

栈:如何实现浏览器的前进和后退功能
如何理解“栈”?
关于“栈”,我有一个非常贴切的例子,就是一摞叠在一起的盘子。我们平时放盘子的时候,都是从下往上一个一个放;取的时候,我们也是从上往下一个一个地依次取,不能从中间任意抽出。后进者先出,先进者后出,这就是典型的“栈”结构。
从栈的操作特性上来看,栈是一种“操作受限”的线性表,只允许在一端插入和删除数据。
当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性,这时我们就应该首选“栈”这种数据结构。
如何实现一个“栈”?
栈主要包含两个操作,入栈和出栈,也就是在栈顶插入一个数据和从栈顶删除一个数据。实际上,栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序栈,用链表实现的栈,我们叫作链式栈。
- 空间复杂度:
不管是顺序栈还是链式栈,我们存储数据只需要一个大小为 n 的数组就够了。在入栈和出栈过程中,只需要一两个临时变量存储空间,所以空间复杂度是 O(1)。 - 时间复杂度:
不管是顺序栈还是链式栈,入栈、出栈只涉及栈顶个别数据的操作,所以时间复杂度都是 O(1)。
支持动态扩容的顺序栈
基于数组实现的栈,是一个固定大小的栈,在初始化栈时需要事先指定栈的大小。当栈满之后,就无法再往栈里添加数据了。尽管链式栈的大小不受限,但要存储 next 指针,内存消耗相对较多。所以我们就要基于数组实现一个可以支持动态扩容的栈
如何来实现一个支持动态扩容的数组的吗?当数组空间不够时,我们就重新申请一块更大的内存,将原来数组中数据统统拷贝过去就可以了
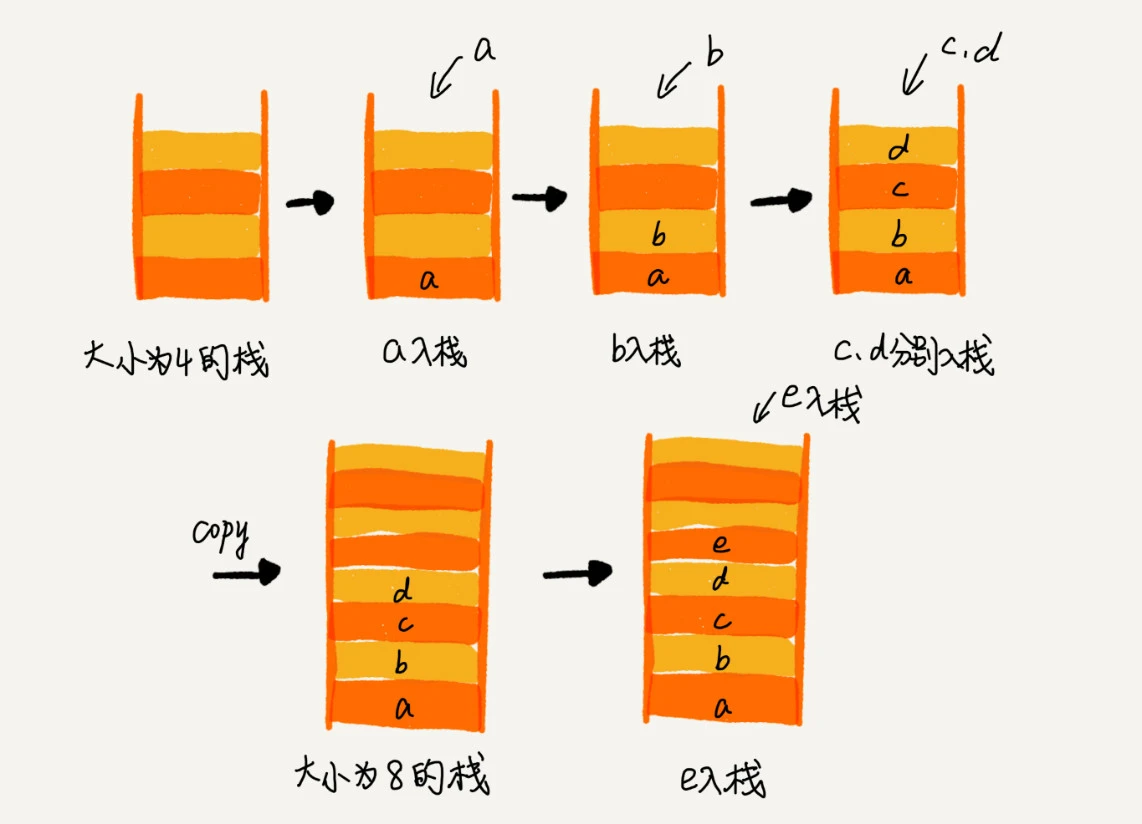
栈操作来说,我们不会涉及内存的重新申请和数据的搬移,所以出栈的时间复杂度仍然是 O(1)。但是,对于入栈操作来说,情况就不一样了。当栈中有空闲空间时,入栈操作的时间复杂度为 O(1)。但当空间不够时,就需要重新申请内存和数据搬移,所以时间复杂度就变成了 O(n)。
分析一下支持动态扩容的顺序栈的入栈、出栈操作的时间复杂度:
为了分析的方便,我们需要事先做一些假设和定义:
- 栈空间不够时,我们重新申请一个是原来大小两倍的数组;
- 为了简化分析,假设只有入栈操作没有出栈操作;
- 定义不涉及内存搬移的入栈操作为 simple-push 操作,时间复杂度为 O(1)。
如果当前栈大小为 K,并且已满,当再有新的数据要入栈时,就需要重新申请 2 倍大小的内存,并且做 K 个数据的搬移操作,然后再入栈。但是,接下来的 K-1 次入栈操作,我们都不需要再重新申请内存和搬移数据,所以这 K-1 次入栈操作都只需要一个 simple-push 操作就可以完成
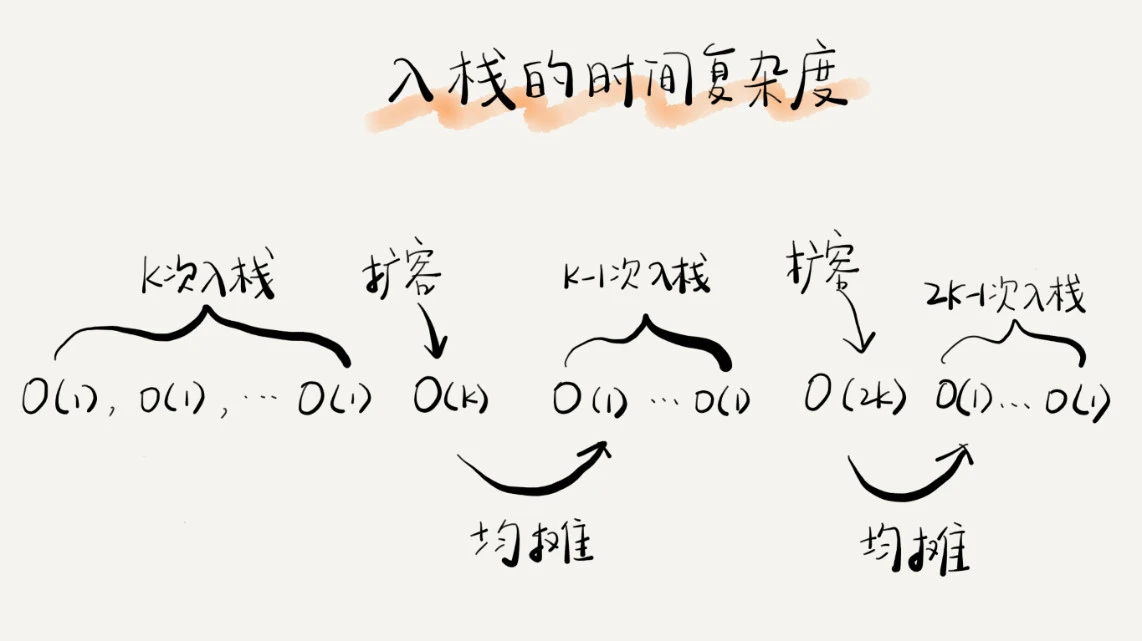
这 K 次入栈操作,总共涉及了 K 个数据的搬移,以及 K 次 simple-push 操作。将 K 个数据搬移均摊到 K 次入栈操作,那每个入栈操作只需要一个数据搬移和一个 simple-push 操作。以此类推,入栈操作的均摊时间复杂度就为 O(1)。
通过这个例子的实战分析,也印证了前面讲到的,均摊时间复杂度一般都等于最好情况时间复杂度。因为在大部分情况下,入栈操作的时间复杂度 O 都是 O(1),只有在个别时刻才会退化为 O(n),所以把耗时多的入栈操作的时间均摊到其他入栈操作上,平均情况下的耗时就接近 O(1)。
总结:也就是说,对于入栈操作来说,最好情况时间复杂度是 O(1),最坏情况时间复杂度是 O(n),平均情况下的时间复杂度是O(1),均摊时间复杂度就为 O(1)
注意:
栈空间大小初始值为k,当第k+1次入栈操作时,栈空间不够了,重新申请2k大小的新的栈空间,copy旧值(k个值已在栈中)以及第第k+1次入栈后, 2k大小的栈空间可不就剩 k-1了,只能再允许k-1次入栈操作了
栈的应用
栈在函数调用中的应用
操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈
int main() {
int a = 1;
int ret = 0;
int res = 0;
ret = add(3, 5);
res = a + ret;
printf("%d", res);
reuturn 0;
}
int add(int x, int y) {
int sum = 0;
sum = x + y;
return sum;
}
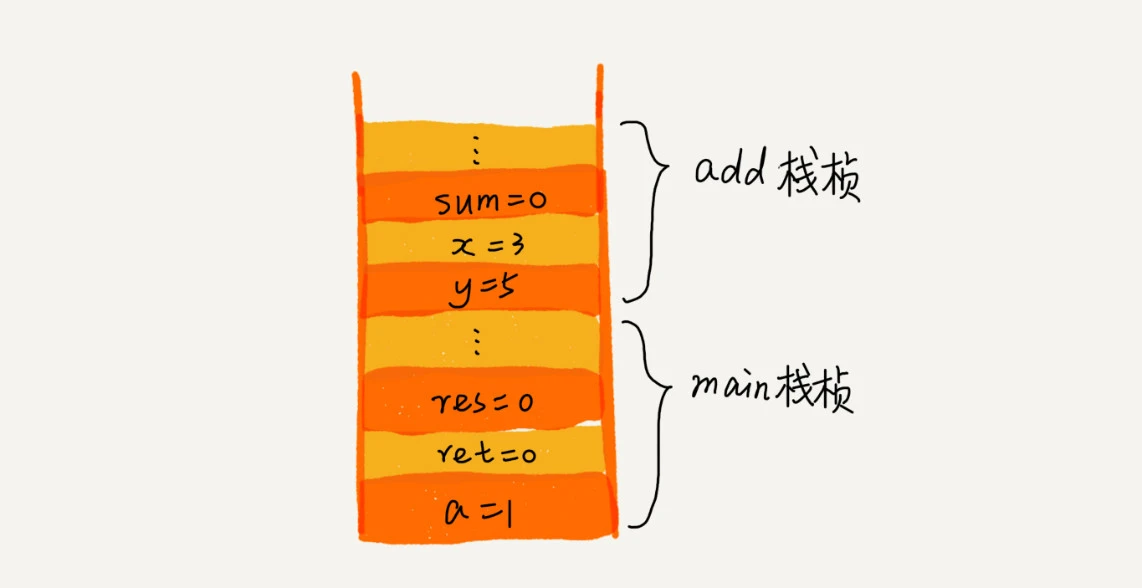
从代码中我们可以看出,main() 函数调用了 add() 函数,获取计算结果,并且与临时变量 a 相加,最后打印 res 的值。为了让你清晰地看到这个过程对应的函数栈里出栈、入栈的操作,我画了一张图。图中显示的是,在执行到 add() 函数时,函数调用栈的情况。
方便理解:
每个函数执行都会有独立的内存空间分配,称为栈,用来存储函数中的临时变量 第二点:比较有意思也就是为什么用栈,假设a函数调用b函数,进入b函数后,将一些临时变量作为一个栈帧入栈,当函数执行完之后,将这个函数对应的所有栈帧出栈,此时b函数的栈帧都在上面是后进来的但会先出去,b函数栈帧都清除后回到a函数。这也正好符合栈这种后进先出的数据结构。
栈在表达式求值中的应用
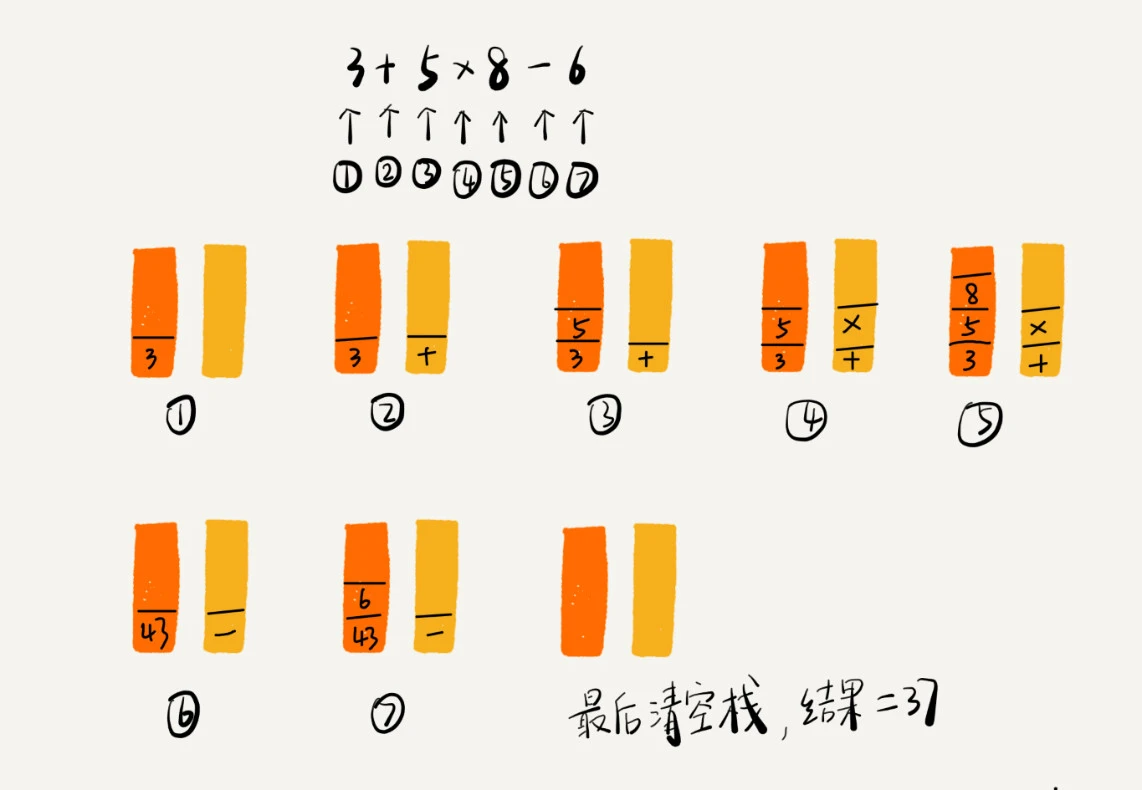
利用两个栈,其中一个用来保存操作数,另一个用来保存运算符。我们从左向右遍历表达式,当遇到数字,我们就直接压入操作数栈;当遇到运算符,就与运算符栈的栈顶元素进行比较,若比运算符栈顶元素优先级高,就将当前运算符压入栈,若比运算符栈顶元素的优先级低或者相同,从运算符栈中取出栈顶运算符,从操作数栈顶取出2个操作数,然后进行计算,把计算完的结果压入操作数栈,继续比较。
栈在括号匹配中的应用
用栈来检查表达式中的括号是否匹配
我们用栈来保存未匹配的左括号,从左到右依次扫描字符串。当扫描到左括号时,则将其压入栈中;当扫描到右括号时,从栈顶取出一个左括号。如果能够匹配,比如“(”跟“)”匹配,“[”跟“]”匹配,“{”跟“}”匹配,则继续扫描剩下的字符串。如果扫描的过程中,遇到不能配对的右括号,或者栈中没有数据,则说明为非法格式。
当所有的括号都扫描完成之后,如果栈为空,则说明字符串为合法格式;否则,说明有未匹配的左括号,为非法格式。
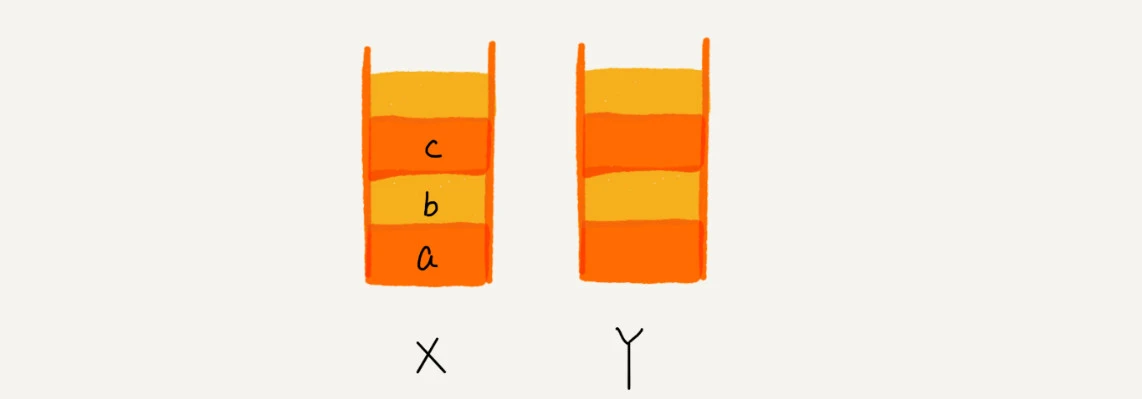
实现浏览器的前进和后退功能
用两个栈就可以非常完美地解决这个问题
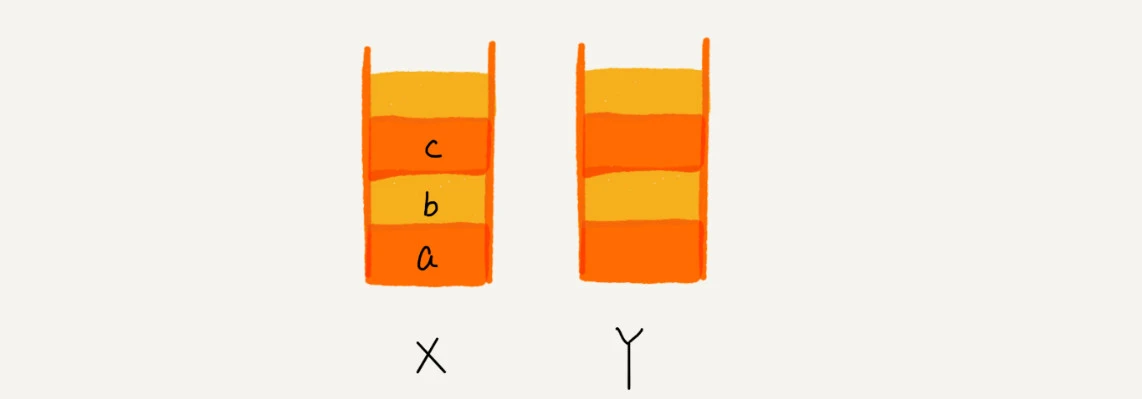
使用两个栈,X 和 Y,我们把首次浏览的页面依次压入栈 X,当点击后退按钮时,再依次从栈 X 中出栈,并将出栈的数据依次放入栈 Y。当我们点击前进按钮时,我们依次从栈 Y 中取出数据,放入栈 X 中。当栈 X 中没有数据时,那就说明没有页面可以继续后退浏览了。当栈 Y 中没有数据,那就说明没有页面可以点击前进按钮浏览了
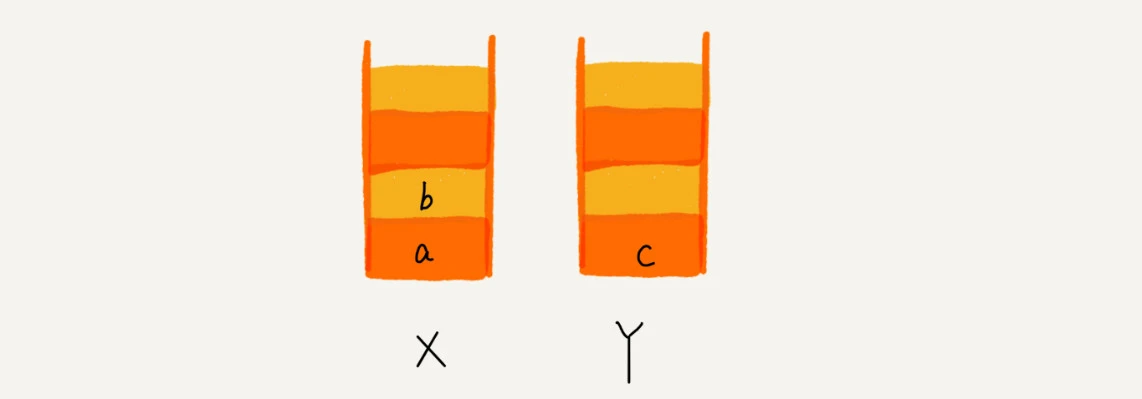
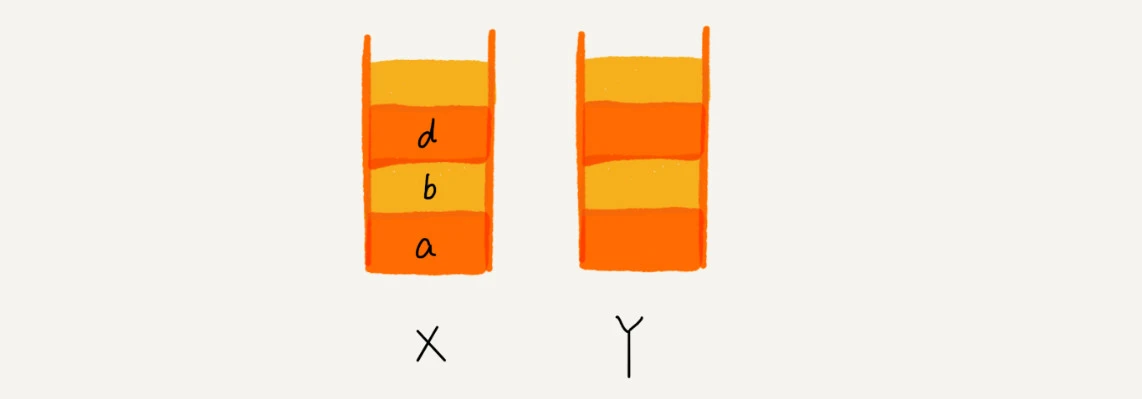
内容小结
栈是一种操作受限的数据结构,只支持入栈和出栈操作。后进先出是它最大的特点。栈既可以通过数组实现,也可以通过链表来实现。不管基于数组还是链表,入栈、出栈的时间复杂度都为 O(1)。除此之外,我们还讲了一种支持动态扩容的顺序栈,你需要重点掌握它的均摊时间复杂度分析方法。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异