
pandas练习(三)------ 数据分组
探索酒类消费数据
相关数据见(github)
步骤1 - 导入pandas库
import pandas as pd
步骤2 - 数据集
path3 = "./data/drinks.csv" # drinks.csv
步骤3 将数据框命名为drinks
drinks = pd.read_csv(path3)
drinks.head()
输出:
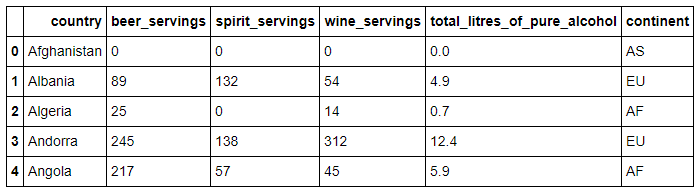
步骤4 哪个大陆(continent)平均消耗的啤酒(beer)更多?
beeravg = drinks.groupby('continent').beer_servings.mean()
beeravg.sort_values(ascending=False)
输出:
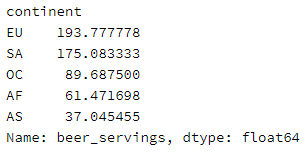
步骤5 打印出每个大陆(continent)的红酒消耗(wine_servings)的描述性统计值
drinks.groupby('continent').wine_servings.describe()
输出:
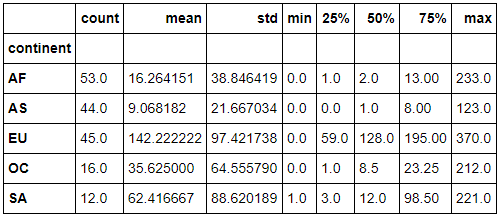
步骤6 打印出每个大陆每种酒类别的消耗平均值
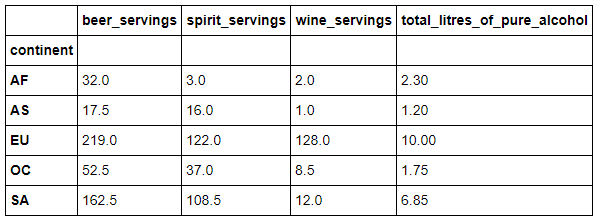
drinks.groupby('continent').mean()
输出:
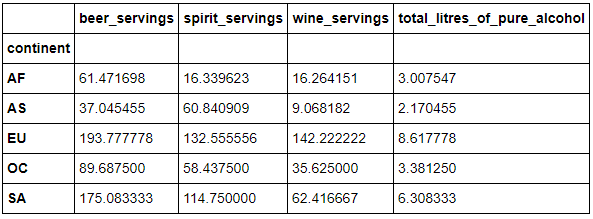
步骤7 打印出每个大陆每种酒类别的消耗中位数
drinks.groupby('continent').median()
输出:
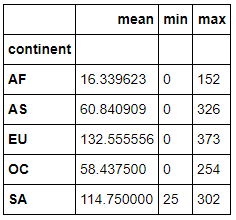
步骤8 打印出每个大陆对spirit饮品消耗的平均值,最大值和最小值
drinks.groupby('continent').spirit_servings.agg(['mean', 'min', 'max'])
输出:
参考链接:
1、http://pandas.pydata.org/pandas-docs/stable/cookbook.html#cookbook
2、https://www.analyticsvidhya.com/blog/2016/01/12-pandas-techniques-python-data-manipulation/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端