mysql高级
优化分析
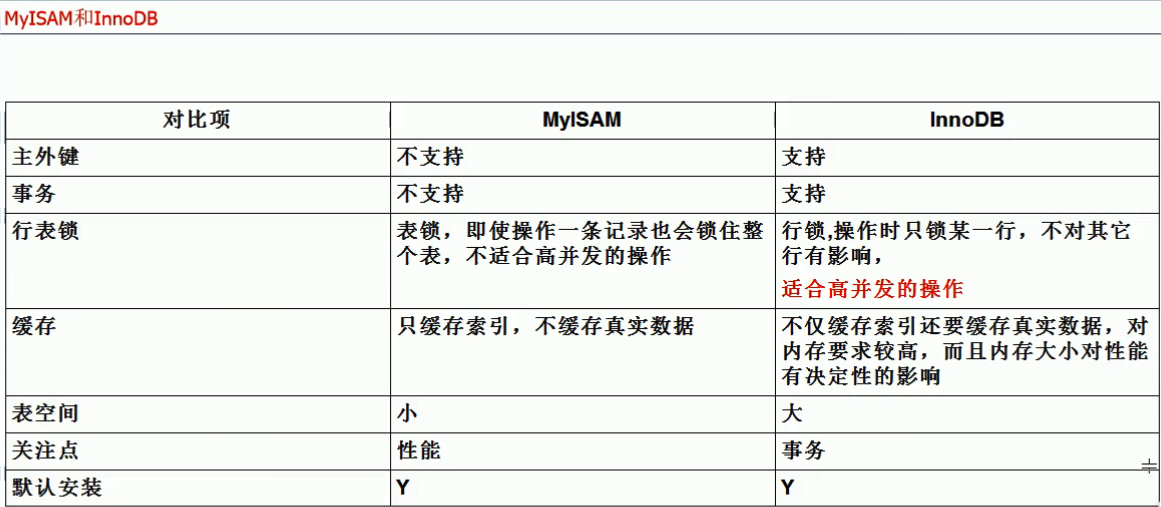
一、存储引擎的对比
二、性能下降SQL慢 、执行时间长、等待时间长
- 查询语句复杂
- 索引失效(单值索引、复合索引)
- 关联查询有太多join(设计缺陷或不得已的需求)
三、常见的Join查询
- SQL执行顺序:手写、机读
- 手写顺序:
#sql语句的手写顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN <right_table> ON <join_condition> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> ORDER BY <order_by_condition> LIMIT <limit_number>
-
机读顺序:
#机读顺序 FROM <left_table> ON <join_condition> <join_type> JOIN <right_table> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> SELECT DISTINCT <select_list> ORDER BY <order_by_condition> LIMIT <limit_number>
总结:https://database.51cto.com/art/201911/605471.htm
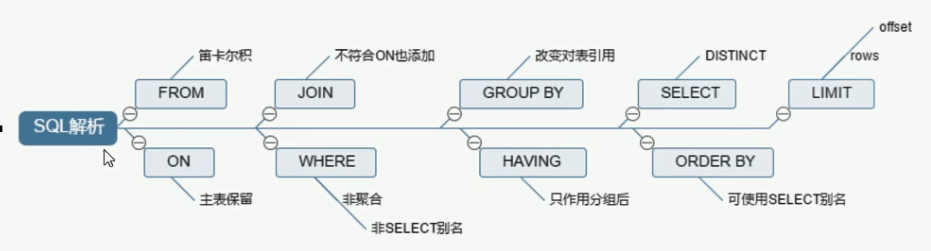
四、七种Join如下所示:
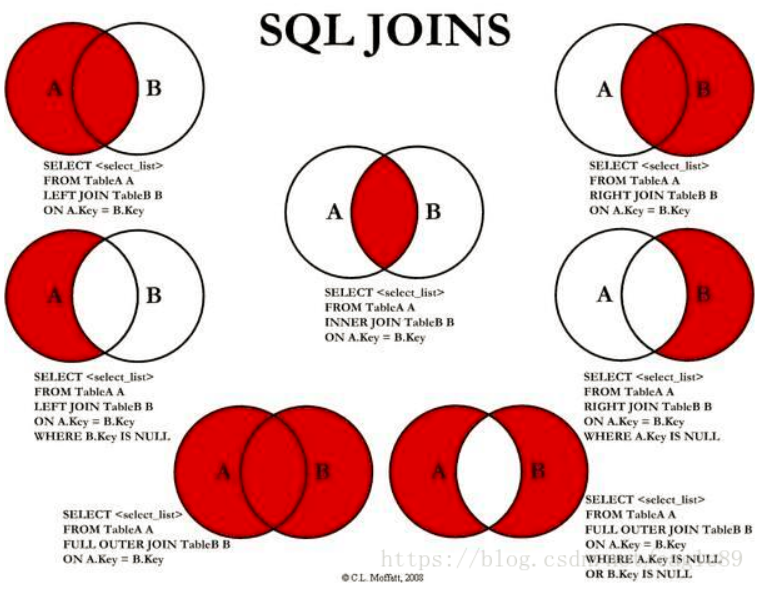
注意:mysql不支持全外连接,但是可以使用union(联合+去重)把左外连接和右外连接联合起来。
五、索引
定义:索引(Index)是帮助MySQL高效获取数据的数据结构 。索引的目的在于提高查找效率,类比字典。除了数据本身之外,数据库还维护一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高效的查找算法,这种数据结构就是索引(排序好的快速查找的数据结构)。
一般来说索引本身很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
索引的优势:
- 提高数据检索的效率,降低数据库的IO成本,类似大学图书馆建书目索引
- 通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗
索引的劣势:
- 索引可以看成一张表,也要占用空间。
- 索引会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加的索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
索引的分类:
- 单值索引:即一个索引只包含单个列,一个表可以有多个单列索引
- 唯一索引:索引列的值必须唯一,但允许有空值(比如身份证号就是唯一的,可以做唯一索引)
- 复合索引:即一个索引包含多个列
mysql索引结构:
- BTree索引
- Hash索引
- full-test全文索引
- R-Tree索引
哪些情况需要创建索引:
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 频繁更新的字段不适合创建索引(因为每次更新不单单是更新了记录,还会更新索引)
- where条件里用不到的字段不创建索引
- 在高并发下倾向于创建组合索引
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序的速度
- 查询中统计或者分组的字段
性能分析:
1、Explain:使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈。
2、使用方法:
EXPLAIN SELECT * FROM <table>;
3、explain的作用:
通过EXPALIN,我们可以分析出以下结果:
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
执行计划各个字段的含义
![]()
1. id: select查询的序列号,表示查询中执行select子句或操作表的顺序
一、id会出现三种结果:
1.id相同,执行顺序由上至下

有上图可见,操作表的id号均为1,所以操作顺序为
d->l->employees
2. id不同时,id值越大优先级越高,越先被执行
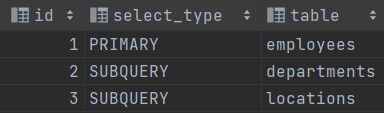
如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
3. id既有相同的,又有不同的
说明:id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
注意:执行过程中,衍生的表用derived表示。
二、查询类型select_type
作用:用来表示查询的类型,主要用于区别普通查询、联合查询、子查询等复杂查询
- SIMPLE: 简单的select查询,查询中不包含子查询和UNION
- PRIMARY: 查询中若包含任何复杂的子部分,最外层查询则被标记为PRIMARY
- SUBQUERY: 在SELECT或WHERE列表中包含了子查询
- DERIVED: 在FROM列表中包含的子查询被标记为DERIVED(衍生),MySQL会递归执行这些子查询,把结果放在临时表中
- UNION: 若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在FROM子句的子查询中,外层的SELECT将被标记为DERIVED
- UNION RESULT:UNION的最终结果
eg.
explain select * from employees e left join departments d on e.department_id = d.department_id union select * from employees e right join departments d on e.department_id = d.department_id;
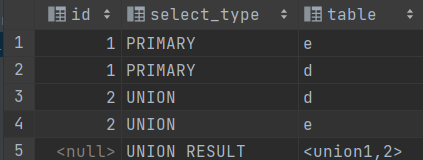
三、table
table就是操作表
四、type
type表示使用了那种类型的查询,分为以下几种:
- ALL
- index
- range
- ref
- eq_ref
- const
- system
- NULL
查询效率从高到低依次为:
system > const > eq_ref > ref > range > index > all
一般来说,需要保证查询至少达到range级别,最好能达到ref。
- system:表只有一行记录,很少出现
- const:表通过索引一次就找到了,const用于比较primary key或者unique索引。
select * from table where id(主键) = XX;
- eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。
- ref:非唯一性索引扫描,对于每个索引键,表中可以找到多个符合条件的行。
- range:只检索给定范围的行,比如在where语句中出现between、<、>、in等查询
select * from table where id between 30 and 60;
- index:index与all的区别在于index类型只遍历索引树,这通常比all快,因为索引文件通常比数据文件小(也就是说all和index都是读全表,但index根据索引扫描然后回表取数据,而all是从硬盘中读取)
select employee_id from employees;
- all:遍历全表
select * from employees;
五、ref
将列与索引进行比较,主要用来表示表的连接条件(即哪些列或常量被用于查找索引列上的值)
#案例:查找部门编号为1700的员工信息 explain select * from employees e, departments d where e.department_id = d.department_id and d.location_id = 1700;

分析结果可以看出:d表的location_id索引列匹配了一个常量(1700);e表的department_id索引列匹配了d表的department_id。他们之间的匹配关系我们可以清楚地从ref中查看到
六、rows
根据表的统计信息和索引的选用情况,大致估算出找到所需记录所需要读取的行数,rows列中的值,越小越好。
七、Extra
- Using filesort:说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取,这种无法利用表内索引进行的排序操作为“文件排序”。(不好)
explain select last_name, department_id from employees order by salary;
- Using temporary:说明使用了临时表保存中间结果,常见于order by 和group by。(不好)
- Using index:select操作中使用了覆盖索引(Covering Index)。
覆盖索引,也叫索引覆盖:select的数据列只用从索引中就能够取得,不必从数据表中读取。mysql可以利用索引返回select列表的字段,即查询的列要被所建的索引覆盖
explain select employee_id from employees;
1,SIMPLE,employees,null,index,,dept_id_fk,5,null,107,100,Using index
- Using where:使用了where过滤
- Using join buffer:多表join的次数非常多
- impossible where:where逻辑错误
八、索引优化
索引优化的总结
- 永远用小的结果集(主表)驱动大的结果集(驱动表)
- 优先优化内层的
- 保证join语句中被驱动表上的join条件字段被索引
九、索引失效
- 全职匹配:查询的语句的字段和顺序恰好和建立的索引的字段和顺序一致,否则索引会失效;
- 最佳左前缀法则:如果索引了多列,要遵守最左前缀法则(查询从索引的最左前列开始并且不能跳过索引中的列);
- 不在索引上做任何操作,包括计算、函数、(手动或自动)的类型转换,会导致索引失效,进而进行全表扫描;
- 不能使用索引中的范围条件右边的列;
- 减少使用select *,尽量使用索引的查询即索引列和查询列一致;
- 在使用不等于!= 、<> 的时候无法使用索引导致全表扫描;
- like以通配符开头(‘%abc’)时,索引会失效变成全表扫描; 解决方法可以使用覆盖索引,但是该方法具有一定的局限性;
- is null, is not null也无法使用索引;
- 字符串不加单引号会导致索引失效;
- 少用or,用它来连接时会失效;
十、查询优化
- 小表驱动大表
# 小表驱动大表 use myemployees; # 员工表有107条数据 select count(*) from employees; # 部门表有27条数据 select count(*) from departments; # 案例1. # 88ms select * from employees e where e.department_id in ( select d.department_id from departments d ); # 107ms select * from employees e where exists(select 1 from departments d where d.department_id = e.department_id); # 当d表的数据小于e表时,采用in要由于exists # in后面跟的是小表,exists后面跟的是大表(in后小,exists大) # select ...from table where exists(subquery)的理解:将主查询中的数据放入子查询中做条件验证,根据验证的结果(true/false)来决定主查询的数据是否保留
- order by关键字优order
原则:尽量使用Index方式排序,避免使用FileSort方式排序。链接一
filesort的原理,以及两种算法。链接二
- group by关键字优化:
- group by的实质是先排序后分组,同样遵循索引的最佳左前缀规则。
- 当无法使用索引列的时候,增大max_length_for_sort_data参数的设置 + 增大sort_buffer_size参数的设置
- where高于having,能写在where限定的条件下就不要去having限定了。
- 批量数据脚本:链接三
存储过程和函数的区别: 返回值:函数的返回值有且只有一个;而存储过程可以有多个或者没有返回值 调用:存储过程可以作为一个独立的部分来执行(CALL 调用);而函数作为查询语句的一部分来调用(SELECT 调用),函数的返回值可以是表,故可以放在FROM后面
十一、锁机制
1、
- 从对数据库操作的类型分,分为
读锁和写锁
读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响
写锁(排它锁):当前写操作没有完成前,它会阻断其他写锁和读锁 - 从对数据操作的粒度分,分为
表锁和行锁
2、表锁偏向MyISAM存储引擎,开销小,加锁快,无死锁,锁定粒度大,发生锁冲突的概率最高,并发度最低。
2.1 增加表锁
lock table 表名称 read(write), 表名称2 read(write),其他;
2.2 查看表上过的锁
show open tables; 1表示上锁;0表示未锁
2.3 删除表锁
unlock tables;
3、案例分析(加读锁):链接
4、案例分析(加写锁):链接
总结:
- 对MyISAM表的读操作(加读锁),不会阻塞其他进程对同一个表的读请求,但会阻塞对同一个表的写请求。只有当读锁释放后,才会执行其他进程的写操作;
- 对MyISAM表的写操作(加写锁),会阻塞其他进程对同一表的读和写操作,只有当写锁释放后,才会执行其他进程的读写操作;
5、行锁(偏写)
行锁偏向InnoDB存储引擎,开销大,加锁慢,会出现死锁,锁定粒度最小,发生锁冲突的概率最低,并发度也最高。InnoDB与MYISAM的最大不同有两点:一是支持事务(TRANSACTION);二是采用了行级锁。

6、索引失效会导致行锁变表锁
7、间隙锁及其危害
8、如何锁定一行:在SQL语句后面加上for update。
9、主从复制
9.1 简单介绍
在实际的生产环境中,单台MySQL数据库往往不能满足实际的需求。采用MySQL分布式集群,能够搭建一个高并发、负载均衡的集群服务器。在此之前,我们必须要保证每台MySQL服务器的数据同步,数据同步的方式主要有主从复制。
从上述简介中,我们可以总结出“为什么要做主从复制?”
- 方便地实现数据的多处自动备份,实现了数据库的拓展,还加强了数据的安全性;
- 可以实现读写分离。有这样一个情景,有一条sql语句需要表锁,导致其他事务暂时不能使用读的服务,那么就很影响运行中的业务。采用主从复制,让主库负责写,从库负责读。即使主库出现了表锁的情景,从库也可以保证业务的正常运作;
- 提高单机的I/O性能;
主从复制的原理可以分为以下3个步骤:
- 主服务器(master)把数据更改记录到二进制日志(bin_log)中;
- 从服务器(slave)把主服务器的二进制日志复制到自己的中继日志(relay log)中;
- 从服务器重做中继日志中的日志,把更改应用到自己的数据库上,以达到数据的最终一致性;
注意:主从复制不是完全实时地进行同步,而是异步实时,主服务器与从服务器之间存在执行延时。如果主服务器的压力很大,则可能导致主从服务器延时较大。
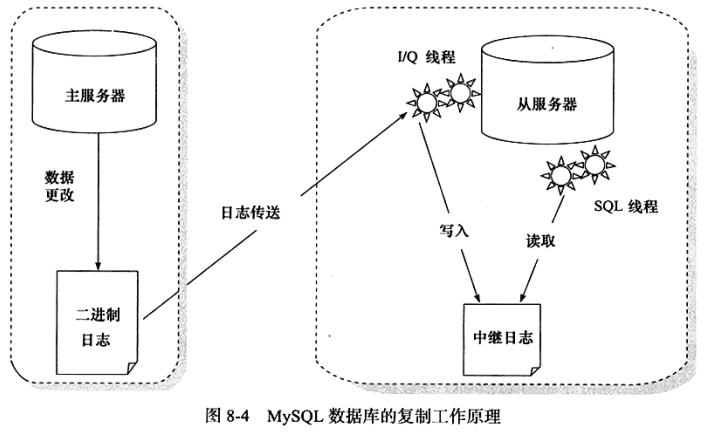
从图上可以看出,从服务器有两个线程,一个是I/O线程,负责读取主服务器上的二进制日志,并将其保存为中继日志;另一个是SQL线程,复制执行中继日志。
复制的基本原则:
- 每个Slave只有一个Master
- 每个Slave只能有一个唯一的服务ID
- 每个Master可以有多个Slave
更多内容见链接五
作者:Ryanjie
出处:http://www.cnblogs.com/ryanjan/
本文版权归作者和博客园所有,欢迎转载。转载请在留言板处留言给我,且在文章标明原文链接,谢谢!
如果您觉得本篇博文对您有所收获,觉得我还算用心,请点击右下角的 [推荐],谢谢!
