

转自aobao.org/monthly/2015/04/01/
本文是对整个Undo生命周期过程的阐述,代码分析基于当前最新的MySQL5.7版本。本文也可以作为了解整个Undo模块的代码导读。由于涉及到的模块众多,因此部分细节并未深入。
前言
Undo log是InnoDB MVCC事务特性的重要组成部分。当我们对记录做了变更操作时就会产生undo记录,Undo记录默认被记录到系统表空间(ibdata)中,但从5.6开始,也可以使用独立的Undo 表空间。
Undo记录中存储的是老版本数据,当一个旧的事务需要读取数据时,为了能读取到老版本的数据,需要顺着undo链找到满足其可见性的记录。当版本链很长时,通常可以认为这是个比较耗时的操作(例如bug#69812)。
大多数对数据的变更操作包括INSERT/DELETE/UPDATE,其中INSERT操作在事务提交前只对当前事务可见,因此产生的Undo日志可以在事务提交后直接删除(谁会对刚插入的数据有可见性需求呢!!),而对于UPDATE/DELETE则需要维护多版本信息,在InnoDB里,UPDATE和DELETE操作产生的Undo日志被归成一类,即update_undo。
基本文件结构
为了保证事务并发操作时,在写各自的undo log时不产生冲突,InnoDB采用回滚段的方式来维护undo log的并发写入和持久化。回滚段实际上是一种 Undo 文件组织方式,每个回滚段又有多个undo log slot。具体的文件组织方式如下图所示:
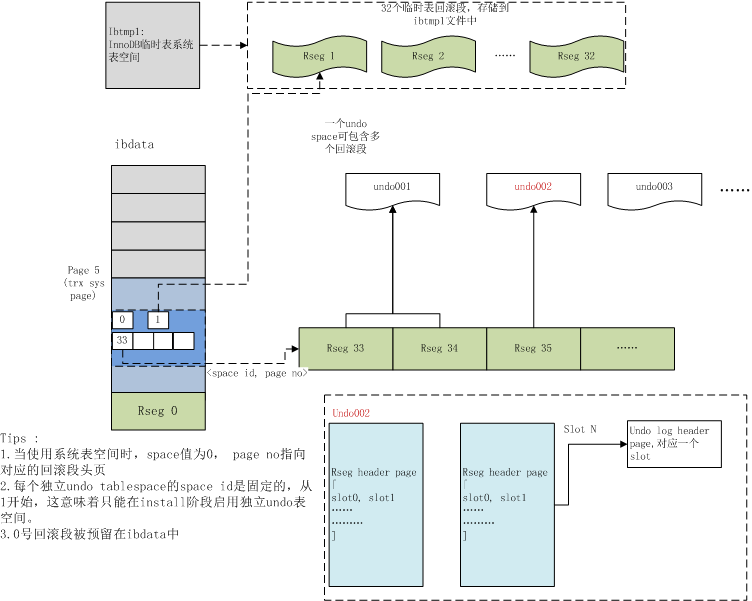
上图展示了基本的Undo回滚段布局结构,其中:
- rseg0预留在系统表空间ibdata中;
- rseg 1~rseg 32这32个回滚段存放于临时表的系统表空间中;
- rseg33~ 则根据配置存放到独立undo表空间中(如果没有打开独立Undo表空间,则存放于ibdata中)
如果我们使用独立Undo tablespace,则总是从第一个Undo space开始轮询分配undo 回滚段。大多数情况下这是OK的,但假设我们将回滚段的个数从33开始依次递增配置到128,就可能导致所有的回滚段都存放在同一个undo space中。(参考函数trx_sys_create_rsegs 以及 bug#74471)
每个回滚段维护了一个段头页,在该page中又划分了1024个slot(TRX_RSEG_N_SLOTS),每个slot又对应到一个undo log对象,因此理论上InnoDB最多支持 96 * 1024个普通事务。
关键结构体
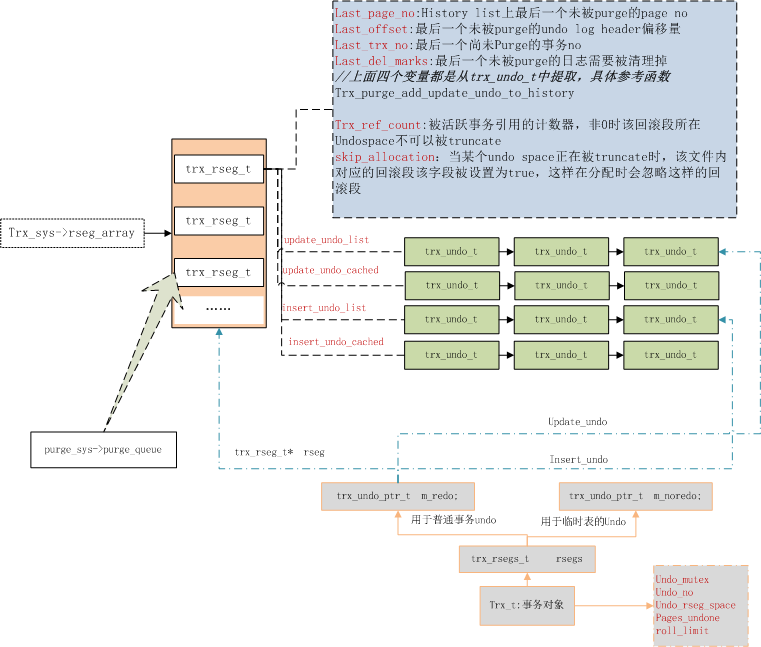
为了便于管理和使用undo记录,在内存中维持了如下关键结构体对象:
- 所有回滚段都记录在
trx_sys->rseg_array,数组大小为128,分别对应不同的回滚段; - rseg_array数组类型为trx_rseg_t,用于维护回滚段相关信息;
- 每个回滚段对象trx_rseg_t还要管理undo log信息,对应结构体为trx_undo_t,使用多个链表来维护trx_undo_t信息;
- 事务开启时,会专门给他指定一个回滚段,以后该事务用到的undo log页,就从该回滚段上分配;
- 事务提交后,需要purge的回滚段会被放到purge队列上(
purge_sys->purge_queue)。
各个结构体之间的联系如下:
分配回滚段
当开启一个读写事务时(或者从只读事务转换为读写事务),我们需要预先为事务分配一个回滚段:
对于只读事务,如果产生对临时表的写入,则需要为其分配回滚段,使用临时表回滚段(第1~32号回滚段),函数入口:trx_assign_rseg -->trx_assign_rseg_low-->get_next_noredo_rseg。
在MySQL5.7中事务默认以只读事务开启,当随后判定为读写事务时,则转换成读写模式,并为其分配事务ID和回滚段,调用函数:trx_set_rw_mode -->trx_assign_rseg_low --> get_next_redo_rseg。
普通回滚段的分配方式如下:
- 采用round-robin的轮询方式来赋予回滚段给事务,如果回滚段被标记为skip_allocation(这个undo tablespace太大了,purge线程需要对其进行truncate操作),则跳到下一个;
- 选择一个回滚段给事务后,会将该回滚段的
rseg->trx_ref_count递增,这样该回滚段所在的undo tablespace文件就不可以被truncate掉; - 临时表回滚段被赋予
trx->rsegs->m_noredo,普通读写操作的回滚段被赋予trx->rsegs->m_redo;如果事务在只读阶段使用到临时表,随后转换成读写事务,那么会为该事务分配两个回滚段。
使用回滚段
当产生数据变更时,我们需要使用Undo log记录下变更前的数据以维护多版本信息。insert 和 delete/update 分开记录undo,因此需要从回滚段单独分配Undo slot。
入口函数:trx_undo_report_row_operation
流程如下:
- 判断当前变更的是否是临时表,如果是临时表,则采用临时表回滚段来分配,否则采用普通的回滚段;
- 临时表操作记录undo时不写redo log;
- 操作类型为TRX_UNDO_INSERT_OP,且未分配insert undo slot时,调用函数
trx_undo_assign_undo进行分配; - 操作类型为TRX_UNDO_MODIFY_OP,且未分配Update undo slot时,调用函数
trx_undo_assign_undo进行分配。
我们来看看函数trx_undo_assign_undo的流程:
- 首先总是从cahced list上分配trx_undo_t (函数
trx_undo_reuse_cached,当满足某些条件时,事务提交时会将其拥有的trx_undo_t放到cached list上,这样新的事务可以重用这些undo 对象,而无需去扫描回滚段,寻找可用的slot,在后面的事务提交一节会介绍到);- 对于INSERT,从
trx_rseg_t::insert_undo_cached上获取,并修改头部重用信息(trx_undo_insert_header_reuse)及预留XID空间(trx_undo_header_add_space_for_xid) - 对于DELETE/UPDATE,从
trx_rseg_t::update_undo_cached上获取, 并在undo log hdr page上创建新的Undo log header(trx_undo_header_create),及预留XID存储空间(trx_undo_header_add_space_for_xid) - 获取到trx_undo_t对象后,会从cached list上移除掉。并初始化trx_undo_t相关信息(trx_undo_mem_init_for_reuse),将
trx_undo_t::state设置为TRX_UNDO_ACTIVE
- 对于INSERT,从
-
如果没有cache的trx_undo_t,则需要从回滚段上分配一个空闲的undo slot(trx_undo_create),并创建对应的undo页,进行初始化;
一个回滚段可以支持1024个事务并发,如果不幸回滚段都用完了(通常这几乎不会发生),会返回错误DB_TOO_MANY_CONCURRENT_TRXS
每一个Undo log segment实际上对应一个独立的段,段头的起始位置在UNDO 头page的TRX_UNDO_SEG_HDR+TRX_UNDO_FSEG_HEADER偏移位置(见下图)
-
已分配给事务的trx_undo_t会加入到链表
trx_rseg_t::insert_undo_list或者trx_rseg_t::update_undo_list上; - 如果是数据词典操作(DDL)产生的undo,主要是表级别操作,例如创建或删除表,还需要记录操作的table id到undo log header中(TRX_UNDO_TABLE_ID),同时将TRX_UNDO_DICT_TRANS设置为TRUE。(trx_undo_mark_as_dict_operation)。
总的来说,undo header page主要包括如下信息: 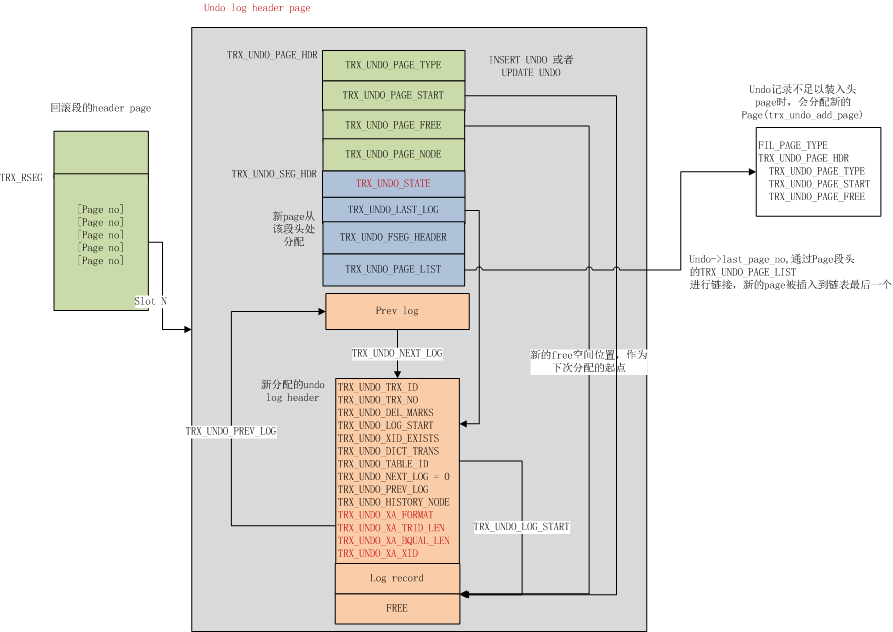
如何写入undo日志
入口函数:trx_undo_report_row_operation
当分配了一个undo slot,同时初始化完可用的空闲区域后,就可以向其中写入undo记录了。写入的page no取自undo->last_page_no,初始情况下和hdr_page_no相同。
对于INSERT_UNDO,调用函数trx_undo_page_report_insert进行插入,记录格式大致如下图所示: 
对于UPDATE_UNDO,调用函数trx_undo_page_report_modify进行插入,UPDATE UNDO的记录格式大概如下图所示: 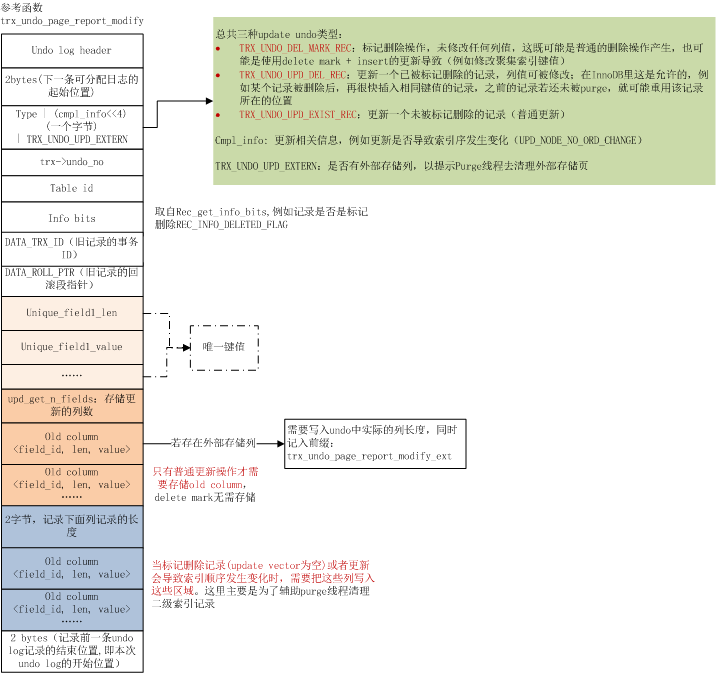
在写入的过程中,可能出现单页面空间不足的情况,导致写入失败,我们需要将刚刚写入的区域清空重置(trx_undo_erase_page_end),同时申请一个新的page(trx_undo_add_page) 加入到undo log段上,同时将undo->last_page_no指向新分配的page,然后重试。
完成Undo log写入后,构建新的回滚段指针并返回(trx_undo_build_roll_ptr),回滚段指针包括undo log所在的回滚段id、日志所在的page no、以及page内的偏移量,需要记录到聚集索引记录中。
事务Prepare阶段
入口函数:trx_prepare_low
当事务完成需要提交时,为了和BINLOG做XA,InnoDB的commit被划分成了两个阶段:prepare阶段和commit阶段,本小节主要讨论下prepare阶段undo相关的逻辑。
为了在崩溃重启时知道事务状态,需要将事务设置为Prepare,MySQL 5.7对临时表undo和普通表undo分别做了处理,前者在写undo日志时总是不需要记录redo,后者则需要记录。
分别设置insert undo 和 update undo的状态为prepare,调用函数trx_undo_set_state_at_prepare,过程也比较简单,找到undo log slot对应的头页面(trx_undo_t::hdr_page_no),将页面段头的TRX_UNDO_STATE设置为TRX_UNDO_PREPARED,同时修改其他对应字段,如下图所示(对于外部显式XA所产生的XID,这里不做讨论): 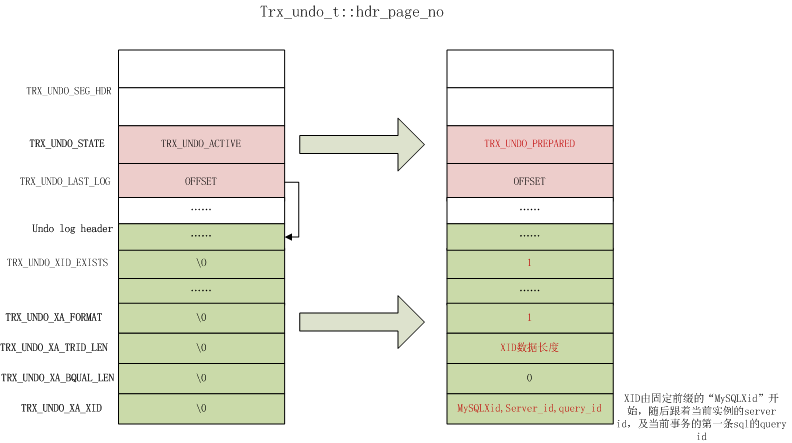
Tips:InnoDB层的XID是如何获取的呢? 当Innodb的参数innodb_support_xa打开时,在执行事务的第一条SQL时,就会去注册XA,根据第一条SQL的query id拼凑XID数据,然后存储在事务对象中。参考函数trans_register_ha。
事务Commit
当事务commit时,需要将事务状态设置为COMMIT状态,这里同样通过Undo来实现的。
入口函数:trx_commit_low-->trx_write_serialisation_history
在该函数中,需要将该事务包含的Undo都设置为完成状态,先设置insert undo,再设置update undo(trx_undo_set_state_at_finish),完成状态包含三种:
- 如果当前的undo log只占一个page,且占用的header page大小使用不足其3/4时(TRX_UNDO_PAGE_REUSE_LIMIT),则状态设置为TRX_UNDO_CACHED,该undo对象会随后加入到undo cache list上;
- 如果是Insert_undo(undo类型为TRX_UNDO_INSERT),则状态设置为TRX_UNDO_TO_FREE;
- 如果不满足a和b,则表明该undo可能需要Purge线程去执行清理操作,状态设置为TRX_UNDO_TO_PURGE。
在确认状态信息后,写入undo header page的TRX_UNDO_STATE中。
如果当前事务包含update undo,并且undo所在回滚段不在purge队列时,还需要将当前undo所在的回滚段(及当前最大的事务号)加入Purge线程的Purge队列(purge_sys->purge_queue)中(参考函数trx_serialisation_number_get)。
对于undate undo需要调用trx_undo_update_cleanup进行清理操作,清理的过程包括:
-
将undo log加入到history list上,调用
trx_purge_add_update_undo_to_history:-
如果该undo log不满足cache的条件(状态为TRX_UNDO_CACHED,如上述),则将其占用的slot设置为FIL_NULL,意为slot空闲,同时更新回滚段头的TRX_RSEG_HISTORY_SIZE值,将当前undo占用的page数累加上去;
-
将当前undo加入到回滚段的TRX_RSEG_HISTORY链表上,作为链表头节点,节点指针为UNDO头的TRX_UNDO_HISTORY_NODE;
-
更新
trx_sys->rseg_history_len(也就是show engine innodb status看到的history list),如果只有普通的update_undo,则加1,如果还有临时表的update_undo,则加2,然后唤醒purge线程; -
将当前事务的
trx_t::no写入undo头的TRX_UNDO_TRX_NO段; -
如果不是delete-mark操作,将undo头的TRX_UNDO_DEL_MARKS更新为false;
-
如果undo所在回滚段的
rseg->last_page_no为FIL_NULL,表示该回滚段的旧的清理已经完成,进行如下赋值,记录这个回滚段上第一个需要purge的undo记录信息:-
rseg->last_page_no = undo->hdr_page_no;
-
rseg->last_offset = undo->hdr_offset;
-
rseg->last_trx_no = trx->no;
-
rseg->last_del_marks = undo->del_marks;
-
-
-
如果undo需要cache,将undo对象放到回滚段的update_undo_cached链表上;否则释放undo对象(trx_undo_mem_free)。
注意上面只清理了update_undo,insert_undo直到事务释放记录锁、从读写事务链表清除、以及关闭read view后才进行,调用函数trx_undo_insert_cleanup:
-
如果Undo状态为TRX_UNDO_CACHED,则加入到回滚段的insert_undo_cached链表上;
-
否则,将该undo所占的segment及其所占用的回滚段的slot全部释放掉(trx_undo_seg_free),修改当前回滚段的大小(rseg->curr_size),并释放undo对象所占的内存(trx_undo_mem_free),和Update_undo不同,insert_undo并未放到History list上。
事务完成提交后,需要将其使用的回滚段引用计数rseg->trx_ref_count减1;
事务回滚
如果事务因为异常或者被显式的回滚了,那么所有数据变更都要改回去。这里就要借助回滚日志中的数据来进行恢复了。
入口函数为:row_undo_step --> row_undo
操作也比较简单,析取老版本记录,做逆向操作即可:对于标记删除的记录清理标记删除标记;对于in-place更新,将数据回滚到最老版本;对于插入操作,直接删除聚集索引和二级索引记录(row_undo_ins)。
具体的操作中,先回滚二级索引记录(row_undo_mod_del_mark_sec、row_undo_mod_upd_exist_sec、row_undo_mod_upd_del_sec),再回滚聚集索引记录(row_undo_mod_clust)。这里不展开描述,可以参阅对应的函数。
多版本控制
InnoDB的多版本使用undo来构建,这很好理解,undo记录中包含了记录更改前的镜像,如果更改数据的事务未提交,对于隔离级别大于等于read commit的事务而言,它不应该看到已修改的数据,而是应该给它返回老版本的数据。
入口函数: row_vers_build_for_consistent_read
由于在修改聚集索引记录时,总是存储了回滚段指针和事务id,可以通过该指针找到对应的undo 记录,通过事务Id来判断记录的可见性。当旧版本记录中的事务id对当前事务而言是不可见时,则继续向前构建,直到找到一个可见的记录或者到达版本链尾部。(关于事务可见性及read view,可以参阅我们之前的月报)
Tips 1:构建老版本记录(trx_undo_prev_version_build)需要持有page latch,因此如果Undo链太长的话,其他请求该page的线程可能等待时间过长导致crash,最典型的就是备库备份场景:
当备库使用innodb表存储复制位点信息时(relay_log_info_repository=TABLE),逻辑备份显式开启一个read view并且执行了长时间的备份时,这中间都无法对slave_relay_log_info表做purge操作,导致版本链极其长;当开始备份slave_relay_log_info表时,就需要去花很长的时间构建老版本;复制线程由于需要更新slave_relay_log_info表,因此会陷入等待Page latch的场景,最终有可能导致信号量等待超时,实例自杀。 (bug#74003)
Tips 2:在构建老版本的过程中,总是需要创建heap来存储旧版本记录,实际上这个heap是可以重用的,无需总是重复构建(bug#69812)
Tips 3:如果回滚段类型是INSERT,就完全没有必要去看Undo日志了,因为一个未提交事务的新插入记录,对其他事务而言总是不可见的。
Tips 4: 对于聚集索引我们知道其记录中存有修改该记录的事务id,我们可以直接判断是否需要构建老版本(lock_clust_rec_cons_read_sees),但对于二级索引记录,并未存储事务id,而是每次更新记录时,同时更新记录所在的page上的事务id(PAGE_MAX_TRX_ID),如果该事务id对当前事务是可见的,那么就无需去构建老版本了,否则就需要去回表查询对应的聚集索引记录,然后判断可见性(lock_sec_rec_cons_read_sees)。
Purge清理操作
从上面的分析我们可以知道:update_undo产生的日志会放到history list中,当这些旧版本无人访问时,需要进行清理操作;另外页内标记删除的操作也需要从物理上清理掉。后台Purge线程负责这些工作。
入口函数:srv_do_purge --> trx_purge
-
确认可见性
在开始尝试purge前,purge线程会先克隆一个最老的活跃视图(
trx_sys->mvcc->clone_oldest_view),所有在readview开启之前提交的事务所做的事务变更都是可以清理的。 -
获取需要purge的undo记录(
trx_purge_attach_undo_recs)从history list上读取多个Undo记录,并分配到多个purge线程的工作队列上(
(purge_node_t*) thr->child->undo_recs),默认一次最多取300个undo记录,可通过参数innodb_purge_batch_size参数调整。 -
Purge工作线程
当完成任务的分发后,各个工作线程(包括协调线程)开始进行purge操作 入口函数: row_purge_step -> row_purge -> row_purge_record_func
主要包括两种:一种是记录直接被标记删除了,这时候需要物理清理所有的聚集索引和二级索引记录(
row_purge_record_func);另一种是聚集索引in-place更新了,但二级索引上的记录顺序可能发生变化,而二级索引的更新总是标记删除 + 插入,因此需要根据回滚段记录去检查二级索引记录序是否发生变化,并执行清理操作(row_purge_upd_exist_or_extern)。 -
清理history list
从前面的分析我们知道,insert undo在事务提交后,Undo segment 就释放了。而update undo则加入了history list,为了将这些文件空间回收重用,需要对其进行truncate操作;默认每处理128轮Purge循环后,Purge协调线程需要执行一次purge history List操作。
入口函数:
trx_purge_truncate --> trx_purge_truncate_history从回滚段的HISTORY 文件链表上开始遍历释放Undo log segment,由于history 链表是按照trx no有序的,因此遍历truncate直到完全清除,或者遇到一个还未purge的undo log(trx no比当前purge到的位置更大)时才停止。
关于Purge操作的逻辑实际上还算是比较复杂的代码模块,这里只是简单的介绍了下,以后有时间再展开描述。
崩溃恢复
当实例从崩溃中恢复时,需要将活跃的事务从undo中提取出来,对于ACTIVE状态的事务直接回滚,对于Prepare状态的事务,如果该事务对应的binlog已经记录,则提交,否则回滚事务。
实现的流程也比较简单,首先先做redo (recv_recovery_from_checkpoint_start),undo是受redo 保护的,因此可以从redo中恢复(临时表undo除外,临时表undo是不记录redo的)。
在redo日志应用完成后,初始化完成数据词典子系统(dict_boot),随后开始初始化事务子系统(trx_sys_init_at_db_start),undo 段的初始化即在这一步完成。
在初始化undo段时(trx_sys_init_at_db_start -> trx_rseg_array_init -> ... -> trx_undo_lists_init),会根据每个回滚段page中的slot是否被使用来恢复对应的undo log,读取其状态信息和类型等信息,创建内存结构,并存放到每个回滚段的undo list上。
当初始化完成undo内存对象后,就要据此来恢复崩溃前的事务链表了(trx_lists_init_at_db_start),根据每个回滚段的insert_undo_list来恢复插入操作的事务(trx_resurrect_insert),根据update_undo_list来恢复更新事务(tex_resurrect_update),如果既存在插入又存在更新,则只恢复一个事务对象。另外除了恢复事务对象外,还要恢复表锁及读写事务链表,从而恢复到崩溃之前的事务场景。
当从Undo恢复崩溃前活跃的事务对象后,会去开启一个后台线程来做事务回滚和清理操作(recv_recovery_rollback_active -> trx_rollback_or_clean_all_recovered),对于处于ACTIVE状态的事务直接回滚,对于既不ACTIVE也非PREPARE状态的事务,直接则认为其是提交的,直接释放事务对象。但完成这一步后,理论上事务链表上只存在PREPARE状态的事务。
随后很快我们进入XA Recover阶段,MySQL使用内部XA,即通过Binlog和InnoDB做XA恢复。在初始化完成引擎后,Server层会开始扫描最后一个Binlog文件,搜集其中记录的XID(MYSQL_BIN_LOG::recover),然后和InnoDB层的事务XID做对比。如果XID已经存在于binlog中了,对应的事务需要提交;否则需要回滚事务。
Tips:为何只需要扫描最后一个binlog文件就可以了? 因为在每次rotate到一个新的binlog文件之前,总是要保证前一个binlog文件中对应的事务都提交并且sync redo到磁盘了,也就是说,前一个binlog文件中的事务在崩溃恢复时肯定是出于提交状态的。
本文是对整个Undo生命周期过程的阐述,代码分析基于当前最新的MySQL5.7版本。本文也可以作为了解整个Undo模块的代码导读。由于涉及到的模块众多,因此部分细节并未深入。
前言
Undo log是InnoDB MVCC事务特性的重要组成部分。当我们对记录做了变更操作时就会产生undo记录,Undo记录默认被记录到系统表空间(ibdata)中,但从5.6开始,也可以使用独立的Undo 表空间。
Undo记录中存储的是老版本数据,当一个旧的事务需要读取数据时,为了能读取到老版本的数据,需要顺着undo链找到满足其可见性的记录。当版本链很长时,通常可以认为这是个比较耗时的操作(例如bug#69812)。
大多数对数据的变更操作包括INSERT/DELETE/UPDATE,其中INSERT操作在事务提交前只对当前事务可见,因此产生的Undo日志可以在事务提交后直接删除(谁会对刚插入的数据有可见性需求呢!!),而对于UPDATE/DELETE则需要维护多版本信息,在InnoDB里,UPDATE和DELETE操作产生的Undo日志被归成一类,即update_undo。
基本文件结构
为了保证事务并发操作时,在写各自的undo log时不产生冲突,InnoDB采用回滚段的方式来维护undo log的并发写入和持久化。回滚段实际上是一种 Undo 文件组织方式,每个回滚段又有多个undo log slot。具体的文件组织方式如下图所示:
上图展示了基本的Undo回滚段布局结构,其中:
- rseg0预留在系统表空间ibdata中;
- rseg 1~rseg 32这32个回滚段存放于临时表的系统表空间中;
- rseg33~ 则根据配置存放到独立undo表空间中(如果没有打开独立Undo表空间,则存放于ibdata中)
如果我们使用独立Undo tablespace,则总是从第一个Undo space开始轮询分配undo 回滚段。大多数情况下这是OK的,但假设我们将回滚段的个数从33开始依次递增配置到128,就可能导致所有的回滚段都存放在同一个undo space中。(参考函数trx_sys_create_rsegs 以及 bug#74471)
每个回滚段维护了一个段头页,在该page中又划分了1024个slot(TRX_RSEG_N_SLOTS),每个slot又对应到一个undo log对象,因此理论上InnoDB最多支持 96 * 1024个普通事务。
关键结构体
为了便于管理和使用undo记录,在内存中维持了如下关键结构体对象:
- 所有回滚段都记录在
trx_sys->rseg_array,数组大小为128,分别对应不同的回滚段; - rseg_array数组类型为trx_rseg_t,用于维护回滚段相关信息;
- 每个回滚段对象trx_rseg_t还要管理undo log信息,对应结构体为trx_undo_t,使用多个链表来维护trx_undo_t信息;
- 事务开启时,会专门给他指定一个回滚段,以后该事务用到的undo log页,就从该回滚段上分配;
- 事务提交后,需要purge的回滚段会被放到purge队列上(
purge_sys->purge_queue)。
各个结构体之间的联系如下:
分配回滚段
当开启一个读写事务时(或者从只读事务转换为读写事务),我们需要预先为事务分配一个回滚段:
对于只读事务,如果产生对临时表的写入,则需要为其分配回滚段,使用临时表回滚段(第1~32号回滚段),函数入口:trx_assign_rseg -->trx_assign_rseg_low-->get_next_noredo_rseg。
在MySQL5.7中事务默认以只读事务开启,当随后判定为读写事务时,则转换成读写模式,并为其分配事务ID和回滚段,调用函数:trx_set_rw_mode -->trx_assign_rseg_low --> get_next_redo_rseg。
普通回滚段的分配方式如下:
- 采用round-robin的轮询方式来赋予回滚段给事务,如果回滚段被标记为skip_allocation(这个undo tablespace太大了,purge线程需要对其进行truncate操作),则跳到下一个;
- 选择一个回滚段给事务后,会将该回滚段的
rseg->trx_ref_count递增,这样该回滚段所在的undo tablespace文件就不可以被truncate掉; - 临时表回滚段被赋予
trx->rsegs->m_noredo,普通读写操作的回滚段被赋予trx->rsegs->m_redo;如果事务在只读阶段使用到临时表,随后转换成读写事务,那么会为该事务分配两个回滚段。
使用回滚段
当产生数据变更时,我们需要使用Undo log记录下变更前的数据以维护多版本信息。insert 和 delete/update 分开记录undo,因此需要从回滚段单独分配Undo slot。
入口函数:trx_undo_report_row_operation
流程如下:
- 判断当前变更的是否是临时表,如果是临时表,则采用临时表回滚段来分配,否则采用普通的回滚段;
- 临时表操作记录undo时不写redo log;
- 操作类型为TRX_UNDO_INSERT_OP,且未分配insert undo slot时,调用函数
trx_undo_assign_undo进行分配; - 操作类型为TRX_UNDO_MODIFY_OP,且未分配Update undo slot时,调用函数
trx_undo_assign_undo进行分配。
我们来看看函数trx_undo_assign_undo的流程:
- 首先总是从cahced list上分配trx_undo_t (函数
trx_undo_reuse_cached,当满足某些条件时,事务提交时会将其拥有的trx_undo_t放到cached list上,这样新的事务可以重用这些undo 对象,而无需去扫描回滚段,寻找可用的slot,在后面的事务提交一节会介绍到);- 对于INSERT,从
trx_rseg_t::insert_undo_cached上获取,并修改头部重用信息(trx_undo_insert_header_reuse)及预留XID空间(trx_undo_header_add_space_for_xid) - 对于DELETE/UPDATE,从
trx_rseg_t::update_undo_cached上获取, 并在undo log hdr page上创建新的Undo log header(trx_undo_header_create),及预留XID存储空间(trx_undo_header_add_space_for_xid) - 获取到trx_undo_t对象后,会从cached list上移除掉。并初始化trx_undo_t相关信息(trx_undo_mem_init_for_reuse),将
trx_undo_t::state设置为TRX_UNDO_ACTIVE
- 对于INSERT,从
-
如果没有cache的trx_undo_t,则需要从回滚段上分配一个空闲的undo slot(trx_undo_create),并创建对应的undo页,进行初始化;
一个回滚段可以支持1024个事务并发,如果不幸回滚段都用完了(通常这几乎不会发生),会返回错误DB_TOO_MANY_CONCURRENT_TRXS
每一个Undo log segment实际上对应一个独立的段,段头的起始位置在UNDO 头page的TRX_UNDO_SEG_HDR+TRX_UNDO_FSEG_HEADER偏移位置(见下图)
-
已分配给事务的trx_undo_t会加入到链表
trx_rseg_t::insert_undo_list或者trx_rseg_t::update_undo_list上; - 如果是数据词典操作(DDL)产生的undo,主要是表级别操作,例如创建或删除表,还需要记录操作的table id到undo log header中(TRX_UNDO_TABLE_ID),同时将TRX_UNDO_DICT_TRANS设置为TRUE。(trx_undo_mark_as_dict_operation)。
总的来说,undo header page主要包括如下信息:
如何写入undo日志
入口函数:trx_undo_report_row_operation
当分配了一个undo slot,同时初始化完可用的空闲区域后,就可以向其中写入undo记录了。写入的page no取自undo->last_page_no,初始情况下和hdr_page_no相同。
对于INSERT_UNDO,调用函数trx_undo_page_report_insert进行插入,记录格式大致如下图所示:
对于UPDATE_UNDO,调用函数trx_undo_page_report_modify进行插入,UPDATE UNDO的记录格式大概如下图所示:
在写入的过程中,可能出现单页面空间不足的情况,导致写入失败,我们需要将刚刚写入的区域清空重置(trx_undo_erase_page_end),同时申请一个新的page(trx_undo_add_page) 加入到undo log段上,同时将undo->last_page_no指向新分配的page,然后重试。
完成Undo log写入后,构建新的回滚段指针并返回(trx_undo_build_roll_ptr),回滚段指针包括undo log所在的回滚段id、日志所在的page no、以及page内的偏移量,需要记录到聚集索引记录中。
事务Prepare阶段
入口函数:trx_prepare_low
当事务完成需要提交时,为了和BINLOG做XA,InnoDB的commit被划分成了两个阶段:prepare阶段和commit阶段,本小节主要讨论下prepare阶段undo相关的逻辑。
为了在崩溃重启时知道事务状态,需要将事务设置为Prepare,MySQL 5.7对临时表undo和普通表undo分别做了处理,前者在写undo日志时总是不需要记录redo,后者则需要记录。
分别设置insert undo 和 update undo的状态为prepare,调用函数trx_undo_set_state_at_prepare,过程也比较简单,找到undo log slot对应的头页面(trx_undo_t::hdr_page_no),将页面段头的TRX_UNDO_STATE设置为TRX_UNDO_PREPARED,同时修改其他对应字段,如下图所示(对于外部显式XA所产生的XID,这里不做讨论):
Tips:InnoDB层的XID是如何获取的呢? 当Innodb的参数innodb_support_xa打开时,在执行事务的第一条SQL时,就会去注册XA,根据第一条SQL的query id拼凑XID数据,然后存储在事务对象中。参考函数trans_register_ha。
事务Commit
当事务commit时,需要将事务状态设置为COMMIT状态,这里同样通过Undo来实现的。
入口函数:trx_commit_low-->trx_write_serialisation_history
在该函数中,需要将该事务包含的Undo都设置为完成状态,先设置insert undo,再设置update undo(trx_undo_set_state_at_finish),完成状态包含三种:
- 如果当前的undo log只占一个page,且占用的header page大小使用不足其3/4时(TRX_UNDO_PAGE_REUSE_LIMIT),则状态设置为TRX_UNDO_CACHED,该undo对象会随后加入到undo cache list上;
- 如果是Insert_undo(undo类型为TRX_UNDO_INSERT),则状态设置为TRX_UNDO_TO_FREE;
- 如果不满足a和b,则表明该undo可能需要Purge线程去执行清理操作,状态设置为TRX_UNDO_TO_PURGE。
在确认状态信息后,写入undo header page的TRX_UNDO_STATE中。
如果当前事务包含update undo,并且undo所在回滚段不在purge队列时,还需要将当前undo所在的回滚段(及当前最大的事务号)加入Purge线程的Purge队列(purge_sys->purge_queue)中(参考函数trx_serialisation_number_get)。
对于undate undo需要调用trx_undo_update_cleanup进行清理操作,清理的过程包括:
-
将undo log加入到history list上,调用
trx_purge_add_update_undo_to_history:-
如果该undo log不满足cache的条件(状态为TRX_UNDO_CACHED,如上述),则将其占用的slot设置为FIL_NULL,意为slot空闲,同时更新回滚段头的TRX_RSEG_HISTORY_SIZE值,将当前undo占用的page数累加上去;
-
将当前undo加入到回滚段的TRX_RSEG_HISTORY链表上,作为链表头节点,节点指针为UNDO头的TRX_UNDO_HISTORY_NODE;
-
更新
trx_sys->rseg_history_len(也就是show engine innodb status看到的history list),如果只有普通的update_undo,则加1,如果还有临时表的update_undo,则加2,然后唤醒purge线程; -
将当前事务的
trx_t::no写入undo头的TRX_UNDO_TRX_NO段; -
如果不是delete-mark操作,将undo头的TRX_UNDO_DEL_MARKS更新为false;
-
如果undo所在回滚段的
rseg->last_page_no为FIL_NULL,表示该回滚段的旧的清理已经完成,进行如下赋值,记录这个回滚段上第一个需要purge的undo记录信息:-
rseg->last_page_no = undo->hdr_page_no;
-
rseg->last_offset = undo->hdr_offset;
-
rseg->last_trx_no = trx->no;
-
rseg->last_del_marks = undo->del_marks;
-
-
-
如果undo需要cache,将undo对象放到回滚段的update_undo_cached链表上;否则释放undo对象(trx_undo_mem_free)。
注意上面只清理了update_undo,insert_undo直到事务释放记录锁、从读写事务链表清除、以及关闭read view后才进行,调用函数trx_undo_insert_cleanup:
-
如果Undo状态为TRX_UNDO_CACHED,则加入到回滚段的insert_undo_cached链表上;
-
否则,将该undo所占的segment及其所占用的回滚段的slot全部释放掉(trx_undo_seg_free),修改当前回滚段的大小(rseg->curr_size),并释放undo对象所占的内存(trx_undo_mem_free),和Update_undo不同,insert_undo并未放到History list上。
事务完成提交后,需要将其使用的回滚段引用计数rseg->trx_ref_count减1;
事务回滚
如果事务因为异常或者被显式的回滚了,那么所有数据变更都要改回去。这里就要借助回滚日志中的数据来进行恢复了。
入口函数为:row_undo_step --> row_undo
操作也比较简单,析取老版本记录,做逆向操作即可:对于标记删除的记录清理标记删除标记;对于in-place更新,将数据回滚到最老版本;对于插入操作,直接删除聚集索引和二级索引记录(row_undo_ins)。
具体的操作中,先回滚二级索引记录(row_undo_mod_del_mark_sec、row_undo_mod_upd_exist_sec、row_undo_mod_upd_del_sec),再回滚聚集索引记录(row_undo_mod_clust)。这里不展开描述,可以参阅对应的函数。
多版本控制
InnoDB的多版本使用undo来构建,这很好理解,undo记录中包含了记录更改前的镜像,如果更改数据的事务未提交,对于隔离级别大于等于read commit的事务而言,它不应该看到已修改的数据,而是应该给它返回老版本的数据。
入口函数: row_vers_build_for_consistent_read
由于在修改聚集索引记录时,总是存储了回滚段指针和事务id,可以通过该指针找到对应的undo 记录,通过事务Id来判断记录的可见性。当旧版本记录中的事务id对当前事务而言是不可见时,则继续向前构建,直到找到一个可见的记录或者到达版本链尾部。(关于事务可见性及read view,可以参阅我们之前的月报)
Tips 1:构建老版本记录(trx_undo_prev_version_build)需要持有page latch,因此如果Undo链太长的话,其他请求该page的线程可能等待时间过长导致crash,最典型的就是备库备份场景:
当备库使用innodb表存储复制位点信息时(relay_log_info_repository=TABLE),逻辑备份显式开启一个read view并且执行了长时间的备份时,这中间都无法对slave_relay_log_info表做purge操作,导致版本链极其长;当开始备份slave_relay_log_info表时,就需要去花很长的时间构建老版本;复制线程由于需要更新slave_relay_log_info表,因此会陷入等待Page latch的场景,最终有可能导致信号量等待超时,实例自杀。 (bug#74003)
Tips 2:在构建老版本的过程中,总是需要创建heap来存储旧版本记录,实际上这个heap是可以重用的,无需总是重复构建(bug#69812)
Tips 3:如果回滚段类型是INSERT,就完全没有必要去看Undo日志了,因为一个未提交事务的新插入记录,对其他事务而言总是不可见的。
Tips 4: 对于聚集索引我们知道其记录中存有修改该记录的事务id,我们可以直接判断是否需要构建老版本(lock_clust_rec_cons_read_sees),但对于二级索引记录,并未存储事务id,而是每次更新记录时,同时更新记录所在的page上的事务id(PAGE_MAX_TRX_ID),如果该事务id对当前事务是可见的,那么就无需去构建老版本了,否则就需要去回表查询对应的聚集索引记录,然后判断可见性(lock_sec_rec_cons_read_sees)。
Purge清理操作
从上面的分析我们可以知道:update_undo产生的日志会放到history list中,当这些旧版本无人访问时,需要进行清理操作;另外页内标记删除的操作也需要从物理上清理掉。后台Purge线程负责这些工作。
入口函数:srv_do_purge --> trx_purge
-
确认可见性
在开始尝试purge前,purge线程会先克隆一个最老的活跃视图(
trx_sys->mvcc->clone_oldest_view),所有在readview开启之前提交的事务所做的事务变更都是可以清理的。 -
获取需要purge的undo记录(
trx_purge_attach_undo_recs)从history list上读取多个Undo记录,并分配到多个purge线程的工作队列上(
(purge_node_t*) thr->child->undo_recs),默认一次最多取300个undo记录,可通过参数innodb_purge_batch_size参数调整。 -
Purge工作线程
当完成任务的分发后,各个工作线程(包括协调线程)开始进行purge操作 入口函数: row_purge_step -> row_purge -> row_purge_record_func
主要包括两种:一种是记录直接被标记删除了,这时候需要物理清理所有的聚集索引和二级索引记录(
row_purge_record_func);另一种是聚集索引in-place更新了,但二级索引上的记录顺序可能发生变化,而二级索引的更新总是标记删除 + 插入,因此需要根据回滚段记录去检查二级索引记录序是否发生变化,并执行清理操作(row_purge_upd_exist_or_extern)。 -
清理history list
从前面的分析我们知道,insert undo在事务提交后,Undo segment 就释放了。而update undo则加入了history list,为了将这些文件空间回收重用,需要对其进行truncate操作;默认每处理128轮Purge循环后,Purge协调线程需要执行一次purge history List操作。
入口函数:
trx_purge_truncate --> trx_purge_truncate_history从回滚段的HISTORY 文件链表上开始遍历释放Undo log segment,由于history 链表是按照trx no有序的,因此遍历truncate直到完全清除,或者遇到一个还未purge的undo log(trx no比当前purge到的位置更大)时才停止。
关于Purge操作的逻辑实际上还算是比较复杂的代码模块,这里只是简单的介绍了下,以后有时间再展开描述。
崩溃恢复
当实例从崩溃中恢复时,需要将活跃的事务从undo中提取出来,对于ACTIVE状态的事务直接回滚,对于Prepare状态的事务,如果该事务对应的binlog已经记录,则提交,否则回滚事务。
实现的流程也比较简单,首先先做redo (recv_recovery_from_checkpoint_start),undo是受redo 保护的,因此可以从redo中恢复(临时表undo除外,临时表undo是不记录redo的)。
在redo日志应用完成后,初始化完成数据词典子系统(dict_boot),随后开始初始化事务子系统(trx_sys_init_at_db_start),undo 段的初始化即在这一步完成。
在初始化undo段时(trx_sys_init_at_db_start -> trx_rseg_array_init -> ... -> trx_undo_lists_init),会根据每个回滚段page中的slot是否被使用来恢复对应的undo log,读取其状态信息和类型等信息,创建内存结构,并存放到每个回滚段的undo list上。
当初始化完成undo内存对象后,就要据此来恢复崩溃前的事务链表了(trx_lists_init_at_db_start),根据每个回滚段的insert_undo_list来恢复插入操作的事务(trx_resurrect_insert),根据update_undo_list来恢复更新事务(tex_resurrect_update),如果既存在插入又存在更新,则只恢复一个事务对象。另外除了恢复事务对象外,还要恢复表锁及读写事务链表,从而恢复到崩溃之前的事务场景。
当从Undo恢复崩溃前活跃的事务对象后,会去开启一个后台线程来做事务回滚和清理操作(recv_recovery_rollback_active -> trx_rollback_or_clean_all_recovered),对于处于ACTIVE状态的事务直接回滚,对于既不ACTIVE也非PREPARE状态的事务,直接则认为其是提交的,直接释放事务对象。但完成这一步后,理论上事务链表上只存在PREPARE状态的事务。
随后很快我们进入XA Recover阶段,MySQL使用内部XA,即通过Binlog和InnoDB做XA恢复。在初始化完成引擎后,Server层会开始扫描最后一个Binlog文件,搜集其中记录的XID(MYSQL_BIN_LOG::recover),然后和InnoDB层的事务XID做对比。如果XID已经存在于binlog中了,对应的事务需要提交;否则需要回滚事务。
Tips:为何只需要扫描最后一个binlog文件就可以了? 因为在每次rotate到一个新的binlog文件之前,总是要保证前一个binlog文件中对应的事务都提交并且sync redo到磁盘了,也就是说,前一个binlog文件中的事务在崩溃恢复时肯定是出于提交状态的。
 posted on
posted on
