二分查找(上)
什么是二分查找?
-
思考题
我们假设只有 10 个订单,订单金额分别是:8,11,19,23,27,33,45,55,67,98。
我们现在想知道是否存在金额等于 19 元的订单,那该怎么做?
最简单的办法当然是从第一个订单开始,一个一个遍历这 10个订单,直到找到金额等于 19 元的订单为止,
但这样查找会比较慢,数据多了呢,那用二分查找能不能更快速地解决呢?
利用二分思想,每次都与区间的中间数据比对大小,缩小查找区间的范围。为了更加直观,我画了一张查找过程的图。其中,low 和 high 表示待查找区间的下标,mid 表示待查找区间的中间元素下标。
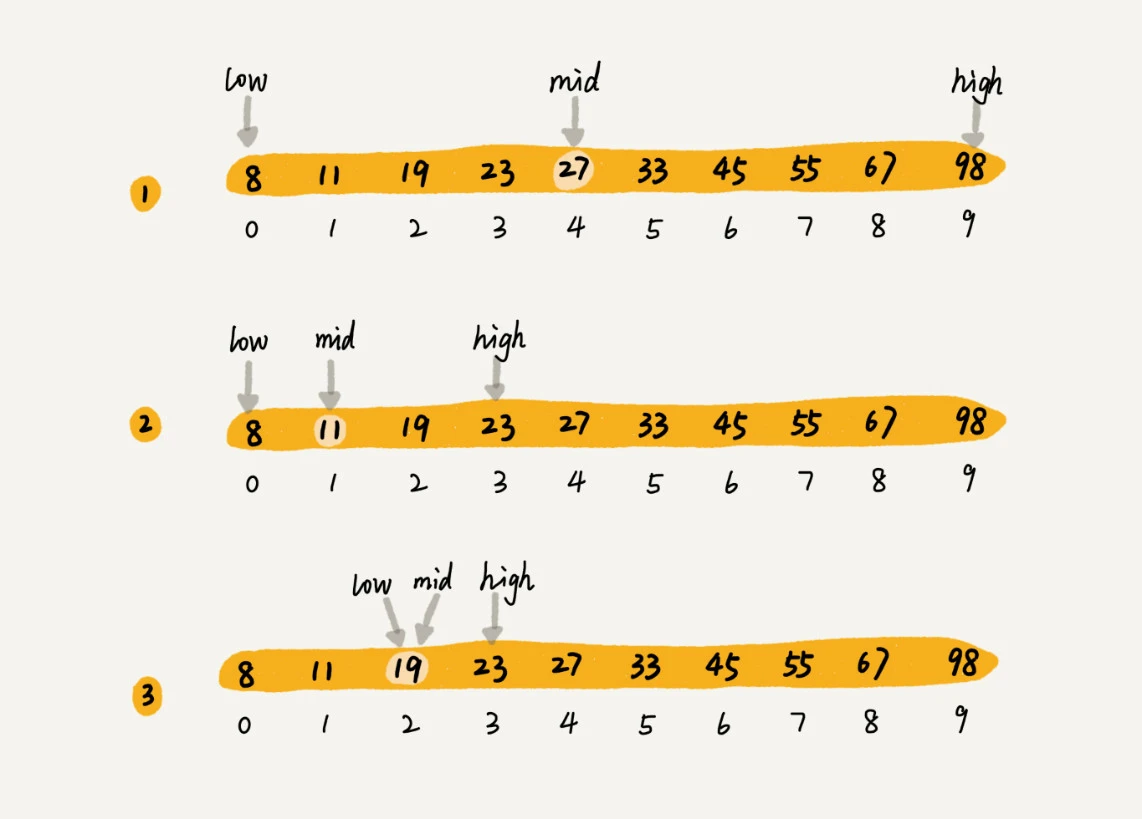
总结:
二分查找针对的是一个有序的数据集合,查找思想有点类似分治思想。每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为 0。
时间复杂度分析?
我们假设数据大小是 n,每次查找后数据都会缩小为原来的一半,也就是会除以 2。最坏情况下,直到查找区间被缩小为空,才停止。

- 时间复杂度
可以看出来,这是一个等比数列。其中 n/2k=1 时,k的值就是总共缩小的次数。而每一次缩小操作只涉及两个数据的大小比较,所以,经过了k次区间缩小操作,时间复杂度就是O(k)。通过n/2k=1,我们可以求得k=log2n,所以时间复杂度就是O(logn)。
- 认识O(logn)
- 这是一种极其高效的时间复杂度,有时甚至比O(1)的算法还要高效。为什么?
- 因为logn是一个非常“恐怖“的数量级,即便n非常大,对应的logn也很小。比如n等于2的32次方,也就是42亿,而logn才32。
- 由此可见,O(logn)有时就是比O(1000),O(10000)快很多。
如何实现二分查找?
1.循环实现
public int binarySearch1(int[] a, int val){
int start = 0;
int end = a.length - 1;
while(start <= end){
int mid = start + (end - start) / 2;
if(a[mid] > val) end = mid - 1;
else if(a[mid] < val) start = mid + 1;
else return mid;
}
return -1;
}
注意事项:
-
循环退出条件是:start<=end,而不是start<end。
-
mid的取值,使用mid=start + (end - start) / 2,而不用mid=(start + end)/2,因为如果start和end比较大的话,求和可能会发生int类型的值超出最大范围(把low,high看成数轴上两个点,二者的中点mid,可不就是在low基础上再加上区间长度(high-low)的一半吗?也就是low+(high-low)/2,更进一步,如果要将性能优化到极致的话,我们可以将这里的除以 2 操作转化成位运算 low+((high-low)>>1)。因为相比除法运算来说,计算机处理位运算要快得多。
-
start和end的更新:start = mid - 1,end = mid + 1,若直接写成start = mid,end=mid,就可能会发生死循环。
- 递归实现
public int binarySearch(int[] a, int val){
return bSear(a, val, 0, a.length-1);
}
private int bSear(int[] a, int val, int start, int end) {
if(start > end) return -1;
int mid = start + (end - start) / 2;
if(a[mid] == val) return mid;
else if(a[mid] > val) end = mid - 1;
else start = mid + 1;
return bSear(a, val, start, end);
}
使用条件(应用场景的局限性)
-
二分查找依赖的是顺序表结构,即数组。
-
二分查找针对的是有序数据。所以,如果我们针对的是一组静态的数据,没有频繁地插入、删除,我们可以进行一次排序,多次二分查找。这样排序的成本可被均摊,二分查找的边际成本就会比较低。
-
数据量太小不适合二分查找,与直接遍历相比效率提升不明显。但有一个例外,就是数据之间的比较操作非常费时,比如数组中存储的都是长度超过300的字符串,那这是还是尽量减少比较操作使用二分查找吧。
-
数据量太大也不是适合用二分查找,因为数组需要连续的空间,若数据量太大,往往找不到存储如此大规模数据的连续内存空间。
思考
- 如何在1000万个整数中快速查找某个整数?
- 1000万个整数占用存储空间为40MB,占用空间不大,所以可以全部加载到内存中进行处理;
- 用一个1000万个元素的数组存储,然后使用快排进行升序排序,时间复杂度为O(nlogn)
- 在有序数组中使用二分查找算法进行查找,时间复杂度为O(logn)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号