Web资源访问及HTTP协议详解
下图为在浏览器中输入URL 后的一系列过程:

从此图中可以总结出几条结论:
1. 如果DNS服务器坏了,可以直接通过ip地址访问网页,因为DNS只是一个域名和IP地址的MAP;
通过在命令行中输入 “ping 域名”即可;
比如:
在命令行中输入 ping www.baidu.com ,则出现如下文字:

可以看出 www.baidu.com 的ip地址是119.75.217.56 ;
直接在浏览器中输入 119.75.217.56 即可访问baidu;
2.Host文件位于 C:\Windows\System32\drivers\etc\hosts
此文件的用途:外挂,将游戏升级程序访问的服务器IP改成自己的机器的IP; 再比如优酷等视频网站去除广告就是通过此种方法;
在此文件中修改映射关系可以改变访问的效果,比如在文件中添加:
127.0.0.1 www.sina.com
则打开tomcat;
在浏览器中输入 http://www.sina.com:8080 可以看到tomcat的主页;
因为在访问DNS服务器之前ie会去访问 Hosts文件,如果存在映射关系,则不会去访问DNS服务器;
3.访问静态资源之前其实会访问默认Servlet,如果自己覆盖默认的Servlet,则不能正常访问到静态资源;
覆盖默认Servlet只需要<url-pattern>/</url-Pattern> 即可;
4.发送HTTP请求的前提是连接服务器;
HTTP协议总结
HTTP协议一般是隐藏在浏览器背后的,如果要查看HTTP协议内容,则需要下载IE插件 HTTPWATCH;
下载地址: http://www.99d.com/down/32/490672.html
HTTP协议时平台无关的;
HTTP由HTTP请求和HTTP响应组成;
1.HTTP请求
一般的HTTP请求如下:

1.1请求行
请求行是由 请求方式、请求资源、请求协议组成;
1.1.1请求方式
请求方式主要有GET和POST两种;
除了表单提交,其他都是GET请求;
一共有八种请求方式:
| 请求方式 | 作用 |
| get | 用于请求某个资源,理论上不修改服务器的状态 |
| post | 表单提交 |
| head | 只返回get请求后相应的头,而不用吧相应体(HTML)返回 |
| trace | 显示服务器端接收的信息,用于调试 |
| put | 将包含的信息放在URL中 |
| delete | 指明要删除某个URL对应的资源 |
| options | 列出HTTP方法列表 |
| connect | 建立隧道 |
幂等:一次请求和多次请求的结果是一样的;
在请求方式中,满足幂等的有:HEAD、GET、PUT;其余的都不是幂等;
1.1.2请求资源
请求资源是要请求返回的web资源;
1.1.3请求协议
请求协议现在一般使用HTTP/1.1,以前使用HTTP/1.0
注意:HTTP/1.1和HTTP/1.0的区别
HTTP是基于TCP/IP之上的,HTTP/1.0是指连接web服务器后只允许一次HTTP请求;HTTP/1.1是指连接web服务器后允许多次HTTP请求;
1.2请求头
请求头是由很多Map组成;
| Host | 客户机向服务器发送请求的主机名 |
| Accept | 客户机支持的数据类型 |
| Accept-Language |
客户机支持的语言 Tips:在访问www.google.com 时服务器会解析出客户机支持的语言,然后发回此语言的网页; |
| Accept-Charset | 客户机支持的编码 |
| Accept-Encoding | 客户机的压缩格式 |
| Referer |
客户机访问此资源的来源;比如从1.html中的超链接请求2.html,则请求2.html时会发送Referer: 1.html 用途:防盗链 避免从未知网站链接此网站,盗用资源 |
| User-Agent | 客户机的软件环境 |
| Connection | 客户机发送此连接后的连接状态时继续连接还是断开 |
| Date | 客户机发送的时间 |
注意:请求头和实际内容中间需要加上空行;
2.HTTP响应
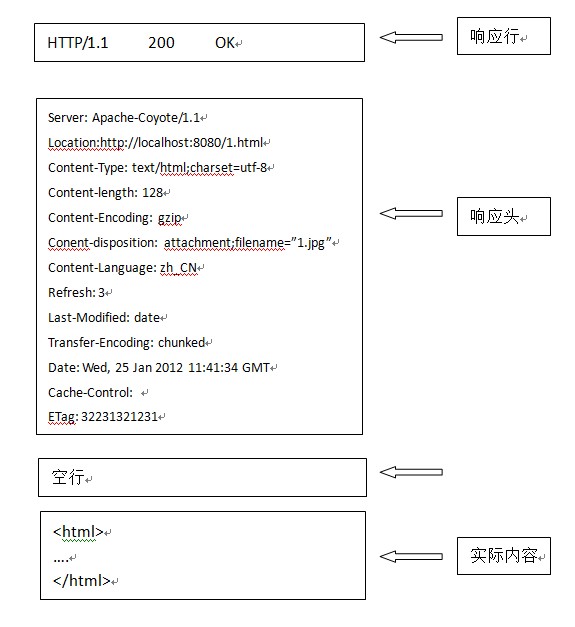
2.1 响应行
2.2.1 状态码
| 100-199 | 服务器成功接收客户请求,不过需要让客户机继续发送请求完成整个请求过程 |
| 200-299 | 200 成功处理 |
| 300-399 | 302 : 找别人,在响应头中需要有location属性; 304、307:找缓存,即缓存中存在页面 |
| 400-499 | 403:存在页面,但是用户没有权限访问; 404:无此页面 |
| 500-599 | 500 : 服务器内部错误 |
2.2 响应头
| Server | 服务器信息 |
| Content-Length | 响应内容的长度 |
| Content-Encoding | 服务器内容的压缩格式 |
| Content-Type | 服务器内容的格式,比如text/html ; image/jpeg |
| location |
用于状态码为302,表示别人的地址 |
| Content-disposition | 下载返回的数据 |
| Transfer-Encoding | 以块传输还是以字节传输 |
| Date | 时间 |
| refresh | 定时刷新或重定向 |
| Last-Modified | 最后改变的时间 |
| Expires | -1或0 表示无缓存 |
| ETag | 每个web资源都有一个标示符,只要web资源内容改动,标示符就会改变; |
应用1:location重定向
response.setStatus(302);
response.setHeader("location","http://localhost:8080/a/1.html");
应用2:content-Encoding 压缩数据
response.setHeader("content-encoding","gzip");
ByteArrayOutputStream bout = new ByteArrayOutputStream();
GZIPOutputStream out = new GZIPOutputStream(bout);
out.write("Hello".getBytes());
out.close();
byte[] b = bout.toByteArray();
response.getOutputStream().write(b);
电信对于网站的收费是按照出口流量收费的,因此需要压缩数据,减少费用;
应用3:content-disposition
response.setHeader("content-disposition","attachment;filename=1.jpg");
应用4:refresh
response.setHeader("refresh","3"); 定时更新 用于实时软件
response.setHeader("refresh","3;url='http://localhost:8080/1.html'"); 注册登录
应用5:content-type 返回的数据类型;
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("content-type", "image/ipeg");
InputStream in = this.getServletContext().getResourceAsStream("/1.jpg");
java.io.OutputStream out = response.getOutputStream();
byte[]b = new byte[1024];
int length = 0;
while((length=in.read(b))>0){
out.write(b, 0, length);
}
out.close();
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号