引页尽量不淘汰
-
read_gen = page->read_gen + btree->evict_priority;
-
if (WT_PAGE_IS_INTERNAL(page))
-
read_gen += WT_EVICT_INT_SKEW;
-
-
return (read_gen);
-
}
按评分排序后,得到一个分数从小到大的有序队列,这个时候需要计算candidate(evict_page是即将被淘汰的页,candidate page是本次决定淘汰的页,evict > candicate),继续上代码:
-
if (FLD_ISSET(cache->state,
-
WT_EVICT_PASS_AGGRESSIVE | WT_EVICT_PASS_WOULD_BLOCK)) {
-
// 此时cache空间已经非常紧张了,进入aggressive模式或者application用户
-
// 线程淘汰模式了,则把全部evict_page变成candidate_page
-
evict_queue->evict_candidates = entries;
-
} else {
-
// 寻找第一个不是WT_READGEN_OLDEST的分数
-
read_gen_oldest = WT_READGEN_OLDEST;
-
for (candidates = 0; candidates < entries; ++candidates) {
-
read_gen_oldest =
-
__evict_read_gen(
-
&evict_queue->evict_queue[candidates]);
-
if (read_gen_oldest != WT_READGEN_OLDEST)
-
break;
-
}
-
-
// 此处意味着全部page的分数都是WT_READGEN_OLDEST,则全部变成
-
// candidate
-
if (read_gen_oldest == WT_READGEN_OLDEST)
-
evict_queue->evict_candidates = entries;
-
else if (candidates >= entries / 2)
-
// 如果第一个不是WT_READGEN_OLDEST的分数位置是在
-
// 中间位置或中间偏后面的位置,则直接取到这个点
-
evict_queue->evict_candidates = candidates;
-
else {
-
cache->read_gen_oldest = read_gen_oldest;
-
-
// 去一个适中的值,差不多在这个点的值和最后点的值得3/4处
-
// 也就是说在当前这个点到末尾之间去一个值作为平衡点
-
cutoff =
-
(3 * read_gen_oldest + __evict_read_gen(
-
&evict_queue->evict_queue[entries - 1])) / 4;
-
-
// 在至少10%和至多50%间找一个小于cutoff的边界作为
-
// candidate数量
-
for (candidates = 1 + entries / 10;
-
candidates < entries / 2;
-
candidates++)
-
if (__evict_read_gen(
-
&evict_queue->evict_queue[candidates]) >
-
cutoff)
-
break;
-
evict_queue->evict_candidates = candidates;
-
}
-
}
4.3 Cache 现存问题及CacheHang问题
上述分析了Cache相关的设计,其实可以看出evict还是有些精巧的地方,单还不够完善,尤其是在cache evict和checkpoint同时发生,或者evict_server不能找到可以evict的page时的退让策略,触发了一些线上问题,本文的下半节《MongoDB WiredTiger 存储引擎cache_pool设计 (下) -- 实践篇》将对次进行深入讨论
MongoDB WiredTiger 存储引擎cache_pool设计 (下) -- 实践篇
1. Cache Pool引发的问题
之前的文章《MongoDB WiredTiger 存储引擎cache_pool设计 (上) -- 原理篇》和大家分享WiredTiger的整体架构和Cache Pool相关的设计,这篇来介绍下阿里云MongoDB线上出现的问题,及改进措施。
用过MongoDB 3.0之后版本的同学应该都比较熟悉WiredTiger的cache evict问题。
连续好几个版本在cache 淘汰算法上设计都有些小问题,现象总结起来就是写入hang住。本文使用的是MongoDB v3.2.9下wiredtiger-2.8.1(现在wt官方主推v2.9.0版本, MongoDB v3.4之后会使用这个版本,云MongoDB现在可以使用v3.2.9,后续我们会很快支持)。WiredTiger逐渐并入MongoDB的分之管理,Github可以看到如下:
如果自建使用的MongoDB v3.2.10之后的版本,可参考 @林青 的文章?spm=5176.100240.searchblog.34.AinuZY
我们在服务内部用户的时候,发现在write heavy场景下,通过mongostat发现used%居高不下,写入也会抖动的比较厉害,磁盘IO偶尔出现uitl 100%或者非常空闲的奇怪现象,抓取了Mongo的stack发现异常的线程和cache evict相关,紧急情况下收集了部分数据,将MongoDB升级到v3.2.10,问题解决。于是,我们在线下环境进行了复现,收集了profiling数据。
1.1 cache evict
首先介绍cache evict相关的概念,在MongoDB v3.2.8(WiredTiger v2.8.1)里面有如下选项:(注:这些变量在wt-v2.9.1之后意义改变比较大,如不清楚版本可参见http://source.wiredtiger.com/2.8.0/group__wt.html)
| 参数选项 | 含义 |
|---|---|
| cache_size | cache的总大小 |
| eviction_trigger | 百分比, 如果cache内存使用量超过此百分比,则触发cache evict的淘汰 |
| eviction_target | 百分比,如果触发了evict淘汰,则需要将cache内存使用量降至此百分比之下,才停止evict |
| eviction_dirty_trigger | 百分比, 如果cache中dirty page内存使用量超过此百分比,则触发cache evict的淘汰 |
| eviction_dirty_target | 百分比,如果触发了evict淘汰,则需要将cache中dirty page内存使用量降至此百分比之下,才停止evict |
| evict.threads_max | 最大并发的evict线程数 |
| evict.threads_min | 最少并发的evict线程数 |
MongoDB默认设置:threads_max = 4, eviction_target == eviction_dirty_target == 80%eviction_trigger == eviction_dirty_trigger == 95%,cache_size用户设置
在线下环境我们让cache_size尽可能的小,分别设置了2G和10MB,通过sysbench和ycsb在insert heavy情况下复现并遇到了如下两个问题。
1.2 _evict_server cpu 100%
压测程序QPS陡降到100以下,mongostat发现写入几乎完全hang住,cache used 100%左右徘徊
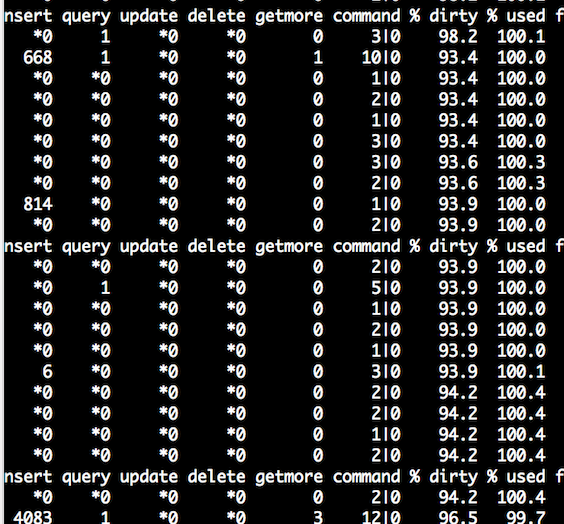
堆栈采样显示__tree_walk_internal占据绝大部分cpu,这个函数是btree 遍历page所用。cache模块的evict_server在寻找可以淘汰的dirty/clean page时会用这个函数依次遍历dirty/clean page,查看是否可以将page进行淘汰,evict_server每检查一次page就会触发__tree_walk_internal,到这里我们猜想cache evict是在大量的遍历page,导致cpu飙高。
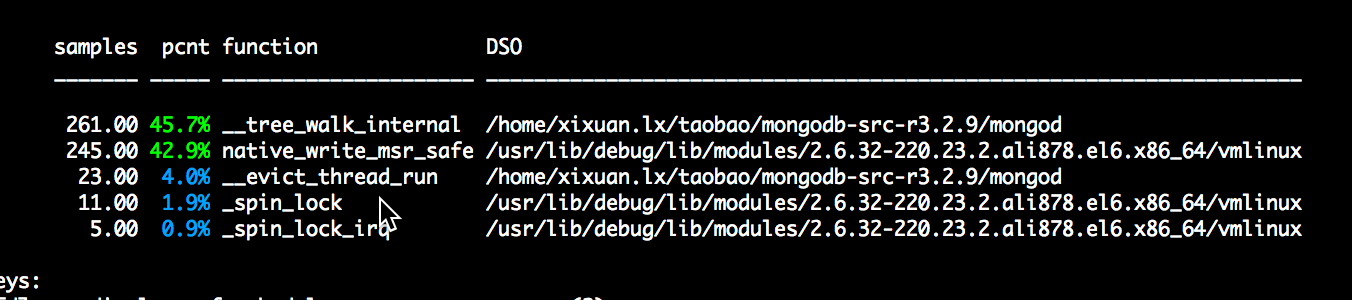
1.3 evict hang
同样一个测试数据集,我们使用cacheSize=10MB(最初的目的是让问题尽快复现),偶发出现写入hang,但cpu都是idle。并且MongoDB基本是不可用的状态,·cache used甚至超过100%·
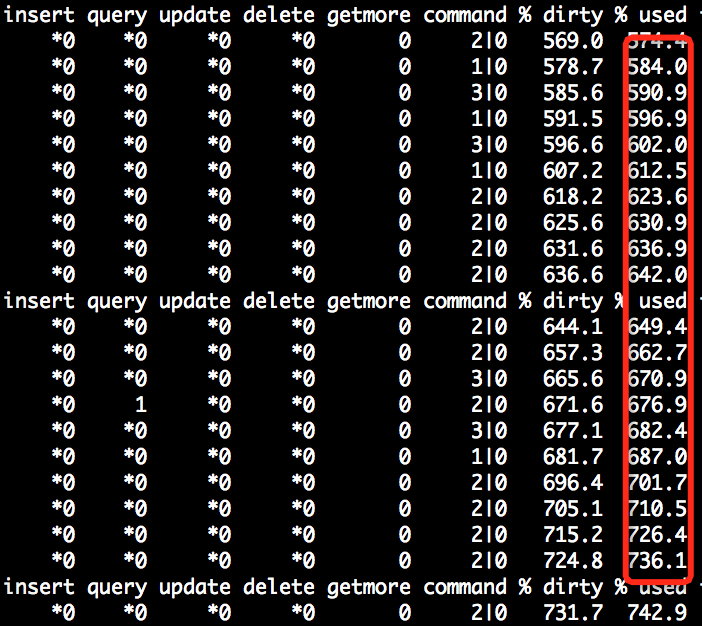
此时获得的堆栈采样在·__wt_sleep()·函数采样比例较高。但由于WiredTiger自选地方比较多,__wt_sleep()经常出现在spin超过一定次数后发生yield,还好有strace,发现sleep()的调用的入参十分有规律,是N + 1000的sleep方式,通过追代码发现如下
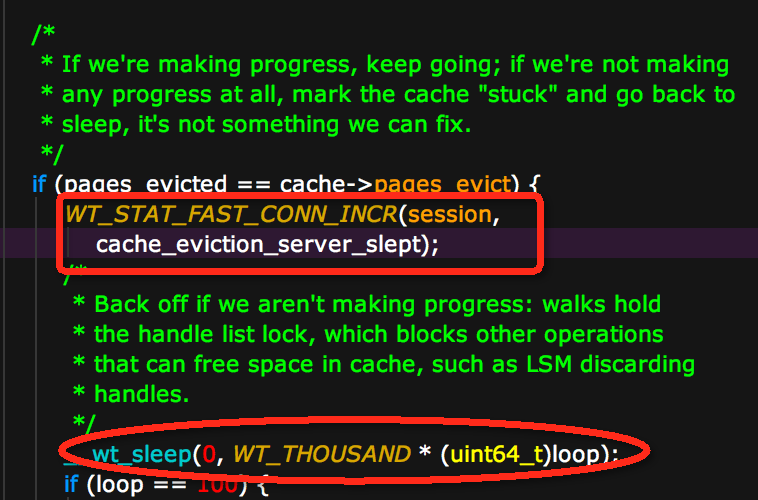
这是当evict_server找到一些page后,但是evict_worker不能进行evict操作,也就是之前统计的pages_evicted等于现在的cache->pages_evict(说明evict的page数量是0),会主动的休眠一下。
这里官方的想法应该是现在evict_worker已经很忙了,不能再evict(比如磁盘IO很大),这时候应该通过sleep放慢evict_server查找脏页的速度(这个假设不一定是成立的,后面会讲到)。
至此,基本的trace工具能搜集到的都差不多收集完了,其实还有systemtap这个神器还没用,打点的功能真是没的说。细心的同学可能发现上图中红色方形中的WT_STAT相关的内部采集点,没错wt内部提供了这样的机制,通过点计数方profiling内部的逻辑。
2. WiredTiger profiling 工具
MongoDB本身支持了wt的profiling参数,通过--wiredTigerStatisticsLogDelaySecs可定期将统计信息写入统计日志(默认0不开启)。我们设置5s一次的采集,在dbpath下会生成很多WiredTigerStat.xx.yy的文件。然后我们通过内置的wtstats.py脚本来生成可读的html
python ./src/third_party/wiredtiger/tools/wtstats/wtstats.py /data/u10/mongod-xixuan/data/primary/)
打开之后可以看到cache、cursor、blockmanager、log、transaction等统计信息
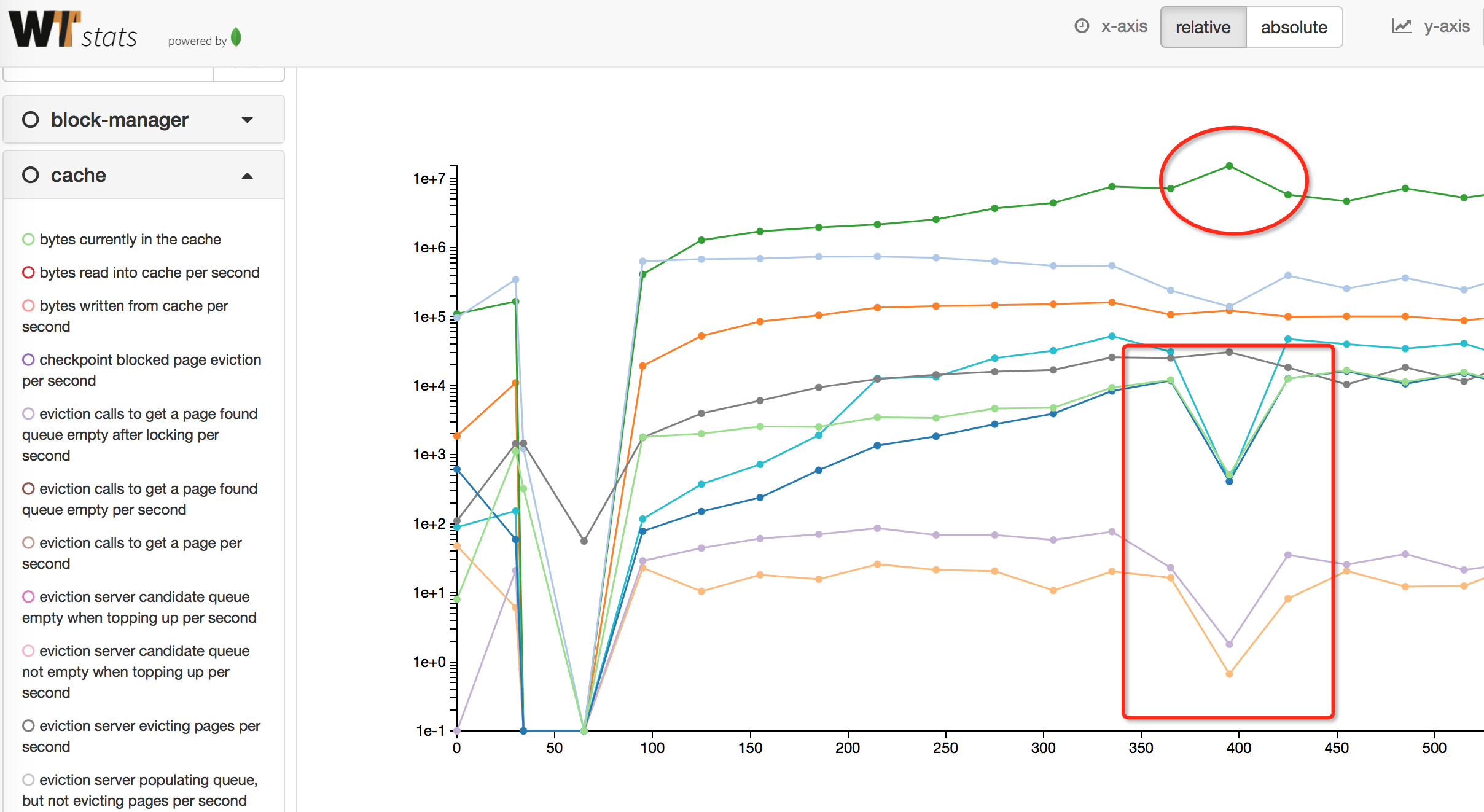
- 更多的Cache Pool相关参数解释可以另一篇文章 《WiredTiger v2.8.1 cache相关参数整理》
此图可以清晰的看到cache evict的内部采集指标,发现在大量出现下降的400这个地方,很多统计都是陡降(pages_queued要淘汰的page入队数量、pages_evict淘汰数量、pages_reconcile叶子写盘数量),增长的三个指标分别是:
pages walked for eviction,evict时遍历的page数量pages seen by eviction,evict时检查的page数量pages currently held in cache,cache中page的数量
那么,问题就显而易见了,pages在不断的被evict_server看到,遍历的速度还是很快的,但是有如下问题:
- 访问的page不能被evict,所以不能如队列,所以cpu会飙升,但找不到合适的page,
这间接导致了上面说的在不能evict时候会sleep的问题。 - 不能被evict_worker写入磁盘,导致evict失败。
3. 深挖 Root Cause
问题和现象已经很明朗了,下面就是根据代码找到问题所在,这里需要gdb和perf进行调试和采样,需要带上WiredTiger的debug symbol。为了防止编译MongoDB代码(编译时间太痛苦,20分钟以上)。
这里使用--use-system-wiredtiger来指定可以使用自己编译的WiredTiger,这个技巧也可用来测试wt的兼容性和开发的debug用。
scons --use-system-wiredtiger CPPPATH=/home/xixuan.lx/taobao/wiredtiger/include LIBPATH=/home/xixuan.lx/taobao/wiredtiger/lib/
LD_LIBRARY_PATH=/home/xixuan.lx/taobao/wiredtiger/lib/:$LD_LIBRARY_PATH gdb -tui ./mongod
3.1 发现可疑点
经过debug发现3处存在问题的地方:
1) 和checkpoint竞争
evict_server通过__evict_walk_file遍历btree文件的page时,会给cache->evict_walk_lock加锁。同样在checkpoint_server中,对evict_walk_lock也会加锁导致evict和checkpoint操作是互斥的

这带来的效果就是checkpoint如果慢,则evict也会滞后,导致cache增长。这样的问题在测试时候出现过,表现为写入hang滞后,cache used一直涨,但过一段时间后,写入可以恢复的场景。
2) pages_seen增长很快,但是不能进行evict
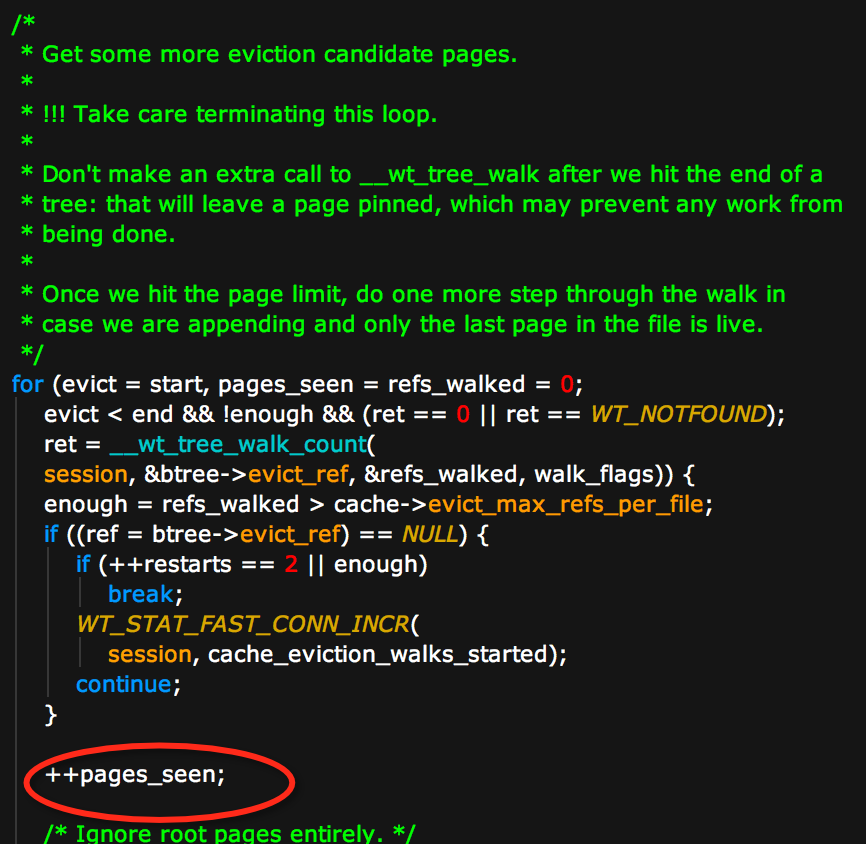
- page_seen是遍历btree的page数量,从第二节中给出的曲线图可以看出这个值一直在快速增长
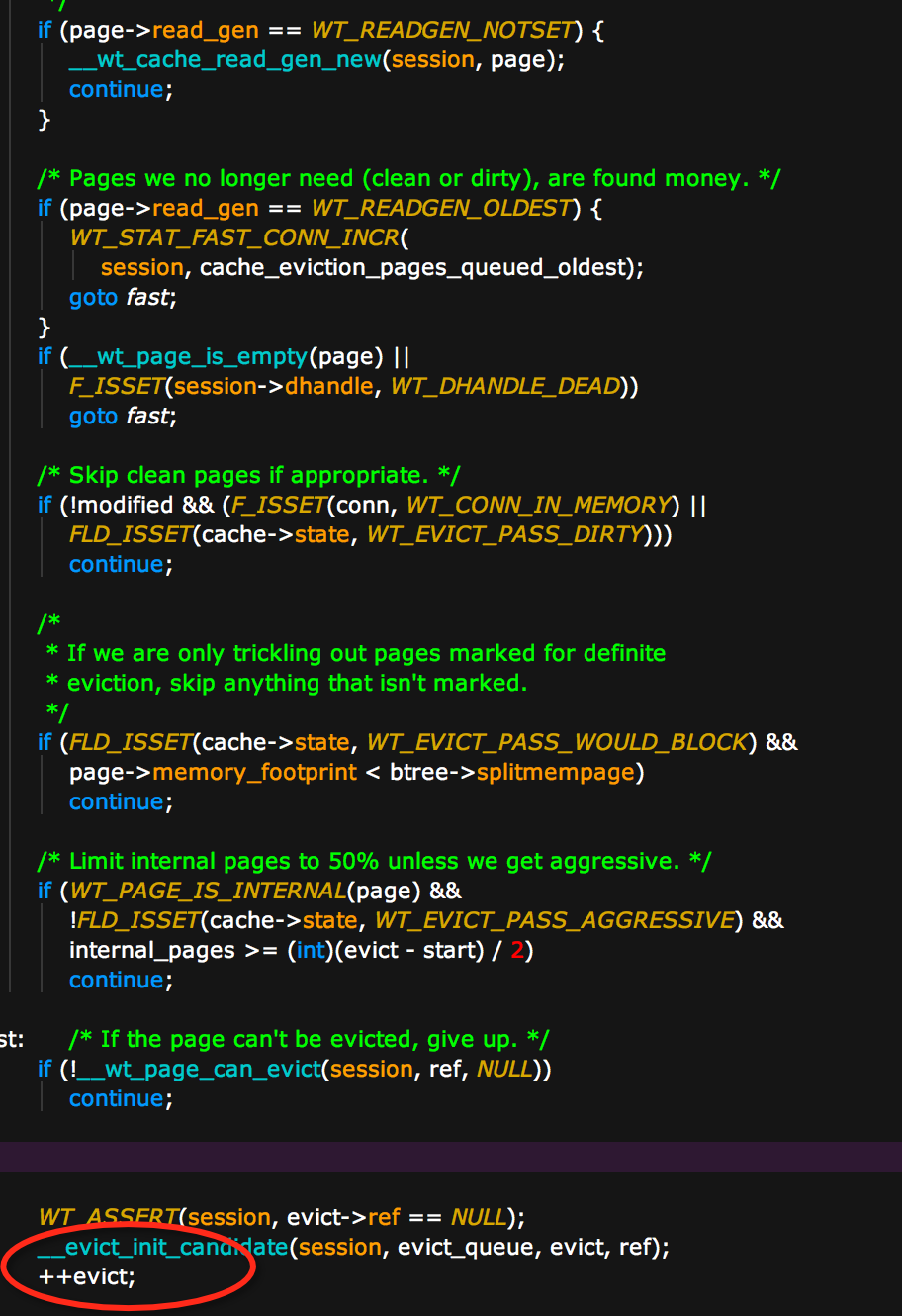
- 可以evict的page陡降说明上述代码中
__wt_page_can_evict()返回false,或者之前的continue,说明page不能淘汰。这里分析了下原因可能有3个: - 看到的page很多都是internal_page也就是索引页
- 或者cache状态是WT_EVICT_PASS_WOULD_BLOCK几近满了并且memory_footprint很大
- 发现btree在做checkpoint,并且陷入了之前说的sleep问题(此时并不是evict太慢,而是没有page可以evict,但是evict_server还是会sleep)
3) __wt_evict_page()调用失败
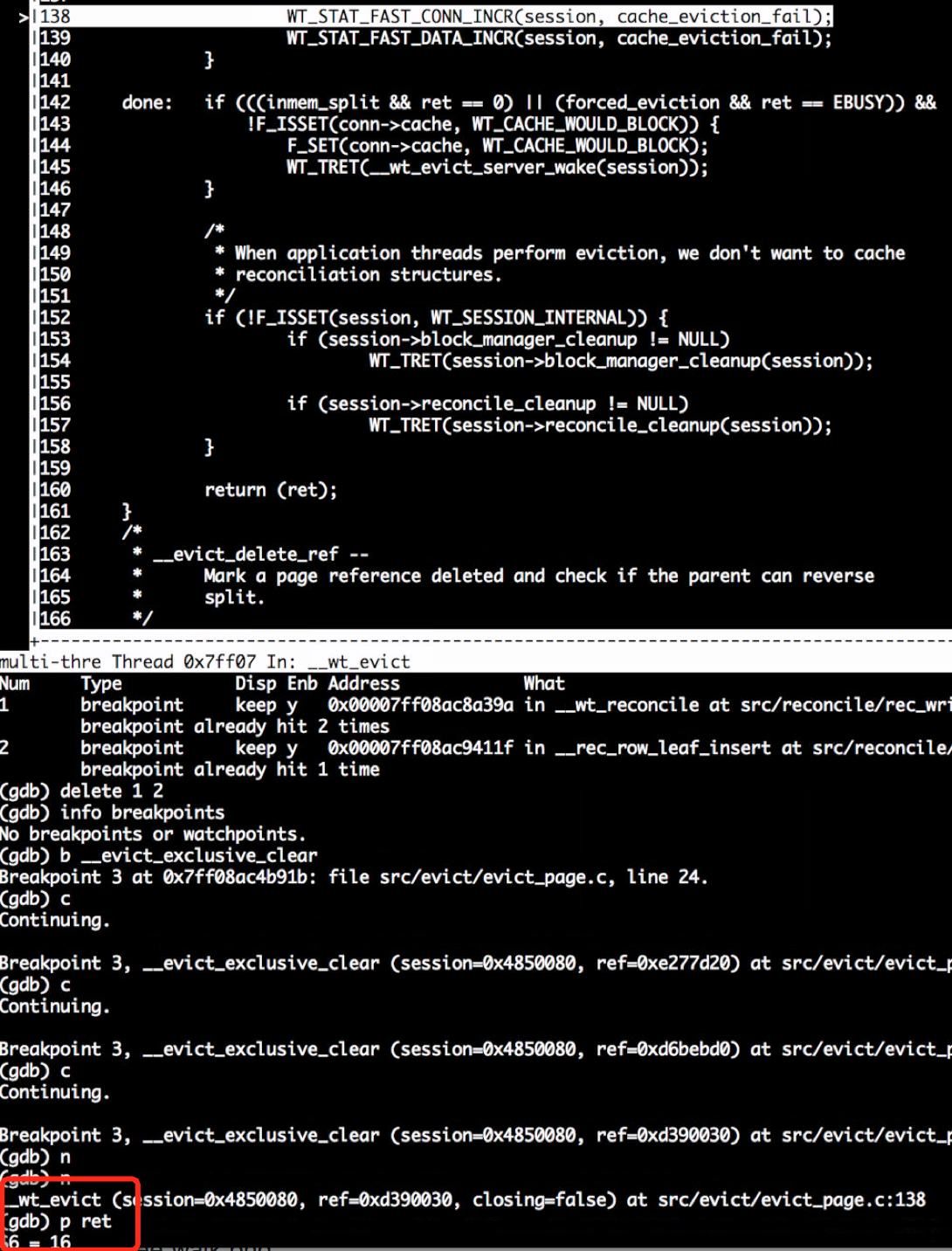
可以看到__wt_evict(这个函数是evict_worker淘汰一个page时调用),返回的ret值是16也就是EBUSY,在深入往下追只有两个地方会返回EBUSY:
if (!F_ISSET(r, WT_EVICT_LOOKASIDE | WT_EVICT_UPDATE_RESTORE))
return (EBUSY);
if (skipped && !F_ISSET(r, WT_EVICT_UPDATE_RESTORE))
return (EBUSY);
在看设置WT_EVICT_UPDATE_RESTORE的地方
flags = WT_EVICTING;
if (closing)
LF_SET(WT_VISIBILITY_ERR);
else if (!WT_PAGE_IS_INTERNAL(page)) {
if (F_ISSET(S2C(session), WT_CONN_IN_MEMORY))
LF_SET(WT_EVICT_IN_MEMORY | WT_EVICT_UPDATE_RESTORE);
else if (page->read_gen == WT_READGEN_OLDEST)
LF_SET(WT_EVICT_UPDATE_RESTORE);
else if (F_ISSET(S2C(session)->cache, WT_CACHE_STUCK))
LF_SET(WT_EVICT_LOOKASIDE);
}
由于未设置WT_EVICT_UPDATE_RESTORE而导致__wt_evict不能刷page
3.2 初步结论
分析到这里,总结一下原因
- checkpoint影响cache evict,导致evict延时,并且可能导致page不能当做evict_page进行淘汰
- evict_server由于__wt_evict失败(由于WT_READGEN_OLDEST标记为mark),evict_worker不能刷page,这时由于evict_server的退让机制(上面的sleep机制) 导致evict问题被放大,越来越慢。
3.3 JIRA跟进
MongoDB官方针对cache问题也提了几个issue,在v3.2.10和v3.4.0中都进不了不少。涉及的issue如下:
- WT-2924 Ensure we are doing eviction when threads are waiting for it
- WT-2545 Investigate eviction tree walk
- WT-2639 Add tree walk optimization to skip subtrees not in memory
- WT-2702 Under high thread load, WiredTiger exceeds cache size
- WT-2664 Change eviction so any eviction thread can find candidates
3.3 改进思路及WiredTiger参数建议
- 可以增大cacheSize,让evict更少,以此来减少上面冲突的概率,也可以拉平evict的差距。
- 减小evict_triger、evict_target的设置,更早的触发evict行为,这样每次evict执行时间会缩短
- 修改源码,临界淘汰时候之淘汰clean page(这样减少磁盘IO),或者禁用sleep退让模式
- 用更高IOPS的硬件,交给硬件来解决软件的问题(没办法的办法)
 posted on
posted on

