关于CNN中的感受野(Receptive Field)
①、感受野
在卷积神经网络(CNN)中,感受野是指卷积神经网络中每一层输出的特征图(feature map)上的每个像素点在原始图像上映射的区域大小。
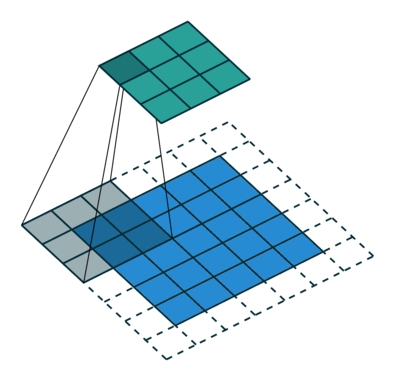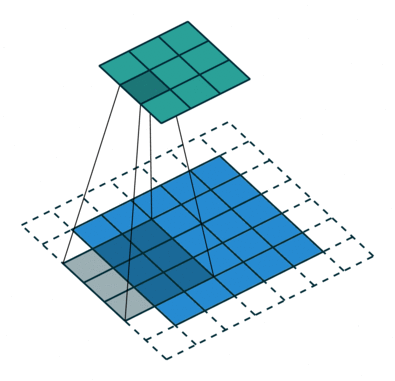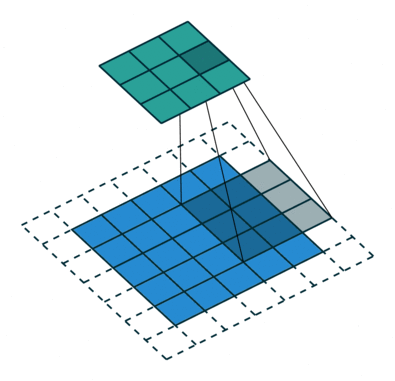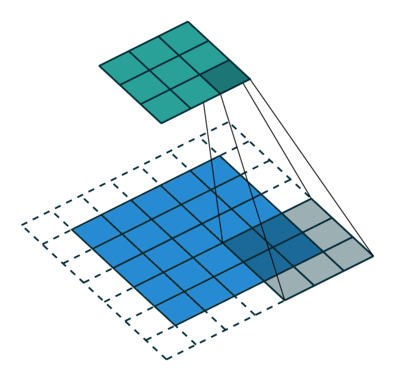
②、作用
神经元的感受野的值越大,表示其能接触到的原始图像范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节。因此感受野的值可以用来大致判断每一层的抽象层次。
③、感受野的计算
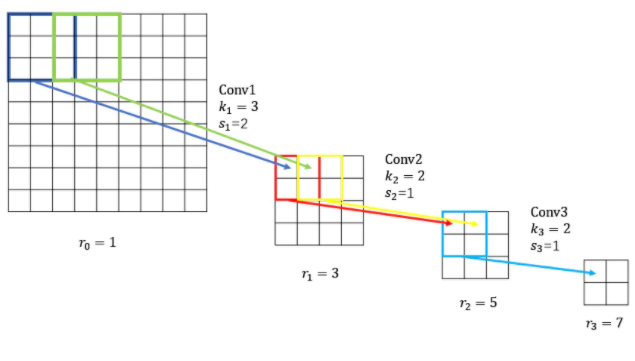
说明:①、第一卷积层的输出特征图的像素的感受野大小等于滤波器的大小;②、深层的卷积层的感受野大小和改层之前所有层的滤波器大小和步长有关;③、计算感受野时,不考虑padding的大小;④定义一些符号:$k_{n}$、$s_{n}$、$r_{n}$分别表示第$n$层的$kernel_size$、$stride$、$receptive_field$。
- 在输入图像中,每个像素的感受野$r_{0} = 1$,这很好理解嘛,在原始输入图像上,每一个像素和自己对应嘛。
- 对于Conv1层,他的感受野$r_{1}=3$
- 对于Conv2层,它的感受野最大为$k_{n} \times r_{n-1}=2 \times 3=6$。但是我们对第$n-1$层进行卷积时,由于$s_{n-1}$小于$k_{n-1}$,故会存在重叠的部分,我们要减去重叠的部分。
- $r_{n=2} = k_{n} \times r_{n-1} - (k_{n-1} - s_{n-1}) * r(n-2) = 2 * 3 - (3 - 2)*1 = 5$
- 对于Conv3层,它的感受野最大为$k_{3} * r_{2} = 2*5=10$。但是Conv3的前一层Conv2在卷积的时候,由于重叠,重叠的部分为$(k_{2}-s_{2})*r_{1} = (2-1)*3 = 3$。
- 所以$r_{3} = 10 - 3 = 7$
综上,我们的以得出$r_{n} = k_{n} \times r_{n-1} - (k_{n-1} - s_{n-1}) * r(n-2) $
当然,我们也可以这么计算:
$r_{n} = r_{n-1} + (k_{n} - 1) \times ?$
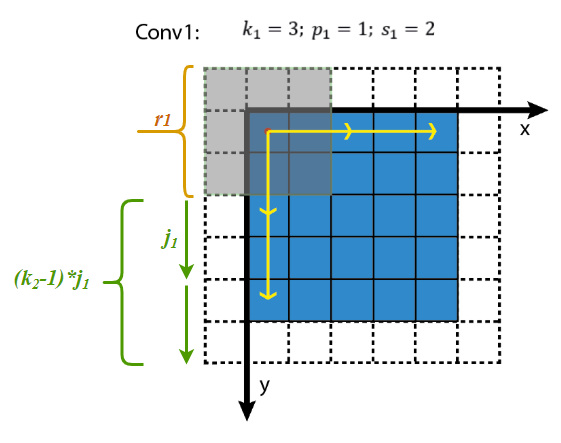
这个公式可以这样理解:第$k$层的一个位置在第$k-1$层的视野大小为$k_{n}$,但是这些位置要一直向前扩展到输入层,对于第一个位置,扩展后的视野即为$r_{n-1}$,正好是前一层的感受野大小。但是对于剩余的$k_{n} - 1$个位置就要看$Stride$的大小了(注意这里的$Stide$)并不包括当前层的,当前层只会影响到后面层的感受野),那么剩余的$k_{n} -1$个位置究竟在输入图像上前进多少个像素呢?我们这里暂且用?表示。
我们用$j_{l-1}替代$?$,那怎么求解呢?
第$l$层前进一个元素,相当于第$l-1$层上前进$s_{l}$个元素,表示一下为:
$j_{l} = j_{l-1} \times s_{l}$,这里$s_{l}$表示$Convl$的卷积核在第$l-1$层上滑动的步长,特殊的输入图像的$s_{0} = 1$
根据上述地推公式有:
$j_{l} = \prod_{i=0}^{l}s_{i}$
那么我们可以看出,第$l$层上前进一个元素,相当于在输入图像前进了$\prod_{i=0}^{l}s_{i}=\prod_{i=1}^{l}s_{i}$个像素。
那么现在知道$?$怎么来的吧,$?=\prod_{i=1}^{n-1}s_{i}$
综上有:$r_{n} = r_{n-1} + (k_{n} - 1) \times \prod_{i=1}^{n-1}s_{i}$
也有写成这样的,其实和上面是一样的。
$r_{n} = r_{n-1}\times k_{n}-(k_{n}-1)( r_{n-1} -\prod_{i=1}^{n-1}s_{i})$
当然还有一种从CNN神经网络到输入端的计算方法,但是我觉得物理意义没有这个清晰(也可能我没弄明白哈),后面给出链接。
一、https://zhuanlan.zhihu.com/p/35708466(公式解释)
二、https://www.cnblogs.com/shine-lee/p/12069176.html(物理解释)
三、https://yifdu.github.io/2019/03/24/感受野的计算问题/(文末有另一种计算方法)
四、https://www.jianshu.com/p/9997c6f5c01e
作者:Ryanjie
出处:http://www.cnblogs.com/ryanjan/
本文版权归作者和博客园所有,欢迎转载。转载请在留言板处留言给我,且在文章标明原文链接,谢谢!
如果您觉得本篇博文对您有所收获,觉得我还算用心,请点击右下角的 [推荐],谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号