

day 18






# 计算器
# re模块
# 正则表达式 —— 字符串匹配的
# 学习正则表达式
# 学习使用re模块来操作正则表达式
# while True:
# phone_number = input('please input your phone number : ')
# if len(phone_number) == 11 \
# and phone_number.isdigit()\
# and (phone_number.startswith('13') \
# or phone_number.startswith('14') \
# or phone_number.startswith('15') \
# or phone_number.startswith('18')):
# print('是合法的手机号码')
# else:
# print('不是合法的手机号码')
# import re
# phone_number = input('please input your phone number : ')
# if re.match('^(13|14|15|18)[0-9]{9}$',phone_number):
# print('是合法的手机号码')
# else:
# print('不是合法的手机号码')
# 绿茶 白茶 黄茶 青茶(乌龙茶) 红茶 黑茶
# 发酵程度和制作工艺
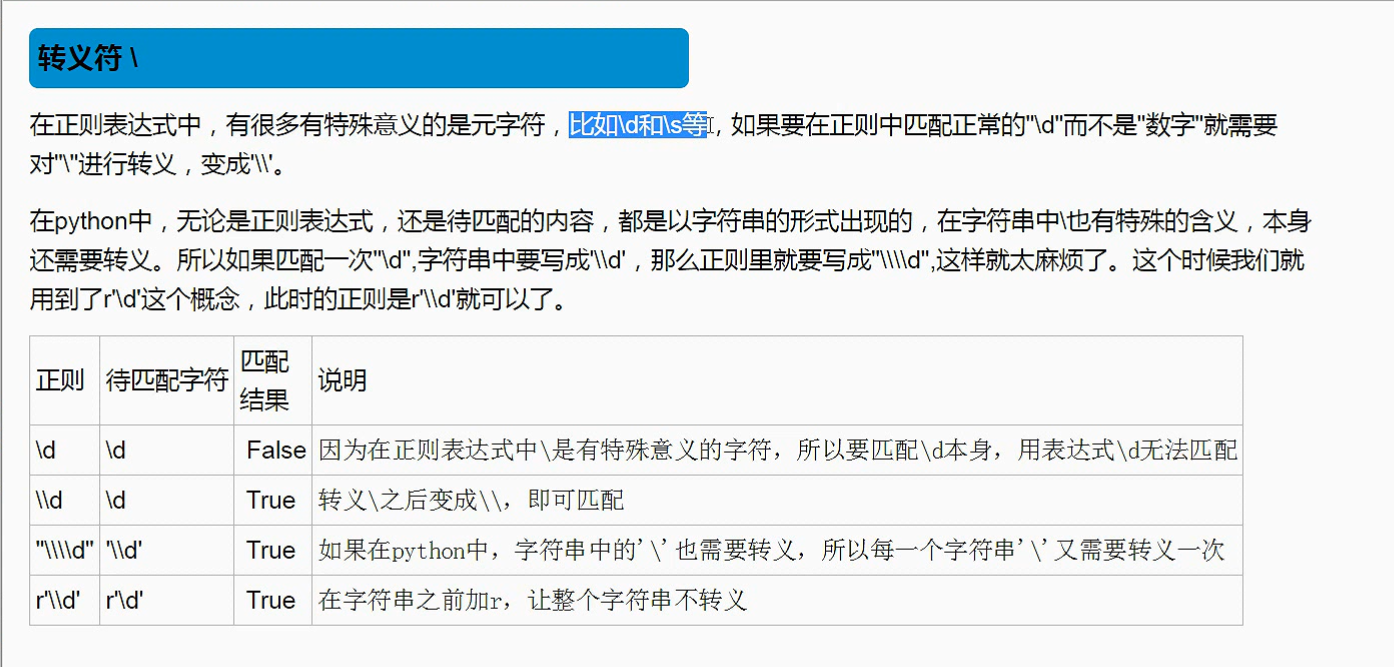
# print(r'\\n')
# print(r'\n')
import re
# findall
# search
# match
# ret = re.findall('[a-z]+', 'eva egon yuan')
# # 返回所有满足匹配条件的结果,放在列表里
# print(ret)
# ret = re.search('a', 'eva egon yuan')
# if ret:
# print(ret.group())
# 从前往后,找到一个就返回,返回的变量需要调用group才能拿到结果
# 如果没有找到,那么返回None,调用group会报错
# ret = re.match('[a-z]+', 'eva egon yuan')
# if ret:
# print(ret.group())
# match是从头开始匹配,如果正则规则从头开始可以匹配上,就返回一个变量。
# 匹配的内容需要用group才能显示
# 如果没匹配上,就返回None,调用group会报错
# ret = re.split('[ab]', 'abcd')
# # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
# print(ret) # ['', '', 'cd']
# ret = re.sub('\d', 'H', 'eva3egon4yuan4',1)
#将数字替换成'H',参数1表示只替换1个
# print(ret) #evaHegon4yuan4
# ret = re.subn('\d', 'H', 'eva3egon4yuan4')
# #将数字替换成'H',返回元组(替换的结果,替换了多少次)
# print(ret)
# obj = re.compile('\d{3}')
# #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
# ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
# print(ret.group())
# ret = obj.search('abcashgjgsdghkash456eeee3wr2') #正则表达式对象调用search,参数为待匹配的字符串
# print(ret.group()) #结果 : 123
# import re
# ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
# print(ret) # <callable_iterator object at 0x10195f940>
# # print(next(ret).group()) #查看第一个结果
# # print(next(ret).group()) #查看第二个结果
# # print([i.group() for i in ret]) #查看剩余的左右结果
# for i in ret:
# print(i.group())
import re
# ret = re.search('^[1-9](\d{14})(\d{2}[0-9x])?$','110105199912122277')
# print(ret.group())
# print(ret.group(1))
# print(ret.group(2))
# import re
#
# ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
# print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
#
# ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
# print(ret) # ['www.oldboy.com']
ret=re.split("\d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan']
ret=re.split("(\d+)","eva3egon4yuan")
print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']
import re
from urllib.request import urlopen
def getPage(url):
response = urlopen(url)
return response.read().decode('utf-8')
def parsePage(s):
ret = re.findall(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',s,re.S)
return ret
def main(num):
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
print(ret)
count = 0
for i in range(10): # 10页
main(count)
count += 25
# url从网页上把代码搞下来
# bytes decode ——> utf-8 网页内容就是我的待匹配字符串
# ret = re.findall(正则,带匹配的字符串) #ret是所有匹配到的内容组成的列表
a = '1 - 2 * ( ( 6 0 -3 0 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )'
# 去掉所有的空格
# 加减乘除 括号
# 先算括号里的乘除,再算括号里的加减
# 从括号里取值 == 正则表达式
ss = '9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14'
# 从一个没有括号的表达式中取 */法 == 正则表达式
# 复习
# 元字符 量词
# re模块
# 预习
# 今天没讲的练习题
# 作业
# 计算器
# 今天的作业 : 从括号里取值 == 正则表达式
# 从括号里取值 == 正则表达式
