VGG16学习笔记
VGG16
一、摘要
- VGG-16主要采用增加卷积层的方法来加深网络,结果发现网络深度越深,网络学习的效果越好,分类能力越强。
- 该文表明:使用非常小的卷积滤波器(3×3)增加网络深度,当深度增加到16-19层时,可以实现对现有技术的显著改,并且对于其他图像识别的数据集也有很好的推广能力。
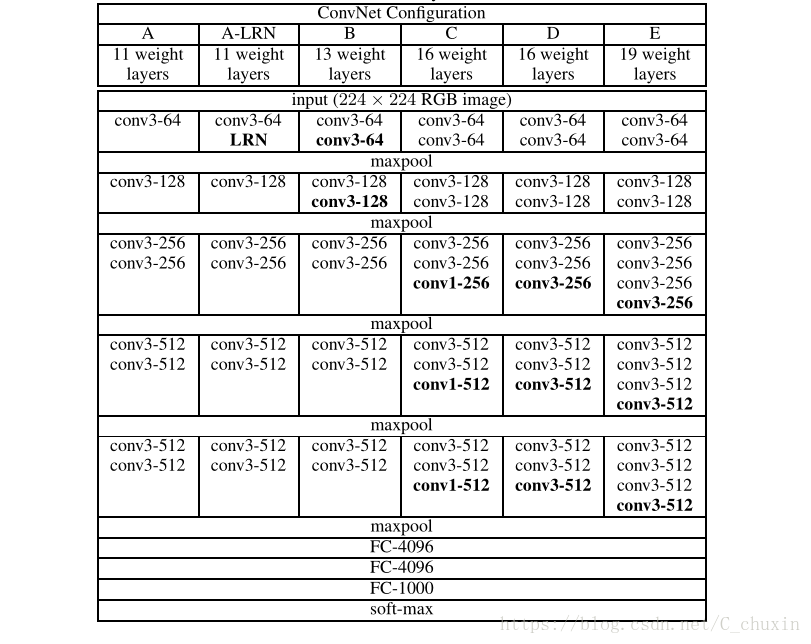
二、ConvNet的配置
- 输入图像:固定大小的224×224的RGB图像(预处理为对每个像素减去RGB均值)。
- 卷积层:使用3×3的卷积滤波器,stride = 1,padding为same,卷积后的图像尺寸不变(ConvNet Configuration C中另用conv1,其中1×1的卷积滤波器可以看作输入通道的线性变换)。
- 池化层:窗口为2×2,stride = 2(池化后图像的尺寸减半),它们跟随在一些卷积层之后,但并不是所有卷积层之后都有池化层。
- 全连接层:有三个全连接层FC,前两个有4096个通道,最后一个有1000个通道(每个类别占一个通道)。
- softmax:实现多种类分类
所有隐藏层之后,都配有ReLU(Rectified linear uint-修正线性单元)
VGG-16中的16指的是在这个网络中包含16个卷积层和全连接层。此外还有VGG-19,由于VGG-16和VGG-19的表现几乎误无差,且VGG-16的参数较VGG-19少,所以大多数人依然选取VGG-16
三、说明
①、卷积层使用3×3的滤波器,很容易看到两层3×3的卷积层(两层之间无池化层)的感受野和一层5×5的卷积层相同,三层3×3的卷积层有7×7的有效感受野。这种替换是合理有效的。
- 每一层卷积层后会跟着非线性校正层ReLU。那么相较于单个非线性修正层,使用了三个的会使网络的决策更有判别性。
- 这种替换减少了参数。假设输入卷积层的通道数均为C1,输出的特征图的通道数也为C2(也就是卷积滤波器的数量)。那么3×3的情况共有3×(3×3×C1×C2)=27C1C2 ; 7×7的情况有(7×7×C1×C2)=49C1C2
关于感受野的说明:通俗讲为输出特征图上的一个单元对应输入层上的区域大小
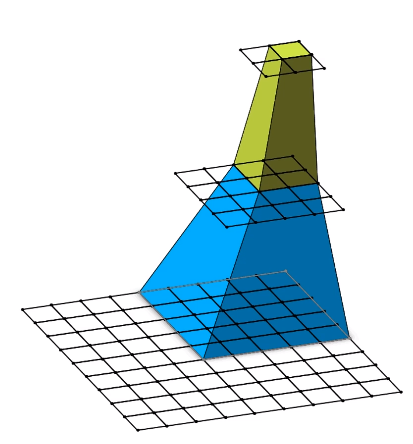

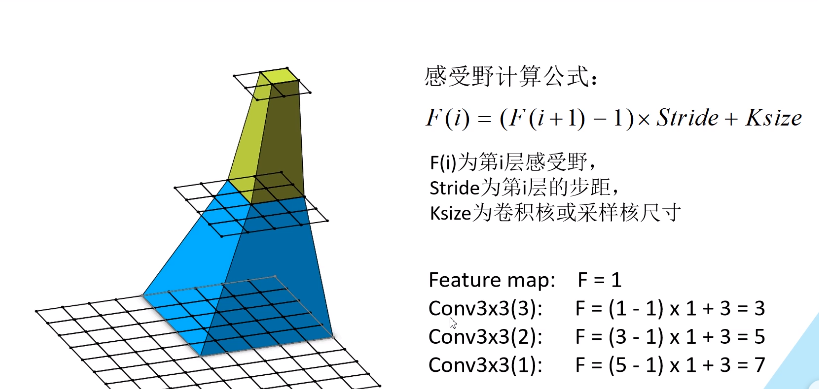
图1、感受野的解释(图文来源B站,文末给有链接,这个UP主讲的很好)
②、ConvNet-C使用了1×1的卷积滤波器,该卷积核的作用是什么?
- 1×1的卷积核不影响特征图的感受野,但是会增加模型的非线性。
- 1×1的卷积核本身是对每个通道做线性变换,起到非线性作用的是卷积层后紧跟的非线性激活函数。
③、网络深度对结果的影响
- VGG16与谷歌的GoogleNet网络深度都很深。
- 二者都采用了小卷积
- VGG16只采用3×3的卷积核,而GoogleNet采用了1×1、3×3、5×5的卷积核,模型更为复杂。
四、模型参数说明

五、VGG-16的网络结构
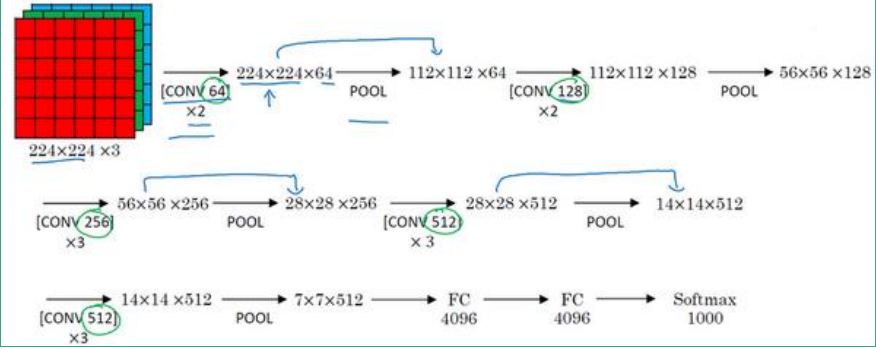
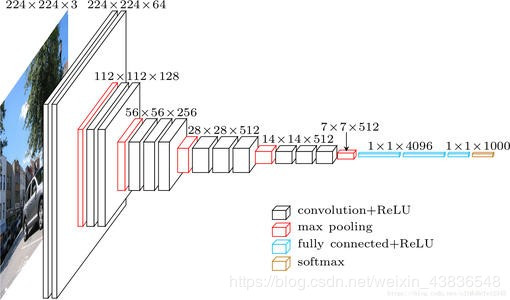
注意:FC1000层后没有ReLU激活函数,而是用softmax层激活。
六、参考文献
- https://arxiv.org/abs/1409.1556(原文)
- https://blog.csdn.net/C_chuxin/article/details/82833070?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase#%C2%A0%C2%A0%E6%9C%AC%E6%96%87%E6%A6%82%E8%BF%B0(翻译)
- https://blog.csdn.net/whz1861/article/details/78111606(讲解)
- https://youtu.be/RNnKtNrsrmg(VGG16可视化)
- https://www.bilibili.com/video/BV1q7411T7Y6/?spm_id_from=333.788.videocard.15(B站UP详讲VGG16)
作者:Ryanjie
出处:http://www.cnblogs.com/ryanjan/
本文版权归作者和博客园所有,欢迎转载。转载请在留言板处留言给我,且在文章标明原文链接,谢谢!
如果您觉得本篇博文对您有所收获,觉得我还算用心,请点击右下角的 [推荐],谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号