

点云分割网络---Point Transformer V3
PDF:《Point Transformer V3: Simpler, Faster, Stronger》
CODE: https://github.com/Pointcept/PointTransformerV3
一、大体内容
Point Transformer V3(PTv3)没有像V2那样在注意力机制方面寻求创新,而是专注于保持点云背景下准确性和效率之间的平衡,如下所示与上一代Point Transformer V2相比,PTv3在以下方面显示出优势:更强的性能。PTv3在各种室内和室外3D感知任务中实现了最先进的结果。感受野较宽。得益于其简单高效,PTv3将感受野从16个点扩展到1024个点,速度更快。PTv3显著提高了处理速度,使其适用于对延迟敏感的应用程序。降低内存消耗,PTv3减少了内存使用,增强了更广泛情况下的可访问性。

二、贡献点
- 更简单、更快、更强的性能: PTv3 在室内和室外 3D 感知任务中取得了最先进的成果,同时保持了较高的效率。
- 更广泛的感受野: 通过高效的数据结构,PTv3 将感受野从 16 个点扩展到 1024 个点,而不会牺牲效率。
- 更快的速度: PTv3 显著提高了处理速度,使其适用于对延迟敏感的应用。
- 更低的内存消耗: PTv3 减少了内存使用量,使其更易于在各种情况下使用。
- 多数据集联合训练: PTv3 可以通过多数据集联合训练进一步改进性能,例如使用 Point Prompt Training (PPT) 方法。
三、细节
3.1 点云序列化
PTv3 使用空间填充曲线将点云序列化为结构化格式,从而保留了空间邻近关系,并简化了计算。(如:Z-order序列化(Z-ordering)是一种用于多维数据的方法,它可以将多维空间中的点映射到一维空间中,同时保持点之间的相对邻近性。在处理点云数据时,Z-order序列化可以有效地组织数据以优化存储和访问)
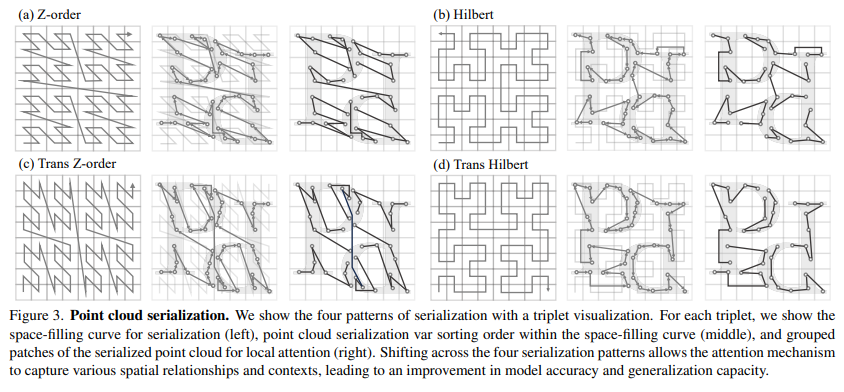
3.2 序列化注意力
PTv3 使用 patch attention 机制,将点分组到 patch 中,并在每个 patch 内进行注意力计算,从而提高了效率。PTv3 使用多种 patch 交互策略,例如 Shift Dilation、Shift Patch 和 Shuffle Order,以扩大感受野并增强模型的泛化能力。
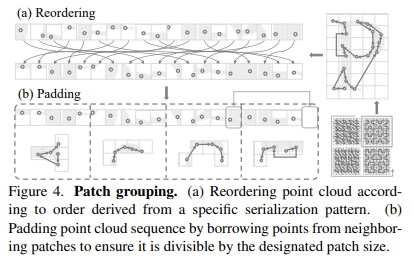
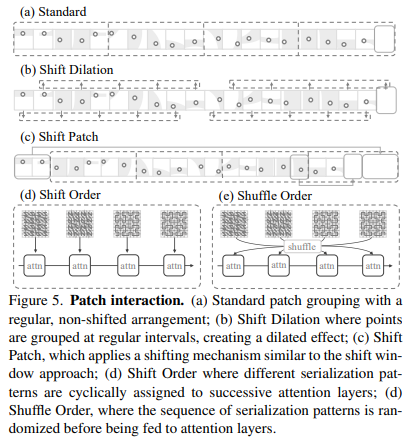
3.3 位置编码
为了处理海量数据,点云transformer通常采用局部注意力,这依赖于相对位置编码方法以获得最佳性能。观察结果表明RPE的效率明显低下且复杂。
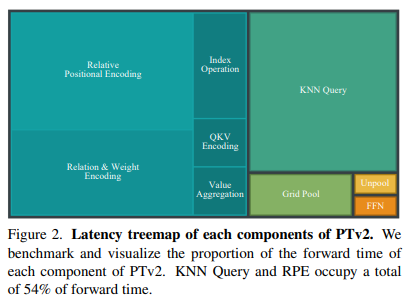
作为一种更有效的替代方案,为点云transformer引入了条件位置编码(CPE),其中通过基于八叉树的深度卷积实现。我们认为这种替换是优雅的,因为RPE在点云变换器中的实现本质上可以被视为大核稀疏卷积的变体。但单个CPE也不足以达到峰值性能(当与RPE结合时,仍有可能额外提高0.5%)。因此PTV3提出了一种增强的条件位置编码(xCPE),通过在注意力层之前直接准备具有跳过连接的稀疏卷积层来实现。实验结果表明,与标准CPE相比,xCPE完全释放了性能,延迟略微增加了几毫秒,性能增益证明了这种微小的权衡是合理的。
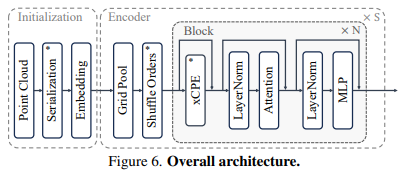
3.4 网络结构
PTv3 采用 U-Net 框架,包含四个编码器和解码器阶段,每个阶段都有不同的 block 深度和通道数。
四、效果
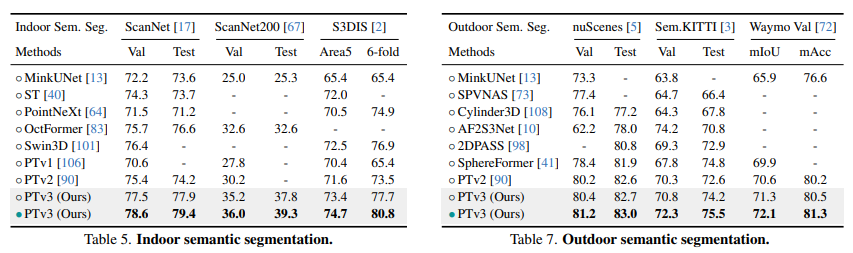
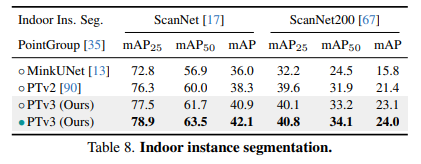
4.1 分割
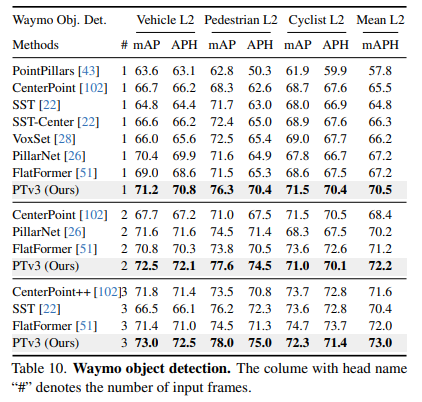
4.2 检测
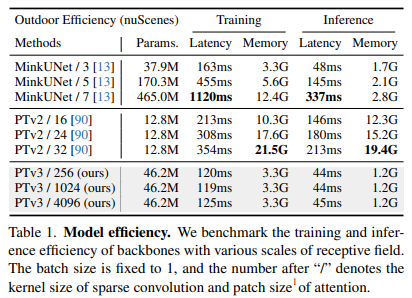
4.3 效率


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!
2017-07-10 nodejs爬虫笔记(二)---代理设置